 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
The ParlaSent multilingual training dataset for sentiment identification in parliamentary proceedings
Sep 18, 2023
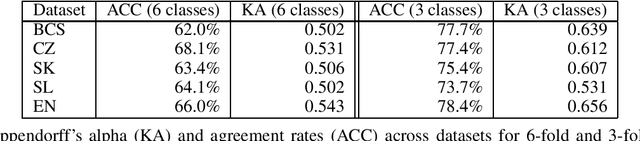
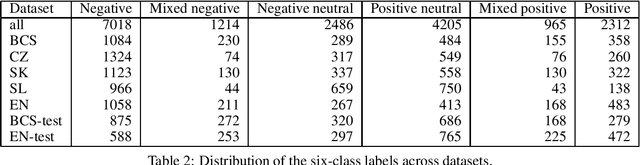
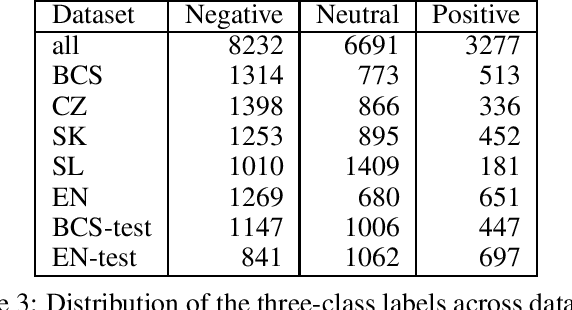
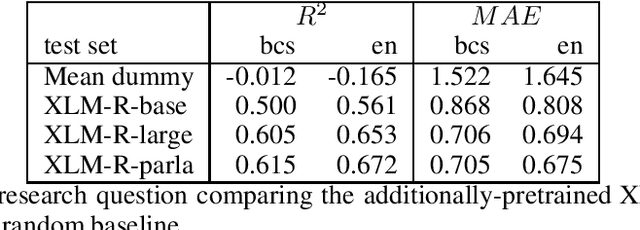
Sentiments inherently drive politics. How we receive and process information plays an essential role in political decision-making, shaping our judgment with strategic consequences both on the level of legislators and the masses. If sentiment plays such an important role in politics, how can we study and measure it systematically? The paper presents a new dataset of sentiment-annotated sentences, which are used in a series of experiments focused on training a robust sentiment classifier for parliamentary proceedings. The paper also introduces the first domain-specific LLM for political science applications additionally pre-trained on 1.72 billion domain-specific words from proceedings of 27 European parliaments. We present experiments demonstrating how the additional pre-training of LLM on parliamentary data can significantly improve the model downstream performance on the domain-specific tasks, in our case, sentiment detection in parliamentary proceedings. We further show that multilingual models perform very well on unseen languages and that additional data from other languages significantly improves the target parliament's results. The paper makes an important contribution to multiple domains of social sciences and bridges them with computer science and computational linguistics. Lastly, it sets up a more robust approach to sentiment analysis of political texts in general, which allows scholars to study political sentiment from a comparative perspective using standardized tools and techniques.
