 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
General Debiasing for Multimodal Sentiment Analysis
Jul 20, 2023
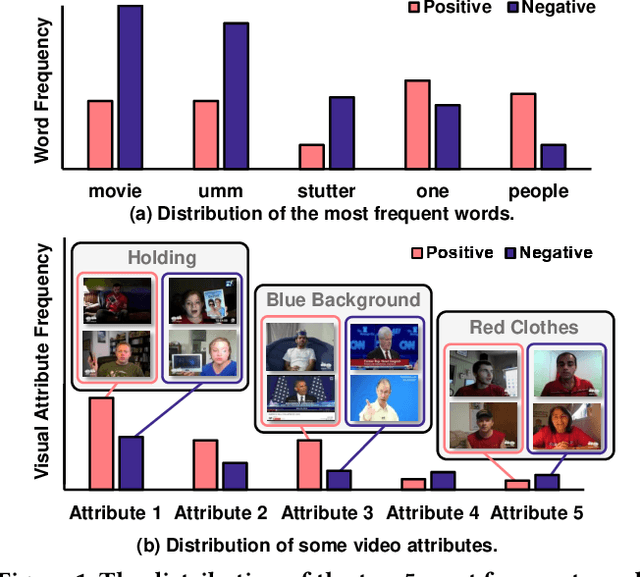

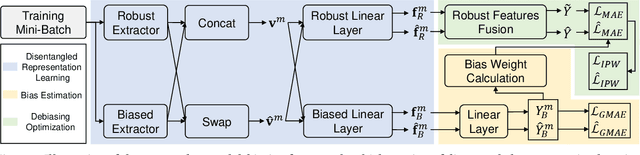
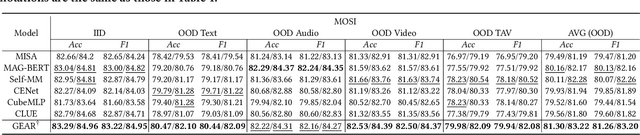
Existing work on Multimodal Sentiment Analysis (MSA) utilizes multimodal information for prediction yet unavoidably suffers from fitting the spurious correlations between multimodal features and sentiment labels. For example, if most videos with a blue background have positive labels in a dataset, the model will rely on such correlations for prediction, while ``blue background'' is not a sentiment-related feature. To address this problem, we define a general debiasing MSA task, which aims to enhance the Out-Of-Distribution (OOD) generalization ability of MSA models by reducing their reliance on spurious correlations. To this end, we propose a general debiasing framework based on Inverse Probability Weighting (IPW), which adaptively assigns small weights to the samples with larger bias i.e., the severer spurious correlations). The key to this debiasing framework is to estimate the bias of each sample, which is achieved by two steps: 1) disentangling the robust features and biased features in each modality, and 2) utilizing the biased features to estimate the bias. Finally, we employ IPW to reduce the effects of large-biased samples, facilitating robust feature learning for sentiment prediction. To examine the model's generalization ability, we keep the original testing sets on two benchmarks and additionally construct multiple unimodal and multimodal OOD testing sets. The empirical results demonstrate the superior generalization ability of our proposed framework. We have released the code and data to facilitate the reproduction.
PipeOptim: Ensuring Effective 1F1B Schedule with Optimizer-Dependent Weight Prediction
Dec 05, 2023Asynchronous pipeline model parallelism with a "1F1B" (one forward, one backward) schedule generates little bubble overhead and always provides quite a high throughput. However, the "1F1B" schedule inevitably leads to weight inconsistency and weight staleness issues due to the cross-training of different mini-batches across GPUs. To simultaneously address these two problems, in this paper, we propose an optimizer-dependent weight prediction strategy (a.k.a PipeOptim) for asynchronous pipeline training. The key insight of our proposal is that we employ a weight prediction strategy in the forward pass to ensure that each mini-batch uses consistent and staleness-free weights to compute the forward pass. To be concrete, we first construct the weight prediction scheme based on the update rule of the used optimizer when training the deep neural network models. Then throughout the "1F1B" pipelined training, each mini-batch is mandated to execute weight prediction ahead of the forward pass, subsequently employing the predicted weights to perform the forward pass. As a result, PipeOptim 1) inherits the advantage of the "1F1B" schedule and generates pretty high throughput, and 2) can ensure effective parameter learning regardless of the type of the used optimizer. To verify the effectiveness of our proposal, we conducted extensive experimental evaluations using eight different deep-learning models spanning three machine-learning tasks including image classification, sentiment analysis, and machine translation. The experiment results demonstrate that PipeOptim outperforms the popular pipelined approaches including GPipe, PipeDream, PipeDream-2BW, and SpecTrain. The code of PipeOptim can be accessible at https://github.com/guanleics/PipeOptim.
