 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Multi-Purpose NLP Chatbot : Design, Methodology & Conclusion
Oct 13, 2023
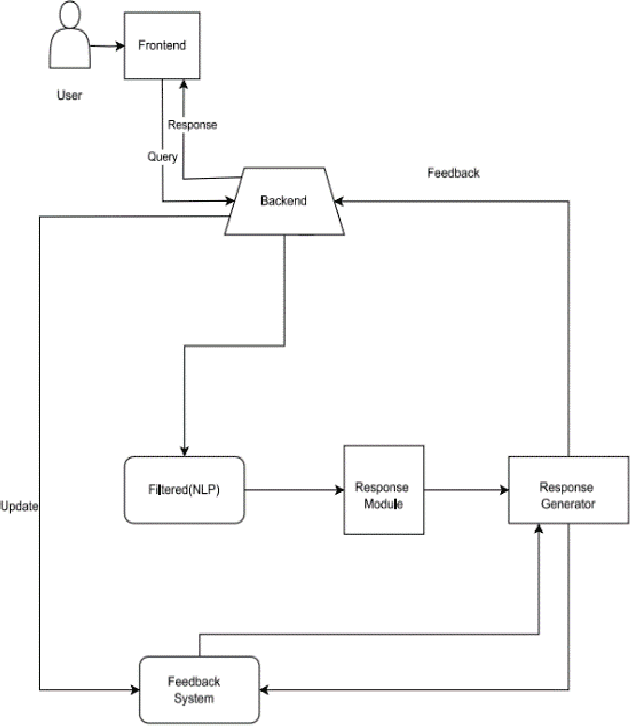
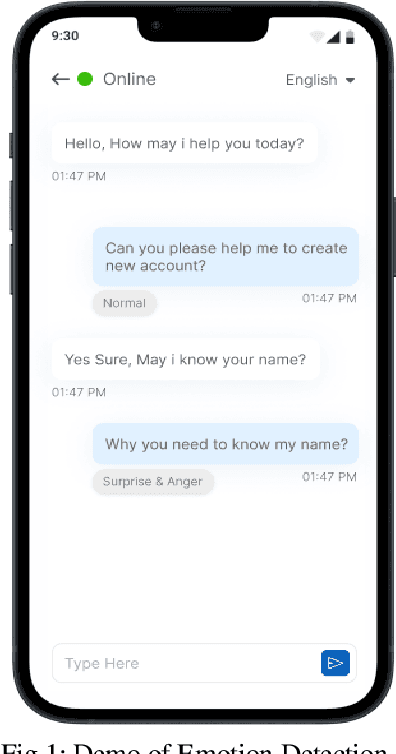
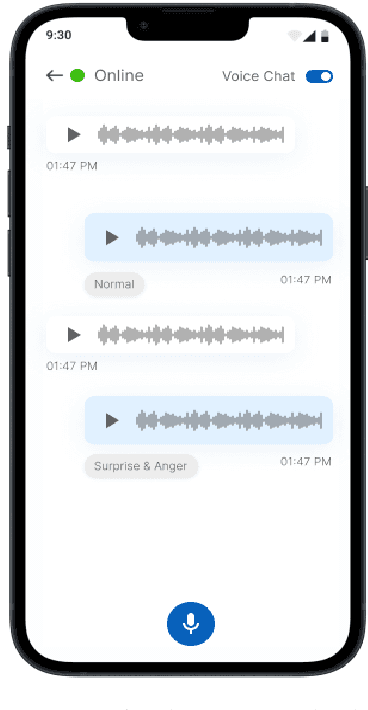
With a major focus on its history, difficulties, and promise, this research paper provides a thorough analysis of the chatbot technology environment as it exists today. It provides a very flexible chatbot system that makes use of reinforcement learning strategies to improve user interactions and conversational experiences. Additionally, this system makes use of sentiment analysis and natural language processing to determine user moods. The chatbot is a valuable tool across many fields thanks to its amazing characteristics, which include voice-to-voice conversation, multilingual support [12], advising skills, offline functioning, and quick help features. The complexity of chatbot technology development is also explored in this study, along with the causes that have propelled these developments and their far-reaching effects on a range of sectors. According to the study, three crucial elements are crucial: 1) Even without explicit profile information, the chatbot system is built to adeptly understand unique consumer preferences and fluctuating satisfaction levels. With the use of this capacity, user interactions are made to meet their wants and preferences. 2) Using a complex method that interlaces Multiview voice chat information, the chatbot may precisely simulate users' actual experiences. This aids in developing more genuine and interesting discussions. 3) The study presents an original method for improving the black-box deep learning models' capacity for prediction. This improvement is made possible by introducing dynamic satisfaction measurements that are theory-driven, which leads to more precise forecasts of consumer reaction.
