 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Deep Learning Brasil at ABSAPT 2022: Portuguese Transformer Ensemble Approaches
Nov 08, 2023
Aspect-based Sentiment Analysis (ABSA) is a task whose objective is to classify the individual sentiment polarity of all entities, called aspects, in a sentence. The task is composed of two subtasks: Aspect Term Extraction (ATE), identify all aspect terms in a sentence; and Sentiment Orientation Extraction (SOE), given a sentence and its aspect terms, the task is to determine the sentiment polarity of each aspect term (positive, negative or neutral). This article presents we present our participation in Aspect-Based Sentiment Analysis in Portuguese (ABSAPT) 2022 at IberLEF 2022. We submitted the best performing systems, achieving new state-of-the-art results on both subtasks.
Generative Context-aware Fine-tuning of Self-supervised Speech Models
Dec 15, 2023When performing tasks like automatic speech recognition or spoken language understanding for a given utterance, access to preceding text or audio provides contextual information can improve performance. Considering the recent advances in generative large language models (LLM), we hypothesize that an LLM could generate useful context information using the preceding text. With appropriate prompts, LLM could generate a prediction of the next sentence or abstractive text like titles or topics. In this paper, we study the use of LLM-generated context information and propose an approach to distill the generated information during fine-tuning of self-supervised speech models, which we refer to as generative context-aware fine-tuning. This approach allows the fine-tuned model to make improved predictions without access to the true surrounding segments or to the LLM at inference time, while requiring only a very small additional context module. We evaluate the proposed approach using the SLUE and Libri-light benchmarks for several downstream tasks: automatic speech recognition, named entity recognition, and sentiment analysis. The results show that generative context-aware fine-tuning outperforms a context injection fine-tuning approach that accesses the ground-truth previous text, and is competitive with a generative context injection fine-tuning approach that requires the LLM at inference time.
Corporate Bankruptcy Prediction with Domain-Adapted BERT
Dec 06, 2023This study performs BERT-based analysis, which is a representative contextualized language model, on corporate disclosure data to predict impending bankruptcies. Prior literature on bankruptcy prediction mainly focuses on developing more sophisticated prediction methodologies with financial variables. However, in our study, we focus on improving the quality of input dataset. Specifically, we employ BERT model to perform sentiment analysis on MD&A disclosures. We show that BERT outperforms