 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Towards the new XAI: A Hypothesis-Driven Approach to Decision Support Using Evidence
Feb 02, 2024
Prior research on AI-assisted human decision-making has explored several different explainable AI (XAI) approaches. A recent paper has proposed a paradigm shift calling for hypothesis-driven XAI through a conceptual framework called evaluative AI that gives people evidence that supports or refutes hypotheses without necessarily giving a decision-aid recommendation. In this paper we describe and evaluate an approach for hypothesis-driven XAI based on the Weight of Evidence (WoE) framework, which generates both positive and negative evidence for a given hypothesis. Through human behavioural experiments, we show that our hypothesis-driven approach increases decision accuracy, reduces reliance compared to a recommendation-driven approach and an AI-explanation-only baseline, but with a small increase in under-reliance compared to the recommendation-driven approach. Further, we show that participants used our hypothesis-driven approach in a materially different way to the two baselines.
Dual-space Hierarchical Learning for Goal-guided Conversational Recommendation
Dec 30, 2023
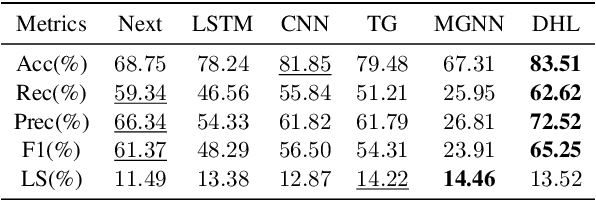
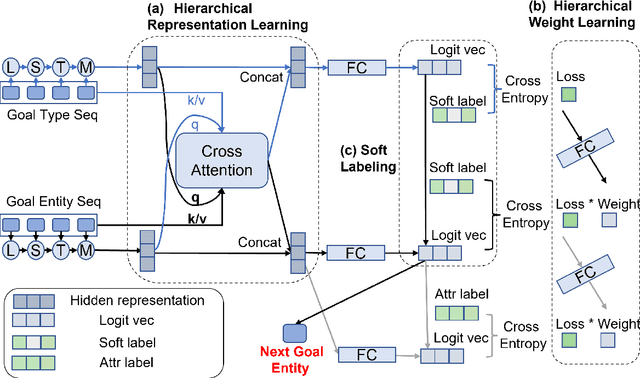
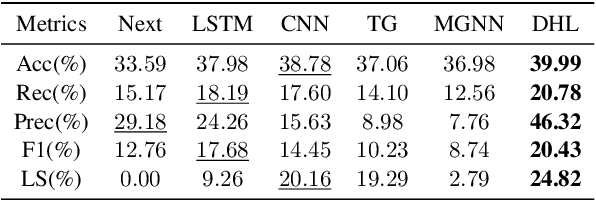
Proactively and naturally guiding the dialog from the non-recommendation context (e.g., Chit-chat) to the recommendation scenario (e.g., Music) is crucial for the Conversational Recommender System (CRS). Prior studies mainly focus on planning the next dialog goal~(e.g., chat on a movie star) conditioned on the previous dialog. However, we find the dialog goals can be simultaneously observed at different levels, which can be utilized to improve CRS. In this paper, we propose Dual-space Hierarchical Learning (DHL) to leverage multi-level goal sequences and their hierarchical relationships for conversational recommendation. Specifically, we exploit multi-level goal sequences from both the representation space and the optimization space. In the representation space, we propose the hierarchical representation learning where a cross attention module derives mutually enhanced multi-level goal representations. In the optimization space, we devise the hierarchical weight learning to reweight lower-level goal sequences, and introduce bi-level optimization for stable update. Additionally, we propose a soft labeling strategy to guide optimization gradually. Experiments on two real-world datasets verify the effectiveness of our approach. Code and data are available here.
RDGCL: Reaction-Diffusion Graph Contrastive Learning for Recommendation
Dec 27, 2023Contrastive learning (CL) has emerged as a promising technique for improving recommender systems, addressing the challenge of data sparsity by leveraging self-supervised signals from raw data. Integration of CL with graph convolutional network (GCN)-based collaborative filterings (CFs) has been explored in recommender systems. However, current CL-based recommendation models heavily rely on low-pass filters and graph augmentations. In this paper, we propose a novel CL method for recommender systems called the reaction-diffusion graph contrastive learning model (RDGCL). We design our own GCN for CF based on both the diffusion, i.e., low-pass filter, and the reaction, i.e., high-pass filter, equations. Our proposed CL-based training occurs between reaction and diffusion-based embeddings, so there is no need for graph augmentations. Experimental evaluation on 6 benchmark datasets demonstrates that our proposed method outperforms state-of-the-art CL-based recommendation models. By enhancing recommendation accuracy and diversity, our method brings an advancement in CL for recommender systems.
