 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Discovering Highly Influential Shortcut Reasoning: An Automated Template-Free Approach
Dec 15, 2023
Shortcut reasoning is an irrational process of inference, which degrades the robustness of an NLP model. While a number of previous work has tackled the identification of shortcut reasoning, there are still two major limitations: (i) a method for quantifying the severity of the discovered shortcut reasoning is not provided; (ii) certain types of shortcut reasoning may be missed. To address these issues, we propose a novel method for identifying shortcut reasoning. The proposed method quantifies the severity of the shortcut reasoning by leveraging out-of-distribution data and does not make any assumptions about the type of tokens triggering the shortcut reasoning. Our experiments on Natural Language Inference and Sentiment Analysis demonstrate that our framework successfully discovers known and unknown shortcut reasoning in the previous work.
Exploiting Diverse Feature for Multimodal Sentiment Analysis
Aug 25, 2023
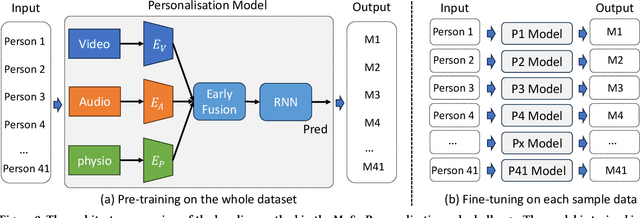
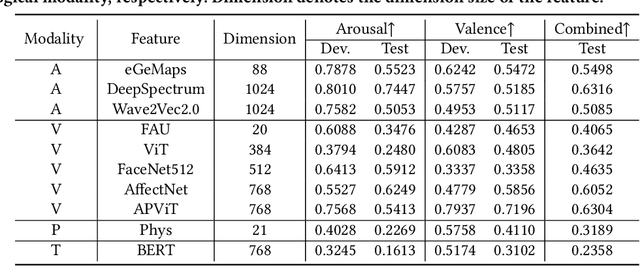
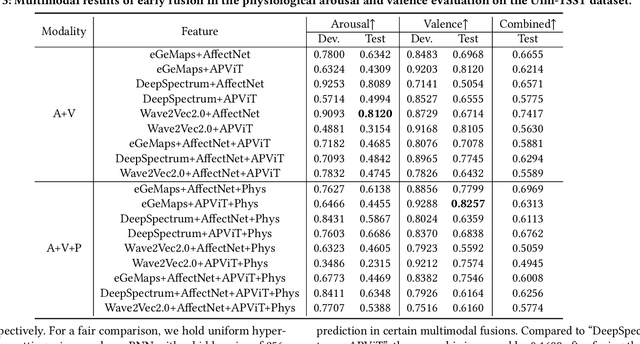
In this paper, we present our solution to the MuSe-Personalisation sub-challenge in the MuSe 2023 Multimodal Sentiment Analysis Challenge. The task of MuSe-Personalisation aims to predict the continuous arousal and valence values of a participant based on their audio-visual, language, and physiological signal modalities data. Considering different people have personal characteristics, the main challenge of this task is how to build robustness feature presentation for sentiment prediction. To address this issue, we propose exploiting diverse features. Specifically, we proposed a series of feature extraction methods to build a robust representation and model ensemble. We empirically evaluate the performance of the utilized method on the officially provided dataset. \textbf{As a result, we achieved 3rd place in the MuSe-Personalisation sub-challenge.} Specifically, we achieve the results of 0.8492 and 0.8439 for MuSe-Personalisation in terms of arousal and valence CCC.
