 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Sentiment Analysis on YouTube Smart Phone Unboxing Video Reviews in Sri Lanka
Feb 04, 2023
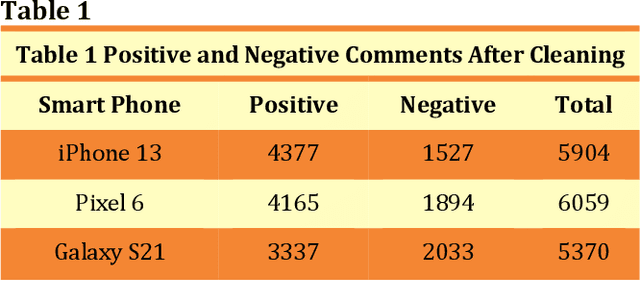
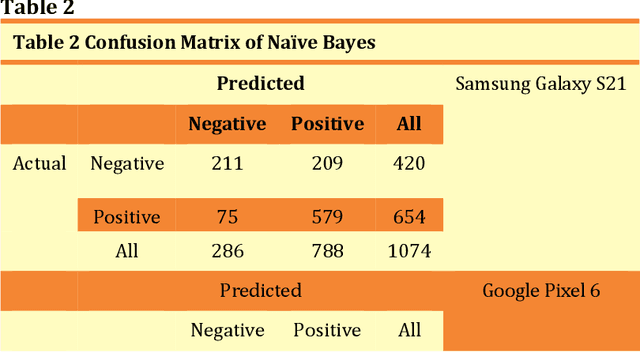


Product-related reviews are based on users' experiences that are mostly shared on videos in YouTube. It is the second most popular website globally in 2021. People prefer to watch videos on recently released products prior to purchasing, in order to gather overall feedback and make worthy decisions. These videos are created by vloggers who are enthusiastic about technical materials and feedback is usually placed by experienced users of the product or its brand. Analyzing the sentiment of the user reviews gives useful insights into the product in general. This study is focused on three smartphone reviews, namely, Apple iPhone 13, Google Pixel 6, and Samsung Galaxy S21 which were released in 2021. VADER, which is a lexicon and rule-based sentiment analysis tool was used to classify each comment to its appropriate positive or negative orientation. All three smartphones show a positive sentiment from the users' perspective and iPhone 13 has the highest number of positive reviews. The resulting models have been tested using N\"aive Bayes, Decision Tree, and Support Vector Machine. Among these three classifiers, Support Vector Machine shows higher accuracies and F1-scores.
Predicting Listing Prices In Dynamic Short Term Rental Markets Using Machine Learning Models
Aug 14, 2023Our research group wanted to take on the difficult task of predicting prices in a dynamic market. And short term rentals such as Airbnb listings seemed to be the perfect proving ground to do such a thing. Airbnb has revolutionized the travel industry by providing a platform for homeowners to rent out their properties to travelers. The pricing of Airbnb rentals is prone to high fluctuations, with prices changing frequently based on demand, seasonality, and other factors. Accurate prediction of Airbnb rental prices is crucial for hosts to optimize their revenue and for travelers to make informed booking decisions. In this project, we aim to predict the prices of Airbnb rentals using a machine learning modeling approach. Our project expands on earlier research in the area of analyzing Airbnb rental prices by taking a methodical machine learning approach as well as incorporating sentiment analysis into our feature engineering. We intend to gain a deeper understanding on periodic changes of Airbnb rental prices. The primary objective of this study is to construct an accurate machine learning model for predicting Airbnb rental prices specifically in Austin, Texas. Our project's secondary objective is to identify the key factors that drive Airbnb rental prices and to investigate how these factors vary across different locations and property types.
