 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
mahaNLP: A Marathi Natural Language Processing Library
Nov 05, 2023
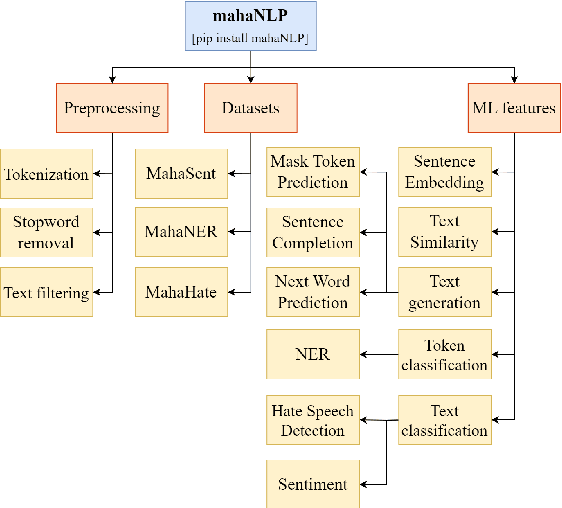
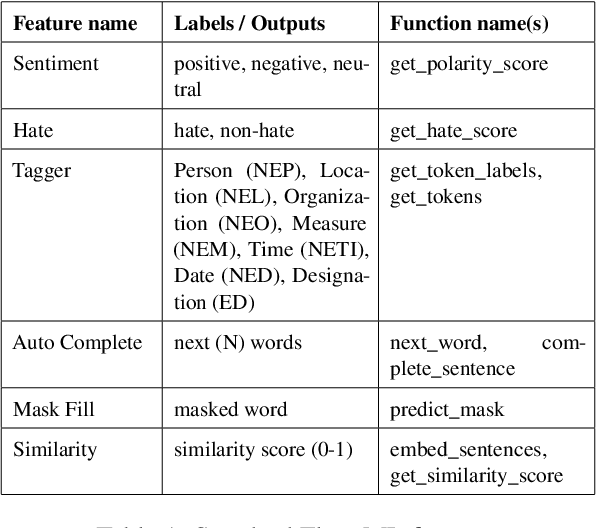
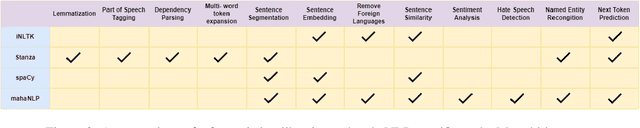

We present mahaNLP, an open-source natural language processing (NLP) library specifically built for the Marathi language. It aims to enhance the support for the low-resource Indian language Marathi in the field of NLP. It is an easy-to-use, extensible, and modular toolkit for Marathi text analysis built on state-of-the-art MahaBERT-based transformer models. Our work holds significant importance as other existing Indic NLP libraries provide basic Marathi processing support and rely on older models with restricted performance. Our toolkit stands out by offering a comprehensive array of NLP tasks, encompassing both fundamental preprocessing tasks and advanced NLP tasks like sentiment analysis, NER, hate speech detection, and sentence completion. This paper focuses on an overview of the mahaNLP framework, its features, and its usage. This work is a part of the L3Cube MahaNLP initiative, more information about it can be found at https://github.com/l3cube-pune/MarathiNLP .
Mental Health Diagnosis in the Digital Age: Harnessing Sentiment Analysis on Social Media Platforms upon Ultra-Sparse Feature Content
Nov 09, 2023Amid growing global mental health concerns, particularly among vulnerable groups, natural language processing offers a tremendous potential for early detection and intervention of people's mental disorders via analyzing their postings and discussions on social media platforms. However, ultra-sparse training data, often due to vast vocabularies and low-frequency words, hinders the analysis accuracy. Multi-labeling and Co-occurrences of symptoms may also blur the boundaries in distinguishing similar/co-related disorders. To address these issues, we propose a novel semantic feature preprocessing technique with a three-folded structure: 1) mitigating the feature sparsity with a weak classifier, 2) adaptive feature dimension with modulus loops, and 3) deep-mining and extending features among the contexts. With enhanced semantic features, we train a machine learning model to predict and classify mental disorders. We utilize the Reddit Mental Health Dataset 2022 to examine conditions such as Anxiety, Borderline Personality Disorder (BPD), and Bipolar-Disorder (BD) and present solutions to the data sparsity challenge, highlighted by 99.81% non-zero elements. After applying our preprocessing technique, the feature sparsity decreases to 85.4%. Overall, our methods, when compared to seven benchmark models, demonstrate significant performance improvements: 8.0% in accuracy, 0.069 in precision, 0.093 in recall, 0.102 in F1 score, and 0.059 in AUC. This research provides foundational insights for mental health prediction and monitoring, providing innovative solutions to navigate challenges associated with ultra-sparse data feature and intricate multi-label classification in the domain of mental health analysis.