Chinese Fine-Grained Financial Sentiment Analysis with Large Language Models
Jun 25, 2023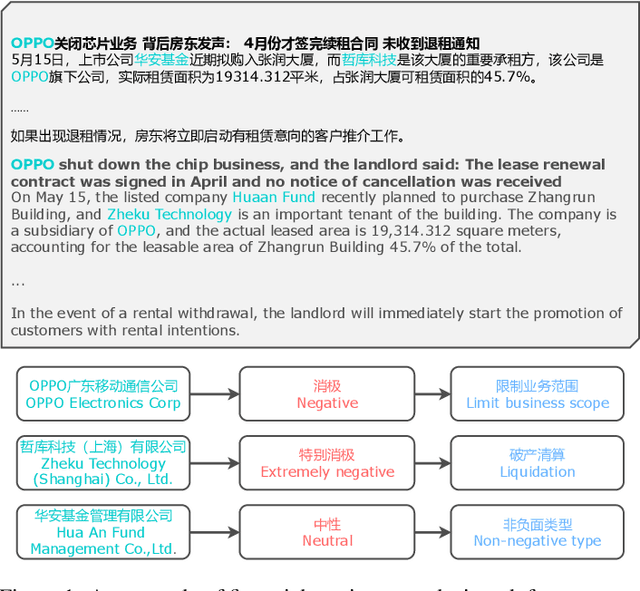
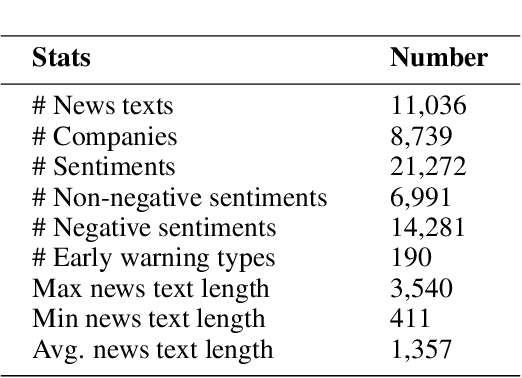
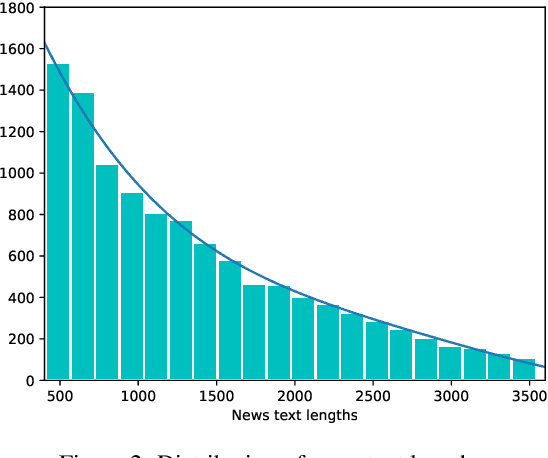
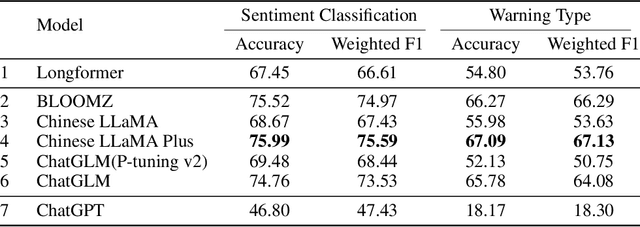
Entity-level fine-grained sentiment analysis in the financial domain is a crucial subtask of sentiment analysis and currently faces numerous challenges. The primary challenge stems from the lack of high-quality and large-scale annotated corpora specifically designed for financial text sentiment analysis, which in turn limits the availability of data necessary for developing effective text processing techniques. Recent advancements in large language models (LLMs) have yielded remarkable performance in natural language processing tasks, primarily centered around language pattern matching. In this paper, we propose a novel and extensive Chinese fine-grained financial sentiment analysis dataset, FinChina SA, for enterprise early warning. We thoroughly evaluate and experiment with well-known existing open-source LLMs using our dataset. We firmly believe that our dataset will serve as a valuable resource to advance the exploration of real-world financial sentiment analysis tasks, which should be the focus of future research. Our dataset and all code to replicate the experimental results will be released.