CONFLATOR: Incorporating Switching Point based Rotatory Positional Encodings for Code-Mixed Language Modeling
Sep 11, 2023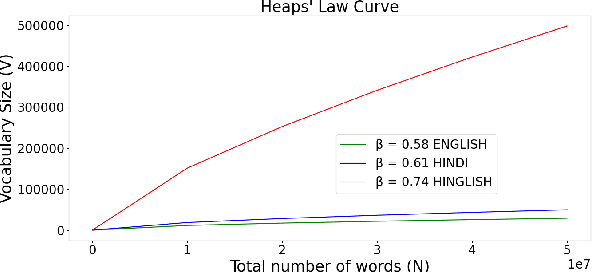
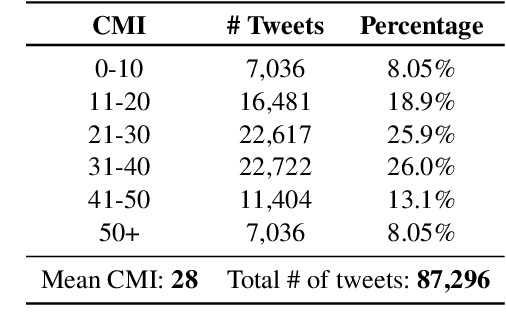
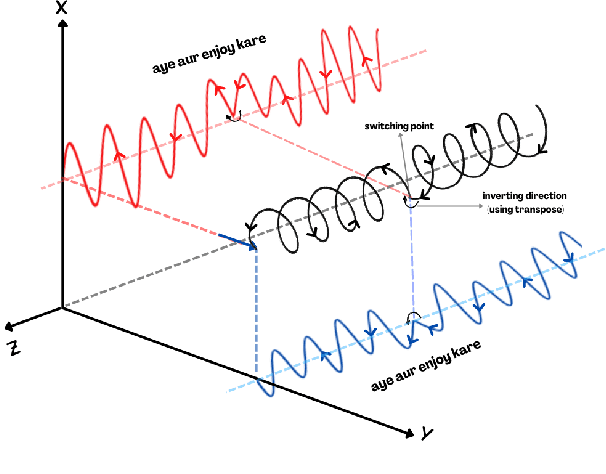
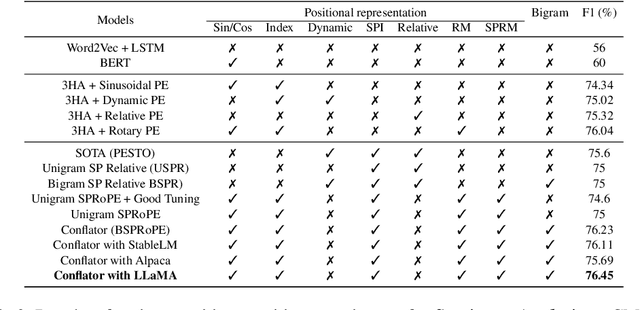
The mixing of two or more languages is called Code-Mixing (CM). CM is a social norm in multilingual societies. Neural Language Models (NLMs) like transformers have been very effective on many NLP tasks. However, NLM for CM is an under-explored area. Though transformers are capable and powerful, they cannot always encode positional/sequential information since they are non-recurrent. Therefore, to enrich word information and incorporate positional information, positional encoding is defined. We hypothesize that Switching Points (SPs), i.e., junctions in the text where the language switches (L1 -> L2 or L2-> L1), pose a challenge for CM Language Models (LMs), and hence give special emphasis to switching points in the modeling process. We experiment with several positional encoding mechanisms and show that rotatory positional encodings along with switching point information yield the best results. We introduce CONFLATOR: a neural language modeling approach for code-mixed languages. CONFLATOR tries to learn to emphasize switching points using smarter positional encoding, both at unigram and bigram levels. CONFLATOR outperforms the state-of-the-art on two tasks based on code-mixed Hindi and English (Hinglish): (i) sentiment analysis and (ii) machine translation.
Impact of Sentiment Analysis in Fake Review Detection
Dec 18, 2022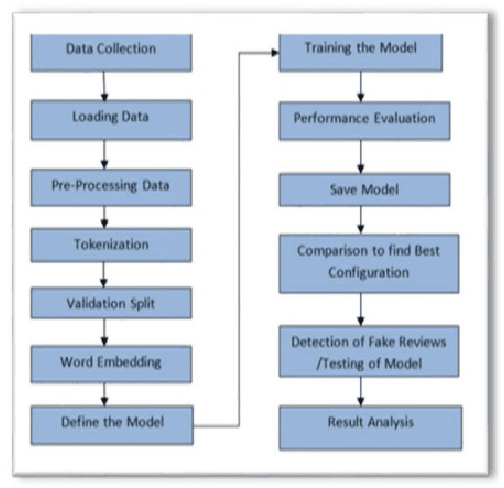
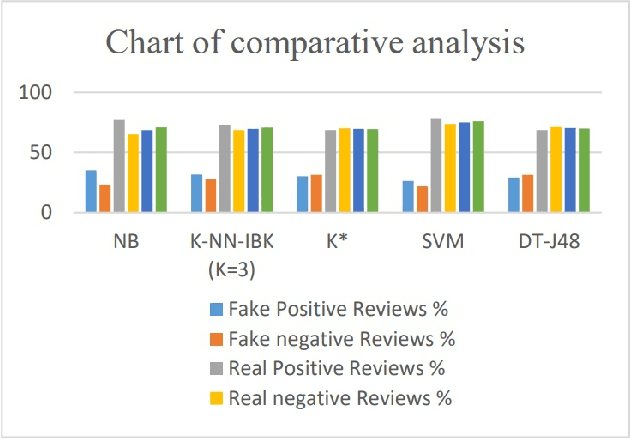
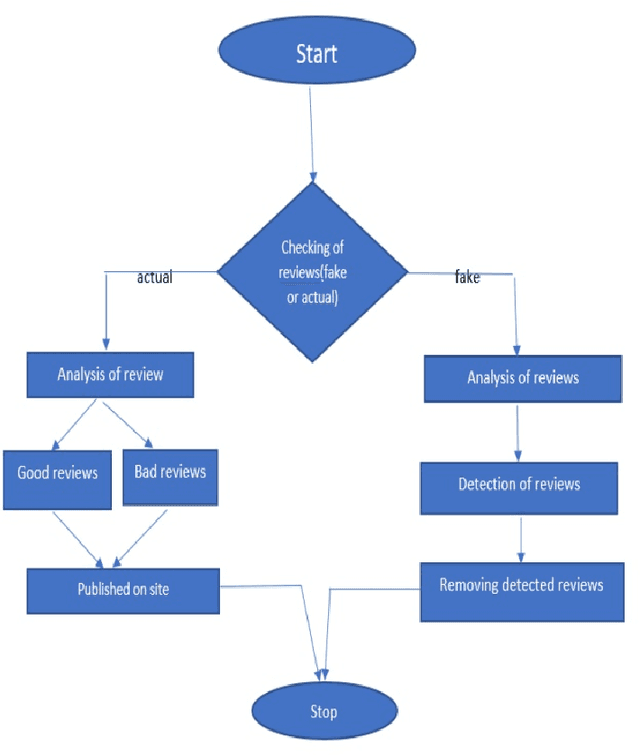

