 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Optimal Strategies to Perform Multilingual Analysis of Social Content for a Novel Dataset in the Tourism Domain
Nov 20, 2023
The rising influence of social media platforms in various domains, including tourism, has highlighted the growing need for efficient and automated natural language processing (NLP) approaches to take advantage of this valuable resource. However, the transformation of multilingual, unstructured, and informal texts into structured knowledge often poses significant challenges. In this work, we evaluate and compare few-shot, pattern-exploiting and fine-tuning machine learning techniques on large multilingual language models (LLMs) to establish the best strategy to address the lack of annotated data for 3 common NLP tasks in the tourism domain: (1) Sentiment Analysis, (2) Named Entity Recognition, and (3) Fine-grained Thematic Concept Extraction (linked to a semantic resource). Furthermore, we aim to ascertain the quantity of annotated examples required to achieve good performance in those 3 tasks, addressing a common challenge encountered by NLP researchers in the construction of domain-specific datasets. Extensive experimentation on a newly collected and annotated multilingual (French, English, and Spanish) dataset composed of tourism-related tweets shows that current few-shot learning techniques allow us to obtain competitive results for all three tasks with very little annotation data: 5 tweets per label (15 in total) for Sentiment Analysis, 10% of the tweets for location detection (around 160) and 13% (200 approx.) of the tweets annotated with thematic concepts, a highly fine-grained sequence labeling task based on an inventory of 315 classes. This comparative analysis, grounded in a novel dataset, paves the way for applying NLP to new domain-specific applications, reducing the need for manual annotations and circumventing the complexities of rule-based, ad hoc solutions.
L3Cube-MahaSent-MD: A Multi-domain Marathi Sentiment Analysis Dataset and Transformer Models
Jun 24, 2023

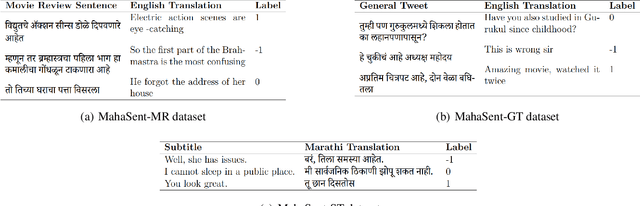
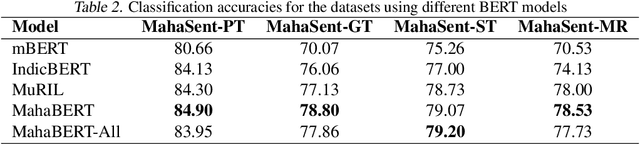
The exploration of sentiment analysis in low-resource languages, such as Marathi, has been limited due to the availability of suitable datasets. In this work, we present L3Cube-MahaSent-MD, a multi-domain Marathi sentiment analysis dataset, with four different domains - movie reviews, general tweets, TV show subtitles, and political tweets. The dataset consists of around 60,000 manually tagged samples covering 3 distinct sentiments - positive, negative, and neutral. We create a sub-dataset for each domain comprising 15k samples. The MahaSent-MD is the first comprehensive multi-domain sentiment analysis dataset within the Indic sentiment landscape. We fine-tune different monolingual and multilingual BERT models on these datasets and report the best accuracy with the MahaBERT model. We also present an extensive in-domain and cross-domain analysis thus highlighting the need for low-resource multi-domain datasets. The data and models are available at https://github.com/l3cube-pune/MarathiNLP .
Experimenting with UD Adaptation of an Unsupervised Rule-based Approach for Sentiment Analysis of Mexican Tourist Texts
Sep 11, 2023

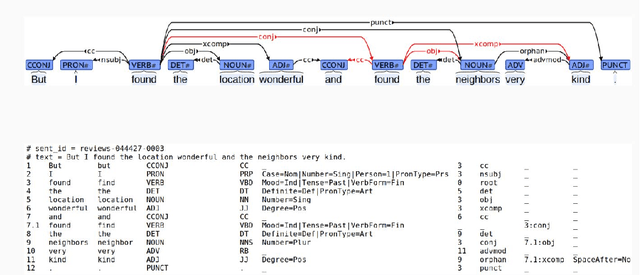

This paper summarizes the results of experimenting with Universal Dependencies (UD) adaptation of an Unsupervised, Compositional and Recursive (UCR) rule-based approach for Sentiment Analysis (SA) submitted to the Shared Task at Rest-Mex 2023 (Team Olga/LyS-SALSA) (within the IberLEF 2023 conference). By using basic syntactic rules such as rules of modification and negation applied on words from sentiment dictionaries, our approach exploits some advantages of an unsupervised method for SA: (1) interpretability and explainability of SA, (2) robustness across datasets, languages and domains and (3) usability by non-experts in NLP. We compare our approach with other unsupervised approaches of SA that in contrast to our UCR rule-based approach use simple heuristic rules to deal with negation and modification. Our results show a considerable improvement over these approaches. We discuss future improvements of our results by using modality features as another shifting rule of polarity and word disambiguation techniques to identify the right sentiment words.