GMNLP at SemEval-2023 Task 12: Sentiment Analysis with Phylogeny-Based Adapters
Apr 25, 2023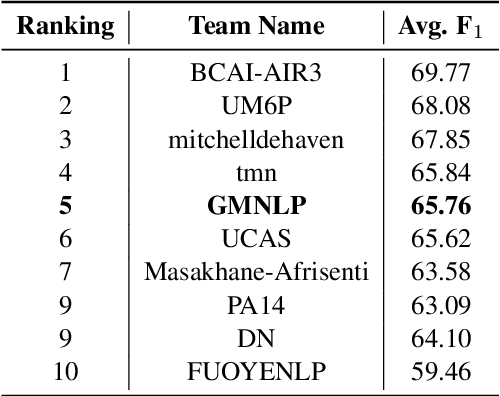

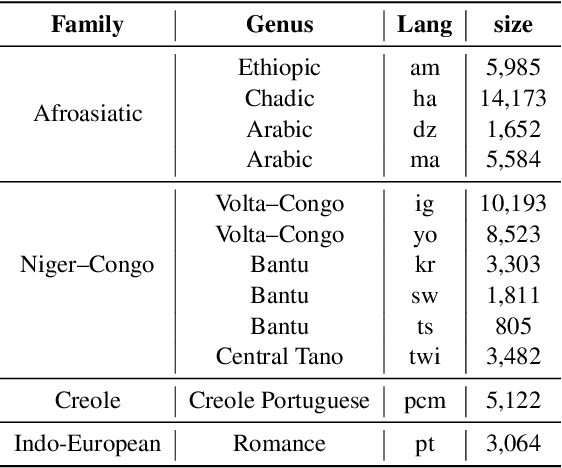
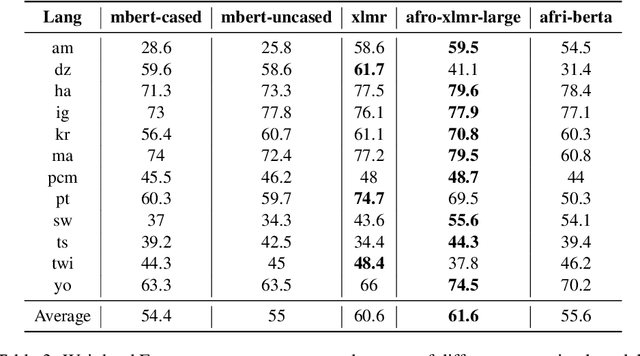
This report describes GMU's sentiment analysis system for the SemEval-2023 shared task AfriSenti-SemEval. We participated in all three sub-tasks: Monolingual, Multilingual, and Zero-Shot. Our approach uses models initialized with AfroXLMR-large, a pre-trained multilingual language model trained on African languages and fine-tuned correspondingly. We also introduce augmented training data along with original training data. Alongside finetuning, we perform phylogeny-based adapter tuning to create several models and ensemble the best models for the final submission. Our system achieves the best F1-score on track 5: Amharic, with 6.2 points higher F1-score than the second-best performing system on this track. Overall, our system ranks 5th among the 10 systems participating in all 15 tracks.