Misalignment, Learning, and Ranking: Harnessing Users Limited Attention
Feb 21, 2024In digital health and EdTech, recommendation systems face a significant challenge: users often choose impulsively, in ways that conflict with the platform's long-term payoffs. This misalignment makes it difficult to effectively learn to rank items, as it may hinder exploration of items with greater long-term payoffs. Our paper tackles this issue by utilizing users' limited attention spans. We propose a model where a platform presents items with unknown payoffs to the platform in a ranked list to $T$ users over time. Each user selects an item by first considering a prefix window of these ranked items and then picking the highest preferred item in that window (and the platform observes its payoff for this item). We study the design of online bandit algorithms that obtain vanishing regret against hindsight optimal benchmarks. We first consider adversarial window sizes and stochastic iid payoffs. We design an active-elimination-based algorithm that achieves an optimal instance-dependent regret bound of $O(\log(T))$, by showing matching regret upper and lower bounds. The key idea is using the combinatorial structure of the problem to either obtain a large payoff from each item or to explore by getting a sample from that item. This method systematically narrows down the item choices to enhance learning efficiency and payoff. Second, we consider adversarial payoffs and stochastic iid window sizes. We start from the full-information problem of finding the permutation that maximizes the expected payoff. By a novel combinatorial argument, we characterize the polytope of admissible item selection probabilities by a permutation and show it has a polynomial-size representation. Using this representation, we show how standard algorithms for adversarial online linear optimization in the space of admissible probabilities can be used to obtain a polynomial-time algorithm with $O(\sqrt{T})$ regret.
CDRNP: Cross-Domain Recommendation to Cold-Start Users via Neural Process
Jan 23, 2024Cross-domain recommendation (CDR) has been proven as a promising way to tackle the user cold-start problem, which aims to make recommendations for users in the target domain by transferring the user preference derived from the source domain. Traditional CDR studies follow the embedding and mapping (EMCDR) paradigm, which transfers user representations from the source to target domain by learning a user-shared mapping function, neglecting the user-specific preference. Recent CDR studies attempt to learn user-specific mapping functions in meta-learning paradigm, which regards each user's CDR as an individual task, but neglects the preference correlations among users, limiting the beneficial information for user representations. Moreover, both of the paradigms neglect the explicit user-item interactions from both domains during the mapping process. To address the above issues, this paper proposes a novel CDR framework with neural process (NP), termed as CDRNP. Particularly, it develops the meta-learning paradigm to leverage user-specific preference, and further introduces a stochastic process by NP to capture the preference correlations among the overlapping and cold-start users, thus generating more powerful mapping functions by mapping the user-specific preference and common preference correlations to a predictive probability distribution. In addition, we also introduce a preference remainer to enhance the common preference from the overlapping users, and finally devises an adaptive conditional decoder with preference modulation to make prediction for cold-start users with items in the target domain. Experimental results demonstrate that CDRNP outperforms previous SOTA methods in three real-world CDR scenarios.
LiGNN: Graph Neural Networks at LinkedIn
Feb 17, 2024In this paper, we present LiGNN, a deployed large-scale Graph Neural Networks (GNNs) Framework. We share our insight on developing and deployment of GNNs at large scale at LinkedIn. We present a set of algorithmic improvements to the quality of GNN representation learning including temporal graph architectures with long term losses, effective cold start solutions via graph densification, ID embeddings and multi-hop neighbor sampling. We explain how we built and sped up by 7x our large-scale training on LinkedIn graphs with adaptive sampling of neighbors, grouping and slicing of training data batches, specialized shared-memory queue and local gradient optimization. We summarize our deployment lessons and learnings gathered from A/B test experiments. The techniques presented in this work have contributed to an approximate relative improvements of 1% of Job application hearing back rate, 2% Ads CTR lift, 0.5% of Feed engaged daily active users, 0.2% session lift and 0.1% weekly active user lift from people recommendation. We believe that this work can provide practical solutions and insights for engineers who are interested in applying Graph neural networks at large scale.
