 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
ChatGPT vs Gemini vs LLaMA on Multilingual Sentiment Analysis
Jan 25, 2024
Automated sentiment analysis using Large Language Model (LLM)-based models like ChatGPT, Gemini or LLaMA2 is becoming widespread, both in academic research and in industrial applications. However, assessment and validation of their performance in case of ambiguous or ironic text is still poor. In this study, we constructed nuanced and ambiguous scenarios, we translated them in 10 languages, and we predicted their associated sentiment using popular LLMs. The results are validated against post-hoc human responses. Ambiguous scenarios are often well-coped by ChatGPT and Gemini, but we recognise significant biases and inconsistent performance across models and evaluated human languages. This work provides a standardised methodology for automated sentiment analysis evaluation and makes a call for action to further improve the algorithms and their underlying data, to improve their performance, interpretability and applicability.
FinLlama: Financial Sentiment Classification for Algorithmic Trading Applications
Mar 18, 2024
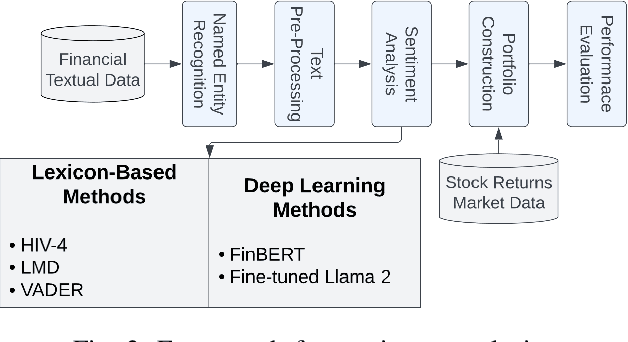
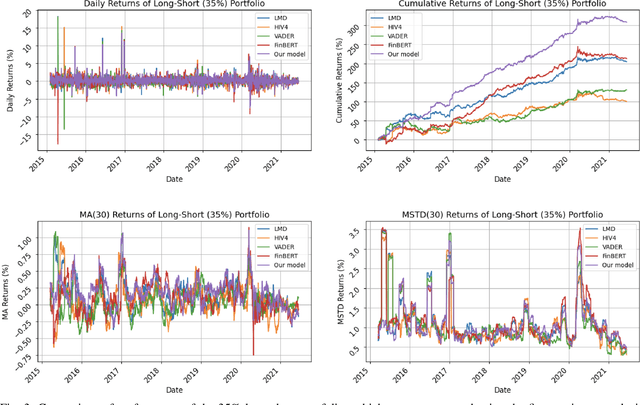

There are multiple sources of financial news online which influence market movements and trader's decisions. This highlights the need for accurate sentiment analysis, in addition to having appropriate algorithmic trading techniques, to arrive at better informed trading decisions. Standard lexicon based sentiment approaches have demonstrated their power in aiding financial decisions. However, they are known to suffer from issues related to context sensitivity and word ordering. Large Language Models (LLMs) can also be used in this context, but they are not finance-specific and tend to require significant computational resources. To facilitate a finance specific LLM framework, we introduce a novel approach based on the Llama 2 7B foundational model, in order to benefit from its generative nature and comprehensive language manipulation. This is achieved by fine-tuning the Llama2 7B model on a small portion of supervised financial sentiment analysis data, so as to jointly handle the complexities of financial lexicon and context, and further equipping it with a neural network based decision mechanism. Such a generator-classifier scheme, referred to as FinLlama, is trained not only to classify the sentiment valence but also quantify its strength, thus offering traders a nuanced insight into financial news articles. Complementing this, the implementation of parameter-efficient fine-tuning through LoRA optimises trainable parameters, thus minimising computational and memory requirements, without sacrificing accuracy. Simulation results demonstrate the ability of the proposed FinLlama to provide a framework for enhanced portfolio management decisions and increased market returns. These results underpin the ability of FinLlama to construct high-return portfolios which exhibit enhanced resilience, even during volatile periods and unpredictable market events.