SemEval-2023 Task 12: Sentiment Analysis for African Languages (AfriSenti-SemEval)
May 01, 2023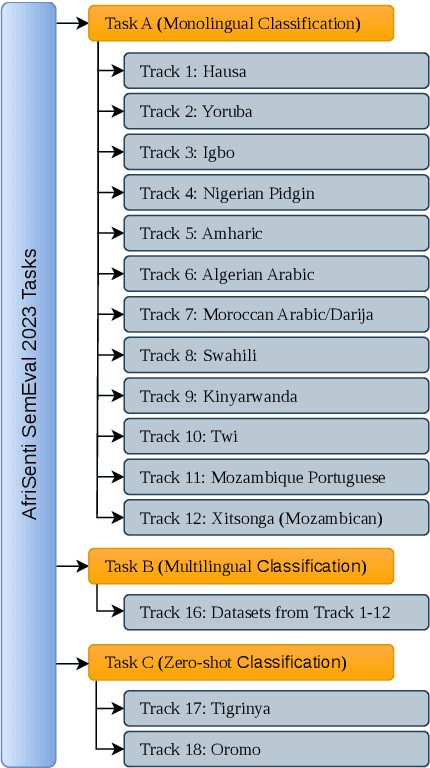
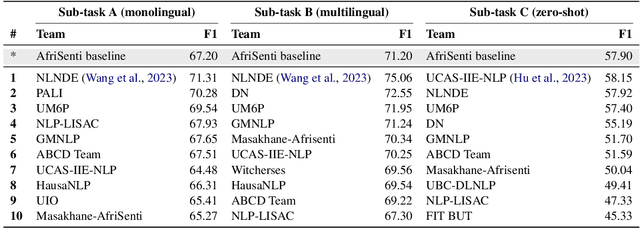
We present the first Africentric SemEval Shared task, Sentiment Analysis for African Languages (AfriSenti-SemEval) - The dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023. AfriSenti-SemEval is a sentiment classification challenge in 14 African languages: Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a (Muhammad et al., 2023), using data labeled with 3 sentiment classes. We present three subtasks: (1) Task A: monolingual classification, which received 44 submissions; (2) Task B: multilingual classification, which received 32 submissions; and (3) Task C: zero-shot classification, which received 34 submissions. The best performance for tasks A and B was achieved by NLNDE team with 71.31 and 75.06 weighted F1, respectively. UCAS-IIE-NLP achieved the best average score for task C with 58.15 weighted F1. We describe the various approaches adopted by the top 10 systems and their approaches.
DeBERTinha: A Multistep Approach to Adapt DebertaV3 XSmall for Brazilian Portuguese Natural Language Processing Task
Sep 28, 2023This paper presents an approach for adapting the DebertaV3 XSmall model pre-trained in English for Brazilian Portuguese natural language processing (NLP) tasks. A key aspect of the methodology involves a multistep training process to ensure the model is effectively tuned for the Portuguese language. Initial datasets from Carolina and BrWac are preprocessed to address issues like emojis, HTML tags, and encodings. A Portuguese-specific vocabulary of 50,000 tokens is created using SentencePiece. Rather than training from scratch, the weights of the pre-trained English model are used to initialize most of the network, with random embeddings, recognizing the expensive cost of training from scratch. The model is fine-tuned using the replaced token detection task in the same format of DebertaV3 training. The adapted model, called DeBERTinha, demonstrates effectiveness on downstream tasks like named entity recognition, sentiment analysis, and determining sentence relatedness, outperforming BERTimbau-Large in two tasks despite having only 40M parameters.