Improving Unimodal Inference with Multimodal Transformers
Nov 16, 2023This paper proposes an approach for improving performance of unimodal models with multimodal training. Our approach involves a multi-branch architecture that incorporates unimodal models with a multimodal transformer-based branch. By co-training these branches, the stronger multimodal branch can transfer its knowledge to the weaker unimodal branches through a multi-task objective, thereby improving the performance of the resulting unimodal models. We evaluate our approach on tasks of dynamic hand gesture recognition based on RGB and Depth, audiovisual emotion recognition based on speech and facial video, and audio-video-text based sentiment analysis. Our approach outperforms the conventionally trained unimodal counterparts. Interestingly, we also observe that optimization of the unimodal branches improves the multimodal branch, compared to a similar multimodal model trained from scratch.
Convolutional Neural Networks for Sentiment Analysis on Weibo Data: A Natural Language Processing Approach
Jul 13, 2023This study addressed the complex task of sentiment analysis on a dataset of 119,988 original tweets from Weibo using a Convolutional Neural Network (CNN), offering a new approach to Natural Language Processing (NLP). The data, sourced from Baidu's PaddlePaddle AI platform, were meticulously preprocessed, tokenized, and categorized based on sentiment labels. A CNN-based model was utilized, leveraging word embeddings for feature extraction, and trained to perform sentiment classification. The model achieved a macro-average F1-score of approximately 0.73 on the test set, showing balanced performance across positive, neutral, and negative sentiments. The findings underscore the effectiveness of CNNs for sentiment analysis tasks, with implications for practical applications in social media analysis, market research, and policy studies. The complete experimental content and code have been made publicly available on the Kaggle data platform for further research and development. Future work may involve exploring different architectures, such as Recurrent Neural Networks (RNN) or transformers, or using more complex pre-trained models like BERT, to further improve the model's ability to understand linguistic nuances and context.
Adversarial Capsule Networks for Romanian Satire Detection and Sentiment Analysis
Jun 13, 2023Satire detection and sentiment analysis are intensively explored natural language processing (NLP) tasks that study the identification of the satirical tone from texts and extracting sentiments in relationship with their targets. In languages with fewer research resources, an alternative is to produce artificial examples based on character-level adversarial processes to overcome dataset size limitations. Such samples are proven to act as a regularization method, thus improving the robustness of models. In this work, we improve the well-known NLP models (i.e., Convolutional Neural Networks, Long Short-Term Memory (LSTM), Bidirectional LSTM, Gated Recurrent Units (GRUs), and Bidirectional GRUs) with adversarial training and capsule networks. The fine-tuned models are used for satire detection and sentiment analysis tasks in the Romanian language. The proposed framework outperforms the existing methods for the two tasks, achieving up to 99.08% accuracy, thus confirming the improvements added by the capsule layers and the adversarial training in NLP approaches.
Sentiment Analysis Using Aligned Word Embeddings for Uralic Languages
May 24, 2023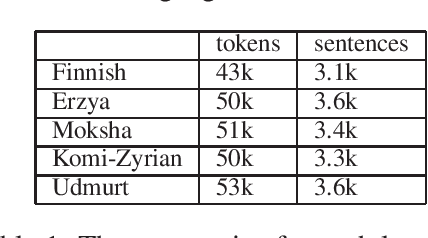
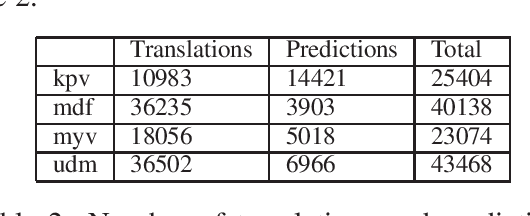
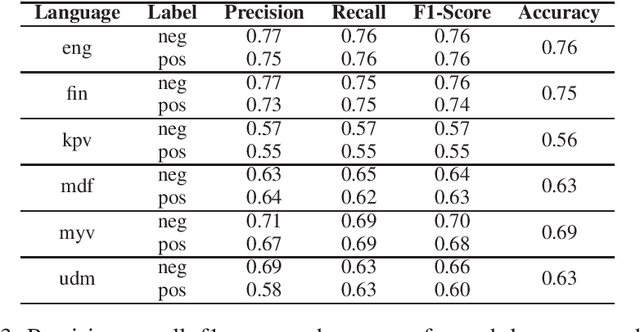
In this paper, we present an approach for translating word embeddings from a majority language into 4 minority languages: Erzya, Moksha, Udmurt and Komi-Zyrian. Furthermore, we align these word embeddings and present a novel neural network model that is trained on English data to conduct sentiment analysis and then applied on endangered language data through the aligned word embeddings. To test our model, we annotated a small sentiment analysis corpus for the 4 endangered languages and Finnish. Our method reached at least 56\% accuracy for each endangered language. The models and the sentiment corpus will be released together with this paper. Our research shows that state-of-the-art neural models can be used with endangered languages with the only requirement being a dictionary between the endangered language and a majority language.