Fake review identification is an important topic and has gained the interest of experts all around the world. Identifying fake reviews is challenging for researchers, and there are several primary challenges to fake review detection. We propose developing an initial research paper for investigating fake reviews by using sentiment analysis. Ten research papers are identified that show fake reviews, and they discuss currently available solutions for predicting or detecting fake reviews. They also show the distribution of fake and truthful reviews through the analysis of sentiment. We summarize and compare previous studies related to fake reviews. We highlight the most significant challenges in the sentiment evaluation process and demonstrate that there is a significant impact on sentiment scores used to identify fake feedback.
The MuSe 2023 Multimodal Sentiment Analysis Challenge: Mimicked Emotions, Cross-Cultural Humour, and Personalisation
May 05, 2023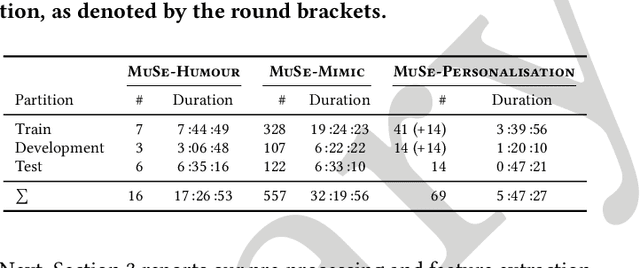
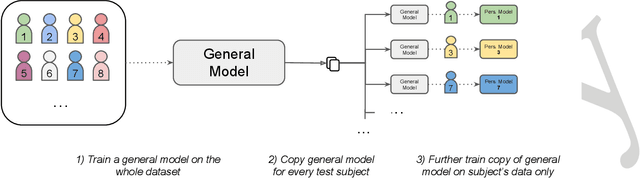
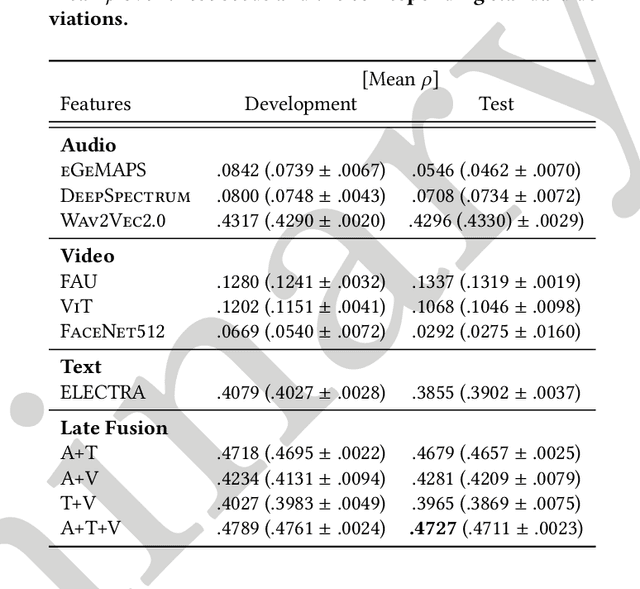
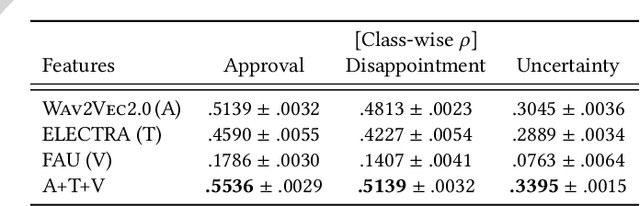
The MuSe 2023 is a set of shared tasks addressing three different contemporary multimodal affect and sentiment analysis problems: In the Mimicked Emotions Sub-Challenge (MuSe-Mimic), participants predict three continuous emotion targets. This sub-challenge utilises the Hume-Vidmimic dataset comprising of user-generated videos. For the Cross-Cultural Humour Detection Sub-Challenge (MuSe-Humour), an extension of the Passau Spontaneous Football Coach Humour (Passau-SFCH) dataset is provided. Participants predict the presence of spontaneous humour in a cross-cultural setting. The Personalisation Sub-Challenge (MuSe-Personalisation) is based on the Ulm-Trier Social Stress Test (Ulm-TSST) dataset, featuring recordings of subjects in a stressed situation. Here, arousal and valence signals are to be predicted, whereas parts of the test labels are made available in order to facilitate personalisation. MuSe 2023 seeks to bring together a broad audience from different research communities such