 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Sentiment analysis and opinion mining on E-commerce site
Nov 28, 2022
Sentiment analysis or opinion mining help to illustrate the phrase NLP (Natural Language Processing). Sentiment analysis has been the most significant topic in recent years. The goal of this study is to solve the sentiment polarity classification challenges in sentiment analysis. A broad technique for categorizing sentiment opposition is presented, along with comprehensive process explanations. With the results of the analysis, both sentence-level classification and review-level categorization are conducted. Finally, we discuss our plans for future sentiment analysis research.
BanglaBook: A Large-scale Bangla Dataset for Sentiment Analysis from Book Reviews
May 11, 2023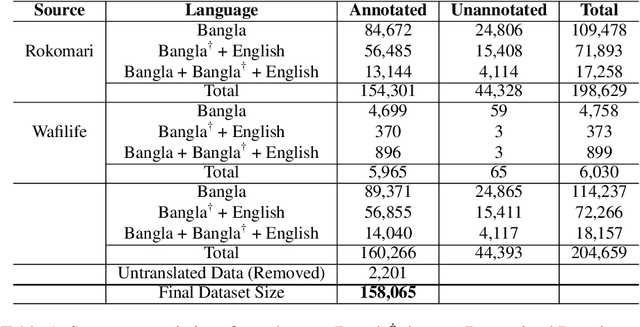
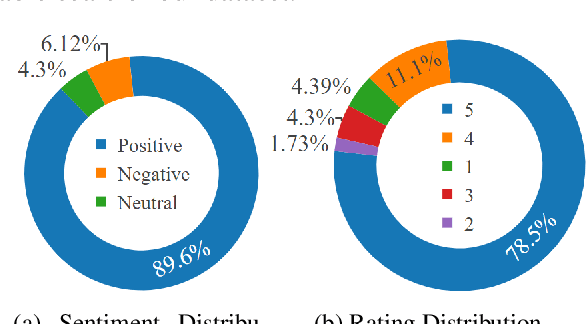
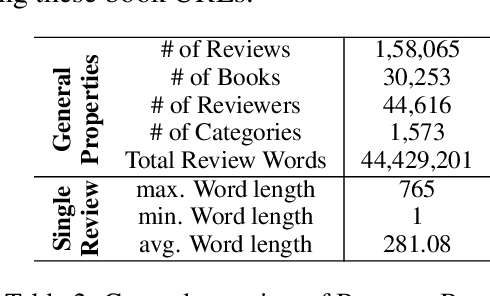
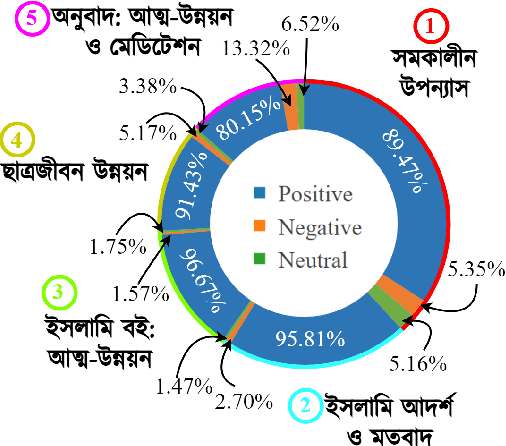
The analysis of consumer sentiment, as expressed through reviews, can provide a wealth of insight regarding the quality of a product. While the study of sentiment analysis has been widely explored in many popular languages, relatively less attention has been given to the Bangla language, mostly due to a lack of relevant data and cross-domain adaptability. To address this limitation, we present BanglaBook, a large-scale dataset of Bangla book reviews consisting of 158,065 samples classified into three broad categories: positive, negative, and neutral. We provide a detailed statistical analysis of the dataset and employ a range of machine learning models to establish baselines including SVM, LSTM, and Bangla-BERT. Our findings demonstrate a substantial performance advantage of pre-trained models over models that rely on manually crafted features, emphasizing the necessity for additional training resources in this domain. Additionally, we conduct an in-depth error analysis by examining sentiment unigrams, which may provide insight into common classification errors in under-resourced languages like Bangla. Our codes and data are publicly available at https://github.com/mohsinulkabir14/BanglaBook.