Reducing Spurious Correlations for Aspect-Based Sentiment Analysis with Variational Information Bottleneck and Contrastive Learning
Mar 12, 2023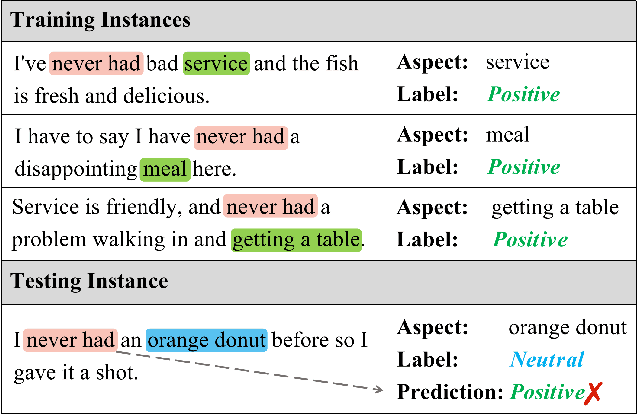

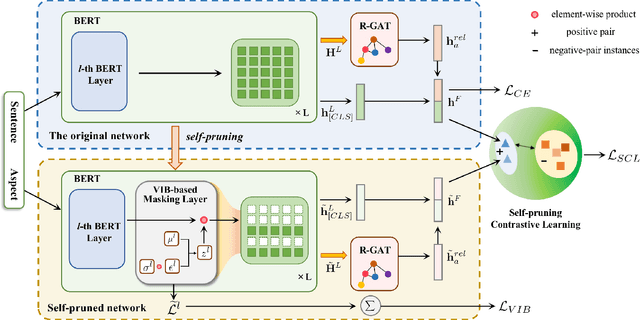
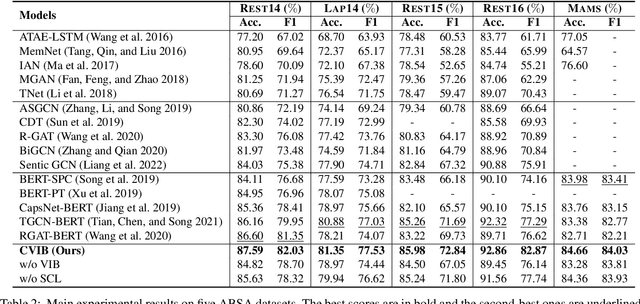
Deep learning techniques have dominated the literature on aspect-based sentiment analysis (ABSA), yielding state-of-the-art results. However, these deep models generally suffer from spurious correlation problems between input features and output labels, which creates significant barriers to robustness and generalization capability. In this paper, we propose a novel Contrastive Variational Information Bottleneck framework (called CVIB) to reduce spurious correlations for ABSA. The proposed CVIB framework is composed of an original network and a self-pruned network, and these two networks are optimized simultaneously via contrastive learning. Concretely, we employ the Variational Information Bottleneck (VIB) principle to learn an informative and compressed network (self-pruned network) from the original network, which discards the superfluous patterns or spurious correlations between input features and prediction labels. Then, self-pruning contrastive learning is devised to pull together semantically similar positive pairs and push away dissimilar pairs, where the representations of the anchor learned by the original and self-pruned networks respectively are regarded as a positive pair while the representations of two different sentences within a mini-batch are treated as a negative pair. To verify the effectiveness of our CVIB method, we conduct extensive experiments on five benchmark ABSA datasets and the experimental results show that our approach achieves better performance than the strong competitors in terms of overall prediction performance, robustness, and generalization.
Causality between Sentiment and Cryptocurrency Prices
Jun 09, 2023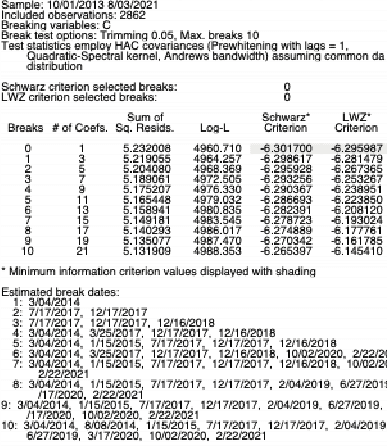