iACOS: Advancing Implicit Sentiment Extraction with Informative and Adaptive Negative Examples
Nov 07, 2023Aspect-based sentiment analysis (ABSA) have been extensively studied, but little light has been shed on the quadruple extraction consisting of four fundamental elements: aspects, categories, opinions and sentiments, especially with implicit aspects and opinions. In this paper, we propose a new method iACOS for extracting Implicit Aspects with Categories and Opinions with Sentiments. First, iACOS appends two implicit tokens at the end of a text to capture the context-aware representation of all tokens including implicit aspects and opinions. Second, iACOS develops a sequence labeling model over the context-aware token representation to co-extract explicit and implicit aspects and opinions. Third, iACOS devises a multi-label classifier with a specialized multi-head attention for discovering aspect-opinion pairs and predicting their categories and sentiments simultaneously. Fourth, iACOS leverages informative and adaptive negative examples to jointly train the multi-label classifier and the other two classifiers on categories and sentiments by multi-task learning. Finally, the experimental results show that iACOS significantly outperforms other quadruple extraction baselines according to the F1 score on two public benchmark datasets.
Enhancing Zero-Shot Crypto Sentiment with Fine-tuned Language Model and Prompt Engineering
Oct 20, 2023Blockchain technology has revolutionized the financial landscape, with cryptocurrencies gaining widespread adoption for their decentralized and transparent nature. As the sentiment expressed on social media platforms can significantly influence cryptocurrency discussions and market movements, sentiment analysis has emerged as a crucial tool for understanding public opinion and predicting market trends. Motivated by the aim to enhance sentiment analysis accuracy in the cryptocurrency domain, this paper investigates fine-tuning techniques on large language models. This paper also investigates the efficacy of supervised fine-tuning and instruction-based fine-tuning on large language models for unseen tasks. Experimental results demonstrate a significant average zero-shot performance gain of 40% after fine-tuning, highlighting the potential of this technique in optimizing pre-trained language model efficiency. Additionally, the impact of instruction tuning on models of varying scales is examined, revealing that larger models benefit from instruction tuning, achieving the highest average accuracy score of 75.16%. In contrast, smaller-scale models may experience reduced generalization due to the complete utilization of model capacity. To gain deeper insight about how instruction works with these language models, this paper presents an experimental investigation into the response of an instruction-based model under different instruction tuning setups. The investigation demonstrates that the model achieves an average accuracy score of 72.38% for short and simple instructions. This performance significantly outperforms its accuracy under long and complex instructions by over 12%, thereby effectively highlighting the profound significance of instruction characteristics in maximizing model performance.