Sentiment Analysis in the Era of Large Language Models: A Reality Check
May 24, 2023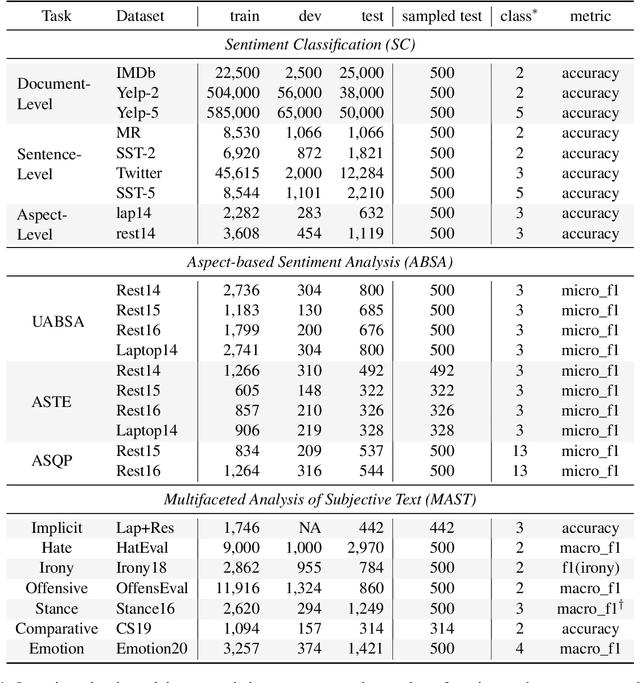
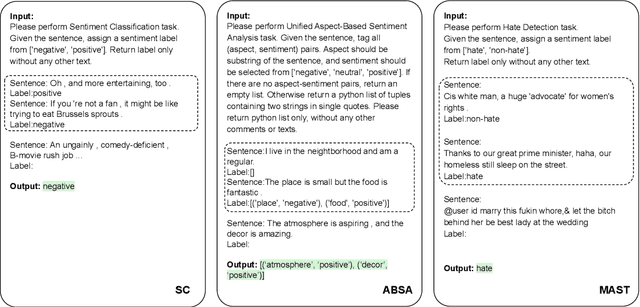
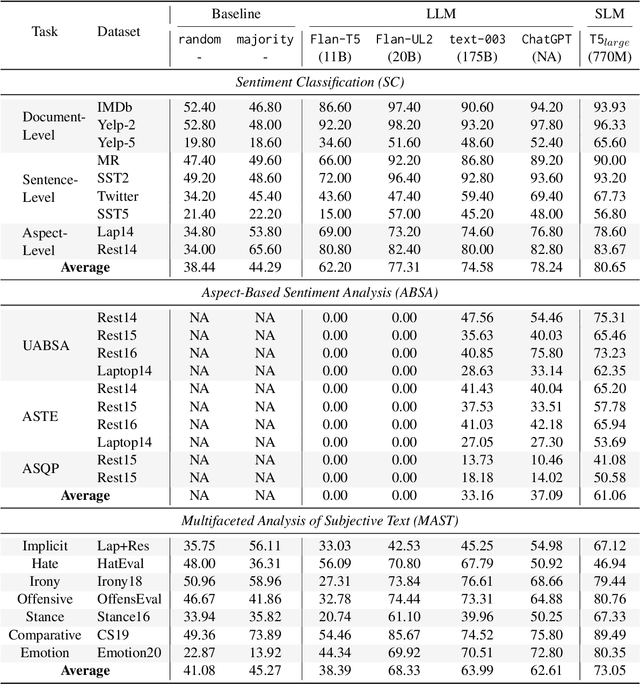
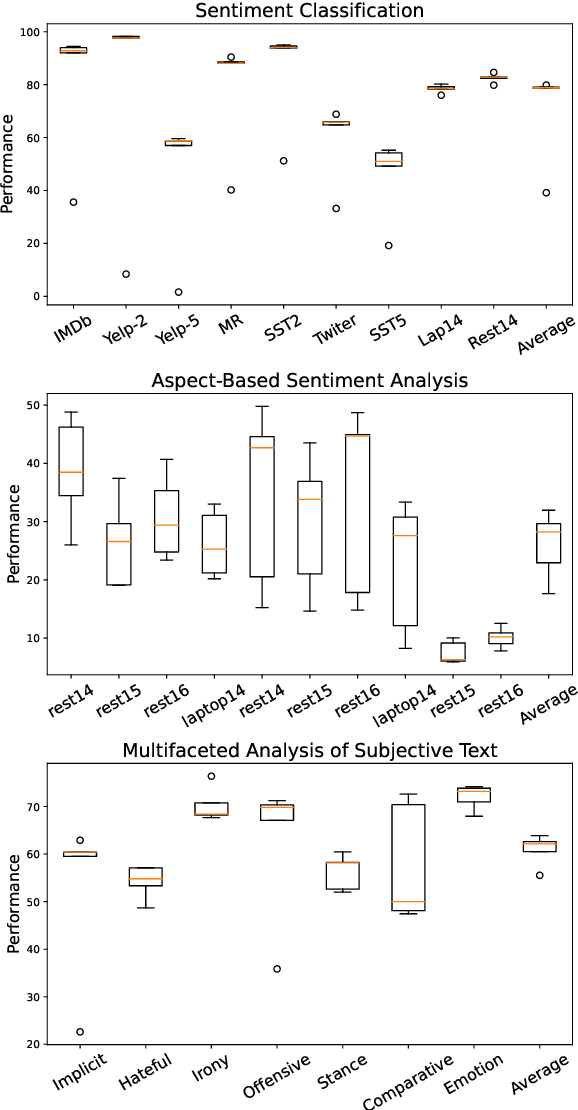
Sentiment analysis (SA) has been a long-standing research area in natural language processing. It can offer rich insights into human sentiments and opinions and has thus seen considerable interest from both academia and industry. With the advent of large language models (LLMs) such as ChatGPT, there is a great potential for their employment on SA problems. However, the extent to which existing LLMs can be leveraged for different sentiment analysis tasks remains unclear. This paper aims to provide a comprehensive investigation into the capabilities of LLMs in performing various sentiment analysis tasks, from conventional sentiment classification to aspect-based sentiment analysis and multifaceted analysis of subjective texts. We evaluate performance across 13 tasks on 26 datasets and compare the results against small language models (SLMs) trained on domain-specific datasets. Our study reveals that while LLMs demonstrate satisfactory performance in simpler tasks, they lag behind in more complex tasks requiring deeper understanding or structured sentiment information. However, LLMs significantly outperform SLMs in few-shot learning settings, suggesting their potential when annotation resources are limited. We also highlight the limitations of current evaluation practices in assessing LLMs' SA abilities and propose a novel benchmark, \textsc{SentiEval}, for a more comprehensive and realistic evaluation. Data and code during our investigations are available at \url{https://github.com/DAMO-NLP-SG/LLM-Sentiment}.
Enhancing search engine precision and user experience through sentiment-based polysemy resolution
Nov 03, 2023With the proliferation of digital content and the need for efficient information retrieval, this study's insights can be applied to various domains, including news services, e-commerce, and digital marketing, to provide users with more meaningful and tailored experiences. The study addresses the common problem of polysemy in search engines, where the same keyword may have multiple meanings. It proposes a solution to this issue by embedding a smart search function into the search engine, which can differentiate between different meanings based on sentiment. The study leverages sentiment analysis, a powerful natural language processing (NLP) technique, to classify and categorize news articles based on their emotional tone. This can provide more insightful and nuanced search results. The article reports an impressive accuracy rate of 85% for the proposed smart search function, which outperforms conventional search engines. This indicates the effectiveness of the sentiment-based approach. The research explores multiple sentiment analysis models, including Sentistrength and Valence Aware Dictionary for Sentiment Reasoning (VADER), to determine the best-performing approach. The findings can be applied to enhance search engines, making them more capable of understanding the context and intent behind users 'queries. This can lead to better search results that are more aligned with what users are looking for. The proposed smart search function can improve the user experience by reducing the need to sift through irrelevant search results. This is particularly important in an age where information overload is common.