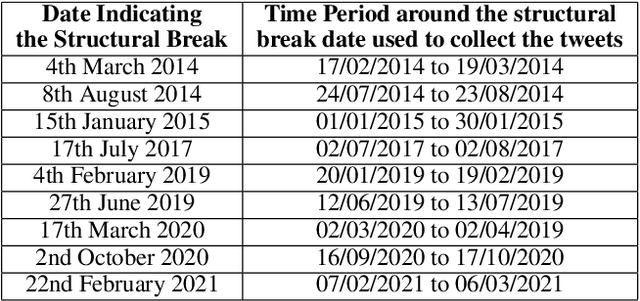
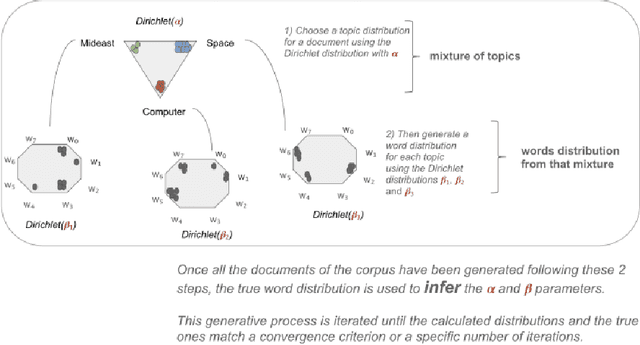
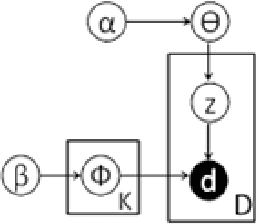
This study investigates the relationship between narratives conveyed through microblogging platforms, namely Twitter, and the value of crypto assets. Our study provides a unique technique to build narratives about cryptocurrency by combining topic modelling of short texts with sentiment analysis. First, we used an unsupervised machine learning algorithm to discover the latent topics within the massive and noisy textual data from Twitter, and then we revealed 4-5 cryptocurrency-related narratives, including financial investment, technological advancement related to crypto, financial and political regulations, crypto assets, and media coverage. In a number of situations, we noticed a strong link between our narratives and crypto prices. Our work connects the most recent innovation in economics, Narrative Economics, to a new area of study that combines topic modelling and sentiment analysis to relate consumer behaviour to narratives.
Comparative Study of Sentiment Analysis for Multi-Sourced Social Media Platforms
Dec 09, 2022
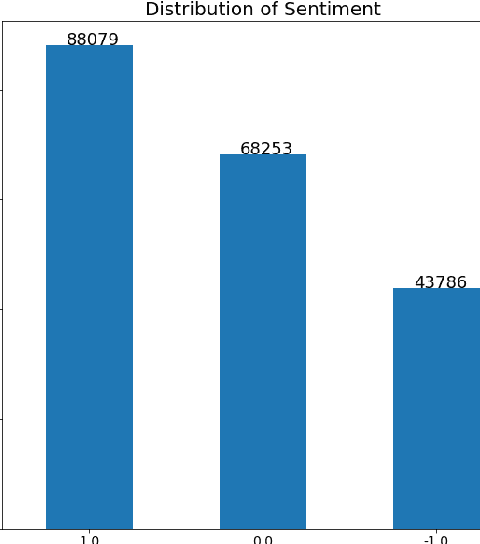
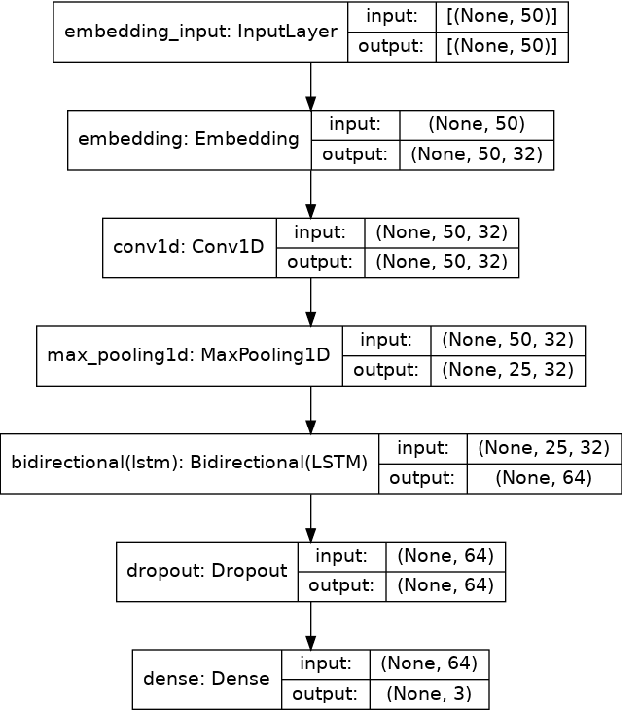

There is a vast amount of data generated every second due to the rapidly growing technology in the current world. This area of research attempts to determine the feelings or opinions of people on social media posts. The dataset we used was a multi-source dataset from the comment section of various social networking sites like Twitter, Reddit, etc. Natural Language Processing Techniques were employed to perform sentiment analysis on the obtained dataset. In this paper, we provide a comparative analysis using techniques of lexicon-based, machine learning and deep learning approaches. The Machine Learning algorithm used in this work is Naive Bayes, the Lexicon-based approach used in this work is TextBlob, and the deep-learning algorithm used in this work is LSTM.