Captions Are Worth a Thousand Words: Enhancing Product Retrieval with Pretrained Image-to-Text Models
Feb 13, 2024This paper explores the usage of multimodal image-to-text models to enhance text-based item retrieval. We propose utilizing pre-trained image captioning and tagging models, such as instructBLIP and CLIP, to generate text-based product descriptions which are combined with existing text descriptions. Our work is particularly impactful for smaller eCommerce businesses who are unable to maintain the high-quality text descriptions necessary to effectively perform item retrieval for search and recommendation use cases. We evaluate the searchability of ground-truth text, image-generated text, and combinations of both texts on several subsets of Amazon's publicly available ESCI dataset. The results demonstrate the dual capability of our proposed models to enhance the retrieval of existing text and generate highly-searchable standalone descriptions.
On the Effectiveness of Unlearning in Session-Based Recommendation
Dec 22, 2023Session-based recommendation predicts users' future interests from previous interactions in a session. Despite the memorizing of historical samples, the request of unlearning, i.e., to remove the effect of certain training samples, also occurs for reasons such as user privacy or model fidelity. However, existing studies on unlearning are not tailored for the session-based recommendation. On the one hand, these approaches cannot achieve satisfying unlearning effects due to the collaborative correlations and sequential connections between the unlearning item and the remaining items in the session. On the other hand, seldom work has conducted the research to verify the unlearning effectiveness in the session-based recommendation scenario. In this paper, we propose SRU, a session-based recommendation unlearning framework, which enables high unlearning efficiency, accurate recommendation performance, and improved unlearning effectiveness in session-based recommendation. Specifically, we first partition the training sessions into separate sub-models according to the similarity across the sessions, then we utilize an attention-based aggregation layer to fuse the hidden states according to the correlations between the session and the centroid of the data in the sub-model. To improve the unlearning effectiveness, we further propose three extra data deletion strategies, including collaborative extra deletion (CED), neighbor extra deletion (NED), and random extra deletion (RED). Besides, we propose an evaluation metric that measures whether the unlearning sample can be inferred after the data deletion to verify the unlearning effectiveness. We implement SRU with three representative session-based recommendation models and conduct experiments on three benchmark datasets. Experimental results demonstrate the effectiveness of our methods.
Improving One-class Recommendation with Multi-tasking on Various Preference Intensities
Jan 18, 2024In the one-class recommendation problem, it's required to make recommendations basing on users' implicit feedback, which is inferred from their action and inaction. Existing works obtain representations of users and items by encoding positive and negative interactions observed from training data. However, these efforts assume that all positive signals from implicit feedback reflect a fixed preference intensity, which is not realistic. Consequently, representations learned with these methods usually fail to capture informative entity features that reflect various preference intensities. In this paper, we propose a multi-tasking framework taking various preference intensities of each signal from implicit feedback into consideration. Representations of entities are required to satisfy the objective of each subtask simultaneously, making them more robust and generalizable. Furthermore, we incorporate attentive graph convolutional layers to explore high-order relationships in the user-item bipartite graph and dynamically capture the latent tendencies of users toward the items they interact with. Experimental results show that our method performs better than state-of-the-art methods by a large margin on three large-scale real-world benchmark datasets.
* RecSys 2020 (ACM Conference on Recommender Systems 2020)
A Survey on Cross-Domain Sequential Recommendation
Jan 10, 2024Cross-domain sequential recommendation (CDSR) shifts the modeling of user preferences from flat to stereoscopic by integrating and learning interaction information from multiple domains at different granularities (ranging from inter-sequence to intra-sequence and from single-domain to cross-domain).In this survey, we initially define the CDSR problem using a four-dimensional tensor and then analyze its multi-type input representations under multidirectional dimensionality reductions. Following that, we provide a systematic overview from both macro and micro views. From a macro view, we abstract the multi-level fusion structures of various models across domains and discuss their bridges for fusion. From a micro view, focusing on the existing models, we specifically discuss the basic technologies and then explain the auxiliary learning technologies. Finally, we exhibit the available public datasets and the representative experimental results as well as provide some insights into future directions for research in CDSR.