 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Automated Ableism: An Exploration of Explicit Disability Biases in Sentiment and Toxicity Analysis Models
Jul 18, 2023

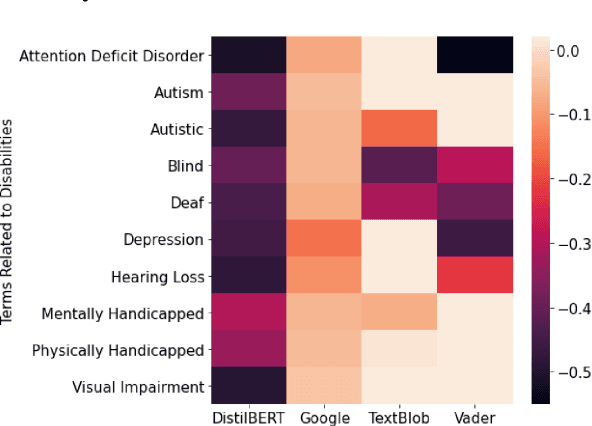


We analyze sentiment analysis and toxicity detection models to detect the presence of explicit bias against people with disability (PWD). We employ the bias identification framework of Perturbation Sensitivity Analysis to examine conversations related to PWD on social media platforms, specifically Twitter and Reddit, in order to gain insight into how disability bias is disseminated in real-world social settings. We then create the \textit{Bias Identification Test in Sentiment} (BITS) corpus to quantify explicit disability bias in any sentiment analysis and toxicity detection models. Our study utilizes BITS to uncover significant biases in four open AIaaS (AI as a Service) sentiment analysis tools, namely TextBlob, VADER, Google Cloud Natural Language API, DistilBERT and two toxicity detection models, namely two versions of Toxic-BERT. Our findings indicate that all of these models exhibit statistically significant explicit bias against PWD.
* TrustNLP at ACL 2023
Tracking public attitudes toward ChatGPT on Twitter using sentiment analysis and topic modeling
Jun 22, 2023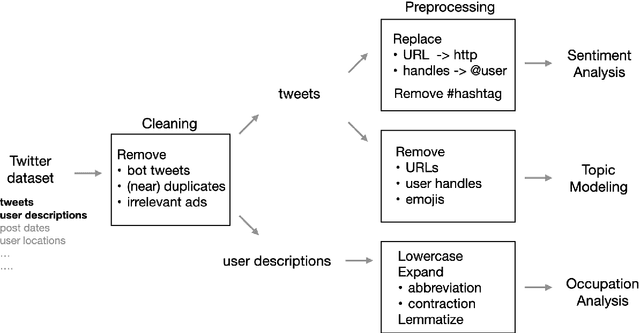
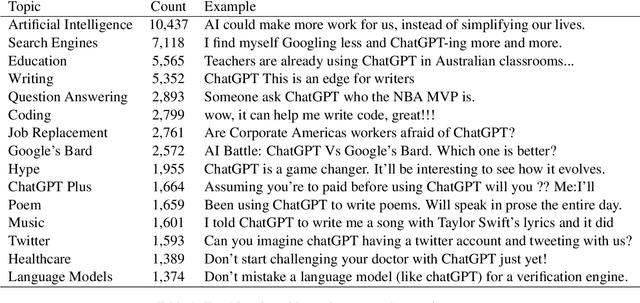
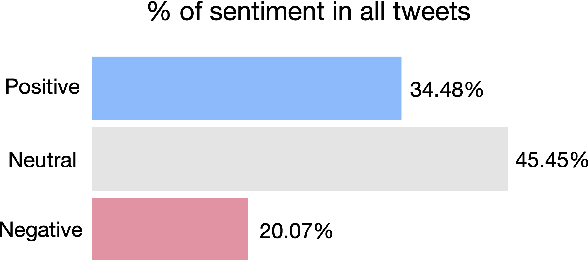
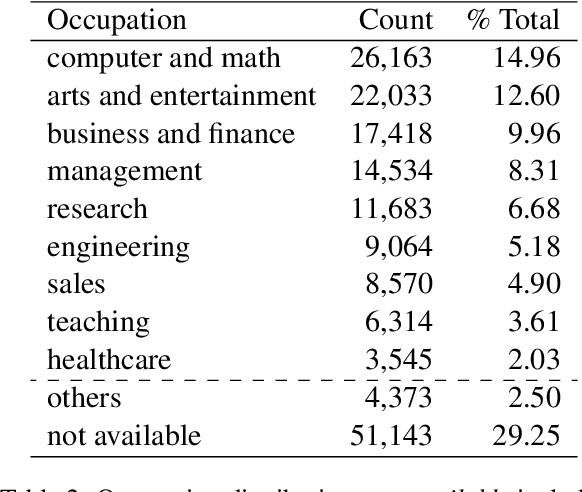
