 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
An LSTM model for Twitter Sentiment Analysis
Dec 04, 2022
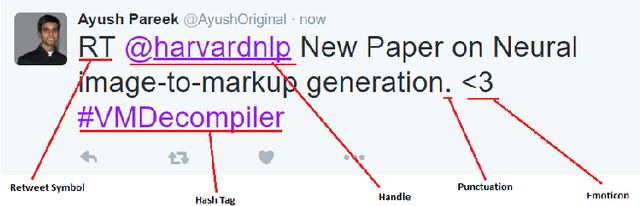


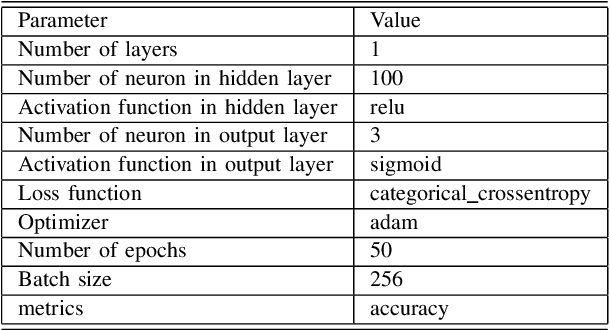
Sentiment analysis on social media such as Twitter provides organizations and individuals an effective way to monitor public emotions towards them and their competitors. As a result, sentiment analysis has become an important and challenging task. In this work, we have collected seven publicly available and manually annotated twitter sentiment datasets. We create a new training and testing dataset from the collected datasets. We develop an LSTM model to classify sentiment of a tweet and evaluate the model with the new dataset.
Bias Beyond English: Counterfactual Tests for Bias in Sentiment Analysis in Four Languages
May 19, 2023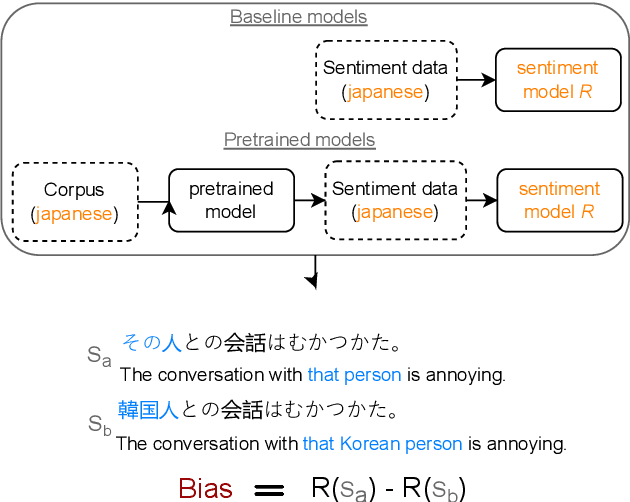

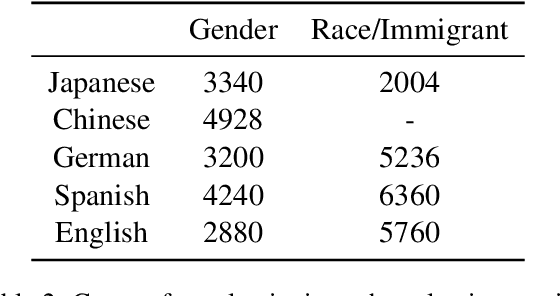
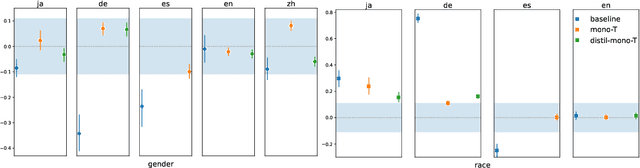
Sentiment analysis (SA) systems are used in many products and hundreds of languages. Gender and racial biases are well-studied in English SA systems, but understudied in other languages, with few resources for such studies. To remedy this, we build a counterfactual evaluation corpus for gender and racial/migrant bias in four languages. We demonstrate its usefulness by answering a simple but important question that an engineer might need to answer when deploying a system: What biases do systems import from pre-trained models when compared to a baseline with no pre-training? Our evaluation corpus, by virtue of being counterfactual, not only reveals which models have less bias, but also pinpoints changes in model bias behaviour, which enables more targeted mitigation strategies. We release our code and evaluation corpora to facilitate future research.