dictionary-based predictions and Word2Vec-based predictions in terms of adjusted R-square in logistic regression, k-nearest neighbor (kNN-5), and linear kernel support vector machine (SVM). Further, instead of pre-training the BERT model from scratch, we apply self-learning with confidence-based filtering to corporate disclosure data (10-K). We achieve the accuracy rate of 91.56% and demonstrate that the domain adaptation procedure brings a significant improvement in prediction accuracy.
A Survey of Quantum-Cognitively Inspired Sentiment Analysis Models
Jun 06, 2023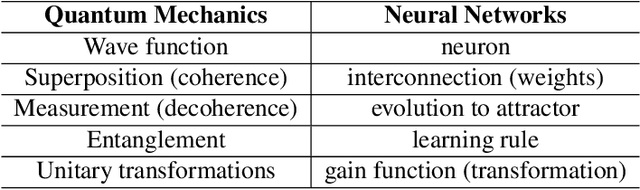
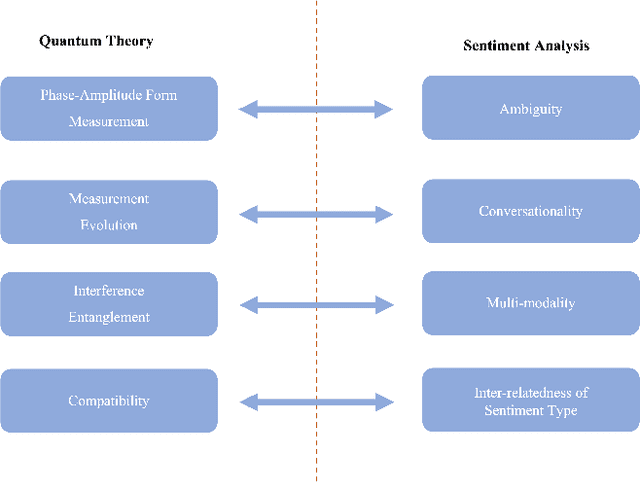
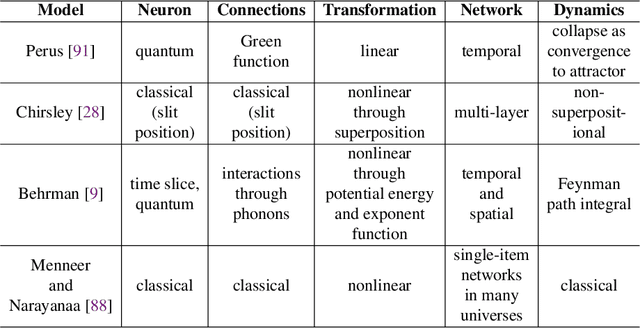
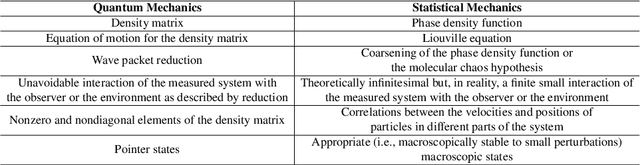
Quantum theory, originally proposed as a physical theory to describe the motions of microscopic particles, has been applied to various non-physics domains involving human cognition and decision-making that are inherently uncertain and exhibit certain non-classical, quantum-like characteristics. Sentiment analysis is a typical example of such domains. In the last few years, by leveraging the modeling power of quantum probability (a non-classical probability stemming from quantum mechanics methodology) and deep neural networks, a range of novel quantum-cognitively inspired models for sentiment analysis have emerged and performed well. This survey presents a timely overview of the latest developments in this fascinating cross-disciplinary area. We first provide a background of quantum probability and quantum cognition at a theoretical level, analyzing their advantages over classical theories in modeling the cognitive aspects of sentiment analysis. Then, recent quantum-cognitively inspired models are introduced and discussed in detail, focusing on how they approach the key challenges of the sentiment analysis task. Finally, we discuss the limitations of the current research and highlight future research directions.
Applying QNLP to sentiment analysis in finance
Jul 20, 2023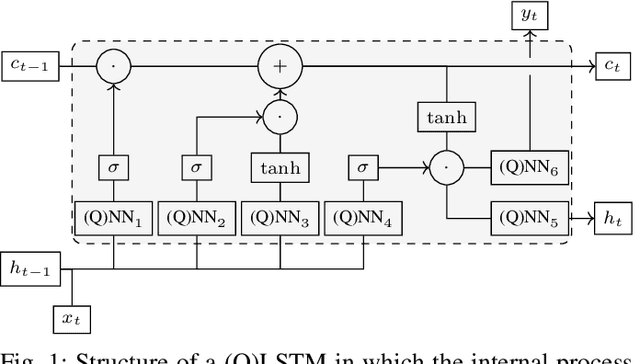
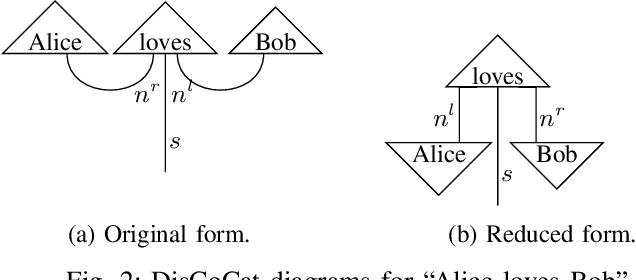
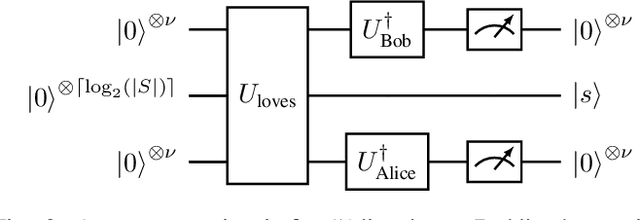
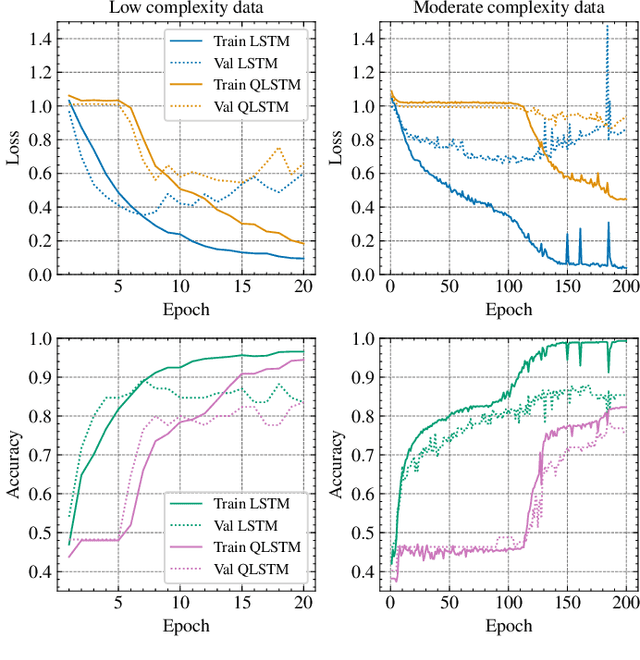
As an application domain where the slightest qualitative improvements can yield immense value, finance is a promising candidate for early quantum advantage. Focusing on the rapidly advancing field of Quantum Natural Language Processing (QNLP), we explore the practical applicability of the two central approaches DisCoCat and Quantum-Enhanced Long Short-Term Memory (QLSTM) to the problem of sentiment analysis in finance. Utilizing a novel ChatGPT-based data generation approach, we conduct a case study with more than 1000 realistic sentences and find that QLSTMs can be trained substantially faster than DisCoCat while also achieving close to classical results for their available software implementations.
