 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
A Comprehensive Survey of Evaluation Techniques for Recommendation Systems
Dec 26, 2023
The effectiveness of recommendation systems is pivotal to user engagement and satisfaction in online platforms. As these recommendation systems increasingly influence user choices, their evaluation transcends mere technical performance and becomes central to business success. This paper addresses the multifaceted nature of recommendation system evaluation by introducing a comprehensive suite of metrics, each tailored to capture a distinct aspect of system performance. We discuss similarity metrics that quantify the precision of content-based and collaborative filtering mechanisms, along with candidate generation metrics which measure how well the system identifies a broad yet pertinent range of items. Following this, we delve into predictive metrics that assess the accuracy of forecasted preferences, ranking metrics that evaluate the order in which recommendations are presented, and business metrics that align system performance with economic objectives. Our approach emphasizes the contextual application of these metrics and their interdependencies. In this paper, we identify the strengths and limitations of current evaluation practices and highlight the nuanced trade-offs that emerge when optimizing recommendation systems across different metrics. The paper concludes by proposing a framework for selecting and interpreting these metrics to not only improve system performance but also to advance business goals. This work is to aid researchers and practitioners in critically assessing recommendation systems and fosters the development of more nuanced, effective, and economically viable personalization strategies. Our code is available at GitHub - https://github.com/aryan-jadon/Evaluation-Metrics-for-Recommendation-Systems.
MCRPL: A Pretrain, Prompt & Fine-tune Paradigm for Non-overlapping Many-to-one Cross-domain Recommendation
Jan 16, 2024Cross-domain Recommendation (CR) is the task that tends to improve the recommendations in the sparse target domain by leveraging the information from other rich domains. Existing methods of cross-domain recommendation mainly focus on overlapping scenarios by assuming users are totally or partially overlapped, which are taken as bridges to connect different domains. However, this assumption does not always hold since it is illegal to leak users' identity information to other domains. Conducting Non-overlapping MCR (NMCR) is challenging since 1) The absence of overlapping information prevents us from directly aligning different domains, and this situation may get worse in the MCR scenario. 2) The distribution between source and target domains makes it difficult for us to learn common information across domains. To overcome the above challenges, we focus on NMCR, and devise MCRPL as our solution. To address Challenge 1, we first learn shared domain-agnostic and domain-dependent prompts, and pre-train them in the pre-training stage. To address Challenge 2, we further update the domain-dependent prompts with other parameters kept fixed to transfer the domain knowledge to the target domain. We conduct experiments on five real-world domains, and the results show the advance of our MCRPL method compared with several recent SOTA baselines.
Chain-of-Layer: Iteratively Prompting Large Language Models for Taxonomy Induction from Limited Examples
Feb 12, 2024Automatic taxonomy induction is crucial for web search, recommendation systems, and question answering. Manual curation of taxonomies is expensive in terms of human effort, making automatic taxonomy construction highly desirable. In this work, we introduce Chain-of-Layer which is an in-context learning framework designed to induct taxonomies from a given set of entities. Chain-of-Layer breaks down the task into selecting relevant candidate entities in each layer and gradually building the taxonomy from top to bottom. To minimize errors, we introduce the Ensemble-based Ranking Filter to reduce the hallucinated content generated at each iteration. Through extensive experiments, we demonstrate that Chain-of-Layer achieves state-of-the-art performance on four real-world benchmarks.
TASER: Temporal Adaptive Sampling for Fast and Accurate Dynamic Graph Representation Learning
Feb 18, 2024Recently, Temporal Graph Neural Networks (TGNNs) have demonstrated state-of-the-art performance in various high-impact applications, including fraud detection and content recommendation. Despite the success of TGNNs, they are prone to the prevalent noise found in real-world dynamic graphs like time-deprecated links and skewed interaction distribution. The noise causes two critical issues that significantly compromise the accuracy of TGNNs: (1) models are supervised by inferior interactions, and (2) noisy input induces high variance in the aggregated messages. However, current TGNN denoising techniques do not consider the diverse and dynamic noise pattern of each node. In addition, they also suffer from the excessive mini-batch generation overheads caused by traversing more neighbors. We believe the remedy for fast and accurate TGNNs lies in temporal adaptive sampling. In this work, we propose TASER, the first adaptive sampling method for TGNNs optimized for accuracy, efficiency, and scalability. TASER adapts its mini-batch selection based on training dynamics and temporal neighbor selection based on the contextual, structural, and temporal properties of past interactions. To alleviate the bottleneck in mini-batch generation, TASER implements a pure GPU-based temporal neighbor finder and a dedicated GPU feature cache. We evaluate the performance of TASER using two state-of-the-art backbone TGNNs. On five popular datasets, TASER outperforms the corresponding baselines by an average of 2.3% in Mean Reciprocal Rank (MRR) while achieving an average of 5.1x speedup in training time.
