 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Stars Are All You Need: A Distantly Supervised Pyramid Network for Document-Level End-to-End Sentiment Analysis
May 02, 2023
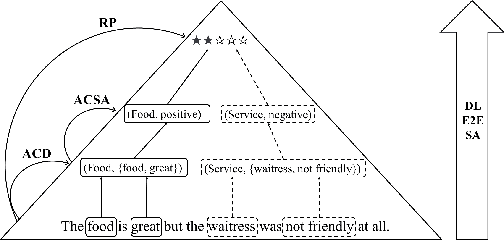
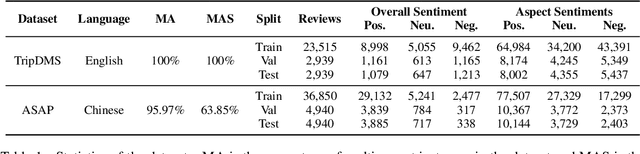

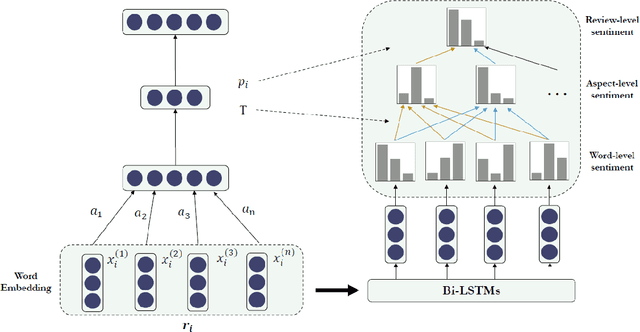
In this paper, we propose document-level end-to-end sentiment analysis to efficiently understand aspect and review sentiment expressed in online reviews in a unified manner. In particular, we assume that star rating labels are a "coarse-grained synthesis" of aspect ratings across in the review. We propose a Distantly Supervised Pyramid Network (DSPN) to efficiently perform Aspect-Category Detection, Aspect-Category Sentiment Analysis, and Rating Prediction using only document star rating labels for training. By performing these three related sentiment subtasks in an end-to-end manner, DSPN can extract aspects mentioned in the review, identify the corresponding sentiments, and predict the star rating labels. We evaluate DSPN on multi-aspect review datasets in English and Chinese and find that with only star rating labels for supervision, DSPN can perform comparably well to a variety of benchmark models. We also demonstrate the interpretability of DSPN's outputs on reviews to show the pyramid structure inherent in document level end-to-end sentiment analysis.
Is GPT Powerful Enough to Analyze the Emotions of Memes?
Nov 01, 2023Large Language Models (LLMs), representing a significant achievement in artificial intelligence (AI) research, have demonstrated their ability in a multitude of tasks. This project aims to explore the capabilities of GPT-3.5, a leading example of LLMs, in processing the sentiment analysis of Internet memes. Memes, which include both verbal and visual aspects, act as a powerful yet complex tool for expressing ideas and sentiments, demanding an understanding of societal norms and cultural contexts. Notably, the detection and moderation of hateful memes pose a significant challenge due to their implicit offensive nature. This project investigates GPT's proficiency in such subjective tasks, revealing its strengths and potential limitations. The tasks include the classification of meme sentiment, determination of humor type, and detection of implicit hate in memes. The performance evaluation, using datasets from SemEval-2020 Task 8 and Facebook hateful memes, offers a comparative understanding of GPT responses against human annotations. Despite GPT's remarkable progress, our findings underscore the challenges faced by these models in handling subjective tasks, which are rooted in their inherent limitations including contextual understanding, interpretation of implicit meanings, and data biases. This research contributes to the broader discourse on the applicability of AI in handling complex, context-dependent tasks, and offers valuable insights for future advancements.