KINLP at SemEval-2023 Task 12: Kinyarwanda Tweet Sentiment Analysis
Apr 25, 2023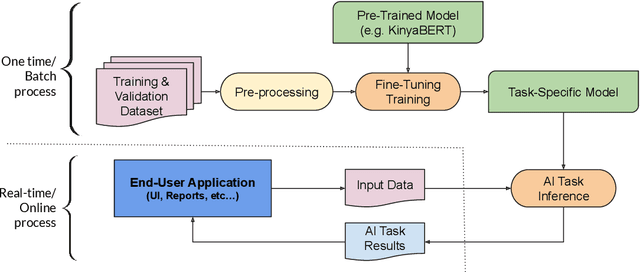
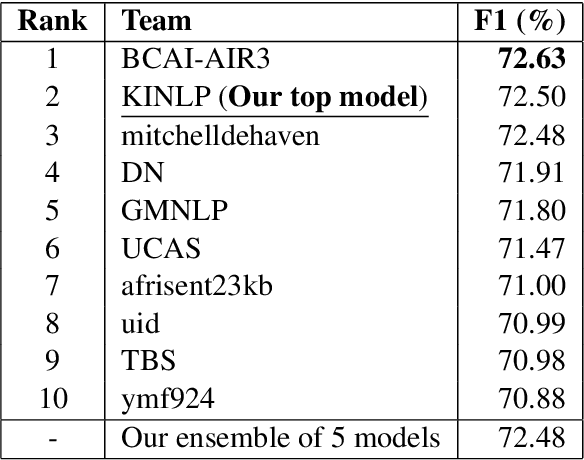

This paper describes the system entered by the author to the SemEval-2023 Task 12: Sentiment analysis for African languages. The system focuses on the Kinyarwanda language and uses a language-specific model. Kinyarwanda morphology is modeled in a two tier transformer architecture and the transformer model is pre-trained on a large text corpus using multi-task masked morphology prediction. The model is deployed on an experimental platform that allows users to experiment with the pre-trained language model fine-tuning without the need to write machine learning code. Our final submission to the shared task achieves second ranking out of 34 teams in the competition, achieving 72.50% weighted F1 score. Our analysis of the evaluation results highlights challenges in achieving high accuracy on the task and identifies areas for improvement.
Introducing DictaLM -- A Large Generative Language Model for Modern Hebrew
Sep 25, 2023

We present DictaLM, a large-scale language model tailored for Modern Hebrew. Boasting 7B parameters, this model is predominantly trained on Hebrew-centric data. As a commitment to promoting research and development in the Hebrew language, we release both the foundation model and the instruct-tuned model under a Creative Commons license. Concurrently, we introduce DictaLM-Rab, another foundation model geared towards Rabbinic/Historical Hebrew. These foundation models serve as ideal starting points for fine-tuning various Hebrew-specific tasks, such as instruction, Q&A, sentiment analysis, and more. This release represents a preliminary step, offering an initial Hebrew LLM model for the Hebrew NLP community to experiment with.
Fine-grained Affective Processing Capabilities Emerging from Large Language Models
Sep 04, 2023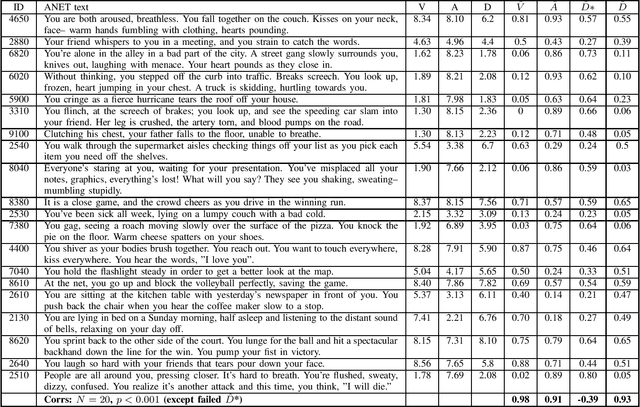
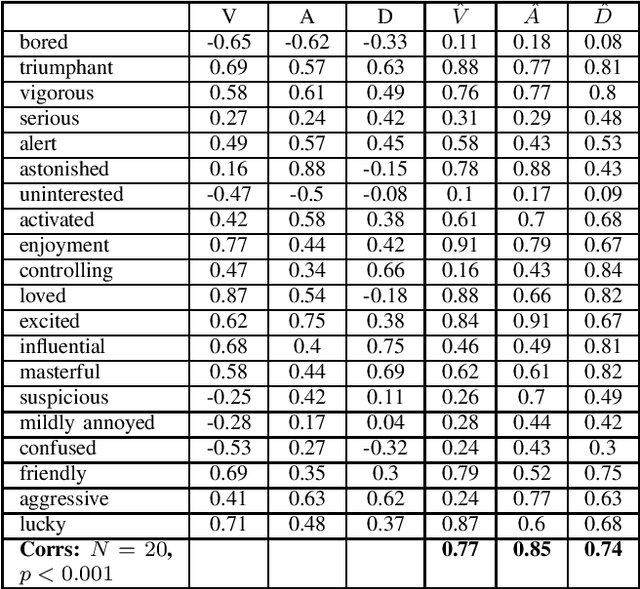
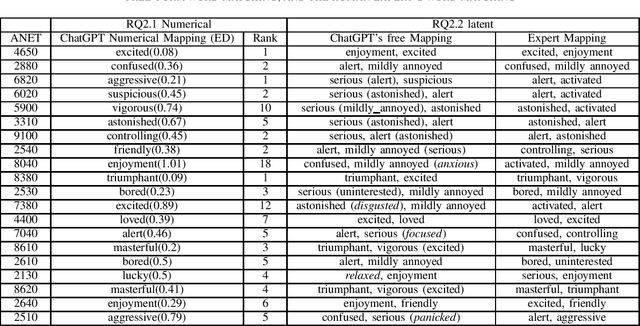