FinGPT: Instruction Tuning Benchmark for Open-Source Large Language Models in Financial Datasets
Oct 07, 2023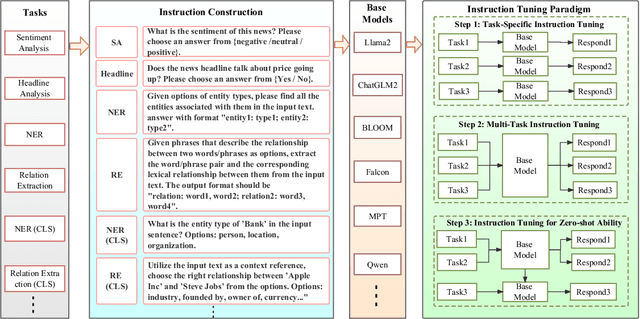
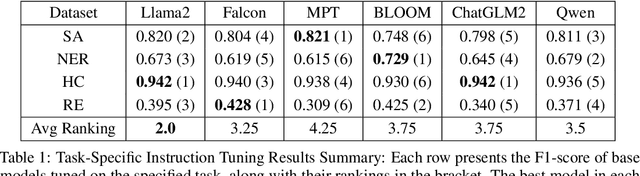
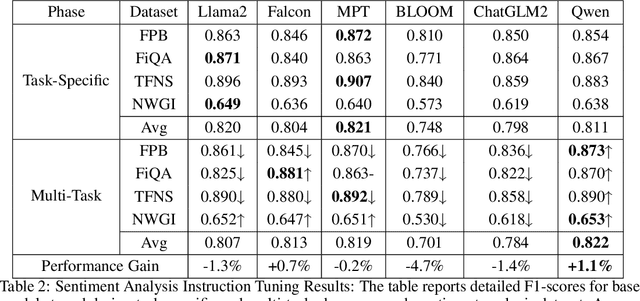
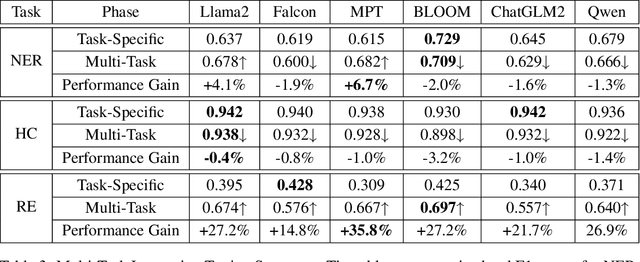
In the swiftly expanding domain of Natural Language Processing (NLP), the potential of GPT-based models for the financial sector is increasingly evident. However, the integration of these models with financial datasets presents challenges, notably in determining their adeptness and relevance. This paper introduces a distinctive approach anchored in the Instruction Tuning paradigm for open-source large language models, specifically adapted for financial contexts. Through this methodology, we capitalize on the interoperability of open-source models, ensuring a seamless and transparent integration. We begin by explaining the Instruction Tuning paradigm, highlighting its effectiveness for immediate integration. The paper presents a benchmarking scheme designed for end-to-end training and testing, employing a cost-effective progression. Firstly, we assess basic competencies and fundamental tasks, such as Named Entity Recognition (NER) and sentiment analysis to enhance specialization. Next, we delve into a comprehensive model, executing multi-task operations by amalgamating all instructional tunings to examine versatility. Finally, we explore the zero-shot capabilities by earmarking unseen tasks and incorporating novel datasets to understand adaptability in uncharted terrains. Such a paradigm fortifies the principles of openness and reproducibility, laying a robust foundation for future investigations in open-source financial large language models (FinLLMs).