Sentiment analysis with adaptive multi-head attention in Transformer
Oct 23, 2023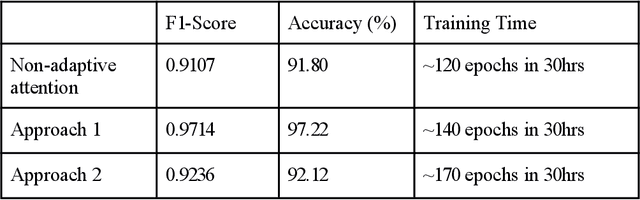
We propose a novel framework based on the attention mechanism to identify the sentiment of a movie review document. Previous efforts on deep neural networks with attention mechanisms focus on encoder and decoder with fixed numbers of multi-head attention. Therefore, we need a mechanism to stop the attention process automatically if no more useful information can be read from the memory.In this paper, we propose an adaptive multi-head attention architecture (AdaptAttn) which varies the number of attention heads based on length of sentences. AdaptAttn has a data preprocessing step where each document is classified into any one of the three bins small, medium or large based on length of the sentence. The document classified as small goes through two heads in each layer, the medium group passes four heads and the large group is processed by eight heads. We examine the merit of our model on the Stanford large movie review dataset. The experimental results show that the F1 score from our model is on par with the baseline model.
The Limits of ChatGPT in Extracting Aspect-Category-Opinion-Sentiment Quadruples: A Comparative Analysis
Oct 10, 2023
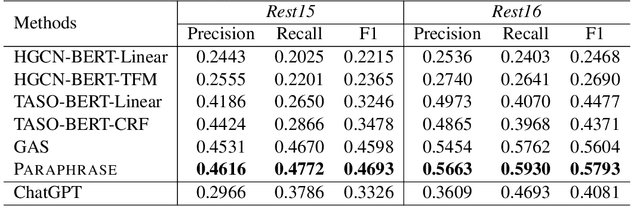
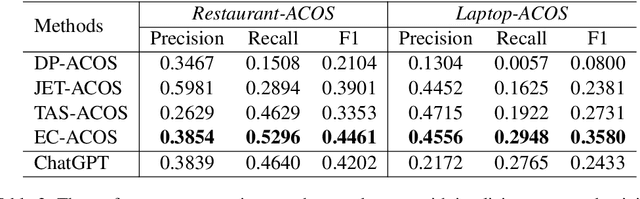
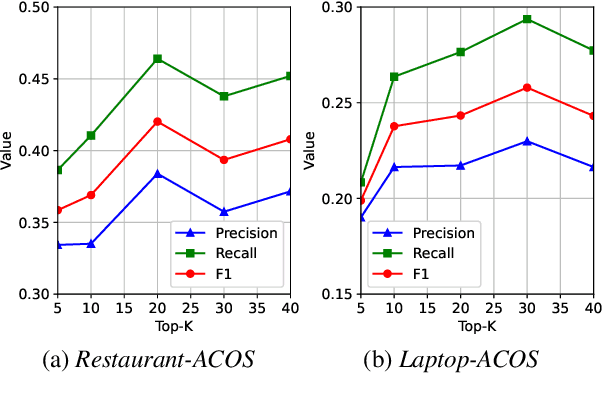
Recently, ChatGPT has attracted great attention from both industry and academia due to its surprising abilities in natural language understanding and generation. We are particularly curious about whether it can achieve promising performance on one of the most complex tasks in aspect-based sentiment analysis, i.e., extracting aspect-category-opinion-sentiment quadruples from texts. To this end, in this paper we develop a specialized prompt template that enables ChatGPT to effectively tackle this complex quadruple extraction task. Further, we propose a selection method on few-shot examples to fully exploit the in-context learning ability of ChatGPT and uplift its effectiveness on this complex task. Finally, we provide a comparative evaluation on ChatGPT against existing state-of-the-art quadruple extraction models based on four public datasets and highlight some important findings regarding the capability boundaries of ChatGPT in the quadruple extraction.