Hiding in Plain Sight: Towards the Science of Linguistic Steganography
Dec 28, 2023Covert communication (also known as steganography) is the practice of concealing a secret inside an innocuous-looking public object (cover) so that the modified public object (covert code) makes sense to everyone but only someone who knows the code can extract the secret (message). Linguistic steganography is the practice of encoding a secret message in natural language text such as spoken conversation or short public communications such as tweets.. While ad hoc methods for covert communications in specific domains exist ( JPEG images, Chinese poetry, etc), there is no general model for linguistic steganography specifically. We present a novel mathematical formalism for creating linguistic steganographic codes, with three parameters: Decodability (probability that the receiver of the coded message will decode the cover correctly), density (frequency of code words in a cover code), and detectability (probability that an attacker can tell the difference between an untampered cover compared to its steganized version). Verbal or linguistic steganography is most challenging because of its lack of artifacts to hide the secret message in. We detail a practical construction in Python of a steganographic code for Tweets using inserted words to encode hidden digits while using n-gram frequency distortion as the measure of detectability of the insertions. Using the publicly accessible Stanford Sentiment Analysis dataset we implemented the tweet steganization scheme -- a codeword (an existing word in the data set) inserted in random positions in random existing tweets to find the tweet that has the least possible n-gram distortion. We argue that this approximates KL distance in a localized manner at low cost and thus we get a linguistic steganography scheme that is both formal and practical and permits a tradeoff between codeword density and detectability of the covert message.
ConKI: Contrastive Knowledge Injection for Multimodal Sentiment Analysis
Jun 27, 2023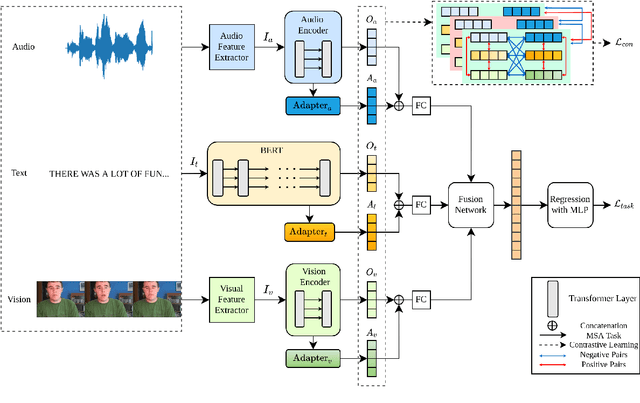
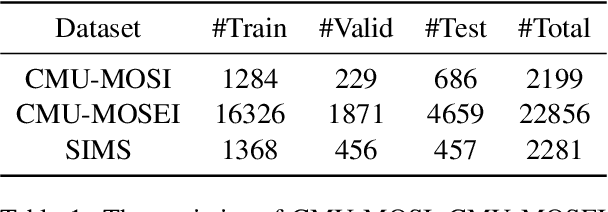
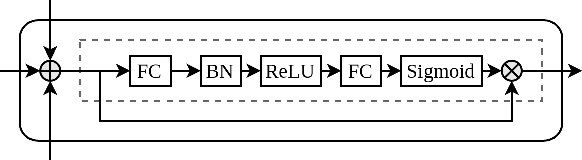
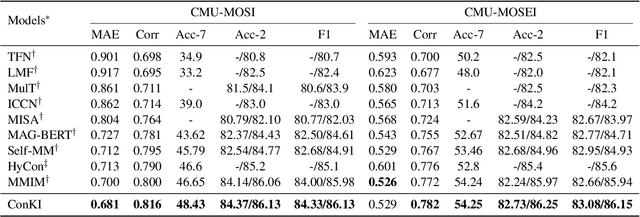
Multimodal Sentiment Analysis leverages multimodal signals to detect the sentiment of a speaker. Previous approaches concentrate on performing multimodal fusion and representation learning based on general knowledge obtained from pretrained models, which neglects the effect of domain-specific knowledge. In this paper, we propose Contrastive Knowledge Injection (ConKI) for multimodal sentiment analysis, where specific-knowledge representations for each modality can be learned together with general knowledge representations via knowledge injection based on an adapter architecture. In addition, ConKI uses a hierarchical contrastive learning procedure performed between knowledge types within every single modality, across modalities within each sample, and across samples to facilitate the effective learning of the proposed representations, hence improving multimodal sentiment predictions. The experiments on three popular multimodal sentiment analysis benchmarks show that ConKI outperforms all prior methods on a variety of performance metrics.