Few-Shot Spoken Language Understanding via Joint Speech-Text Models
Oct 09, 2023Recent work on speech representation models jointly pre-trained with text has demonstrated the potential of improving speech representations by encoding speech and text in a shared space. In this paper, we leverage such shared representations to address the persistent challenge of limited data availability in spoken language understanding tasks. By employing a pre-trained speech-text model, we find that models fine-tuned on text can be effectively transferred to speech testing data. With as little as 1 hour of labeled speech data, our proposed approach achieves comparable performance on spoken language understanding tasks (specifically, sentiment analysis and named entity recognition) when compared to previous methods using speech-only pre-trained models fine-tuned on 10 times more data. Beyond the proof-of-concept study, we also analyze the latent representations. We find that the bottom layers of speech-text models are largely task-agnostic and align speech and text representations into a shared space, while the top layers are more task-specific.
Classifying COVID-19 Related Tweets for Fake News Detection and Sentiment Analysis with BERT-based Models
Apr 02, 2023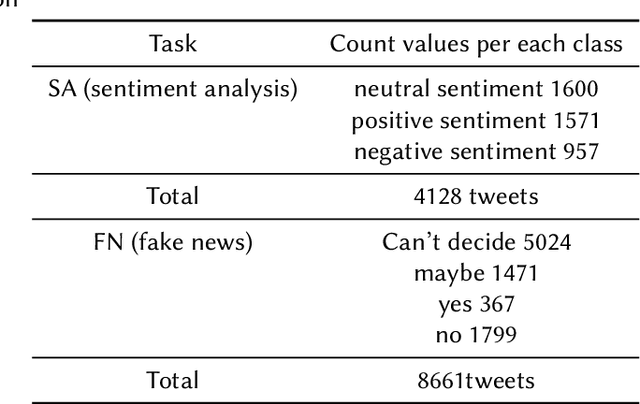
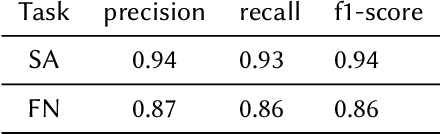
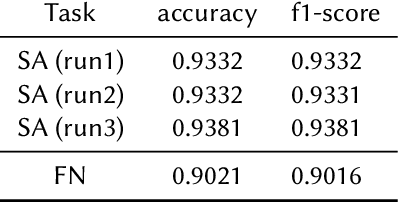
The present paper is about the participation of our team "techno" on CERIST'22 shared tasks. We used an available dataset "task1.c" related to covid-19 pandemic. It comprises 4128 tweets for sentiment analysis task and 8661 tweets for fake news detection task. We used natural language processing tools with the combination of the most renowned pre-trained language models BERT (Bidirectional Encoder Representations from Transformers). The results shows the efficacy of pre-trained language models as we attained an accuracy of 0.93 for the sentiment analysis task and 0.90 for the fake news detection task.
HausaNLP at SemEval-2023 Task 12: Leveraging African Low Resource TweetData for Sentiment Analysis
Apr 26, 2023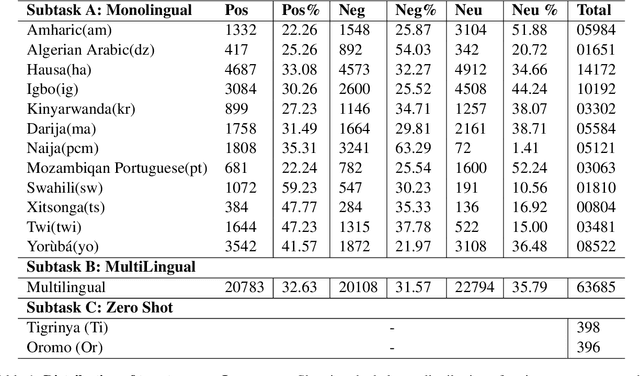
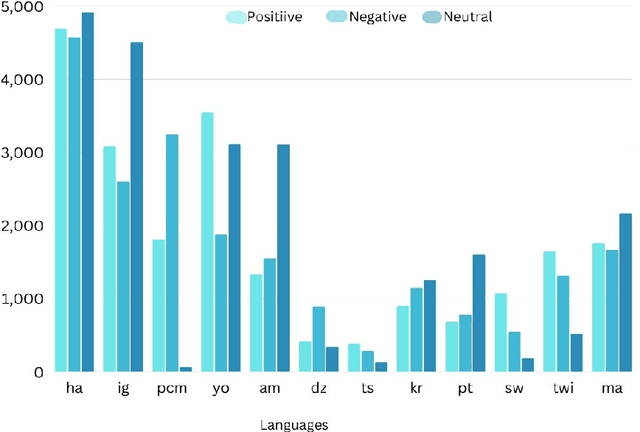
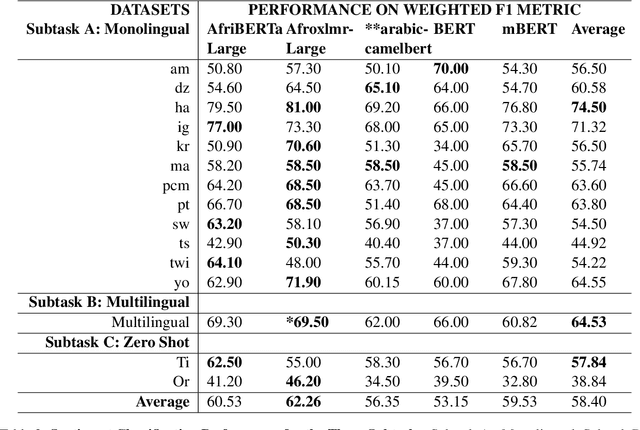