ChatGPT sets a new record with the fastest-growing user base, as a chatbot powered by a large language model (LLM). While it demonstrates state-of-the-art capabilities in a variety of language-generating tasks, it also raises widespread public concerns regarding its societal impact. In this paper, we utilize natural language processing approaches to investigate the public attitudes towards ChatGPT by applying sentiment analysis and topic modeling techniques to Twitter data. Our result shows that the overall sentiment is largely neutral to positive, which also holds true across different occupation groups. Among a wide range of topics mentioned in tweets, the most popular topics are Artificial Intelligence, Search Engines, Education, Writing, and Question Answering.
UBC-DLNLP at SemEval-2023 Task 12: Impact of Transfer Learning on African Sentiment Analysis
Apr 21, 2023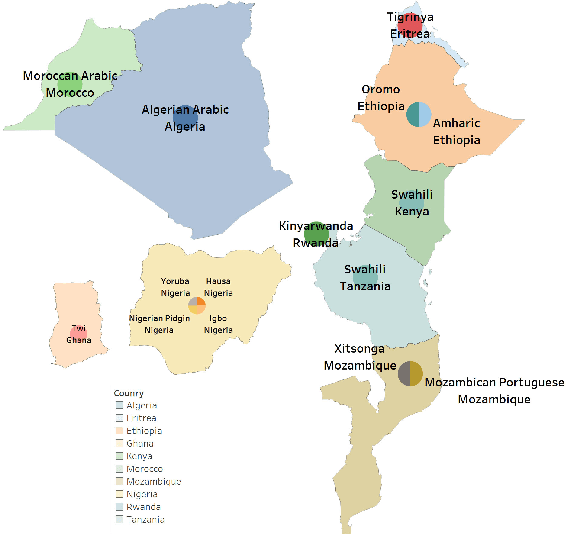
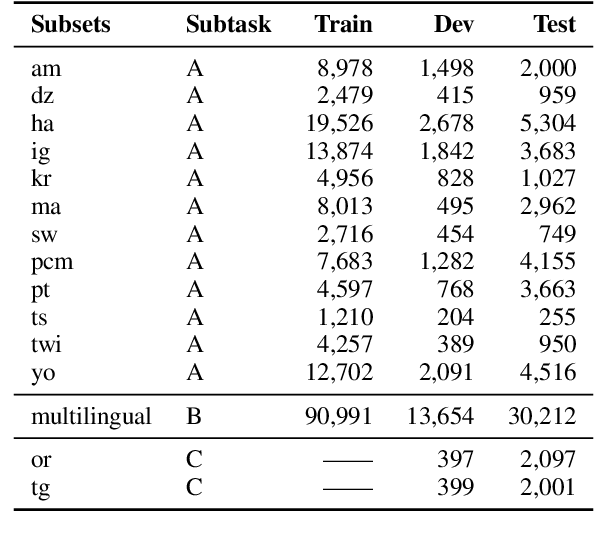
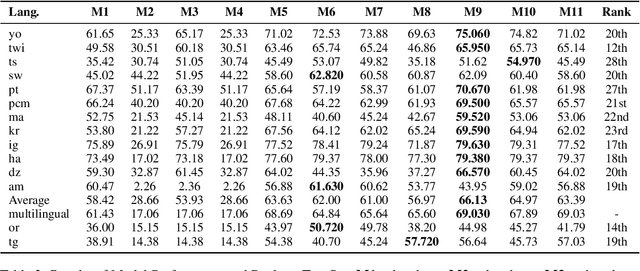
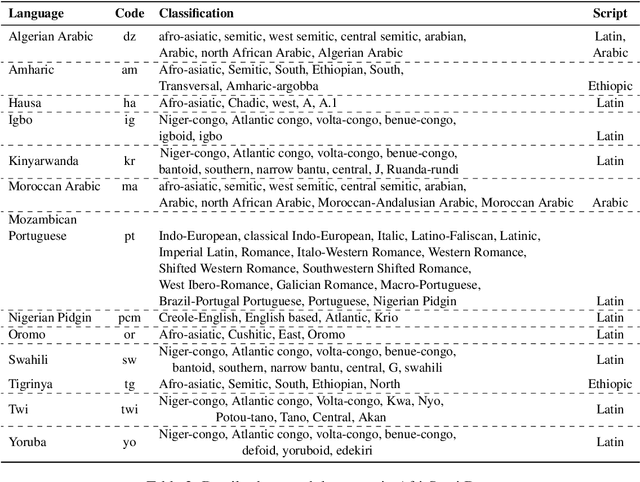
We describe our contribution to the SemEVAl 2023 AfriSenti-SemEval shared task, where we tackle the task of sentiment analysis in 14 different African languages. We develop both monolingual and multilingual models under a full supervised setting (subtasks A and B). We also develop models for the zero-shot setting (subtask C). Our approach involves experimenting with transfer learning using six language models, including further pertaining of some of these models as well as a final finetuning stage. Our best performing models achieve an F1-score