as audio-visual emotion recognition, natural language processing, signal processing, and health informatics. In this baseline paper, we introduce the datasets, sub-challenges, and provided feature sets. As a competitive baseline system, a Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) is employed. On the respective sub-challenges' test datasets, it achieves a mean (across three continuous intensity targets) Pearson's Correlation Coefficient of .4727 for MuSe-Mimic, an Area Under the Curve (AUC) value of .8310 for MuSe-Humor and Concordance Correlation Coefficient (CCC) values of .7482 for arousal and .7827 for valence in the MuSe-Personalisation sub-challenge.
Social Media, Topic Modeling and Sentiment Analysis in Municipal Decision Support
Aug 08, 2023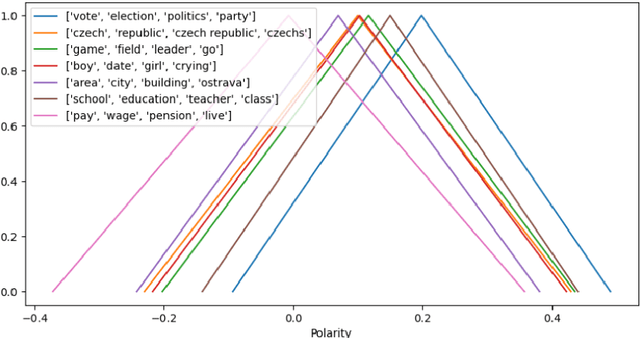
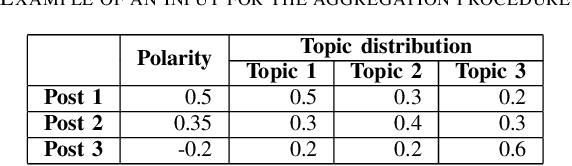

Many cities around the world are aspiring to become. However, smart initiatives often give little weight to the opinions of average citizens. Social media are one of the most important sources of citizen opinions. This paper presents a prototype of a framework for processing social media posts with municipal decision-making in mind. The framework consists of a sequence of three steps: (1) determining the sentiment polarity of each social media post (2) identifying prevalent topics and mapping these topics to individual posts, and (3) aggregating these two pieces of information into a fuzzy number representing the overall sentiment expressed towards each topic. Optionally, the fuzzy number can be reduced into a tuple of two real numbers indicating the "amount" of positive and negative opinion expressed towards each topic. The framework is demonstrated on tweets published from Ostrava, Czechia over a period of about two months. This application illustrates how fuzzy numbers represent sentiment in a richer way and capture the diversity of opinions expressed on social media.