Bidirectional Generative Framework for Cross-domain Aspect-based Sentiment Analysis
May 16, 2023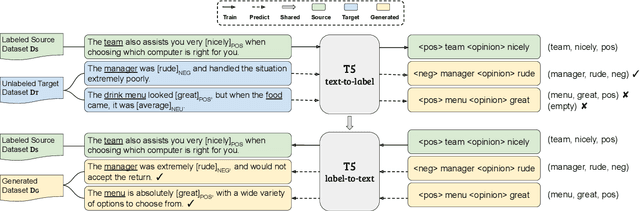


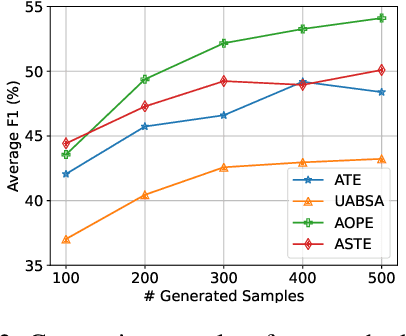
Cross-domain aspect-based sentiment analysis (ABSA) aims to perform various fine-grained sentiment analysis tasks on a target domain by transferring knowledge from a source domain. Since labeled data only exists in the source domain, a model is expected to bridge the domain gap for tackling cross-domain ABSA. Though domain adaptation methods have proven to be effective, most of them are based on a discriminative model, which needs to be specifically designed for different ABSA tasks. To offer a more general solution, we propose a unified bidirectional generative framework to tackle various cross-domain ABSA tasks. Specifically, our framework trains a generative model in both text-to-label and label-to-text directions. The former transforms each task into a unified format to learn domain-agnostic features, and the latter generates natural sentences from noisy labels for data augmentation, with which a more accurate model can be trained. To investigate the effectiveness and generality of our framework, we conduct extensive experiments on four cross-domain ABSA tasks and present new state-of-the-art results on all tasks. Our data and code are publicly available at \url{https://github.com/DAMO-NLP-SG/BGCA}.
CompCodeVet: A Compiler-guided Validation and Enhancement Approach for Code Dataset
Nov 11, 2023Large language models (LLMs) have become increasingly prominent in academia and industry due to their remarkable performance in diverse applications. As these models evolve with increasing parameters, they excel in tasks like sentiment analysis and machine translation. However, even models with billions of parameters face challenges in tasks demanding multi-step reasoning. Code generation and comprehension, especially in C and C++, emerge as significant challenges. While LLMs trained on code datasets demonstrate competence in many tasks, they struggle with rectifying non-compilable C and C++ code. Our investigation attributes this subpar performance to two primary factors: the quality of the training dataset and the inherent complexity of the problem which demands intricate reasoning. Existing "Chain of Thought" (CoT) prompting techniques aim to enhance multi-step reasoning. This approach, however, retains the limitations associated with the latent drawbacks of LLMs. In this work, we propose CompCodeVet, a compiler-guided CoT approach to produce compilable code from non-compilable ones. Diverging from the conventional approach of utilizing larger LLMs, we employ compilers as a teacher to establish a more robust zero-shot thought process. The evaluation of CompCodeVet on two open-source code datasets shows that CompCodeVet has the ability to improve the training dataset quality for LLMs.