of 70.36 on development data and an F1-score of 66.13 on test data. Unsurprisingly, our results demonstrate the effectiveness of transfer learning and fine-tuning techniques for sentiment analysis across multiple languages. Our approach can be applied to other sentiment analysis tasks in different languages and domains.
Cardiovascular Disease Risk Prediction via Social Media
Sep 28, 2023Researchers use Twitter and sentiment analysis to predict Cardiovascular Disease (CVD) risk. We developed a new dictionary of CVD-related keywords by analyzing emotions expressed in tweets. Tweets from eighteen US states, including the Appalachian region, were collected. Using the VADER model for sentiment analysis, users were classified as potentially at CVD risk. Machine Learning (ML) models were employed to classify individuals' CVD risk and applied to a CDC dataset with demographic information to make the comparison. Performance evaluation metrics such as Test Accuracy, Precision, Recall, F1 score, Mathew's Correlation Coefficient (MCC), and Cohen's Kappa (CK) score were considered. Results demonstrated that analyzing tweets' emotions surpassed the predictive power of demographic data alone, enabling the identification of individuals at potential risk of developing CVD. This research highlights the potential of Natural Language Processing (NLP) and ML techniques in using tweets to identify individuals with CVD risks, providing an alternative approach to traditional demographic information for public health monitoring.