Understanding Opinions Towards Climate Change on Social Media
Dec 02, 2023Social media platforms such as Twitter (now known as X) have revolutionized how the public engage with important societal and political topics. Recently, climate change discussions on social media became a catalyst for political polarization and the spreading of misinformation. In this work, we aim to understand how real world events influence the opinions of individuals towards climate change related topics on social media. To this end, we extracted and analyzed a dataset of 13.6 millions tweets sent by 3.6 million users from 2006 to 2019. Then, we construct a temporal graph from the user-user mentions network and utilize the Louvain community detection algorithm to analyze the changes in community structure around Conference of the Parties on Climate Change~(COP) events. Next, we also apply tools from the Natural Language Processing literature to perform sentiment analysis and topic modeling on the tweets. Our work acts as a first step towards understanding the evolution of pro-climate change communities around COP events. Answering these questions helps us understand how to raise people's awareness towards climate change thus hopefully calling on more individuals to join the collaborative effort in slowing down climate change.
Predict the Future from the Past? On the Temporal Data Distribution Shift in Financial Sentiment Classifications
Oct 19, 2023Temporal data distribution shift is prevalent in the financial text. How can a financial sentiment analysis system be trained in a volatile market environment that can accurately infer sentiment and be robust to temporal data distribution shifts? In this paper, we conduct an empirical study on the financial sentiment analysis system under temporal data distribution shifts using a real-world financial social media dataset that spans three years. We find that the fine-tuned models suffer from general performance degradation in the presence of temporal distribution shifts. Furthermore, motivated by the unique temporal nature of the financial text, we propose a novel method that combines out-of-distribution detection with time series modeling for temporal financial sentiment analysis. Experimental results show that the proposed method enhances the model's capability to adapt to evolving temporal shifts in a volatile financial market.
Real-Time Online Stock Forecasting Utilizing Integrated Quantitative and Qualitative Analysis
Dec 05, 2023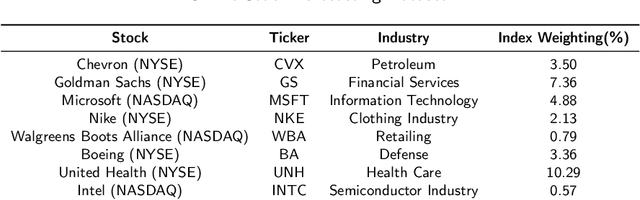
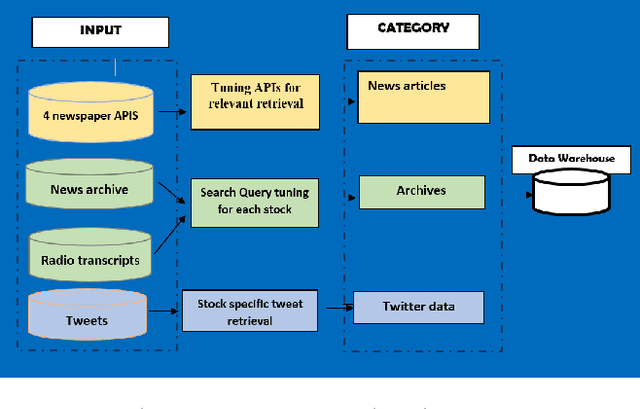
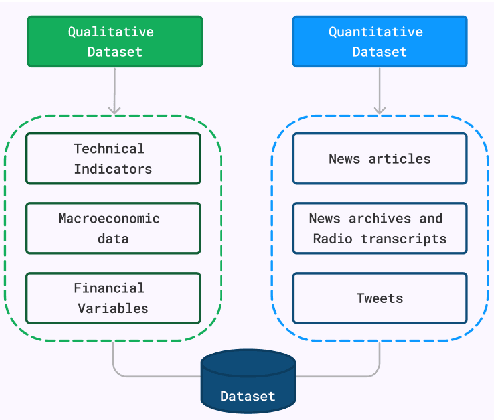
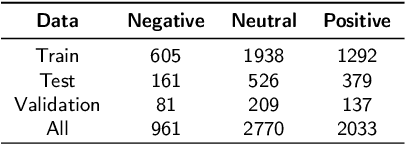