Analysis of the Evolution of Advanced Transformer-Based Language Models: Experiments on Opinion Mining
Aug 07, 2023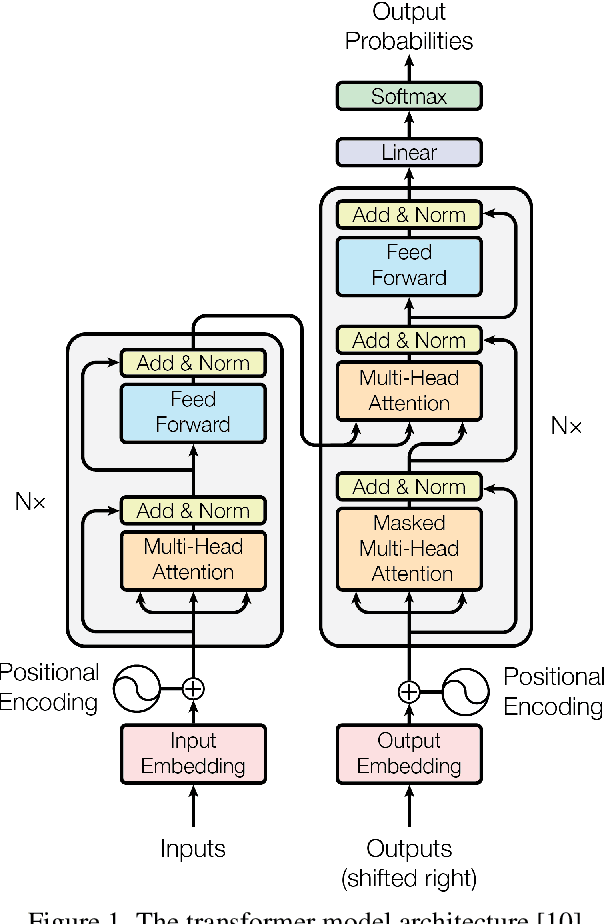
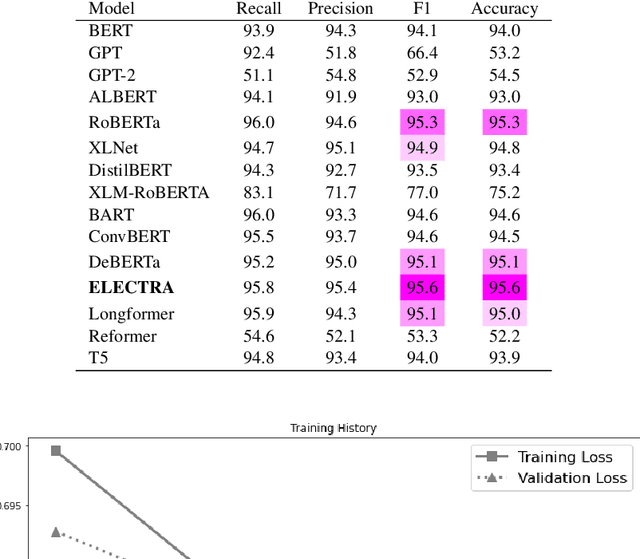
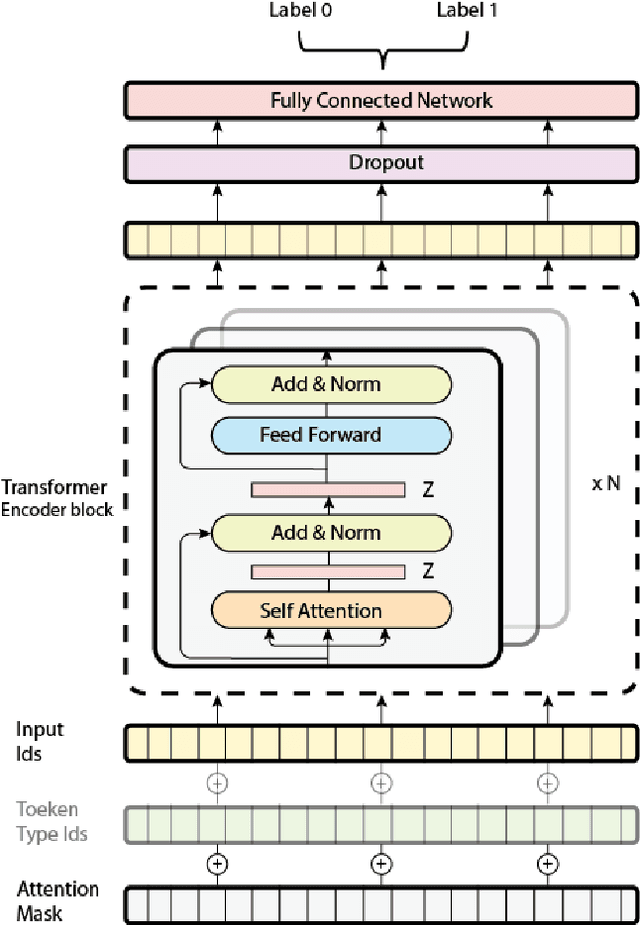
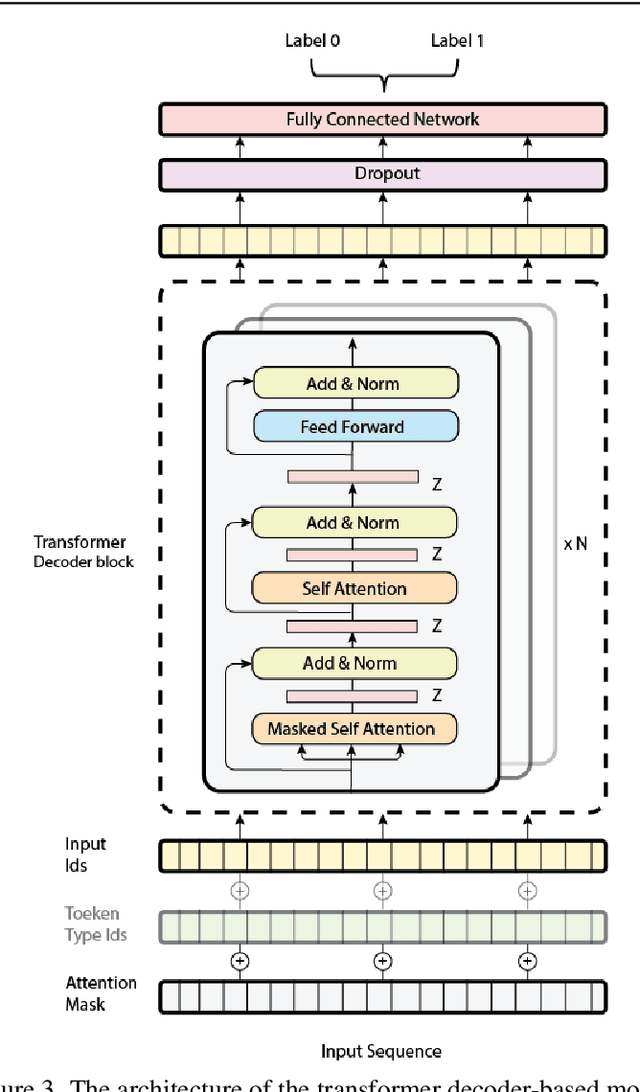
Opinion mining, also known as sentiment analysis, is a subfield of natural language processing (NLP) that focuses on identifying and extracting subjective information in textual material. This can include determining the overall sentiment of a piece of text (e.g., positive or negative), as well as identifying specific emotions or opinions expressed in the text, that involves the use of advanced machine and deep learning techniques. Recently, transformer-based language models make this task of human emotion analysis intuitive, thanks to the attention mechanism and parallel computation. These advantages make such models very powerful on linguistic tasks, unlike recurrent neural networks that spend a lot of time on sequential processing, making them prone to fail when it comes to processing long text. The scope of our paper aims to study the behaviour of the cutting-edge Transformer-based language models on opinion mining and provide a high-level comparison between them to highlight their key particularities. Additionally, our comparative study shows leads and paves the way for production engineers regarding the approach to focus on and is useful for researchers as it provides guidelines for future research subjects.