weighted CapsuleNet networks for Persian multi-domain sentiment analysis
Jul 01, 2023
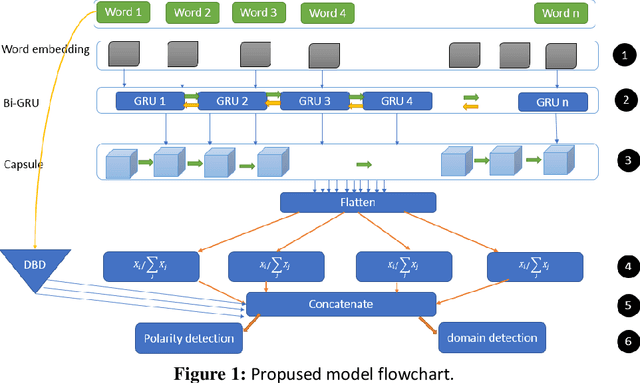

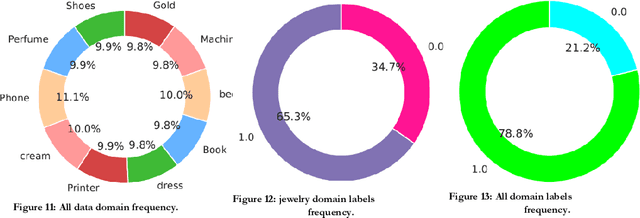
Sentiment classification is a fundamental task in natural language processing, assigning one of the three classes, positive, negative, or neutral, to free texts. However, sentiment classification models are highly domain dependent; the classifier may perform classification with reasonable accuracy in one domain but not in another due to the Semantic multiplicity of words getting poor accuracy. This article presents a new Persian/Arabic multi-domain sentiment analysis method using the cumulative weighted capsule networks approach. Weighted capsule ensemble consists of training separate capsule networks for each domain and a weighting measure called domain belonging degree (DBD). This criterion consists of TF and IDF, which calculates the dependency of each document for each domain separately; this value is multiplied by the possible output that each capsule creates. In the end, the sum of these multiplications is the title of the final output, and is used to determine the polarity. And the most dependent domain is considered the final output for each domain. The proposed method was evaluated using the Digikala dataset and obtained acceptable accuracy compared to the existing approaches. It achieved an accuracy of 0.89 on detecting the domain of belonging and 0.99 on detecting the polarity. Also, for the problem of dealing with unbalanced classes, a cost-sensitive function was used. This function was able to achieve 0.0162 improvements in accuracy for sentiment classification. This approach on Amazon Arabic data can achieve 0.9695 accuracies in domain classification.
Attention-Enhancing Backdoor Attacks Against BERT-based Models
Oct 23, 2023Recent studies have revealed that \textit{Backdoor Attacks} can threaten the safety of natural language processing (NLP) models. Investigating the strategies of backdoor attacks will help to understand the model's vulnerability. Most existing textual backdoor attacks focus on generating stealthy triggers or modifying model weights. In this paper, we directly target the interior structure of neural networks and the backdoor mechanism. We propose a novel Trojan Attention Loss (TAL), which enhances the Trojan behavior by directly manipulating the attention patterns. Our loss can be applied to different attacking methods to boost their attack efficacy in terms of attack successful rates and poisoning rates. It applies to not only traditional dirty-label attacks, but also the more challenging clean-label attacks. We validate our method on different backbone models (BERT, RoBERTa, and DistilBERT) and various tasks (Sentiment Analysis, Toxic Detection, and Topic Classification).