Large-Scale Korean Text Dataset for Classifying Biased Speech in Real-World Online Services
Oct 06, 2023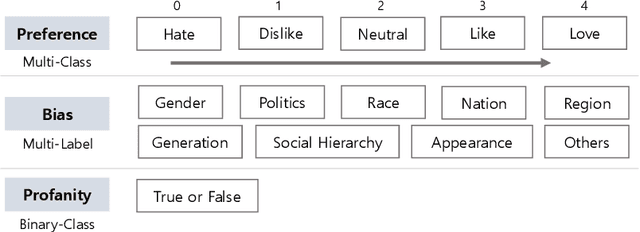
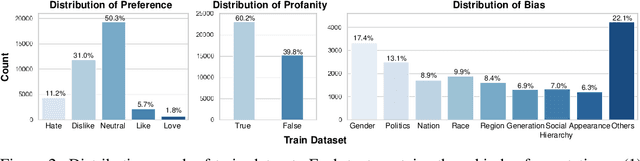
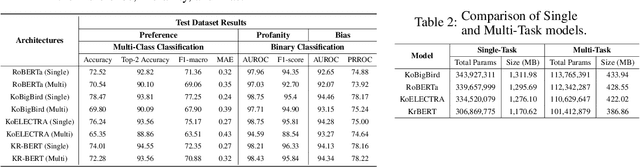

With the growth of online services, the need for advanced text classification algorithms, such as sentiment analysis and biased text detection, has become increasingly evident. The anonymous nature of online services often leads to the presence of biased and harmful language, posing challenges to maintaining the health of online communities. This phenomenon is especially relevant in South Korea, where large-scale hate speech detection algorithms have not yet been broadly explored. In this paper, we introduce a new comprehensive, large-scale dataset collected from a well-known South Korean SNS platform. Our proposed dataset provides annotations including (1) Preferences, (2) Profanities, and (3) Nine types of Bias for the text samples, enabling multi-task learning for simultaneous classification of user-generated texts. Leveraging state-of-the-art BERT-based language models, our approach surpasses human-level accuracy across diverse classification tasks, as measured by various metrics. Beyond academic contributions, our work can provide practical solutions for real-world hate speech and bias mitigation, contributing directly to the improvement of online community health. Our work provides a robust foundation for future research aiming to improve the quality of online discourse and foster societal well-being. All source codes and datasets are publicly accessible at https://github.com/Dasol-Choi/KoMultiText.
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Oct 06, 2023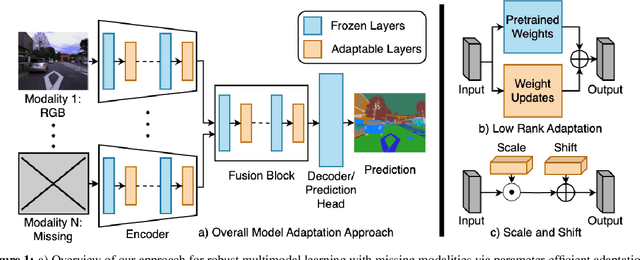
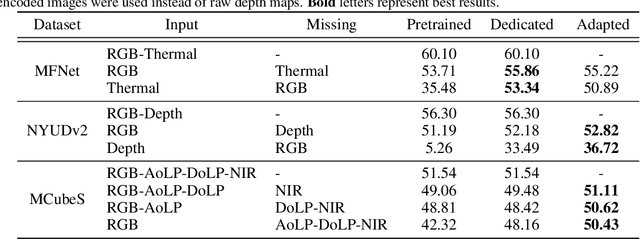
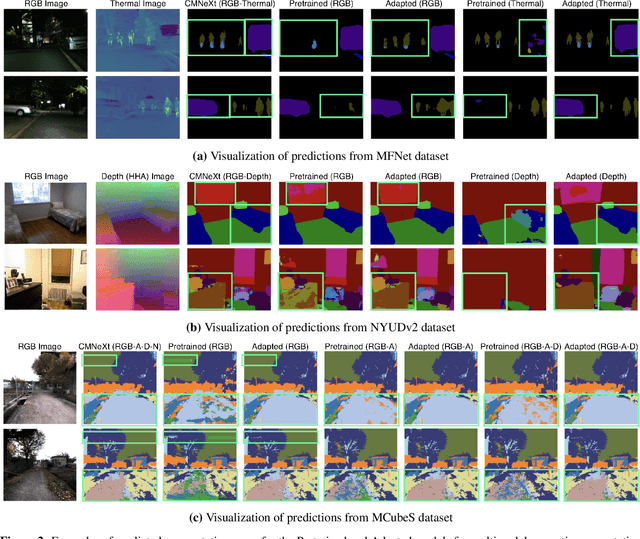
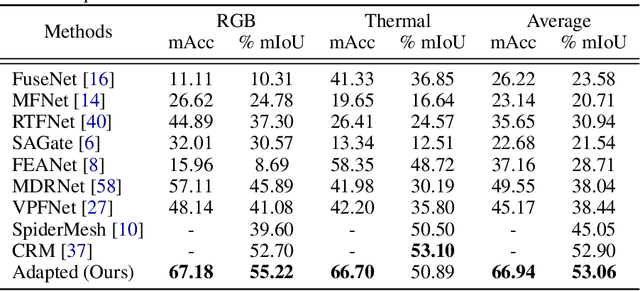
Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose simple and parameter-efficient adaptation procedures for pretrained multimodal networks. In particular, we exploit low-rank adaptation and modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 0.7% of the total parameters in most experiments). We conduct a series of experiments to highlight the robustness of our proposed method using diverse datasets for RGB-thermal and RGB-Depth semantic segmentation, multimodal material segmentation, and multimodal sentiment analysis tasks. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.