We present the findings of SemEval-2023 Task 12, a shared task on sentiment analysis for low-resource African languages using Twitter dataset. The task featured three subtasks; subtask A is monolingual sentiment classification with 12 tracks which are all monolingual languages, subtask B is multilingual sentiment classification using the tracks in subtask A and subtask C is a zero-shot sentiment classification. We present the results and findings of subtask A, subtask B and subtask C. We also release the code on github. Our goal is to leverage low-resource tweet data using pre-trained Afro-xlmr-large, AfriBERTa-Large, Bert-base-arabic-camelbert-da-sentiment (Arabic-camelbert), Multilingual-BERT (mBERT) and BERT models for sentiment analysis of 14 African languages. The datasets for these subtasks consists of a gold standard multi-class labeled Twitter datasets from these languages. Our results demonstrate that Afro-xlmr-large model performed better compared to the other models in most of the languages datasets. Similarly, Nigerian languages: Hausa, Igbo, and Yoruba achieved better performance compared to other languages and this can be attributed to the higher volume of data present in the languages.
LSTM-based QoE Evaluation for Web Microservices' Reputation Scoring
Aug 25, 2023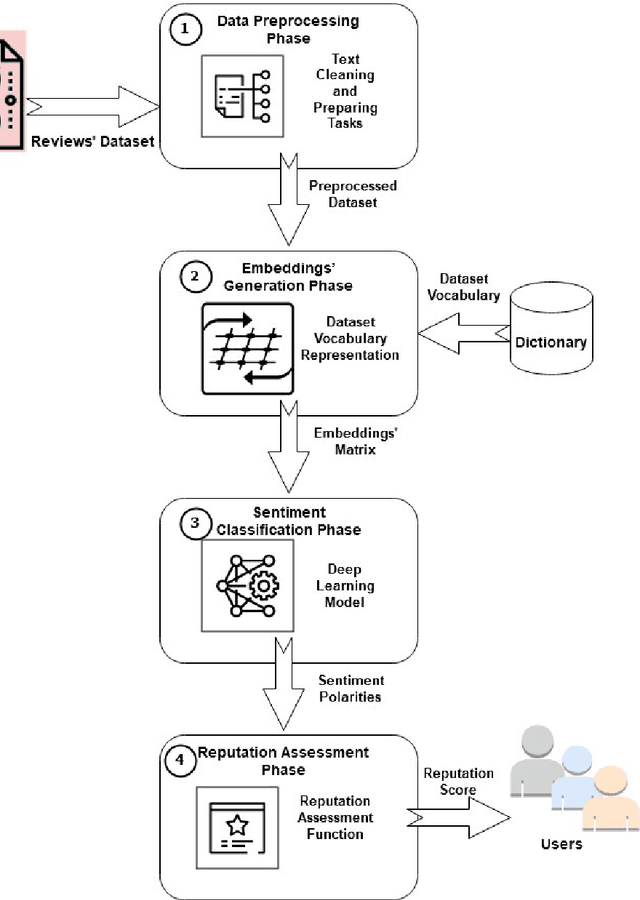

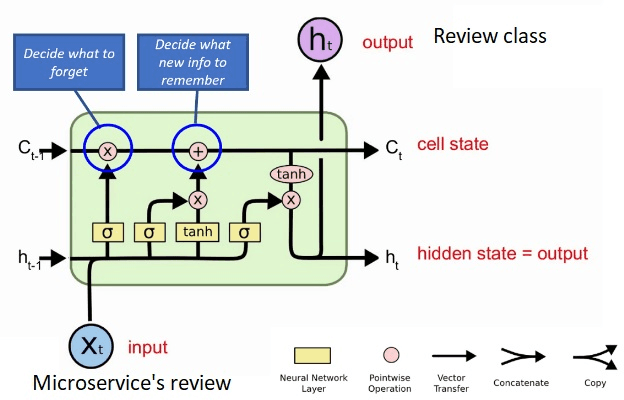
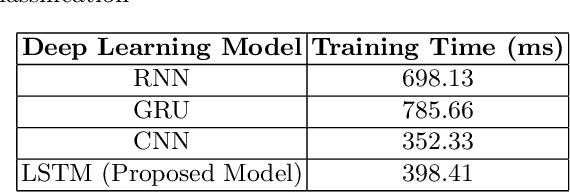
Sentiment analysis is the task of mining the authors' opinions about specific entities. It allows organizations to monitor different services in real time and act accordingly. Reputation is what is generally said or believed about people or things. Informally, reputation combines the measure of reliability derived from feedback, reviews, and ratings gathered from users, which reflect their quality of experience (QoE) and can either increase or harm the reputation of the provided services. In this study, we propose to perform sentiment analysis on web microservices reviews to exploit the provided information to assess and score the microservices' reputation. Our proposed approach uses the Long Short-Term Memory (LSTM) model to perform sentiment analysis and the Net Brand Reputation (NBR) algorithm to assess reputation scores for microservices. This approach is tested on a set of more than 10,000 reviews related to 15 Amazon Web microservices, and the experimental results have shown that our approach is more accurate than existing approaches, with an accuracy and precision of 93% obtained after applying an oversampling strategy and a resulting reputation score of the considered microservices community of 89%.