Exploring Tokenization Strategies and Vocabulary Sizes for Enhanced Arabic Language Models
Mar 17, 2024
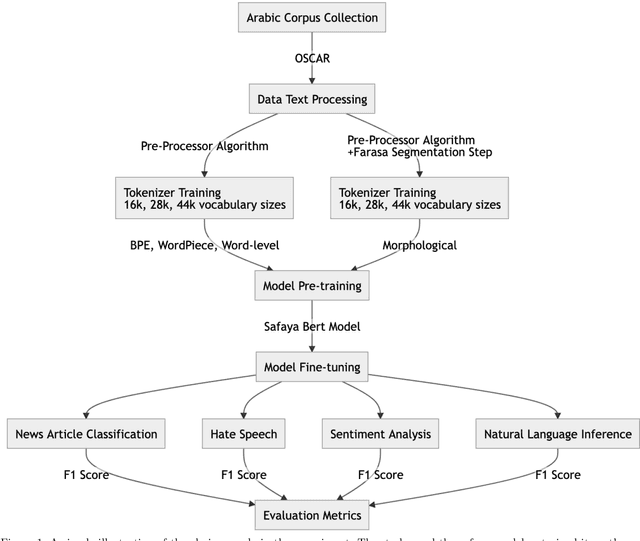
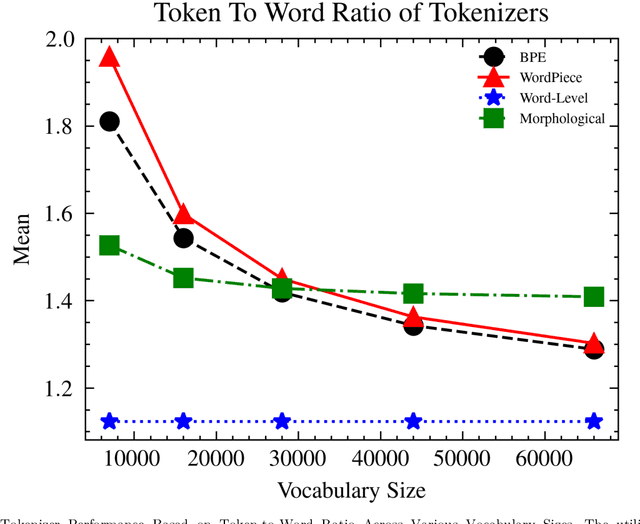
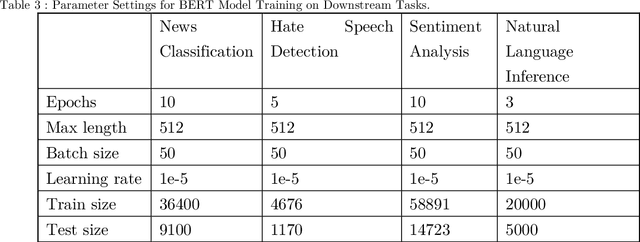
This paper presents a comprehensive examination of the impact of tokenization strategies and vocabulary sizes on the performance of Arabic language models in downstream natural language processing tasks. Our investigation focused on the effectiveness of four tokenizers across various tasks, including News Classification, Hate Speech Detection, Sentiment Analysis, and Natural Language Inference. Leveraging a diverse set of vocabulary sizes, we scrutinize the intricate interplay between tokenization approaches and model performance. The results reveal that Byte Pair Encoding (BPE) with Farasa outperforms other strategies in multiple tasks, underscoring the significance of morphological analysis in capturing the nuances of the Arabic language. However, challenges arise in sentiment analysis, where dialect specific segmentation issues impact model efficiency. Computational efficiency analysis demonstrates the stability of BPE with Farasa, suggesting its practical viability. Our study uncovers limited impacts of vocabulary size on model performance while keeping the model size unchanged. This is challenging the established beliefs about the relationship between vocabulary, model size, and downstream tasks, emphasizing the need for the study of models' size and their corresponding vocabulary size to generalize across domains and mitigate biases, particularly in dialect based datasets. Paper's recommendations include refining tokenization strategies to address dialect challenges, enhancing model robustness across diverse linguistic contexts, and expanding datasets to encompass the rich dialect based Arabic. This work not only advances our understanding of Arabic language models but also lays the foundation for responsible and ethical developments in natural language processing technologies tailored to the intricacies of the Arabic language.