Exploring Sentiment Analysis Techniques in Natural Language Processing: A Comprehensive Review
May 24, 2023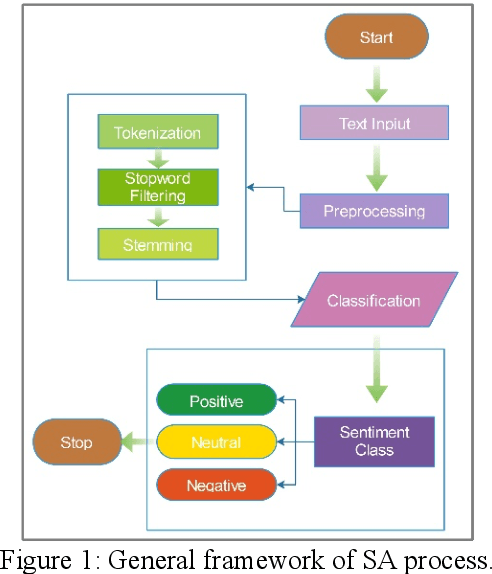
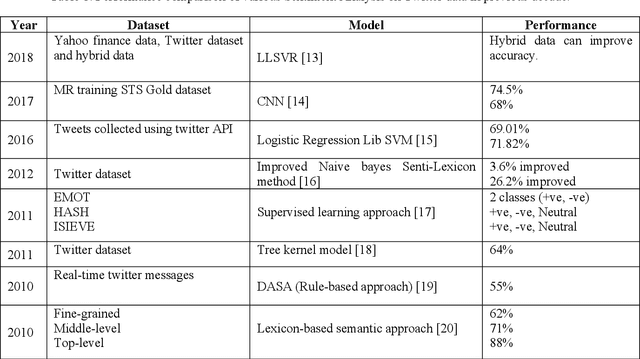
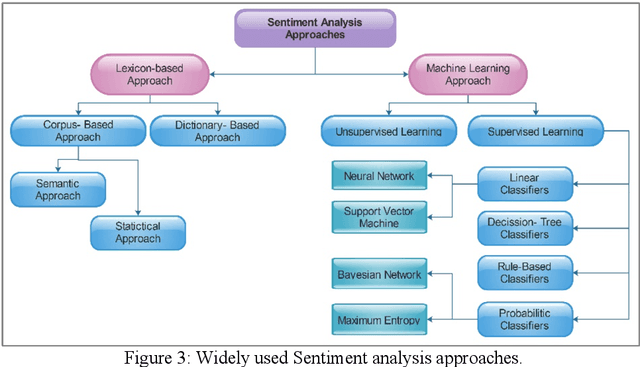
Sentiment analysis (SA) is the automated process of detecting and understanding the emotions conveyed through written text. Over the past decade, SA has gained significant popularity in the field of Natural Language Processing (NLP). With the widespread use of social media and online platforms, SA has become crucial for companies to gather customer feedback and shape their marketing strategies. Additionally, researchers rely on SA to analyze public sentiment on various topics. In this particular research study, a comprehensive survey was conducted to explore the latest trends and techniques in SA. The survey encompassed a wide range of methods, including lexicon-based, graph-based, network-based, machine learning, deep learning, ensemble-based, rule-based, and hybrid techniques. The paper also addresses the challenges and opportunities in SA, such as dealing with sarcasm and irony, analyzing multi-lingual data, and addressing ethical concerns. To provide a practical case study, Twitter was chosen as one of the largest online social media platforms. Furthermore, the researchers shed light on the diverse application areas of SA, including social media, healthcare, marketing, finance, and politics. The paper also presents a comparative and comprehensive analysis of existing trends and techniques, datasets, and evaluation metrics. The ultimate goal is to offer researchers and practitioners a systematic review of SA techniques, identify existing gaps, and suggest possible improvements. This study aims to enhance the efficiency and accuracy of SA processes, leading to smoother and error-free outcomes.