SEntFiN 1.0: Entity-Aware Sentiment Analysis for Financial News
May 20, 2023Fine-grained financial sentiment analysis on news headlines is a challenging task requiring human-annotated datasets to achieve high performance. Limited studies have tried to address the sentiment extraction task in a setting where multiple entities are present in a news headline. In an effort to further research in this area, we make publicly available SEntFiN 1.0, a human-annotated dataset of 10,753 news headlines with entity-sentiment annotations, of which 2,847 headlines contain multiple entities, often with conflicting sentiments. We augment our dataset with a database of over 1,000 financial entities and their various representations in news media amounting to over 5,000 phrases. We propose a framework that enables the extraction of entity-relevant sentiments using a feature-based approach rather than an expression-based approach. For sentiment extraction, we utilize 12 different learning schemes utilizing lexicon-based and pre-trained sentence representations and five classification approaches. Our experiments indicate that lexicon-based n-gram ensembles are above par with pre-trained word embedding schemes such as GloVe. Overall, RoBERTa and finBERT (domain-specific BERT) achieve the highest average accuracy of 94.29% and F1-score of 93.27%. Further, using over 210,000 entity-sentiment predictions, we validate the economic effect of sentiments on aggregate market movements over a long duration.
Introducing DictaLM -- A Large Generative Language Model for Modern Hebrew
Sep 25, 2023

We present DictaLM, a large-scale language model tailored for Modern Hebrew. Boasting 7B parameters, this model is predominantly trained on Hebrew-centric data. As a commitment to promoting research and development in the Hebrew language, we release both the foundation model and the instruct-tuned model under a Creative Commons license. Concurrently, we introduce DictaLM-Rab, another foundation model geared towards Rabbinic/Historical Hebrew. These foundation models serve as ideal starting points for fine-tuning various Hebrew-specific tasks, such as instruction, Q&A, sentiment analysis, and more. This release represents a preliminary step, offering an initial Hebrew LLM model for the Hebrew NLP community to experiment with.