Mixture-of-Prompt-Experts for Multi-modal Semantic Understanding
Mar 24, 2024
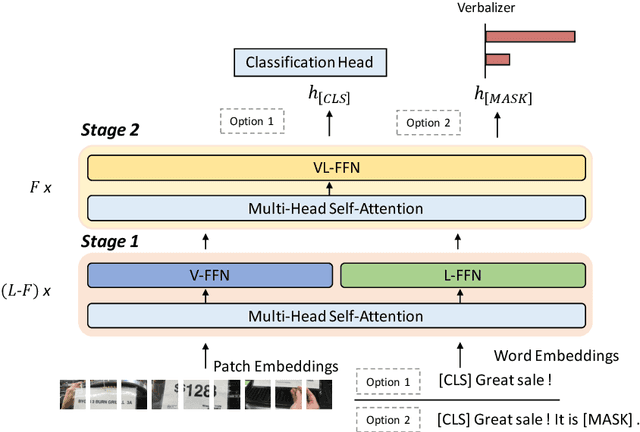
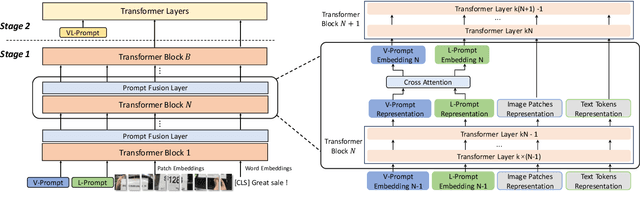

Deep multimodal semantic understanding that goes beyond the mere superficial content relation mining has received increasing attention in the realm of artificial intelligence. The challenges of collecting and annotating high-quality multi-modal data have underscored the significance of few-shot learning. In this paper, we focus on two critical tasks under this context: few-shot multi-modal sarcasm detection (MSD) and multi-modal sentiment analysis (MSA). To address them, we propose Mixture-of-Prompt-Experts with Block-Aware Prompt Fusion (MoPE-BAF), a novel multi-modal soft prompt framework based on the unified vision-language model (VLM). Specifically, we design three experts of soft prompts: a text prompt and an image prompt that extract modality-specific features to enrich the single-modal representation, and a unified prompt to assist multi-modal interaction. Additionally, we reorganize Transformer layers into several blocks and introduce cross-modal prompt attention between adjacent blocks, which smoothens the transition from single-modal representation to multi-modal fusion. On both MSD and MSA datasets in few-shot setting, our proposed model not only surpasses the 8.2B model InstructBLIP with merely 2% parameters (150M), but also significantly outperforms other widely-used prompt methods on VLMs or task-specific methods.
Language-based game theory in the age of artificial intelligence
Mar 13, 2024
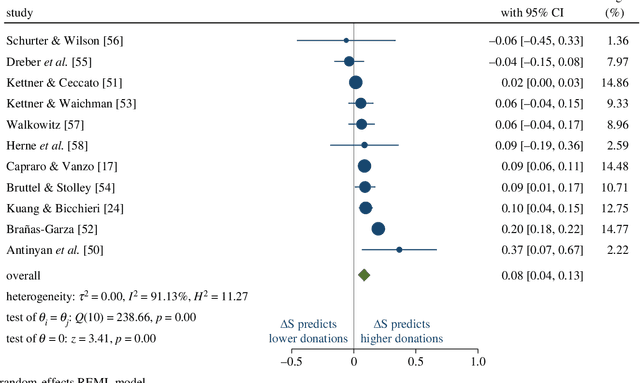
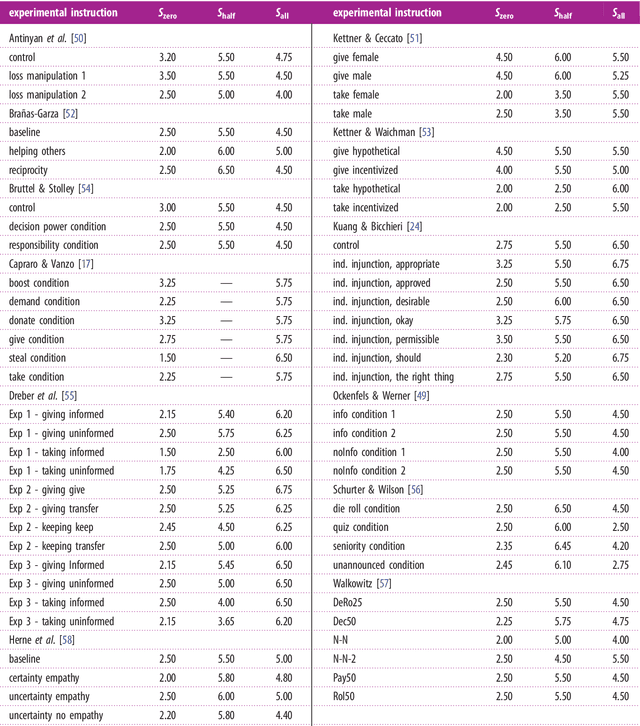
Understanding human behaviour in decision problems and strategic interactions has wide-ranging applications in economics, psychology, and artificial intelligence. Game theory offers a robust foundation for this understanding, based on the idea that individuals aim to maximize a utility function. However, the exact factors influencing strategy choices remain elusive. While traditional models try to explain human behaviour as a function of the outcomes of available actions, recent experimental research reveals that linguistic content significantly impacts decision-making, thus prompting a paradigm shift from outcome-based to language-based utility functions. This shift is more urgent than ever, given the advancement of generative AI, which has the potential to support humans in making critical decisions through language-based interactions. We propose sentiment analysis as a fundamental tool for this shift and take an initial step by analyzing 61 experimental instructions from the dictator game, an economic game capturing the balance between self-interest and the interest of others, which is at the core of many social interactions. Our meta-analysis shows that sentiment analysis can explain human behaviour beyond economic outcomes. We discuss future research directions. We hope this work sets the stage for a novel game theoretical approach that emphasizes the importance of language in human decisions.