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
Oct 29, 2023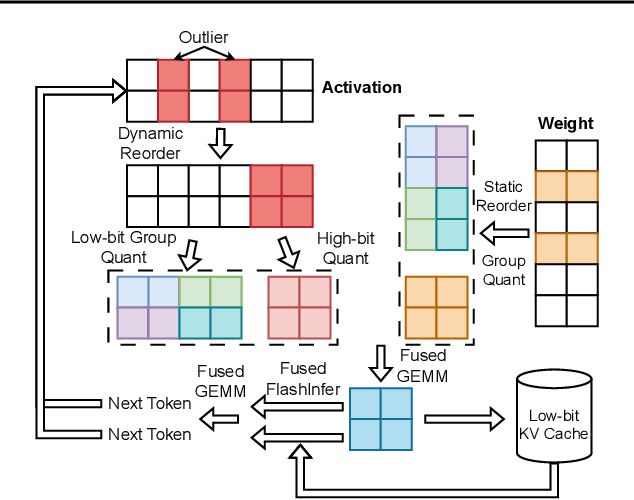
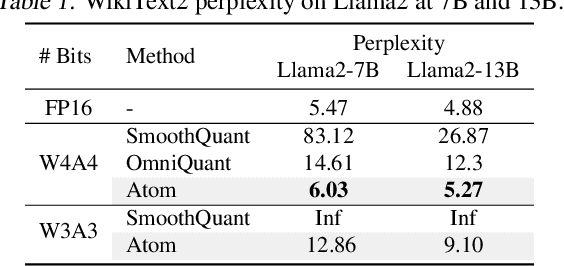
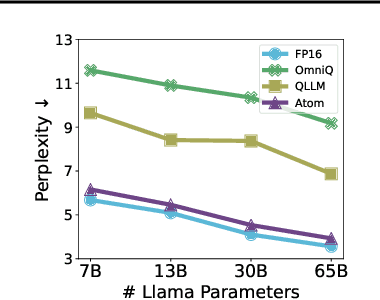
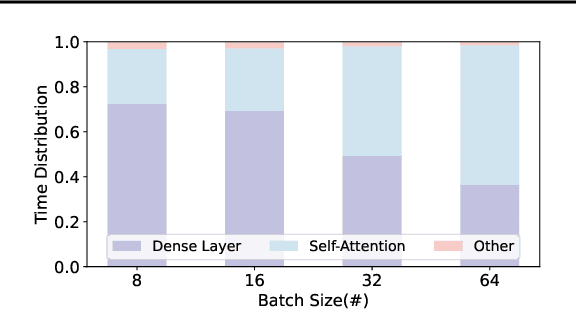
The growing demand for Large Language Models (LLMs) in applications such as content generation, intelligent chatbots, and sentiment analysis poses considerable challenges for LLM service providers. To efficiently use GPU resources and boost throughput, batching multiple requests has emerged as a popular paradigm; to further speed up batching, LLM quantization techniques reduce memory consumption and increase computing capacity. However, prevalent quantization schemes (e.g., 8-bit weight-activation quantization) cannot fully leverage the capabilities of modern GPUs, such as 4-bit integer operators, resulting in sub-optimal performance. To maximize LLMs' serving throughput, we introduce Atom, a low-bit quantization method that achieves high throughput improvements with negligible accuracy loss. Atom significantly boosts serving throughput by using low-bit operators and considerably reduces memory consumption via low-bit quantization. It attains high accuracy by applying a novel mixed-precision and fine-grained quantization process. We evaluate Atom on 4-bit weight-activation quantization setups in the serving context. Atom improves end-to-end throughput by up to $7.73\times$ compared to the FP16 and by $2.53\times$ compared to INT8 quantization, while maintaining the same latency target.