Support for Stock Trend Prediction Using Transformers and Sentiment Analysis
May 18, 2023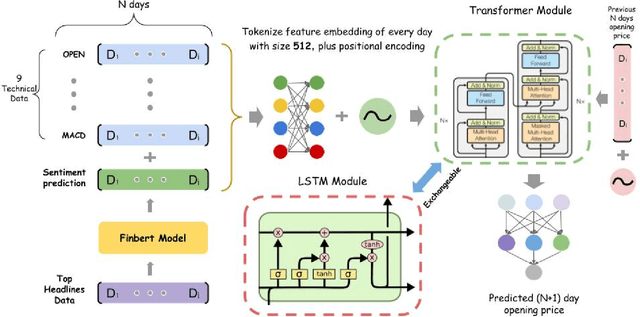
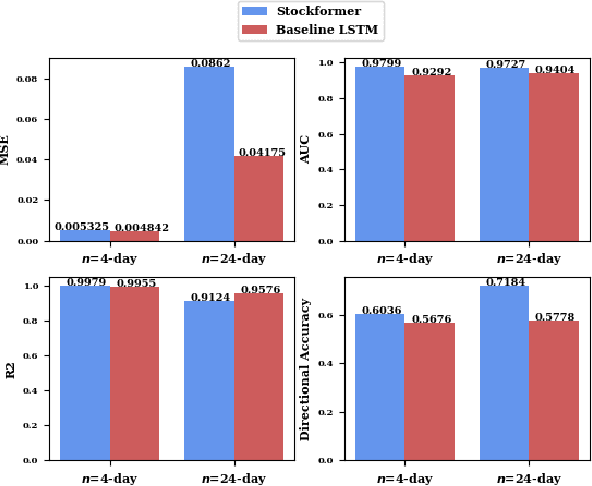
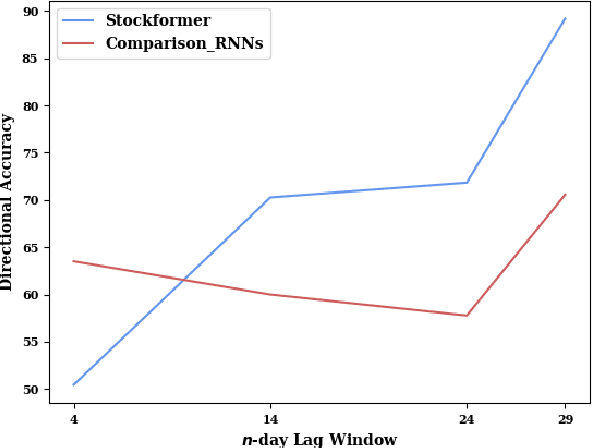

Stock trend analysis has been an influential time-series prediction topic due to its lucrative and inherently chaotic nature. Many models looking to accurately predict the trend of stocks have been based on Recurrent Neural Networks (RNNs). However, due to the limitations of RNNs, such as gradient vanish and long-term dependencies being lost as sequence length increases, in this paper we develop a Transformer based model that uses technical stock data and sentiment analysis to conduct accurate stock trend prediction over long time windows. This paper also introduces a novel dataset containing daily technical stock data and top news headline data spanning almost three years. Stock prediction based solely on technical data can suffer from lag caused by the inability of stock indicators to effectively factor in breaking market news. The use of sentiment analysis on top headlines can help account for unforeseen shifts in market conditions caused by news coverage. We measure the performance of our model against RNNs over sequence lengths spanning 5 business days to 30 business days to mimic different length trading strategies. This reveals an improvement in directional accuracy over RNNs as sequence length is increased, with the largest improvement being close to 18.63% at 30 business days.
Towards Robust Aspect-based Sentiment Analysis through Non-counterfactual Augmentations
Jun 24, 2023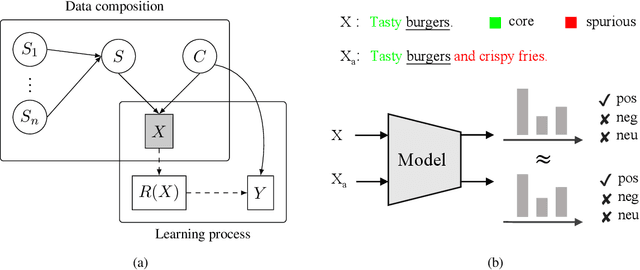

While state-of-the-art NLP models have demonstrated excellent performance for aspect based sentiment analysis (ABSA), substantial evidence has been presented on their lack of robustness. This is especially manifested as significant degradation in performance when faced with out-of-distribution data. Recent solutions that rely on counterfactually augmented datasets show promising results, but they are inherently limited because of the lack of access to explicit causal structure. In this paper, we present an alternative approach that relies on non-counterfactual data augmentation. Our proposal instead relies on using noisy, cost-efficient data augmentations that preserve semantics associated with the target aspect. Our approach then relies on modelling invariances between different versions of the data to improve robustness. A comprehensive suite of experiments shows that our proposal significantly improves upon strong pre-trained baselines on both standard and robustness-specific datasets. Our approach further establishes a new state-of-the-art on the ABSA robustness benchmark and transfers well across domains.