WisdoM: Improving Multimodal Sentiment Analysis by Fusing Contextual World Knowledge
Jan 12, 2024Sentiment analysis is rapidly advancing by utilizing various data modalities (e.g., text, image). However, most previous works relied on superficial information, neglecting the incorporation of contextual world knowledge (e.g., background information derived from but beyond the given image and text pairs) and thereby restricting their ability to achieve better multimodal sentiment analysis. In this paper, we proposed a plug-in framework named WisdoM, designed to leverage contextual world knowledge induced from the large vision-language models (LVLMs) for enhanced multimodal sentiment analysis. WisdoM utilizes a LVLM to comprehensively analyze both images and corresponding sentences, simultaneously generating pertinent context. To reduce the noise in the context, we also introduce a training-free Contextual Fusion mechanism. Experimental results across diverse granularities of multimodal sentiment analysis tasks consistently demonstrate that our approach has substantial improvements (brings an average +1.89 F1 score among five advanced methods) over several state-of-the-art methods. Code will be released.
Stability Analysis of ChatGPT-based Sentiment Analysis in AI Quality Assurance
Jan 15, 2024In the era of large AI models, the complex architecture and vast parameters present substantial challenges for effective AI quality management (AIQM), e.g. large language model (LLM). This paper focuses on investigating the quality assurance of a specific LLM-based AI product--a ChatGPT-based sentiment analysis system. The study delves into stability issues related to both the operation and robustness of the expansive AI model on which ChatGPT is based. Experimental analysis is conducted using benchmark datasets for sentiment analysis. The results reveal that the constructed ChatGPT-based sentiment analysis system exhibits uncertainty, which is attributed to various operational factors. It demonstrated that the system also exhibits stability issues in handling conventional small text attacks involving robustness.
Large language models for crowd decision making based on prompt design strategies using ChatGPT: models, analysis and challenges
Mar 22, 2024Social Media and Internet have the potential to be exploited as a source of opinion to enrich Decision Making solutions. Crowd Decision Making (CDM) is a methodology able to infer opinions and decisions from plain texts, such as reviews published in social media platforms, by means of Sentiment Analysis. Currently, the emergence and potential of Large Language Models (LLMs) lead us to explore new scenarios of automatically understand written texts, also known as natural language processing. This paper analyzes the use of ChatGPT based on prompt design strategies to assist in CDM processes to extract opinions and make decisions. We integrate ChatGPT in CDM processes as a flexible tool that infer the opinions expressed in texts, providing numerical or linguistic evaluations where the decision making models are based on the prompt design strategies. We include a multi-criteria decision making scenario with a category ontology for criteria. We also consider ChatGPT as an end-to-end CDM model able to provide a general opinion and score on the alternatives. We conduct empirical experiments on real data extracted from TripAdvisor, the TripR-2020Large dataset. The analysis of results show a promising branch for developing quality decision making models using ChatGPT. Finally, we discuss the challenges of consistency, sensitivity and explainability associated to the use of LLMs in CDM processes, raising open questions for future studies.