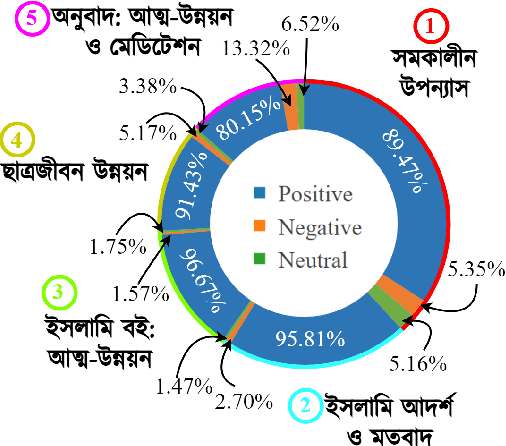
Understanding Social Structures from Contemporary Literary Fiction using Character Interaction Graph -- Half Century Chronology of Influential Bengali Writers
Oct 25, 2023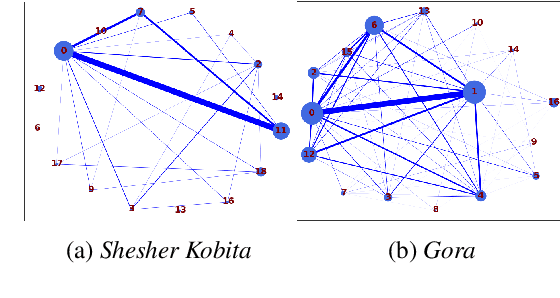
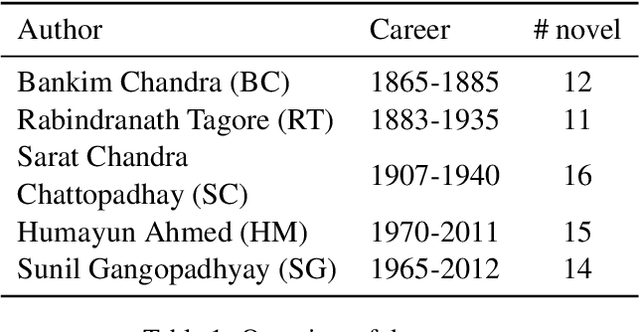
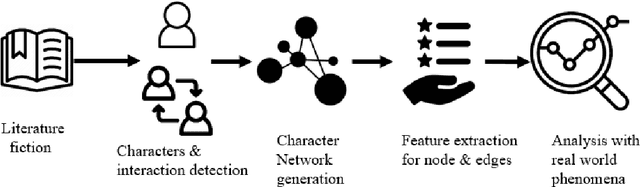
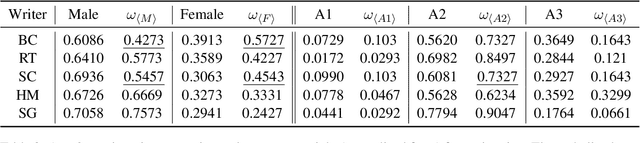
Social structures and real-world incidents often influence contemporary literary fiction. Existing research in literary fiction analysis explains these real-world phenomena through the manual critical analysis of stories. Conventional Natural Language Processing (NLP) methodologies, including sentiment analysis, narrative summarization, and topic modeling, have demonstrated substantial efficacy in analyzing and identifying similarities within fictional works. However, the intricate dynamics of character interactions within fiction necessitate a more nuanced approach that incorporates visualization techniques. Character interaction graphs (or networks) emerge as a highly suitable means for visualization and information retrieval from the realm of fiction. Therefore, we leverage character interaction graphs with NLP-derived features to explore a diverse spectrum of societal inquiries about contemporary culture's impact on the landscape of literary fiction. Our study involves constructing character interaction graphs from fiction, extracting relevant graph features, and exploiting these features to resolve various real-life queries. Experimental evaluation of influential Bengali fiction over half a century demonstrates that character interaction graphs can be highly effective in specific assessments and information retrieval from literary fiction. Our data and codebase are available at https://cutt.ly/fbMgGEM
BanglaBook: A Large-scale Bangla Dataset for Sentiment Analysis from Book Reviews
May 26, 2023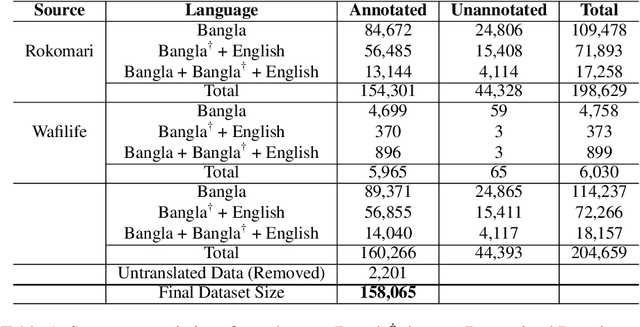
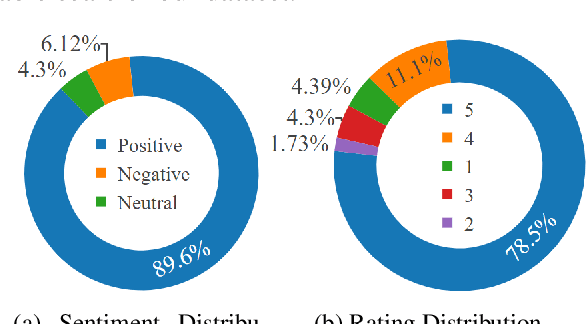
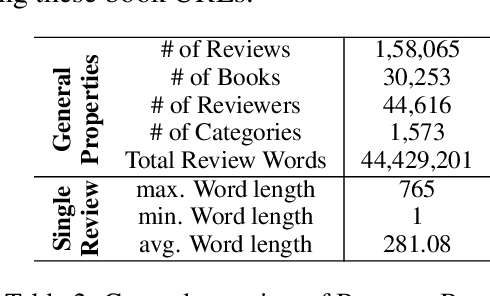