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
Nov 07, 2023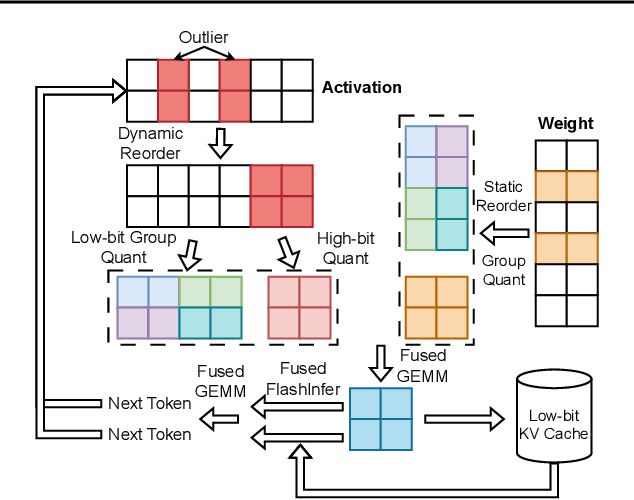
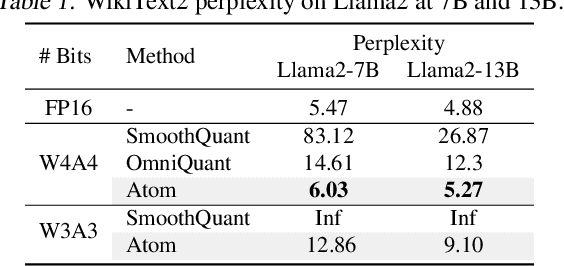
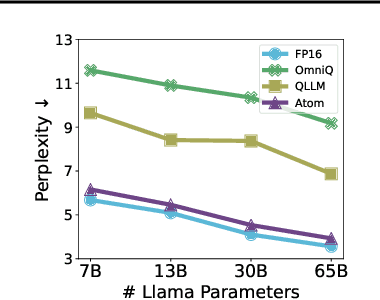
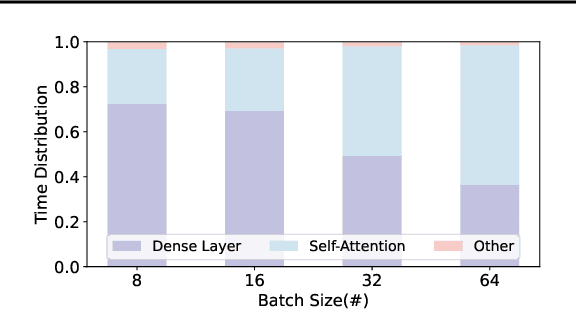
The growing demand for Large Language Models (LLMs) in applications such as content generation, intelligent chatbots, and sentiment analysis poses considerable challenges for LLM service providers. To efficiently use GPU resources and boost throughput, batching multiple requests has emerged as a popular paradigm; to further speed up batching, LLM quantization techniques reduce memory consumption and increase computing capacity. However, prevalent quantization schemes (e.g., 8-bit weight-activation quantization) cannot fully leverage the capabilities of modern GPUs, such as 4-bit integer operators, resulting in sub-optimal performance. To maximize LLMs' serving throughput, we introduce Atom, a low-bit quantization method that achieves high throughput improvements with negligible accuracy loss. Atom significantly boosts serving throughput by using low-bit operators and considerably reduces memory consumption via low-bit quantization. It attains high accuracy by applying a novel mixed-precision and fine-grained quantization process. We evaluate Atom on 4-bit weight-activation quantization setups in the serving context. Atom improves end-to-end throughput by up to $7.73\times$ compared to the FP16 and by $2.53\times$ compared to INT8 quantization, while maintaining the same latency target.
Can Large Language Models Explain Themselves? A Study of LLM-Generated Self-Explanations
Oct 17, 2023Large language models (LLMs) such as ChatGPT have demonstrated superior performance on a variety of natural language processing (NLP) tasks including sentiment analysis, mathematical reasoning and summarization. Furthermore, since these models are instruction-tuned on human conversations to produce "helpful" responses, they can and often will produce explanations along with the response, which we call self-explanations. For example, when analyzing the sentiment of a movie review, the model may output not only the positivity of the sentiment, but also an explanation (e.g., by listing the sentiment-laden words such as "fantastic" and "memorable" in the review). How good are these automatically generated self-explanations? In this paper, we investigate this question on the task of sentiment analysis and for feature attribution explanation, one of the most commonly studied settings in the interpretability literature (for pre-ChatGPT models). Specifically, we study different ways to elicit the self-explanations, evaluate their faithfulness on a set of evaluation metrics, and compare them to traditional explanation methods such as occlusion or LIME saliency maps. Through an extensive set of experiments, we find that ChatGPT's self-explanations perform on par with traditional ones, but are quite different from them according to various agreement metrics, meanwhile being much cheaper to produce (as they are generated along with the prediction). In addition, we identified several interesting characteristics of them, which prompt us to rethink many current model interpretability practices in the era of ChatGPT(-like) LLMs.