UCAS-IIE-NLP at SemEval-2023 Task 12: Enhancing Generalization of Multilingual BERT for Low-resource Sentiment Analysis
Jun 01, 2023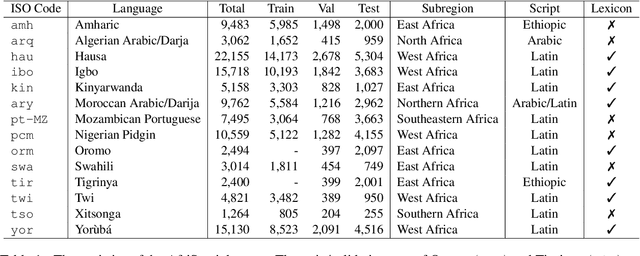
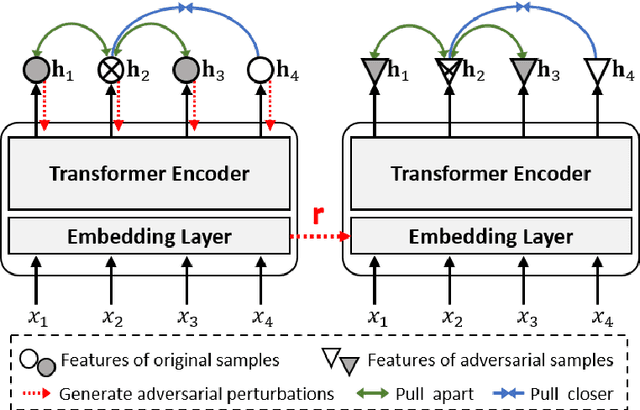

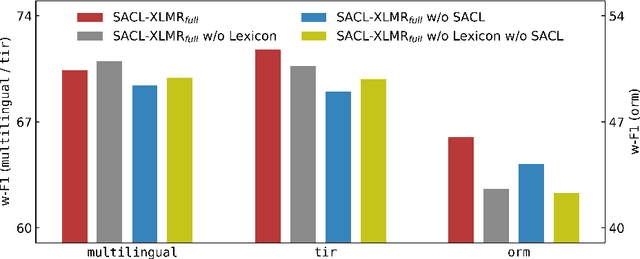
This paper describes our system designed for SemEval-2023 Task 12: Sentiment analysis for African languages. The challenge faced by this task is the scarcity of labeled data and linguistic resources in low-resource settings. To alleviate these, we propose a generalized multilingual system SACL-XLMR for sentiment analysis on low-resource languages. Specifically, we design a lexicon-based multilingual BERT to facilitate language adaptation and sentiment-aware representation learning. Besides, we apply a supervised adversarial contrastive learning technique to learn sentiment-spread structured representations and enhance model generalization. Our system achieved competitive results, largely outperforming baselines on both multilingual and zero-shot sentiment classification subtasks. Notably, the system obtained the 1st rank on the zero-shot classification subtask in the official ranking. Extensive experiments demonstrate the effectiveness of our system.
ViSoBERT: A Pre-Trained Language Model for Vietnamese Social Media Text Processing
Oct 28, 2023English and Chinese, known as resource-rich languages, have witnessed the strong development of transformer-based language models for natural language processing tasks. Although Vietnam has approximately 100M people speaking Vietnamese, several pre-trained models, e.g., PhoBERT, ViBERT, and vELECTRA, performed well on general Vietnamese NLP tasks, including POS tagging and named entity recognition. These pre-trained language models are still limited to Vietnamese social media tasks. In this paper, we present the first monolingual pre-trained language model for Vietnamese social media texts, ViSoBERT, which is pre-trained on a large-scale corpus of high-quality and diverse Vietnamese social media texts using XLM-R architecture. Moreover, we explored our pre-trained model on five important natural language downstream tasks on Vietnamese social media texts: emotion recognition, hate speech detection, sentiment analysis, spam reviews detection, and hate speech spans detection. Our experiments demonstrate that ViSoBERT, with far fewer parameters, surpasses the previous state-of-the-art models on multiple Vietnamese social media tasks. Our ViSoBERT model is available only for research purposes.
Is GPT Powerful Enough to Analyze the Emotions of Memes?