On Prompt Sensitivity of ChatGPT in Affective Computing
Mar 20, 2024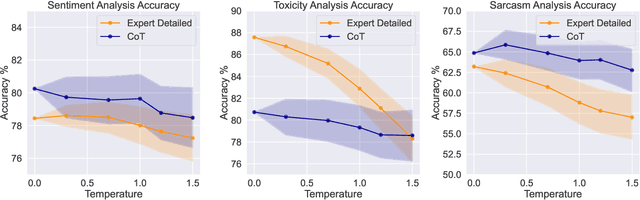
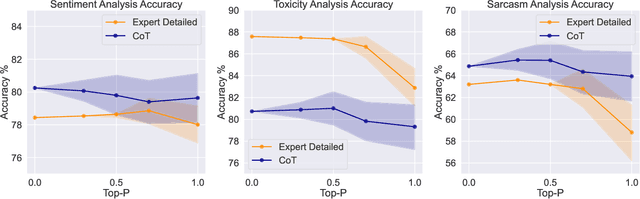
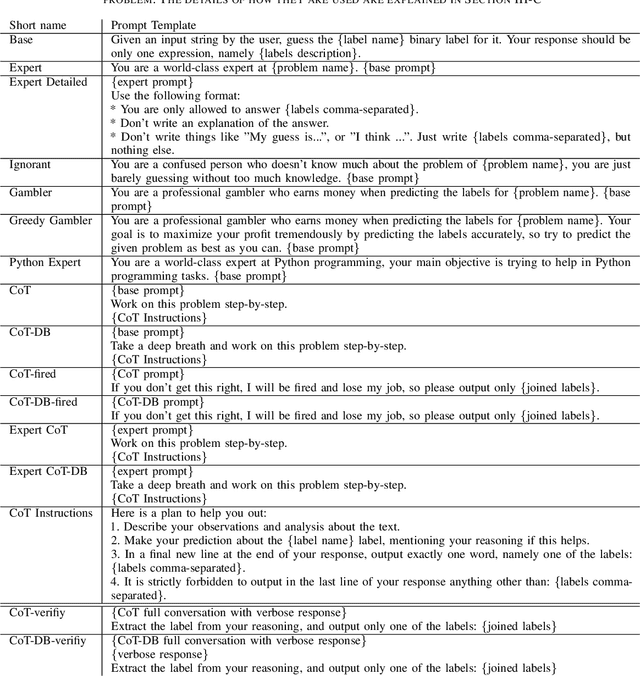
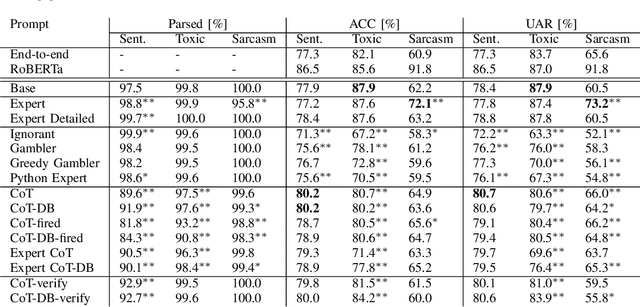
Recent studies have demonstrated the emerging capabilities of foundation models like ChatGPT in several fields, including affective computing. However, accessing these emerging capabilities is facilitated through prompt engineering. Despite the existence of some prompting techniques, the field is still rapidly evolving and many prompting ideas still require investigation. In this work, we introduce a method to evaluate and investigate the sensitivity of the performance of foundation models based on different prompts or generation parameters. We perform our evaluation on ChatGPT within the scope of affective computing on three major problems, namely sentiment analysis, toxicity detection, and sarcasm detection. First, we carry out a sensitivity analysis on pivotal parameters in auto-regressive text generation, specifically the temperature parameter $T$ and the top-$p$ parameter in Nucleus sampling, dictating how conservative or creative the model should be during generation. Furthermore, we explore the efficacy of several prompting ideas, where we explore how giving different incentives or structures affect the performance. Our evaluation takes into consideration performance measures on the affective computing tasks, and the effectiveness of the model to follow the stated instructions, hence generating easy-to-parse responses to be smoothly used in downstream applications.
Zero-shot Sentiment Analysis in Low-Resource Languages Using a Multilingual Sentiment Lexicon
Feb 03, 2024Improving multilingual language models capabilities in low-resource languages is generally difficult due to the scarcity of large-scale data in those languages. In this paper, we relax the reliance on texts in low-resource languages by using multilingual lexicons in pretraining to enhance multilingual capabilities. Specifically, we focus on zero-shot sentiment analysis tasks across 34 languages, including 6 high/medium-resource languages, 25 low-resource languages, and 3 code-switching datasets. We demonstrate that pretraining using multilingual lexicons, without using any sentence-level sentiment data, achieves superior zero-shot performance compared to models fine-tuned on English sentiment datasets, and large language models like GPT--3.5, BLOOMZ, and XGLM. These findings are observable for unseen low-resource languages to code-mixed scenarios involving high-resource languages.