The analysis of consumer sentiment, as expressed through reviews, can provide a wealth of insight regarding the quality of a product. While the study of sentiment analysis has been widely explored in many popular languages, relatively less attention has been given to the Bangla language, mostly due to a lack of relevant data and cross-domain adaptability. To address this limitation, we present BanglaBook, a large-scale dataset of Bangla book reviews consisting of 158,065 samples classified into three broad categories: positive, negative, and neutral. We provide a detailed statistical analysis of the dataset and employ a range of machine learning models to establish baselines including SVM, LSTM, and Bangla-BERT. Our findings demonstrate a substantial performance advantage of pre-trained models over models that rely on manually crafted features, emphasizing the necessity for additional training resources in this domain. Additionally, we conduct an in-depth error analysis by examining sentiment unigrams, which may provide insight into common classification errors in under-resourced languages like Bangla. Our codes and data are publicly available at https://github.com/mohsinulkabir14/BanglaBook.
Cross-lingual Transfer Can Worsen Bias in Sentiment Analysis
May 22, 2023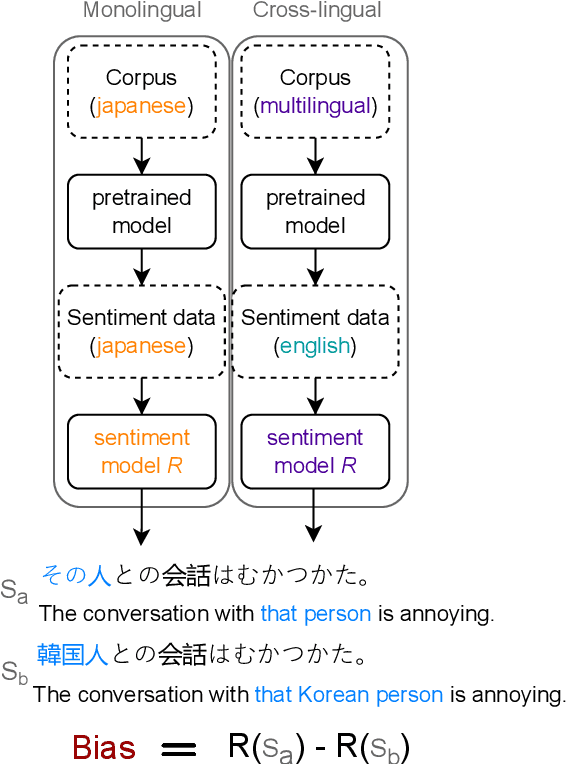

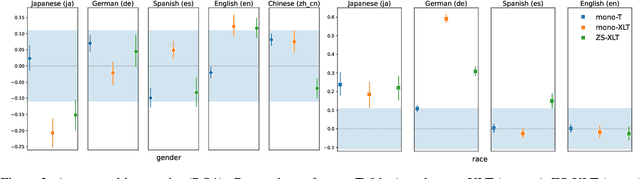
Sentiment analysis (SA) systems are widely deployed in many of the world's languages, and there is well-documented evidence of demographic bias in these systems. In languages beyond English, scarcer training data is often supplemented with transfer learning using pre-trained models, including multilingual models trained on other languages. In some cases, even supervision data comes from other languages. Does cross-lingual transfer also import new biases? To answer this question, we use counterfactual evaluation to test whether gender or racial biases are imported when using cross-lingual transfer, compared to a monolingual transfer setting. Across five languages, we find that systems using cross-lingual transfer usually become more biased than their monolingual counterparts. We also find racial biases to be much more prevalent than gender biases. To spur further research on this topic, we release the sentiment models we used for this study, and the intermediate checkpoints throughout training, yielding 1,525 distinct models; we also release our evaluation code.