An Integrated NPL Approach to Sentiment Analysis in Satisfaction Surveys
Aug 02, 2023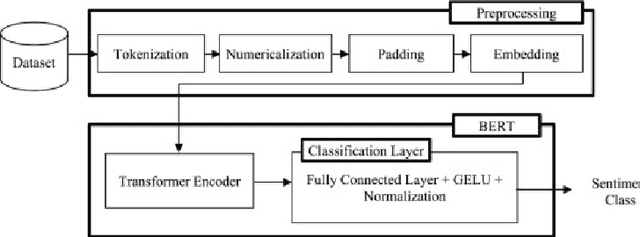
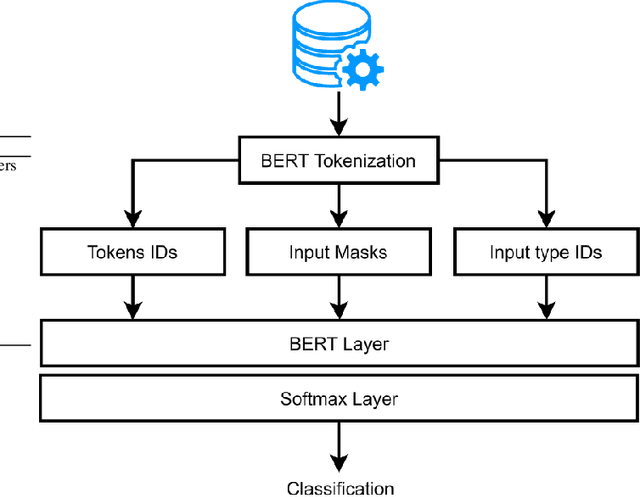
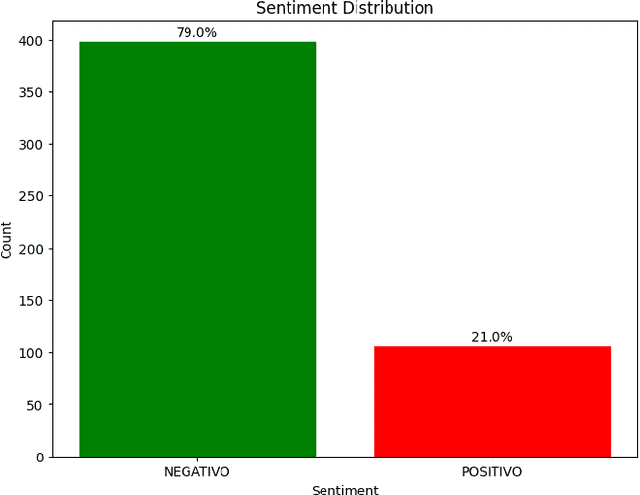

The research project aims to apply an integrated approach to natural language processing NLP to satisfaction surveys. It will focus on understanding and extracting relevant information from survey responses, analyzing feelings, and identifying recurring word patterns. NLP techniques will be used to determine emotional polarity, classify responses into positive, negative, or neutral categories, and use opinion mining to highlight participants opinions. This approach will help identify the most relevant aspects for participants and understand their opinions in relation to those specific aspects. A key component of the research project will be the analysis of word patterns in satisfaction survey responses using NPL. This analysis will provide a deeper understanding of feelings, opinions, and themes and trends present in respondents responses. The results obtained from this approach can be used to identify areas for improvement, understand respondents preferences, and make strategic decisions based on analysis to improve respondent satisfaction.