From Voices to Validity: Leveraging Large Language Models (LLMs) for Textual Analysis of Policy Stakeholder Interviews
Dec 02, 2023Obtaining stakeholders' diverse experiences and opinions about current policy in a timely manner is crucial for policymakers to identify strengths and gaps in resource allocation, thereby supporting effective policy design and implementation. However, manually coding even moderately sized interview texts or open-ended survey responses from stakeholders can often be labor-intensive and time-consuming. This study explores the integration of Large Language Models (LLMs)--like GPT-4--with human expertise to enhance text analysis of stakeholder interviews regarding K-12 education policy within one U.S. state. Employing a mixed-methods approach, human experts developed a codebook and coding processes as informed by domain knowledge and unsupervised topic modeling results. They then designed prompts to guide GPT-4 analysis and iteratively evaluate different prompts' performances. This combined human-computer method enabled nuanced thematic and sentiment analysis. Results reveal that while GPT-4 thematic coding aligned with human coding by 77.89% at specific themes, expanding to broader themes increased congruence to 96.02%, surpassing traditional Natural Language Processing (NLP) methods by over 25%. Additionally, GPT-4 is more closely matched to expert sentiment analysis than lexicon-based methods. Findings from quantitative measures and qualitative reviews underscore the complementary roles of human domain expertise and automated analysis as LLMs offer new perspectives and coding consistency. The human-computer interactive approach enhances efficiency, validity, and interpretability of educational policy research.
Exploring a Hybrid Deep Learning Framework to Automatically Discover Topic and Sentiment in COVID-19 Tweets
Dec 02, 2023COVID-19 has created a major public health problem worldwide and other problems such as economic crisis, unemployment, mental distress, etc. The pandemic is deadly in the world and involves many people not only with infection but also with problems, stress, wonder, fear, resentment, and hatred. Twitter is a highly influential social media platform and a significant source of health-related information, news, opinion and public sentiment where information is shared by both citizens and government sources. Therefore an effective analysis of COVID-19 tweets is essential for policymakers to make wise decisions. However, it is challenging to identify interesting and useful content from major streams of text to understand people's feelings about the important topics of the COVID-19 tweets. In this paper, we propose a new \textit{framework} for analyzing topic-based sentiments by extracting key topics with significant labels and classifying positive, negative, or neutral tweets on each topic to quickly find common topics of public opinion and COVID-19-related attitudes. While building our model, we take into account hybridization of BiLSTM and GRU structures for sentiment analysis to achieve our goal. The experimental results show that our topic identification method extracts better topic labels and the sentiment analysis approach using our proposed hybrid deep learning model achieves the highest accuracy compared to traditional models.
Leveraging Twitter Data for Sentiment Analysis of Transit User Feedback: An NLP Framework
Oct 11, 2023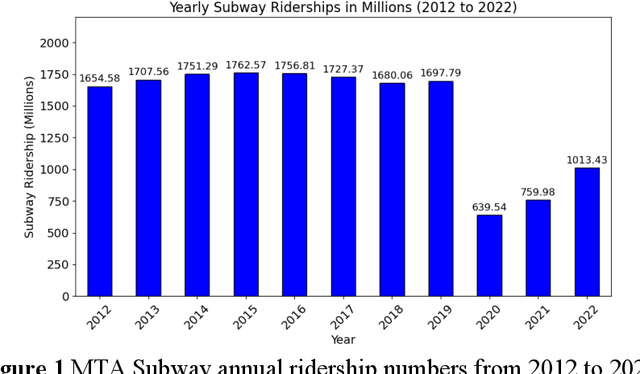

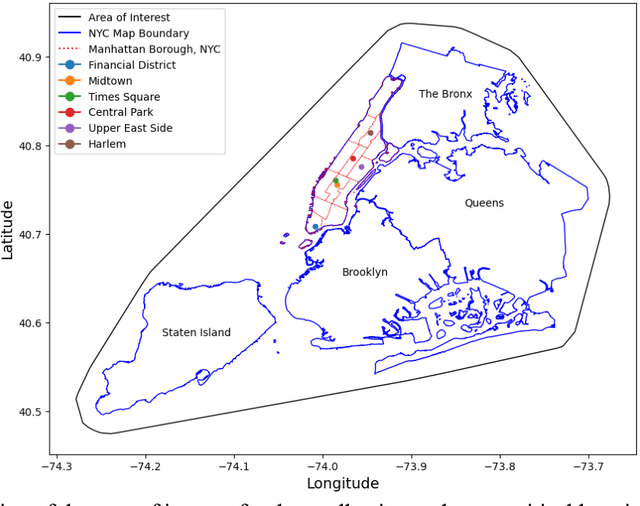