SentimentGPT: Exploiting GPT for Advanced Sentiment Analysis and its Departure from Current Machine Learning
Jul 23, 2023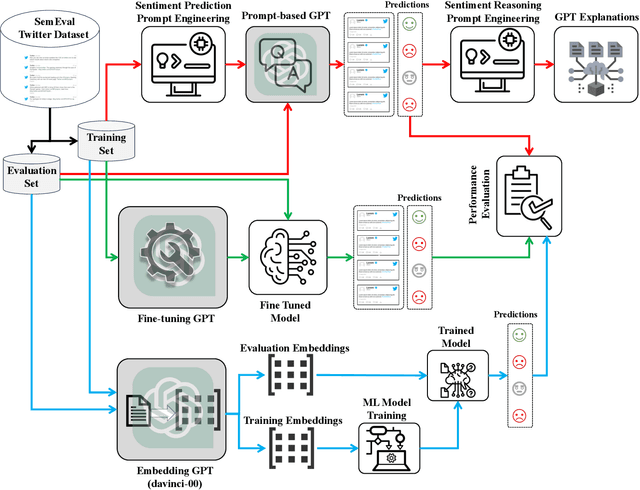
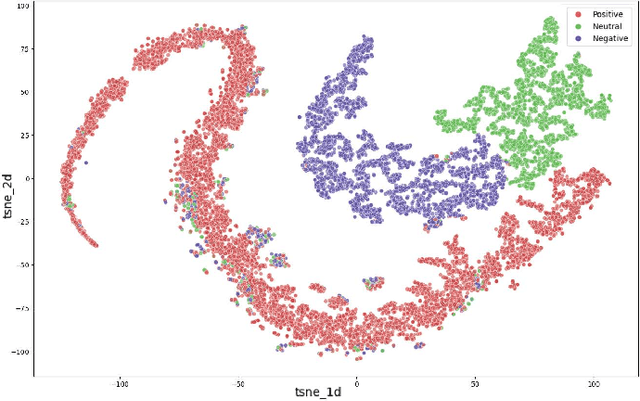
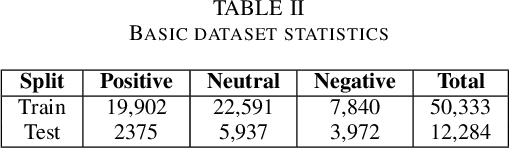
This study presents a thorough examination of various Generative Pretrained Transformer (GPT) methodologies in sentiment analysis, specifically in the context of Task 4 on the SemEval 2017 dataset. Three primary strategies are employed: 1) prompt engineering using the advanced GPT-3.5 Turbo, 2) fine-tuning GPT models, and 3) an inventive approach to embedding classification. The research yields detailed comparative insights among these strategies and individual GPT models, revealing their unique strengths and potential limitations. Additionally, the study compares these GPT-based methodologies with other current, high-performing models previously used with the same dataset. The results illustrate the significant superiority of the GPT approaches in terms of predictive performance, more than 22\% in F1-score compared to the state-of-the-art. Further, the paper sheds light on common challenges in sentiment analysis tasks, such as understanding context and detecting sarcasm. It underscores the enhanced capabilities of the GPT models to effectively handle these complexities. Taken together, these findings highlight the promising potential of GPT models in sentiment analysis, setting the stage for future research in this field. The code can be found at https://github.com/DSAatUSU/SentimentGPT
Explaining high-dimensional text classifiers
Nov 22, 2023Explainability has become a valuable tool in the last few years, helping humans better understand AI-guided decisions. However, the classic explainability tools are sometimes quite limited when considering high-dimensional inputs and neural network classifiers. We present a new explainability method using theoretically proven high-dimensional properties in neural network classifiers. We present two usages of it: 1) On the classical sentiment analysis task for the IMDB reviews dataset, and 2) our Malware-Detection task for our PowerShell scripts dataset.