DN at SemEval-2023 Task 12: Low-Resource Language Text Classification via Multilingual Pretrained Language Model Fine-tuning
May 04, 2023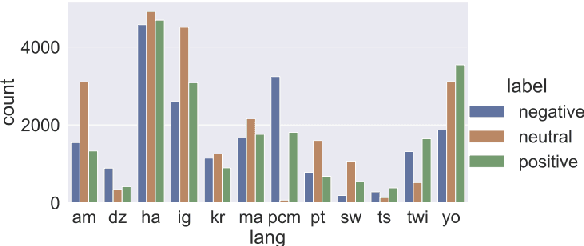
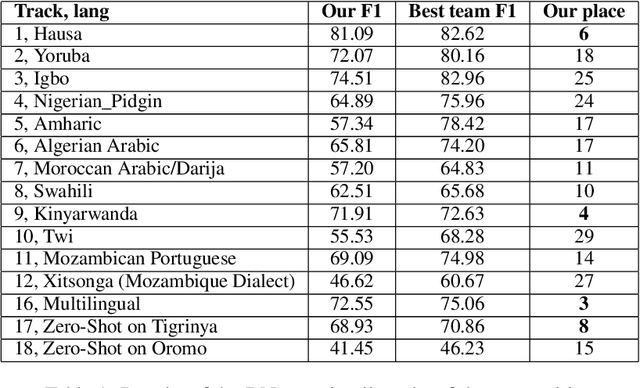
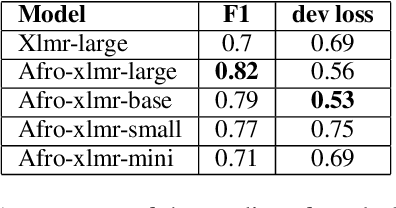
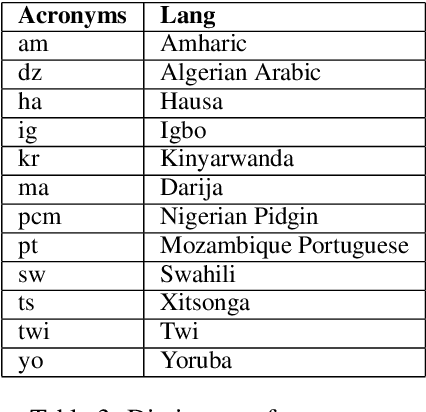
In recent years, sentiment analysis has gained significant importance in natural language processing. However, most existing models and datasets for sentiment analysis are developed for high-resource languages, such as English and Chinese, leaving low-resource languages, particularly African languages, largely unexplored. The AfriSenti-SemEval 2023 Shared Task 12 aims to fill this gap by evaluating sentiment analysis models on low-resource African languages. In this paper, we present our solution to the shared task, where we employed different multilingual XLM-R models with classification head trained on various data, including those retrained in African dialects and fine-tuned on target languages. Our team achieved the third-best results in Subtask B, Track 16: Multilingual, demonstrating the effectiveness of our approach. While our model showed relatively good results on multilingual data, it performed poorly in some languages. Our findings highlight the importance of developing more comprehensive datasets and models for low-resource African languages to advance sentiment analysis research. We also provided the solution on the github repository.
UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition
Nov 21, 2022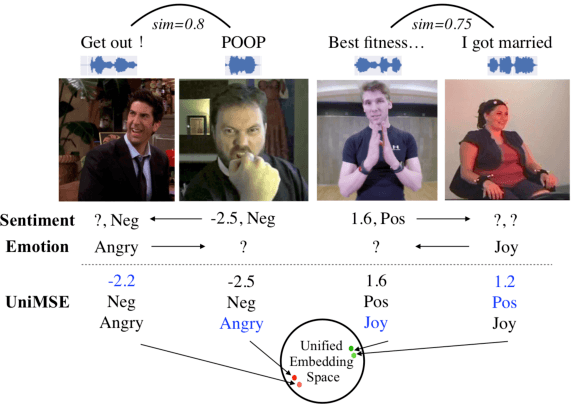
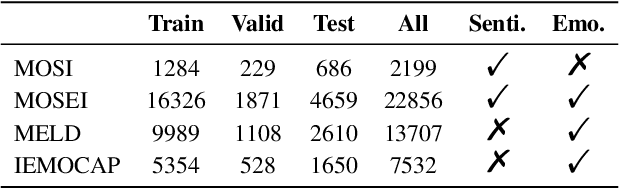
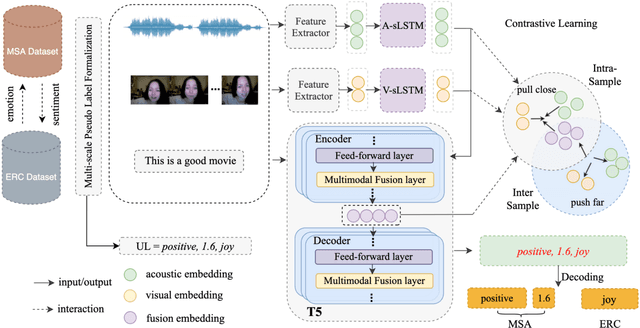
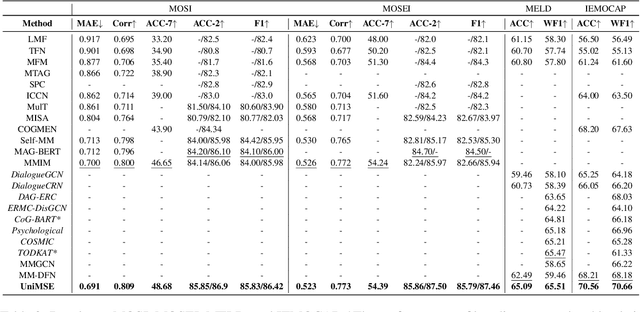
Multimodal sentiment analysis (MSA) and emotion recognition in conversation (ERC) are key research topics for computers to understand human behaviors. From a psychological perspective, emotions are the expression of affect or feelings during a short period, while sentiments are formed and held for a longer period. However, most existing works study sentiment and emotion separately and do not fully exploit the complementary knowledge behind the two. In this paper, we propose a multimodal sentiment knowledge-sharing framework (UniMSE) that unifies MSA and ERC tasks from features, labels, and models. We perform modality fusion at the syntactic and semantic levels and introduce contrastive learning between modalities and samples to better capture the difference and consistency between sentiments and emotions. Experiments on four public benchmark datasets, MOSI, MOSEI, MELD, and IEMOCAP, demonstrate the effectiveness of the proposed method and achieve consistent improvements compared with state-of-the-art methods.
Video-based Cross-modal Auxiliary Network for Multimodal Sentiment Analysis
Aug 30, 2022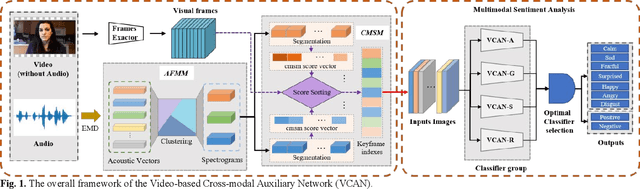
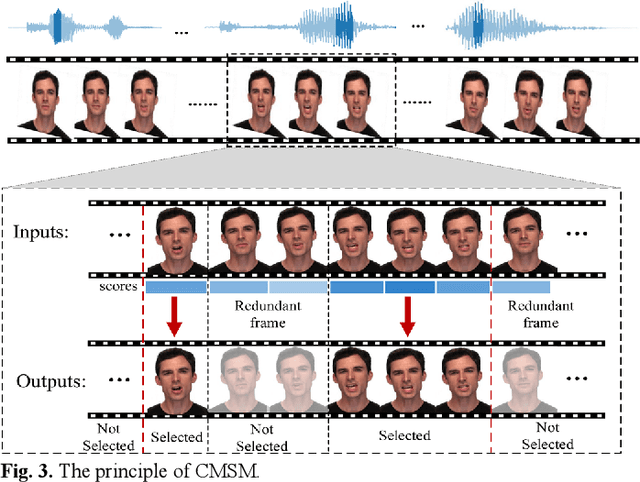
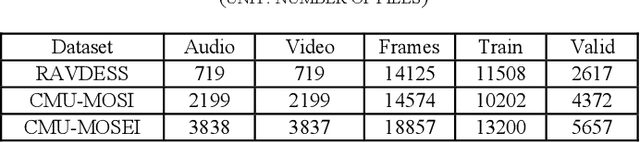
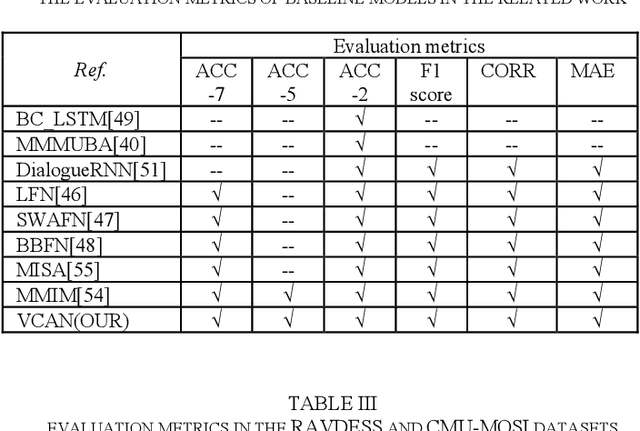
Multimodal sentiment analysis has a wide range of applications due to its information complementarity in multimodal interactions. Previous works focus more on investigating efficient joint representations, but they rarely consider the insufficient unimodal features extraction and data redundancy of multimodal fusion. In this paper, a Video-based