LSTM based models stability in the context of Sentiment Analysis for social media
Nov 21, 2022
Deep learning techniques have proven their effectiveness for Sentiment Analysis (SA) related tasks. Recurrent neural networks (RNN), especially Long Short-Term Memory (LSTM) and Bidirectional LSTM, have become a reference for building accurate predictive models. However, the models complexity and the number of hyperparameters to configure raises several questions related to their stability. In this paper, we present various LSTM models and their key parameters, and we perform experiments to test the stability of these models in the context of Sentiment Analysis.
On the Robustness of Aspect-based Sentiment Analysis: Rethinking Model, Data, and Training
Apr 19, 2023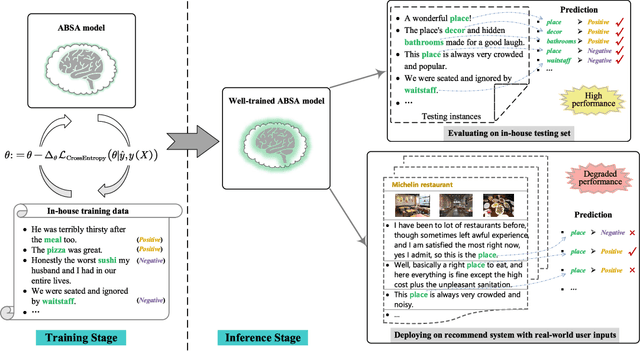


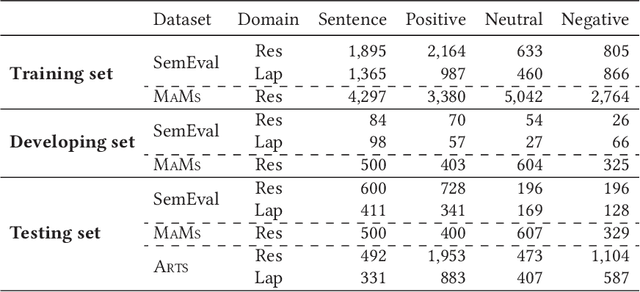
Aspect-based sentiment analysis (ABSA) aims at automatically inferring the specific sentiment polarities toward certain aspects of products or services behind the social media texts or reviews, which has been a fundamental application to the real-world society. Since the early 2010s, ABSA has achieved extraordinarily high accuracy with various deep neural models. However, existing ABSA models with strong in-house performances may fail to generalize to some challenging cases where the contexts are variable, i.e., low robustness to real-world environments. In this study, we propose to enhance the ABSA robustness by systematically rethinking the bottlenecks from all possible angles, including model, data, and training. First, we strengthen the current best-robust syntax-aware models by further incorporating the rich external syntactic dependencies and the labels with aspect simultaneously with a universal-syntax graph convolutional network. In the corpus perspective, we propose to automatically induce high-quality synthetic training data with various types, allowing models to learn sufficient inductive bias for better robustness. Last, we based on the rich pseudo data perform adversarial training to enhance the resistance to the context perturbation and meanwhile employ contrastive learning to reinforce the representations of instances with contrastive sentiments. Extensive robustness evaluations are conducted. The results demonstrate that our enhanced syntax-aware model achieves better robustness performances than all the state-of-the-art baselines. By additionally incorporating our synthetic corpus, the robust testing results are pushed with around 10% accuracy, which are then further improved by installing the advanced training strategies. In-depth analyses are presented for revealing the factors influencing the ABSA robustness.