Implementation of AI Deep Learning Algorithm For Multi-Modal Sentiment Analysis
Nov 19, 2023A multi-modal emotion recognition method was established by combining two-channel convolutional neural network with ring network. This method can extract emotional information effectively and improve learning efficiency. The words were vectorized with GloVe, and the word vector was input into the convolutional neural network. Combining attention mechanism and maximum pool converter BiSRU channel, the local deep emotion and pre-post sequential emotion semantics are obtained. Finally, multiple features are fused and input as the polarity of emotion, so as to achieve the emotion analysis of the target. Experiments show that the emotion analysis method based on feature fusion can effectively improve the recognition accuracy of emotion data set and reduce the learning time. The model has a certain generalization.
Instruct-FinGPT: Financial Sentiment Analysis by Instruction Tuning of General-Purpose Large Language Models
Jun 22, 2023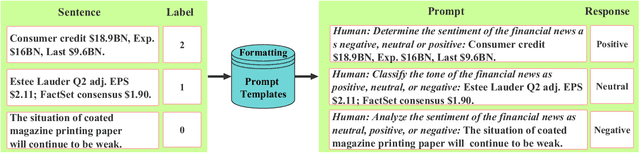
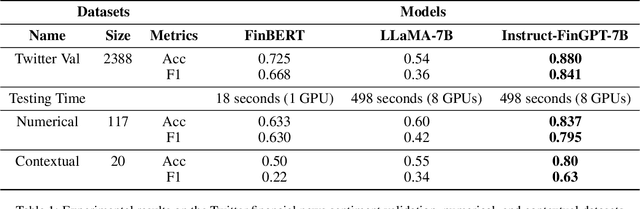
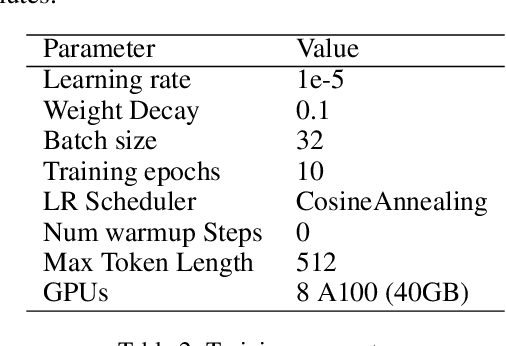
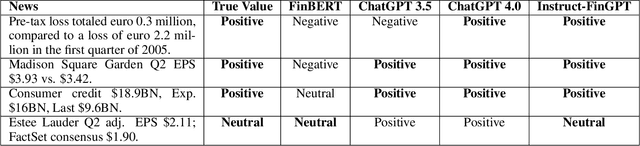
Sentiment analysis is a vital tool for uncovering insights from financial articles, news, and social media, shaping our understanding of market movements. Despite the impressive capabilities of large language models (LLMs) in financial natural language processing (NLP), they still struggle with accurately interpreting numerical values and grasping financial context, limiting their effectiveness in predicting financial sentiment. In this paper, we introduce a simple yet effective instruction tuning approach to address these issues. By transforming a small portion of supervised financial sentiment analysis data into instruction data and fine-tuning a general-purpose LLM with this method, we achieve remarkable advancements in financial sentiment analysis. In the experiment, our approach outperforms state-of-the-art supervised sentiment analysis models, as well as widely used LLMs like ChatGPT and LLaMAs, particularly in scenarios where numerical understanding and contextual comprehension are vital.
Perceiving University Student's Opinions from Google App Reviews
Dec 10, 2023Google app market captures the school of thought of users from every corner of the globe via ratings and text reviews, in a multilinguistic arena. The potential information from the reviews cannot be extracted manually, due to its exponential growth. So, Sentiment analysis, by machine learning and deep learning algorithms employing NLP, explicitly uncovers and interprets the emotions. This study performs the sentiment classification of the app reviews and identifies the university student's behavior towards the app market via exploratory analysis. We applied machine learning algorithms using the TP, TF, and TF IDF text representation scheme and evaluated its performance on Bagging, an ensemble learning method. We used word embedding, Glove, on the deep learning paradigms. Our model was trained on Google app reviews and tested on Student's App Reviews(SAR). The various combinations of these algorithms were compared amongst each other using F score and accuracy and inferences were highlighted graphically. SVM, amongst other classifiers, gave fruitful accuracy(93.41%), F score(89%) on bigram and TF IDF scheme. Bagging enhanced the performance of LR and NB with accuracy of 87.88% and 86.69% and F score of 86% and 78% respectively. Overall, LSTM on Glove embedding recorded the highest accuracy(95.2%) and F score(88%).
* Accepted in Concurrency and Computation Practice and Experience