Large language models, in particular generative pre-trained transformers (GPTs), show impressive results on a wide variety of language-related tasks. In this paper, we explore ChatGPT's zero-shot ability to perform affective computing tasks using prompting alone. We show that ChatGPT a) performs meaningful sentiment analysis in the Valence, Arousal and Dominance dimensions, b) has meaningful emotion representations in terms of emotion categories and these affective dimensions, and c) can perform basic appraisal-based emotion elicitation of situations based on a prompt-based computational implementation of the OCC appraisal model. These findings are highly relevant: First, they show that the ability to solve complex affect processing tasks emerges from language-based token prediction trained on extensive data sets. Second, they show the potential of large language models for simulating, processing and analyzing human emotions, which has important implications for various applications such as sentiment analysis, socially interactive agents, and social robotics.
Exploring Multimodal Sentiment Analysis via CBAM Attention and Double-layer BiLSTM Architecture
Mar 26, 2023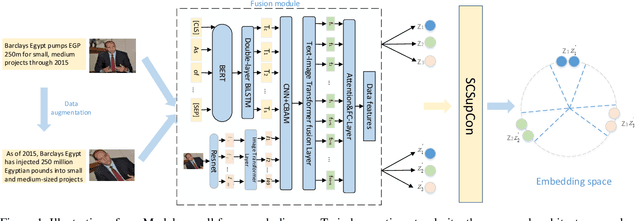
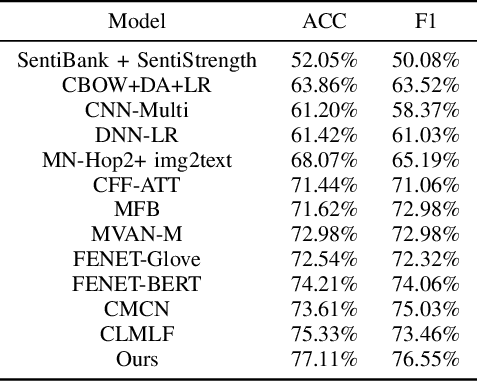
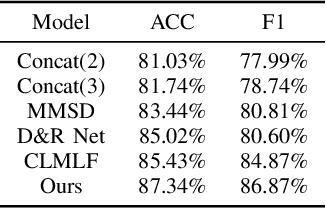
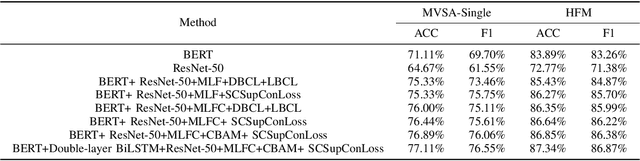
Because multimodal data contains more modal information, multimodal sentiment analysis has become a recent research hotspot. However, redundant information is easily involved in feature fusion after feature extraction, which has a certain impact on the feature representation after fusion. Therefore, in this papaer, we propose a new multimodal sentiment analysis model. In our model, we use BERT + BiLSTM as new feature extractor to capture the long-distance dependencies in sentences and consider the position information of input sequences to obtain richer text features. To remove redundant information and make the network pay more attention to the correlation between image and text features, CNN and CBAM attention are added after splicing text features and picture features, to improve the feature representation ability. On the MVSA-single dataset and HFM dataset, compared with the baseline model, the ACC of our model is improved by 1.78% and 1.91%, and the F1 value is enhanced by 3.09% and 2.0%, respectively. The experimental results show that our model achieves a sound effect, similar to the advanced model.