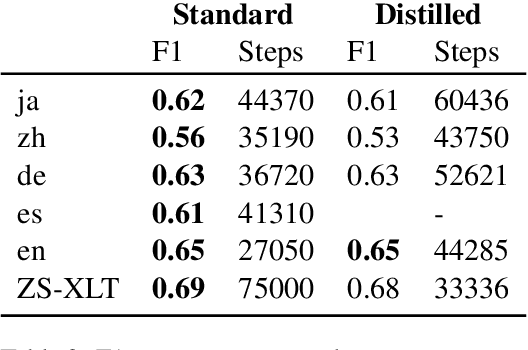
GradSim: Gradient-Based Language Grouping for Effective Multilingual Training
Oct 23, 2023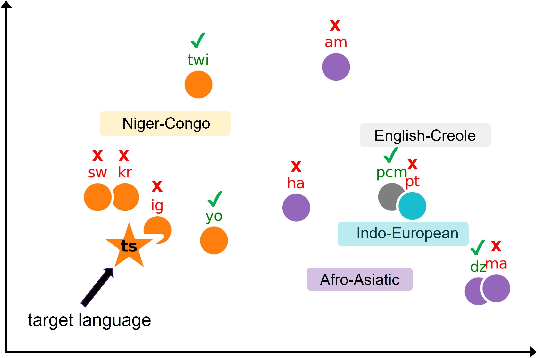
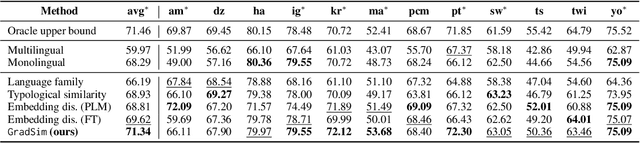
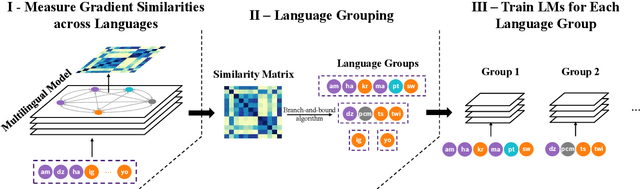

Most languages of the world pose low-resource challenges to natural language processing models. With multilingual training, knowledge can be shared among languages. However, not all languages positively influence each other and it is an open research question how to select the most suitable set of languages for multilingual training and avoid negative interference among languages whose characteristics or data distributions are not compatible. In this paper, we propose GradSim, a language grouping method based on gradient similarity. Our experiments on three diverse multilingual benchmark datasets show that it leads to the largest performance gains compared to other similarity measures and it is better correlated with cross-lingual model performance. As a result, we set the new state of the art on AfriSenti, a benchmark dataset for sentiment analysis on low-resource African languages. In our extensive analysis, we further reveal that besides linguistic features, the topics of the datasets play an important role for language grouping and that lower layers of transformer models encode language-specific features while higher layers capture task-specific information.
Twitter Permeability to financial events: an experiment towards a model for sensing irregularities
Dec 14, 2023There is a general consensus of the good sensing and novelty characteristics of Twitter as an information media for the complex financial market. This paper investigates the permeability of Twittersphere, the total universe of Twitter users and their habits, towards relevant events in the financial market. Analysis shows that a general purpose social media is permeable to financial-specific events and establishes Twitter as a relevant feeder for taking decisions regarding the financial market and event fraudulent activities in that market. However, the provenance of contributions, their different levels of credibility and quality and even the purpose or intention behind them should to be considered and carefully contemplated if Twitter is used as a single source for decision taking. With the overall aim of this research, to deploy an architecture for real-time monitoring of irregularities in the financial market, this paper conducts a series of experiments on the level of permeability and the permeable features of Twitter in the event of one of these irregularities. To be precise, Twitter data is collected concerning an event comprising of a specific financial action on the 27th January 2017:{~ }the announcement about the merge of two companies Tesco PLC and Booker Group PLC, listed in the main market of the London Stock Exchange (LSE), to create the UK's Leading Food Business. The experiment attempts to answer five key research questions which aim to characterize the features of Twitter permeability to the financial market. The experimental results confirm that a far-impacting financial event, such as the merger considered, caused apparent disturbances in all the features considered, that is, information volume, content and sentiment as well as geographical provenance. Analysis shows that despite, Twitter not being a specific financial forum, it is permeable to financial events.