Structured Sentiment Analysis as Transition-based Dependency Parsing
May 09, 2023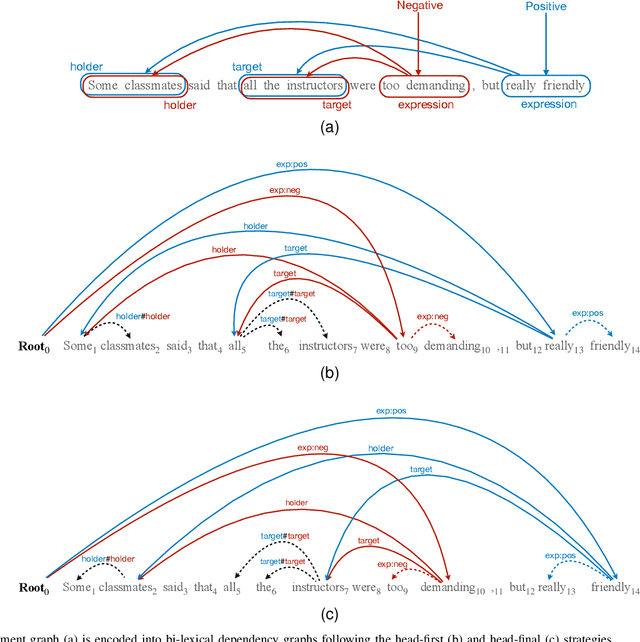

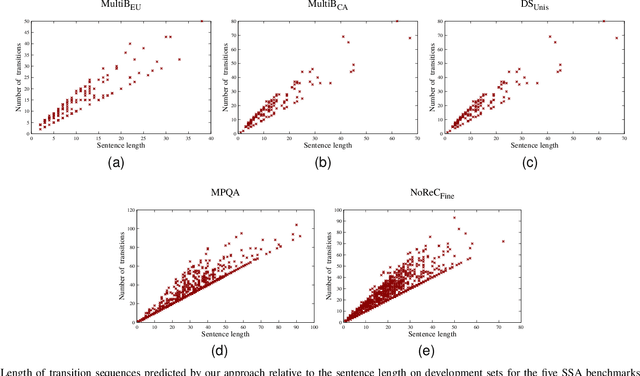
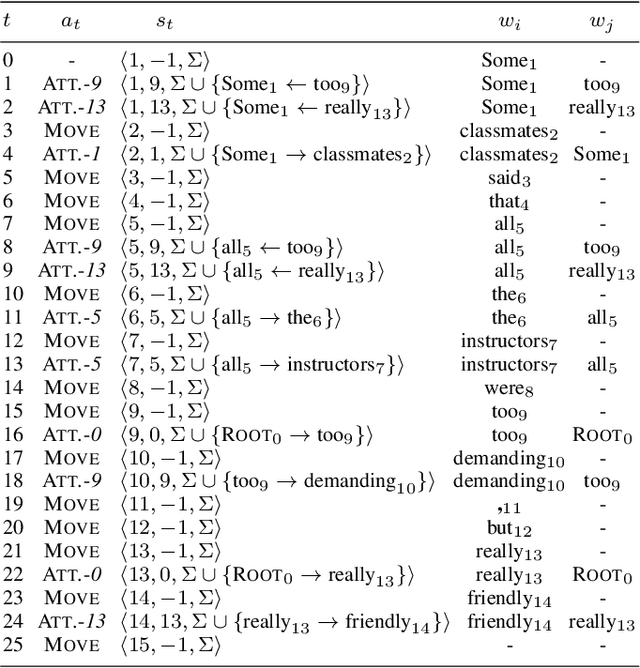
Structured sentiment analysis (SSA) aims to automatically extract people's opinions from a text in natural language and adequately represent that information in a graph structure. One of the most accurate methods for performing SSA was recently proposed and consists of approaching it as a dependency parsing task. Although we can find in the literature how transition-based algorithms excel in dependency parsing in terms of accuracy and efficiency, all proposed attempts to tackle SSA following that approach were based on graph-based models. In this article, we present the first transition-based method to address SSA as dependency parsing. Specifically, we design a transition system that processes the input text in a left-to-right pass, incrementally generating the graph structure containing all identified opinions. To effectively implement our final transition-based model, we resort to a Pointer Network architecture as a backbone. From an extensive evaluation, we demonstrate that our model offers the best performance to date in practically all cases among prior dependency-based methods, and surpass recent task-specific techniques on the most challenging datasets. We additionally include an in-depth analysis and empirically prove that the overall time-complexity cost of our approach is quadratic in the sentence length, being more efficient than top-performing graph-based parsers.