Nov 01, 2023Large Language Models (LLMs), representing a significant achievement in artificial intelligence (AI) research, have demonstrated their ability in a multitude of tasks. This project aims to explore the capabilities of GPT-3.5, a leading example of LLMs, in processing the sentiment analysis of Internet memes. Memes, which include both verbal and visual aspects, act as a powerful yet complex tool for expressing ideas and sentiments, demanding an understanding of societal norms and cultural contexts. Notably, the detection and moderation of hateful memes pose a significant challenge due to their implicit offensive nature. This project investigates GPT's proficiency in such subjective tasks, revealing its strengths and potential limitations. The tasks include the classification of meme sentiment, determination of humor type, and detection of implicit hate in memes. The performance evaluation, using datasets from SemEval-2020 Task 8 and Facebook hateful memes, offers a comparative understanding of GPT responses against human annotations. Despite GPT's remarkable progress, our findings underscore the challenges faced by these models in handling subjective tasks, which are rooted in their inherent limitations including contextual understanding, interpretation of implicit meanings, and data biases. This research contributes to the broader discourse on the applicability of AI in handling complex, context-dependent tasks, and offers valuable insights for future advancements.
Quantum Natural Language Processing based Sentiment Analysis using lambeq Toolkit
May 30, 2023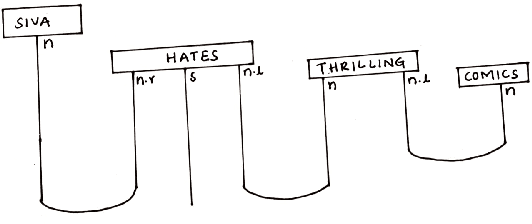
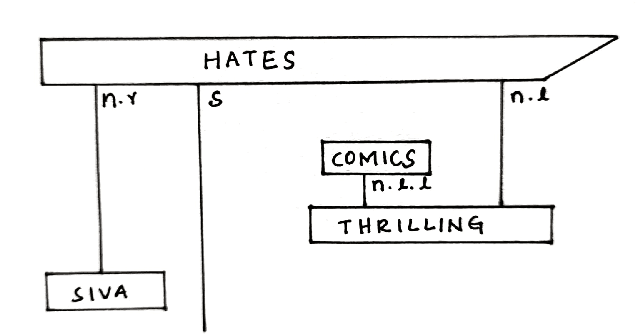
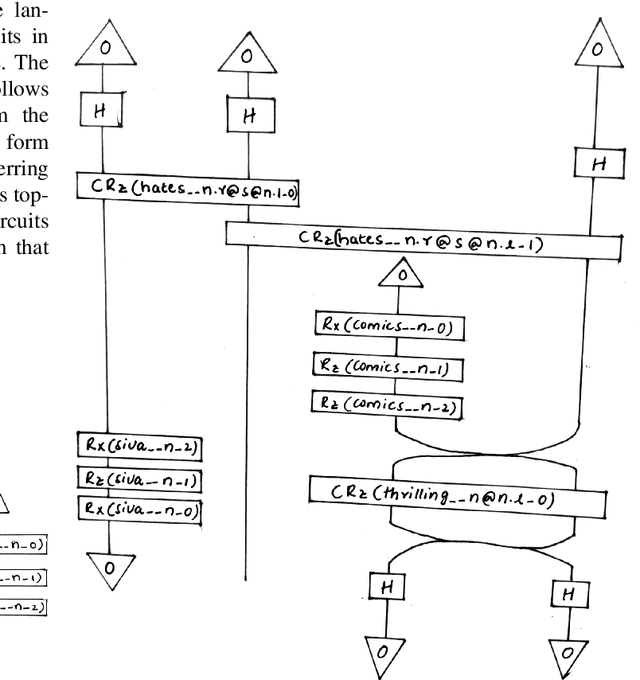

Sentiment classification is one the best use case of classical natural language processing (NLP) where we can witness its power in various daily life domains such as banking, business and marketing industry. We already know how classical AI and machine learning can change and improve technology. Quantum natural language processing (QNLP) is a young and gradually emerging technology which has the potential to provide quantum advantage for NLP tasks. In this paper we show the first application of QNLP for sentiment analysis and achieve perfect test set accuracy for three different kinds of simulations and a decent accuracy for experiments ran on a noisy quantum device. We utilize the lambeq QNLP toolkit and $t|ket>$ by Cambridge Quantum (Quantinuum) to bring out the results.
* 6 pages, 9 figures