Cross-modal Auxiliary Network (VCAN) is proposed, which is comprised of an audio features map module and a cross-modal selection module. The first module is designed to substantially increase feature diversity in audio feature extraction, aiming to improve classification accuracy by providing more comprehensive acoustic representations. To empower the model to handle redundant visual features, the second module is addressed to efficiently filter the redundant visual frames during integrating audiovisual data. Moreover, a classifier group consisting of several image classification networks is introduced to predict sentiment polarities and emotion categories. Extensive experimental results on RAVDESS, CMU-MOSI, and CMU-MOSEI benchmarks indicate that VCAN is significantly superior to the state-of-the-art methods for improving the classification accuracy of multimodal sentiment analysis.
Emoji Prediction using Transformer Models
Jul 16, 2023
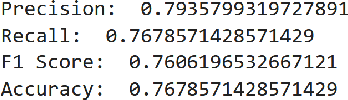
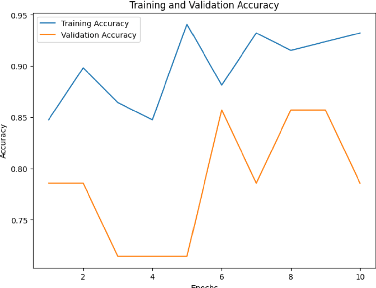
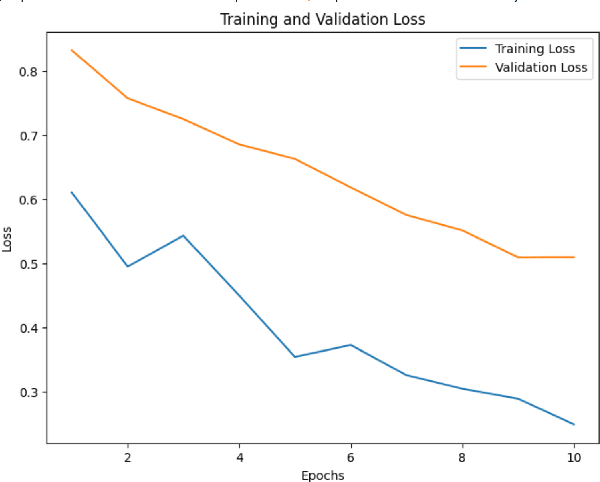
In recent years, the use of emojis in social media has increased dramatically, making them an important element in understanding online communication. However, predicting the meaning of emojis in a given text is a challenging task due to their ambiguous nature. In this study, we propose a transformer-based approach for emoji prediction using BERT, a widely-used pre-trained language model. We fine-tuned BERT on a large corpus of text containing both text and emojis to predict the most appropriate emoji for a given text. Our experimental results demonstrate that our approach outperforms several state-of-the-art models in predicting emojis with an accuracy of over 75 percent. This work has potential applications in natural language processing, sentiment analysis, and social media marketing.