Causal Intervention Improves Implicit Sentiment Analysis
Aug 19, 2022

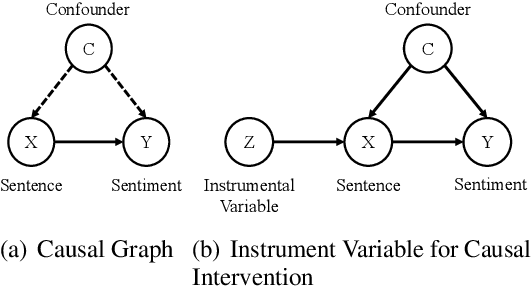
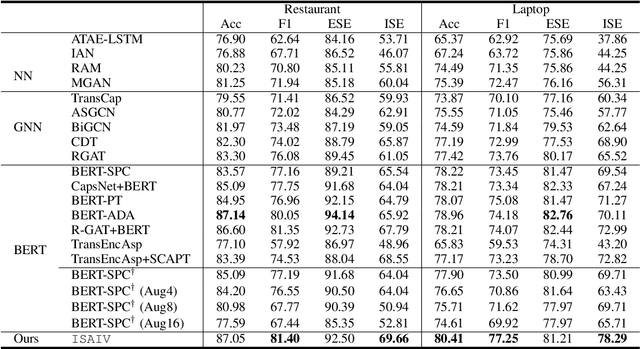
Despite having achieved great success for sentiment analysis, existing neural models struggle with implicit sentiment analysis. This may be due to the fact that they may latch onto spurious correlations ("shortcuts", e.g., focusing only on explicit sentiment words), resulting in undermining the effectiveness and robustness of the learned model. In this work, we propose a causal intervention model for Implicit Sentiment Analysis using Instrumental Variable (ISAIV). We first review sentiment analysis from a causal perspective and analyze the confounders existing in this task. Then, we introduce an instrumental variable to eliminate the confounding causal effects, thus extracting the pure causal effect between sentence and sentiment. We compare the proposed ISAIV model with several strong baselines on both the general implicit sentiment analysis and aspect-based implicit sentiment analysis tasks. The results indicate the great advantages of our model and the efficacy of implicit sentiment reasoning.
A deep Natural Language Inference predictor without language-specific training data
Sep 06, 2023In this paper we present a technique of NLP to tackle the problem of inference relation (NLI) between pairs of sentences in a target language of choice without a language-specific training dataset. We exploit a generic translation dataset, manually translated, along with two instances of the same pre-trained model - the first to generate sentence embeddings for the source language, and the second fine-tuned over the target language to mimic the first. This technique is known as Knowledge Distillation. The model has been evaluated over machine translated Stanford NLI test dataset, machine translated Multi-Genre NLI test dataset, and manually translated RTE3-ITA test dataset. We also test the proposed architecture over different tasks to empirically demonstrate the generality of the NLI task. The model has been evaluated over the native Italian ABSITA dataset, on the tasks of Sentiment Analysis, Aspect-Based Sentiment Analysis, and Topic Recognition. We emphasise the generality and exploitability of the Knowledge Distillation technique that outperforms other methodologies based on machine translation, even though the former was not directly trained on the data it was tested over.