BenLLMEval: A Comprehensive Evaluation into the Potentials and Pitfalls of Large Language Models on Bengali NLP
Sep 22, 2023
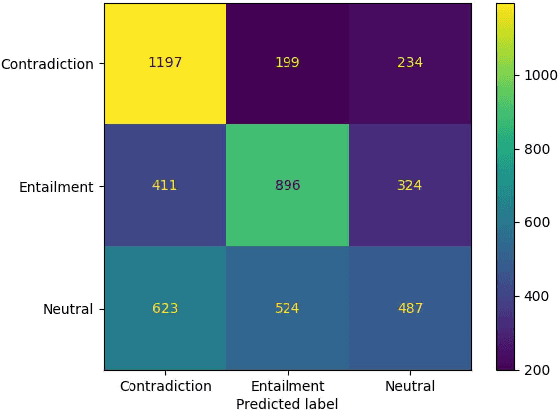
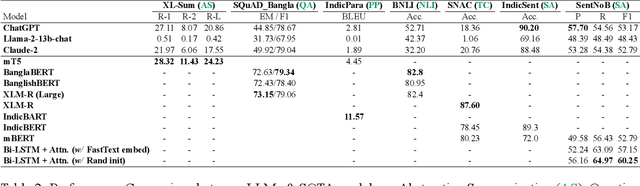

Large Language Models (LLMs) have emerged as one of the most important breakthroughs in natural language processing (NLP) for their impressive skills in language generation and other language-specific tasks. Though LLMs have been evaluated in various tasks, mostly in English, they have not yet undergone thorough evaluation in under-resourced languages such as Bengali (Bangla). In this paper, we evaluate the performance of LLMs for the low-resourced Bangla language. We select various important and diverse Bangla NLP tasks, such as abstractive summarization, question answering, paraphrasing, natural language inference, text classification, and sentiment analysis for zero-shot evaluation with ChatGPT, LLaMA-2, and Claude-2 and compare the performance with state-of-the-art fine-tuned models. Our experimental results demonstrate an inferior performance of LLMs for different Bangla NLP tasks, calling for further effort to develop better understanding of LLMs in low-resource languages like Bangla.
Leveraging Explainable AI to Analyze Researchers' Aspect-Based Sentiment about ChatGPT
Aug 16, 2023The groundbreaking invention of ChatGPT has triggered enormous discussion among users across all fields and domains. Among celebration around its various advantages, questions have been raised with regards to its correctness and ethics of its use. Efforts are already underway towards capturing user sentiments around it. But it begs the question as to how the research community is analyzing ChatGPT with regards to various aspects of its usage. It is this sentiment of the researchers that we analyze in our work. Since Aspect-Based Sentiment Analysis has usually only been applied on a few datasets, it gives limited success and that too only on short text data. We propose a methodology that uses Explainable AI to facilitate such analysis on research data. Our technique presents valuable insights into extending the state of the art of Aspect-Based Sentiment Analysis on newer datasets, where such analysis is not hampered by the length of the text data.