The application of Machine learning to finance has become a familiar approach, even more so in stock market forecasting. The stock market is highly volatile and huge amounts of data are generated every minute globally. The extraction of effective intelligence from this data is of critical importance. However, a collaboration of numerical stock data with qualitative text data can be a challenging task. In this work, we accomplish this and provide an unprecedented, publicly available dataset with technical and fundamental data, sentiment that we gathered from News Archives, TV news captions, Radio Transcripts, Tweets, Daily financial newspapers, etc. The text data entries used for sentiment extraction total more than 1.4 Million. The dataset consists of daily entries from January 2018 to December 2022 for 8 companies representing diverse industrial sectors and the Dow Jones Industrial Average (DJIA) as a whole. Holistic Fundamental and Technical data is provided training ready for Model learning and deployment. The data generated could be used for Incremental online learning with real-time data points retrieved daily, since there was no stagnant data utilized, all the data was retired from APIs or self-designed scripts. Moreover, the utilization of Spearman's rank correlation over real-time data, linking stock returns with sentiment analysis has produced noteworthy results for the DJIA achieving accuracy levels surpassing 60\%. The dataset is made available at https://github.com/batking24/Huge-Stock-Dataset
SOUL: Towards Sentiment and Opinion Understanding of Language
Oct 27, 2023
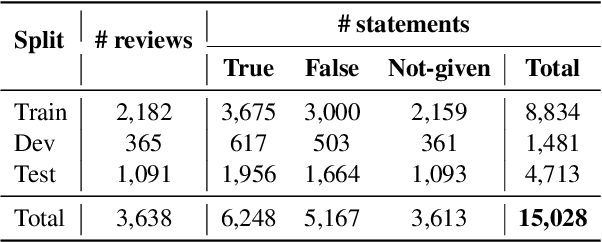
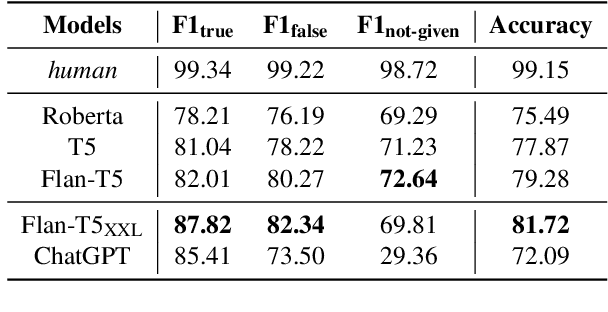
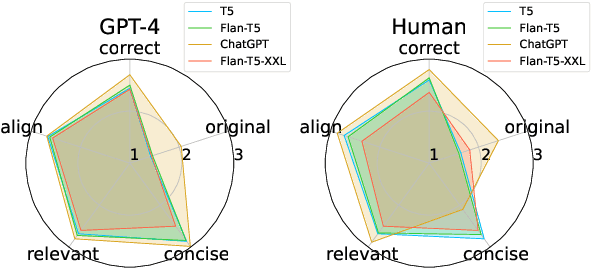
Sentiment analysis is a well-established natural language processing task, with sentiment polarity classification being one of its most popular and representative tasks. However, despite the success of pre-trained language models in this area, they often fall short of capturing the broader complexities of sentiment analysis. To address this issue, we propose a new task called Sentiment and Opinion Understanding of Language (SOUL). SOUL aims to evaluate sentiment understanding through two subtasks: Review Comprehension (RC) and Justification Generation (JG). RC seeks to validate statements that focus on subjective information based on a review text, while JG requires models to provide explanations for their sentiment predictions. To enable comprehensive evaluation, we annotate a new dataset comprising 15,028 statements from 3,638 reviews. Experimental results indicate that SOUL is a challenging task for both small and large language models, with a performance gap of up to 27% when compared to human performance. Furthermore, evaluations conducted with both human experts and GPT-4 highlight the limitations of the small language model in generating reasoning-based justifications. These findings underscore the challenging nature of the SOUL task for existing models, emphasizing the need for further advancements in sentiment analysis to address its complexities. The new dataset and code are available at https://github.com/DAMO-NLP-SG/SOUL.