CDRNP: Cross-Domain Recommendation to Cold-Start Users via Neural Process
Jan 23, 2024Cross-domain recommendation (CDR) has been proven as a promising way to tackle the user cold-start problem, which aims to make recommendations for users in the target domain by transferring the user preference derived from the source domain. Traditional CDR studies follow the embedding and mapping (EMCDR) paradigm, which transfers user representations from the source to target domain by learning a user-shared mapping function, neglecting the user-specific preference. Recent CDR studies attempt to learn user-specific mapping functions in meta-learning paradigm, which regards each user's CDR as an individual task, but neglects the preference correlations among users, limiting the beneficial information for user representations. Moreover, both of the paradigms neglect the explicit user-item interactions from both domains during the mapping process. To address the above issues, this paper proposes a novel CDR framework with neural process (NP), termed as CDRNP. Particularly, it develops the meta-learning paradigm to leverage user-specific preference, and further introduces a stochastic process by NP to capture the preference correlations among the overlapping and cold-start users, thus generating more powerful mapping functions by mapping the user-specific preference and common preference correlations to a predictive probability distribution. In addition, we also introduce a preference remainer to enhance the common preference from the overlapping users, and finally devises an adaptive conditional decoder with preference modulation to make prediction for cold-start users with items in the target domain. Experimental results demonstrate that CDRNP outperforms previous SOTA methods in three real-world CDR scenarios.
Future Impact Decomposition in Request-level Recommendations
Feb 07, 2024In recommender systems, reinforcement learning solutions have shown promising results in optimizing the interaction sequence between users and the system over the long-term performance. For practical reasons, the policy's actions are typically designed as recommending a list of items to handle users' frequent and continuous browsing requests more efficiently. In this list-wise recommendation scenario, the user state is updated upon every request in the corresponding MDP formulation. However, this request-level formulation is essentially inconsistent with the user's item-level behavior. In this study, we demonstrate that an item-level optimization approach can better utilize item characteristics and optimize the policy's performance even under the request-level MDP. We support this claim by comparing the performance of standard request-level methods with the proposed item-level actor-critic framework in both simulation and online experiments. Furthermore, we show that a reward-based future decomposition strategy can better express the item-wise future impact and improve the recommendation accuracy in the long term. To achieve a more thorough understanding of the decomposition strategy, we propose a model-based re-weighting framework with adversarial learning that further boost the performance and investigate its correlation with the reward-based strategy.
Dual-space Hierarchical Learning for Goal-guided Conversational Recommendation
Dec 30, 2023
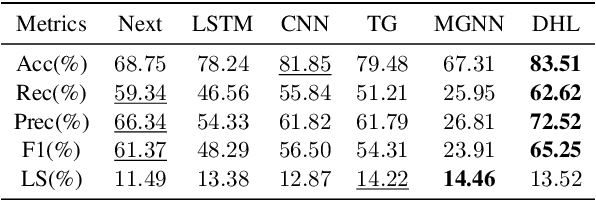
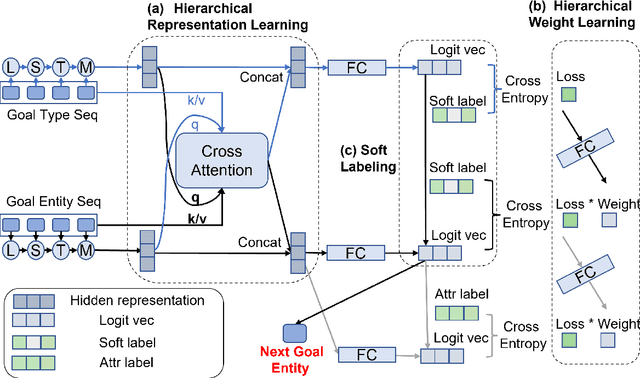
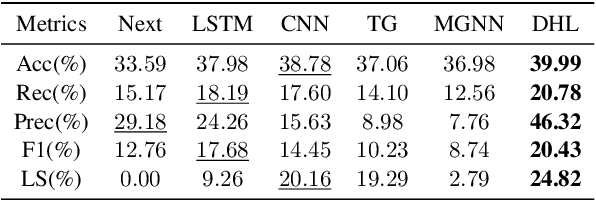
Proactively and naturally guiding the dialog from the non-recommendation context (e.g., Chit-chat) to the recommendation scenario (e.g., Music) is crucial for the Conversational Recommender System (CRS). Prior studies mainly focus on planning the next dialog goal~(e.g., chat on a movie star) conditioned on the previous dialog. However, we find the dialog goals can be simultaneously observed at different levels, which can be utilized to improve CRS. In this paper, we propose Dual-space Hierarchical Learning (DHL) to leverage multi-level goal sequences and their hierarchical relationships for conversational recommendation. Specifically, we exploit multi-level goal sequences from both the representation space and the optimization space. In the representation space, we propose the hierarchical representation learning where a cross attention module derives mutually enhanced multi-level goal representations. In the optimization space, we devise the hierarchical weight learning to reweight lower-level goal sequences, and introduce bi-level optimization for stable update. Additionally, we propose a soft labeling strategy to guide optimization gradually. Experiments on two real-world datasets verify the effectiveness of our approach. Code and data are available here.