Mere Contrastive Learning for Cross-Domain Sentiment Analysis
Aug 18, 2022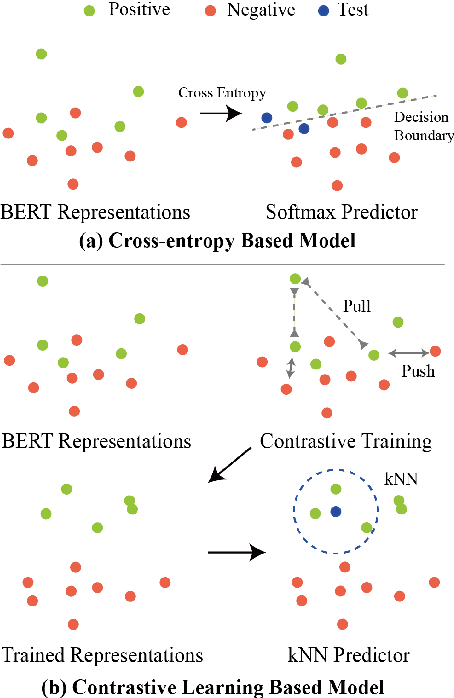
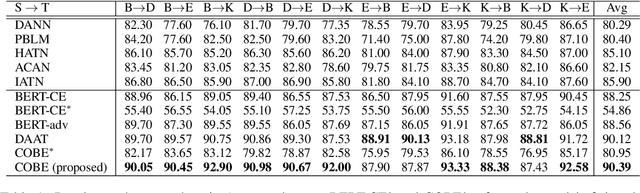
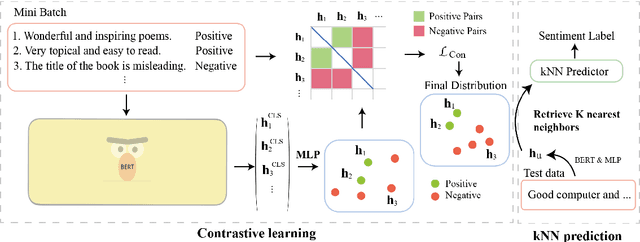
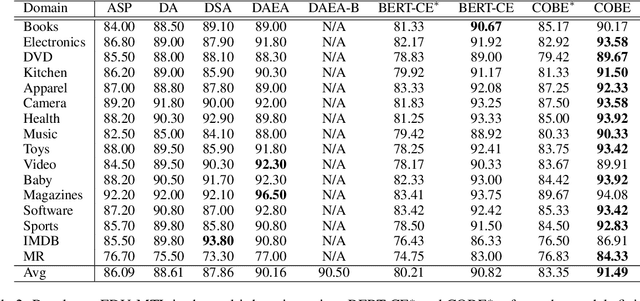
Cross-domain sentiment analysis aims to predict the sentiment of texts in the target domain using the model trained on the source domain to cope with the scarcity of labeled data. Previous studies are mostly cross-entropy-based methods for the task, which suffer from instability and poor generalization. In this paper, we explore contrastive learning on the cross-domain sentiment analysis task. We propose a modified contrastive objective with in-batch negative samples so that the sentence representations from the same class will be pushed close while those from the different classes become further apart in the latent space. Experiments on two widely used datasets show that our model can achieve state-of-the-art performance in both cross-domain and multi-domain sentiment analysis tasks. Meanwhile, visualizations demonstrate the effectiveness of transferring knowledge learned in the source domain to the target domain and the adversarial test verifies the robustness of our model.
A multiclass Q-NLP sentiment analysis experiment using DisCoCat
Sep 07, 2022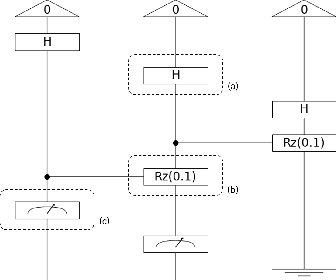


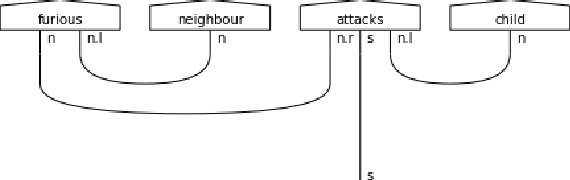
Sentiment analysis is a branch of Natural Language Processing (NLP) which goal is to assign sentiments or emotions to particular sentences or words. Performing this task is particularly useful for companies wishing to take into account customer feedback through chatbots or verbatim. This has been done extensively in the literature using various approaches, ranging from simple models to deep transformer neural networks. In this paper, we will tackle sentiment analysis in the Noisy Intermediate Scale Computing (NISQ) era, using the DisCoCat model of language. We will first present the basics of quantum computing and the DisCoCat model. This will enable us to define a general framework to perform NLP tasks on a quantum computer. We will then extend the two-class classification that was performed by Lorenz et al. (2021) to a four-class sentiment analysis experiment on a much larger dataset, showing the scalability of such a framework.