Unveiling Public Perceptions: Machine Learning-Based Sentiment Analysis of COVID-19 Vaccines in India
Nov 19, 2023In March 2020, the World Health Organisation declared COVID-19 a global pandemic as it spread to nearly every country. By mid-2021, India had introduced three vaccines: Covishield, Covaxin, and Sputnik. To ensure successful vaccination in a densely populated country like India, understanding public sentiment was crucial. Social media, particularly Reddit with over 430 million users, played a vital role in disseminating information. This study employs data mining techniques to analyze Reddit data and gauge Indian sentiments towards COVID-19 vaccines. Using Python's Text Blob library, comments are annotated to assess general sentiments. Results show that most Reddit users in India expressed neutrality about vaccination, posing a challenge for the Indian government's efforts to vaccinate a significant portion of the population.
PipeOptim: Ensuring Effective 1F1B Schedule with Optimizer-Dependent Weight Prediction
Dec 05, 2023Asynchronous pipeline model parallelism with a "1F1B" (one forward, one backward) schedule generates little bubble overhead and always provides quite a high throughput. However, the "1F1B" schedule inevitably leads to weight inconsistency and weight staleness issues due to the cross-training of different mini-batches across GPUs. To simultaneously address these two problems, in this paper, we propose an optimizer-dependent weight prediction strategy (a.k.a PipeOptim) for asynchronous pipeline training. The key insight of our proposal is that we employ a weight prediction strategy in the forward pass to ensure that each mini-batch uses consistent and staleness-free weights to compute the forward pass. To be concrete, we first construct the weight prediction scheme based on the update rule of the used optimizer when training the deep neural network models. Then throughout the "1F1B" pipelined training, each mini-batch is mandated to execute weight prediction ahead of the forward pass, subsequently employing the predicted weights to perform the forward pass. As a result, PipeOptim 1) inherits the advantage of the "1F1B" schedule and generates pretty high throughput, and 2) can ensure effective parameter learning regardless of the type of the used optimizer. To verify the effectiveness of our proposal, we conducted extensive experimental evaluations using eight different deep-learning models spanning three machine-learning tasks including image classification, sentiment analysis, and machine translation. The experiment results demonstrate that PipeOptim outperforms the popular pipelined approaches including GPipe, PipeDream, PipeDream-2BW, and SpecTrain. The code of PipeOptim can be accessible at https://github.com/guanleics/PipeOptim.
Transfer Learning for Low-Resource Sentiment Analysis
Apr 10, 2023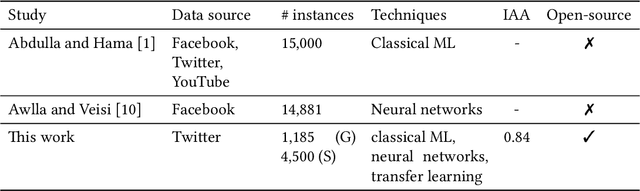

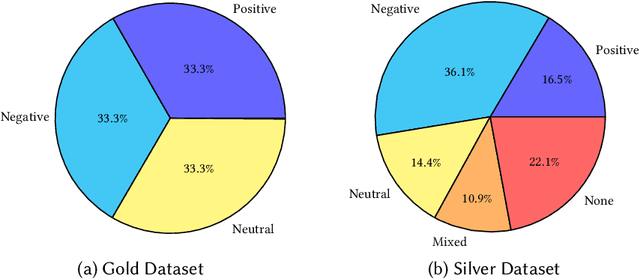
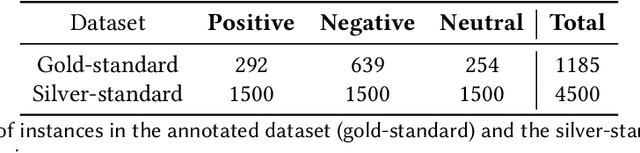
Sentiment analysis is the process of identifying and extracting subjective information from text. Despite the advances to employ cross-lingual approaches in an automatic way, the implementation and evaluation of sentiment analysis systems require language-specific data to consider various sociocultural and linguistic peculiarities. In this paper, the collection and annotation of a dataset are described for sentiment analysis of Central Kurdish. We explore a few classical machine learning and neural network-based techniques for this task. Additionally, we employ an approach in transfer learning to leverage pretrained models for data augmentation. We demonstrate that data augmentation achieves a high F$_1$ score and accuracy despite the difficulty of the task.