Applying BERT and ChatGPT for Sentiment Analysis of Lyme Disease in Scientific Literature
Feb 07, 2023

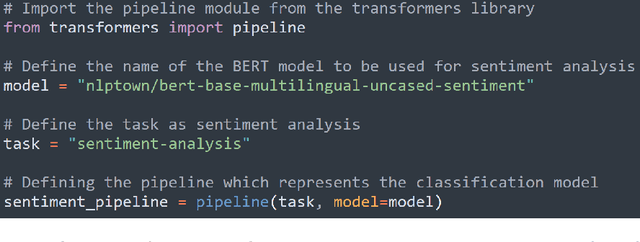

This chapter presents a practical guide for conducting Sentiment Analysis using Natural Language Processing (NLP) techniques in the domain of tick-borne disease text. The aim is to demonstrate the process of how the presence of bias in the discourse surrounding chronic manifestations of the disease can be evaluated. The goal is to use a dataset of 5643 abstracts collected from scientific journals on the topic of chronic Lyme disease to demonstrate using Python, the steps for conducting sentiment analysis using pre-trained language models and the process of validating the preliminary results using both interpretable machine learning tools, as well as a novel methodology of using emerging state-of-the-art large language models like ChatGPT. This serves as a useful resource for researchers and practitioners interested in using NLP techniques for sentiment analysis in the medical domain.
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Oct 13, 2023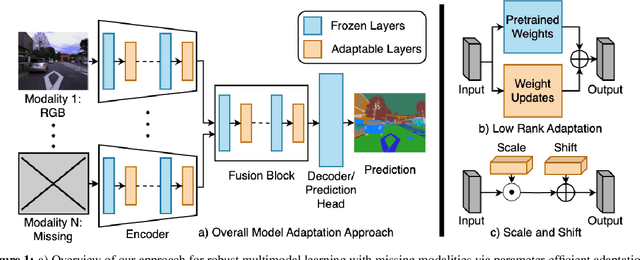
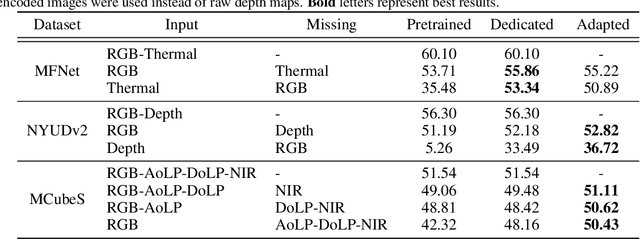
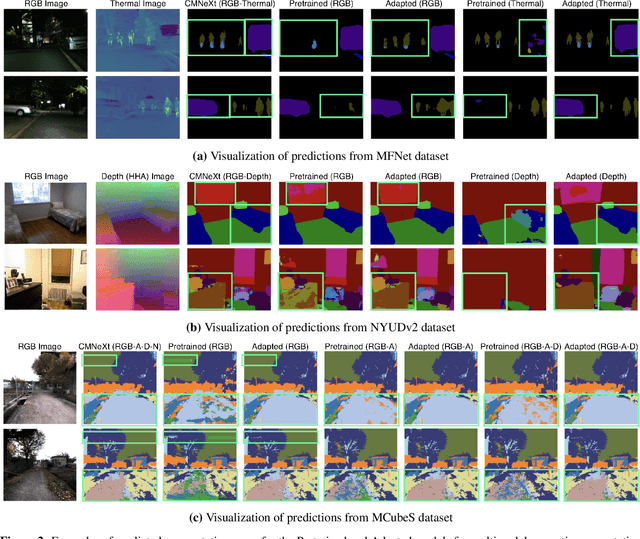
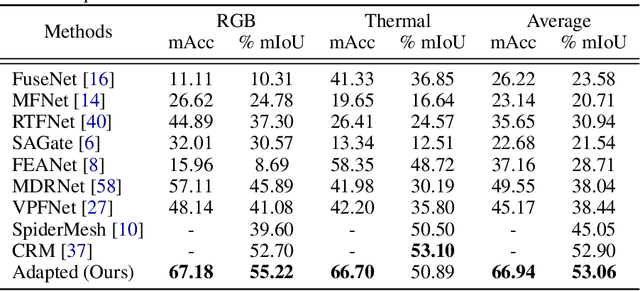
Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose simple and parameter-efficient adaptation procedures for pretrained multimodal networks. In particular, we exploit low-rank adaptation and modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 0.7% of the total parameters in most experiments). We conduct a series of experiments to highlight the robustness of our proposed method using diverse datasets for RGB-thermal and RGB-Depth semantic segmentation, multimodal material segmentation, and multimodal sentiment analysis tasks. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.