Traditional methods of collecting user feedback through transit surveys are often time-consuming, resource intensive, and costly. In this paper, we propose a novel NLP-based framework that harnesses the vast, abundant, and inexpensive data available on social media platforms like Twitter to understand users' perceptions of various service issues. Twitter, being a microblogging platform, hosts a wealth of real-time user-generated content that often includes valuable feedback and opinions on various products, services, and experiences. The proposed framework streamlines the process of gathering and analyzing user feedback without the need for costly and time-consuming user feedback surveys using two techniques. First, it utilizes few-shot learning for tweet classification within predefined categories, allowing effective identification of the issues described in tweets. It then employs a lexicon-based sentiment analysis model to assess the intensity and polarity of the tweet sentiments, distinguishing between positive, negative, and neutral tweets. The effectiveness of the framework was validated on a subset of manually labeled Twitter data and was applied to the NYC subway system as a case study. The framework accurately classifies tweets into predefined categories related to safety, reliability, and maintenance of the subway system and effectively measured sentiment intensities within each category. The general findings were corroborated through a comparison with an agency-run customer survey conducted in the same year. The findings highlight the effectiveness of the proposed framework in gauging user feedback through inexpensive social media data to understand the pain points of the transit system and plan for targeted improvements.
Deep Learning-based Sentiment Classification: A Comparative Survey
Dec 12, 2023Recently, Deep Learning (DL) approaches have been applied to solve the Sentiment Classification (SC) problem, which is a core task in reviews mining or Sentiment Analysis (SA). The performances of these approaches are affected by different factors. This paper addresses these factors and classifies them into three categories: data preparation based factors, feature representation based factors and the classification techniques based factors. The paper is a comprehensive literature-based survey that compares the performance of more than 100 DL-based SC approaches by using 21 public datasets of reviews given by customers within three specific application domains (products, movies and restaurants). These 21 datasets have different characteristics (balanced/imbalanced, size, etc.) to give a global vision for our study. The comparison explains how the proposed factors quantitatively affect the performance of the studied DL-based SC approaches.
MMTF-DES: A Fusion of Multimodal Transformer Models for Desire, Emotion, and Sentiment Analysis of Social Media Data
Oct 22, 2023Desire is a set of human aspirations and wishes that comprise verbal and cognitive aspects that drive human feelings and behaviors, distinguishing humans from other animals. Understanding human desire has the potential to be one of the most fascinating and challenging research domains. It is tightly coupled with sentiment analysis and emotion recognition tasks. It is beneficial for increasing human-computer interactions, recognizing human emotional intelligence, understanding interpersonal relationships, and making decisions. However, understanding human desire is challenging and under-explored because ways of eliciting desire might be different among humans. The task gets more difficult due to the diverse cultures, countries, and languages. Prior studies overlooked the use of image-text pairwise feature representation, which is crucial for the task of human desire understanding. In this research, we have proposed a unified multimodal transformer-based framework with image-text pair settings to identify human desire, sentiment, and emotion. The core of our proposed method lies in the encoder module, which is built using two state-of-the-art multimodal transformer models. These models allow us to extract diverse features. To effectively extract visual and contextualized embedding features from social media image and text pairs, we conducted joint fine-tuning of two pre-trained multimodal transformer models: Vision-and-Language Transformer (ViLT) and Vision-and-Augmented-Language Transformer (VAuLT). Subsequently, we use an early fusion strategy on these embedding features to obtain combined diverse feature representations of the image-text pair. This consolidation incorporates diverse information about this task, enabling us to robustly perceive the context and image pair from multiple perspectives.