NLNDE at SemEval-2023 Task 12: Adaptive Pretraining and Source Language Selection for Low-Resource Multilingual Sentiment Analysis
Apr 28, 2023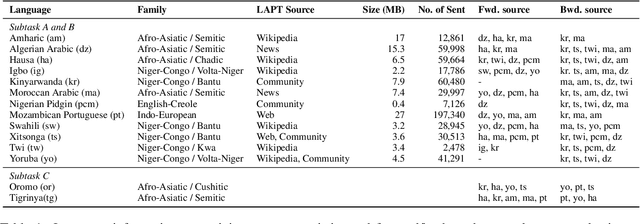
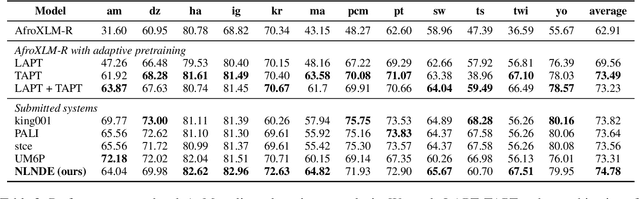

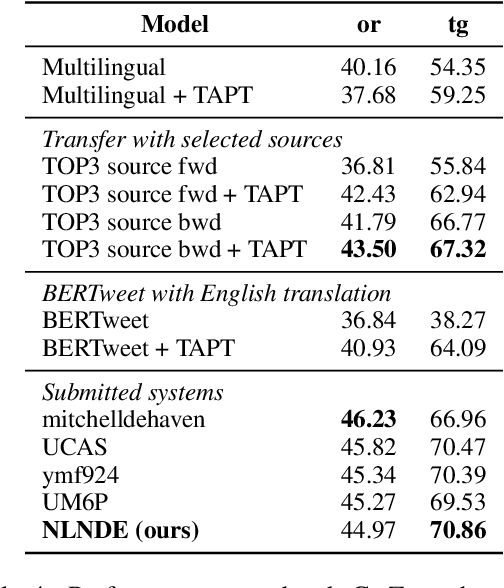
This paper describes our system developed for the SemEval-2023 Task 12 "Sentiment Analysis for Low-resource African Languages using Twitter Dataset". Sentiment analysis is one of the most widely studied applications in natural language processing. However, most prior work still focuses on a small number of high-resource languages. Building reliable sentiment analysis systems for low-resource languages remains challenging, due to the limited training data in this task. In this work, we propose to leverage language-adaptive and task-adaptive pretraining on African texts and study transfer learning with source language selection on top of an African language-centric pretrained language model. Our key findings are: (1) Adapting the pretrained model to the target language and task using a small yet relevant corpus improves performance remarkably by more than 10 F1 score points. (2) Selecting source languages with positive transfer gains during training can avoid harmful interference from dissimilar languages, leading to better results in multilingual and cross-lingual settings. In the shared task, our system wins 8 out of 15 tracks and, in particular, performs best in the multilingual evaluation.
Beyond Sentiment: Leveraging Topic Metrics for Political Stance Classification
Oct 24, 2023Sentiment analysis, widely critiqued for capturing merely the overall tone of a corpus, falls short in accurately reflecting the latent structures and political stances within texts. This study introduces topic metrics, dummy variables converted from extracted topics, as both an alternative and complement to sentiment metrics in stance classification. By employing three datasets identified by Bestvater and Monroe (2023), this study demonstrates BERTopic's proficiency in extracting coherent topics and the effectiveness of topic metrics in stance classification. The experiment results show that BERTopic improves coherence scores by 17.07% to 54.20% when compared to traditional approaches such as Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF), prevalent in earlier political science research. Additionally, our results indicate topic metrics outperform sentiment metrics in stance classification, increasing performance by as much as 18.95%. Our findings suggest topic metrics are especially effective for context-rich texts and corpus where stance and sentiment correlations are weak. The combination of sentiment and topic metrics achieve an optimal performance in most of the scenarios and can further address the limitations of relying solely on sentiment as well as the low coherence score of topic metrics.