Large Language Model-driven Meta-structure Discovery in Heterogeneous Information Network
Feb 18, 2024Heterogeneous information networks (HIN) have gained increasing popularity for being able to capture complex relations between nodes of diverse types. Meta-structure was proposed to identify important patterns of relations on HIN, which has been proven effective for extracting rich semantic information and facilitating graph neural networks to learn expressive representations. However, hand-crafted meta-structures pose challenges for scaling up, which draws wide research attention for developing automatic meta-structure search algorithms. Previous efforts concentrate on searching for meta-structures with good empirical prediction performance, overlooking explainability. Thus, they often produce meta-structures prone to overfitting and incomprehensible to humans. To address this, we draw inspiration from the emergent reasoning abilities of large language models (LLMs). We propose a novel REasoning meta-STRUCTure search (ReStruct) framework that integrates LLM reasoning into the evolutionary procedure. ReStruct uses a grammar translator to encode meta-structures into natural language sentences, and leverages the reasoning power of LLMs to evaluate semantically feasible meta-structures. ReStruct also employs performance-oriented evolutionary operations. These two competing forces jointly optimize for semantic explainability and empirical performance of meta-structures. We also design a differential LLM explainer that can produce natural language explanations for the discovered meta-structures, and refine the explanation by reasoning through the search history. Experiments on five datasets demonstrate ReStruct achieve SOTA performance in node classification and link recommendation tasks. Additionally, a survey study involving 73 graduate students shows that the meta-structures and natural language explanations generated by ReStruct are substantially more comprehensible.
Improving One-class Recommendation with Multi-tasking on Various Preference Intensities
Jan 18, 2024In the one-class recommendation problem, it's required to make recommendations basing on users' implicit feedback, which is inferred from their action and inaction. Existing works obtain representations of users and items by encoding positive and negative interactions observed from training data. However, these efforts assume that all positive signals from implicit feedback reflect a fixed preference intensity, which is not realistic. Consequently, representations learned with these methods usually fail to capture informative entity features that reflect various preference intensities. In this paper, we propose a multi-tasking framework taking various preference intensities of each signal from implicit feedback into consideration. Representations of entities are required to satisfy the objective of each subtask simultaneously, making them more robust and generalizable. Furthermore, we incorporate attentive graph convolutional layers to explore high-order relationships in the user-item bipartite graph and dynamically capture the latent tendencies of users toward the items they interact with. Experimental results show that our method performs better than state-of-the-art methods by a large margin on three large-scale real-world benchmark datasets.
* RecSys 2020 (ACM Conference on Recommender Systems 2020)
RDGCL: Reaction-Diffusion Graph Contrastive Learning for Recommendation
Dec 27, 2023Contrastive learning (CL) has emerged as a promising technique for improving recommender systems, addressing the challenge of data sparsity by leveraging self-supervised signals from raw data. Integration of CL with graph convolutional network (GCN)-based collaborative filterings (CFs) has been explored in recommender systems. However, current CL-based recommendation models heavily rely on low-pass filters and graph augmentations. In this paper, we propose a novel CL method for recommender systems called the reaction-diffusion graph contrastive learning model (RDGCL). We design our own GCN for CF based on both the diffusion, i.e., low-pass filter, and the reaction, i.e., high-pass filter, equations. Our proposed CL-based training occurs between reaction and diffusion-based embeddings, so there is no need for graph augmentations. Experimental evaluation on 6 benchmark datasets demonstrates that our proposed method outperforms state-of-the-art CL-based recommendation models. By enhancing recommendation accuracy and diversity, our method brings an advancement in CL for recommender systems.