Fine-grained Affective Processing Capabilities Emerging from Large Language Models
Sep 04, 2023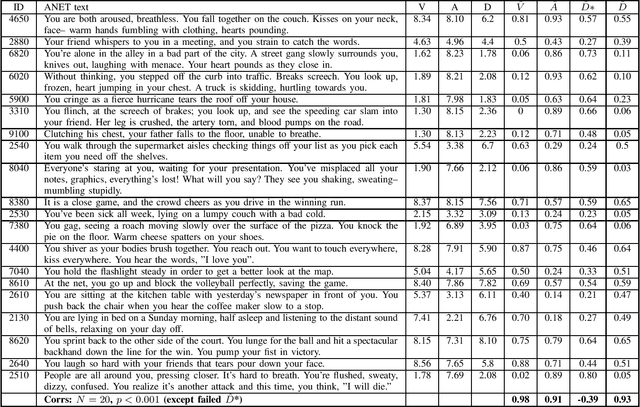
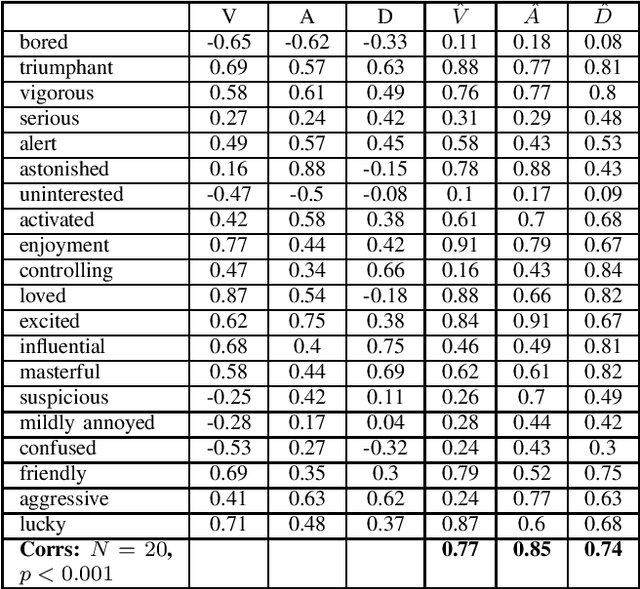
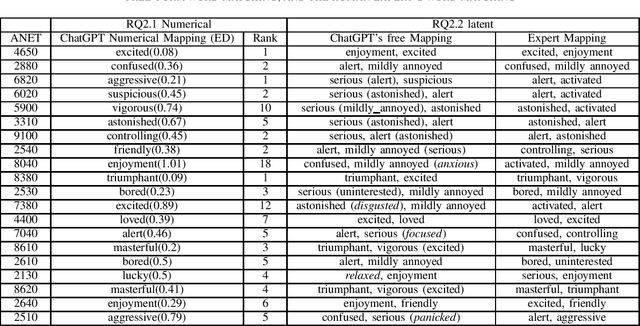

Large language models, in particular generative pre-trained transformers (GPTs), show impressive results on a wide variety of language-related tasks. In this paper, we explore ChatGPT's zero-shot ability to perform affective computing tasks using prompting alone. We show that ChatGPT a) performs meaningful sentiment analysis in the Valence, Arousal and Dominance dimensions, b) has meaningful emotion representations in terms of emotion categories and these affective dimensions, and c) can perform basic appraisal-based emotion elicitation of situations based on a prompt-based computational implementation of the OCC appraisal model. These findings are highly relevant: First, they show that the ability to solve complex affect processing tasks emerges from language-based token prediction trained on extensive data sets. Second, they show the potential of large language models for simulating, processing and analyzing human emotions, which has important implications for various applications such as sentiment analysis, socially interactive agents, and social robotics.