 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Domain-Aware Cross-Attention for Cross-domain Recommendation
Jan 22, 2024
Cross-domain recommendation (CDR) is an important method to improve recommender system performance, especially when observations in target domains are sparse. However, most existing cross-domain recommendations fail to fully utilize the target domain's special features and are hard to be generalized to new domains. The designed network is complex and is not suitable for rapid industrial deployment. Our method introduces a two-step domain-aware cross-attention, extracting transferable features of the source domain from different granularity, which allows the efficient expression of both domain and user interests. In addition, we simplify the training process, and our model can be easily deployed on new domains. We conduct experiments on both public datasets and industrial datasets, and the experimental results demonstrate the effectiveness of our method. We have also deployed the model in an online advertising system and observed significant improvements in both Click-Through-Rate (CTR) and effective cost per mille (ECPM).
EXPLORE -- Explainable Song Recommendation
Dec 30, 2023This study explores the development of an explainable music recommendation system with enhanced user control. Leveraging a hybrid of collaborative filtering and content-based filtering, we address the challenges of opaque recommendation logic and lack of user influence on results. We present a novel approach combining advanced algorithms and an interactive user interface. Our methodology integrates Spotify data with user preference analytics to tailor music suggestions. Evaluation through RMSE and user studies underscores the efficacy and user satisfaction with our system. The paper concludes with potential directions for future enhancements in group recommendations and dynamic feedback integration.
QoS-Aware Graph Contrastive Learning for Web Service Recommendation
Jan 06, 2024With the rapid growth of cloud services driven by advancements in web service technology, selecting a high-quality service from a wide range of options has become a complex task. This study aims to address the challenges of data sparsity and the cold-start problem in web service recommendation using Quality of Service (QoS). We propose a novel approach called QoS-aware graph contrastive learning (QAGCL) for web service recommendation. Our model harnesses the power of graph contrastive learning to handle cold-start problems and improve recommendation accuracy effectively. By constructing contextually augmented graphs with geolocation information and randomness, our model provides diverse views. Through the use of graph convolutional networks and graph contrastive learning techniques, we learn user and service embeddings from these augmented graphs. The learned embeddings are then utilized to seamlessly integrate QoS considerations into the recommendation process. Experimental results demonstrate the superiority of our QAGCL model over several existing models, highlighting its effectiveness in addressing data sparsity and the cold-start problem in QoS-aware service recommendations. Our research contributes to the potential for more accurate recommendations in real-world scenarios, even with limited user-service interaction data.
Plug-In Diffusion Model for Embedding Denoising in Recommendation System
Jan 29, 2024In the realm of recommender systems, handling noisy implicit feedback is a prevalent challenge. While most research efforts focus on mitigating noise through data cleaning methods like resampling and reweighting, these approaches often rely on heuristic assumptions. Alternatively, model perspective denoising strategies actively incorporate noise into user-item interactions, aiming to bolster the model's inherent denoising capabilities. Nonetheless, this type of denoising method presents substantial challenges to the capacity of the recommender model to accurately identify and represent noise patterns. To overcome these hurdles, we introduce a plug-in diffusion model for embedding denoising in recommendation system, which employs a multi-step denoising approach based on diffusion models to foster robust representation learning of embeddings. Our model operates by introducing controlled Gaussian noise into user and item embeddings derived from various recommender systems during the forward phase. Subsequently, it iteratively eliminates this noise in the reverse denoising phase, thereby augmenting the embeddings' resilience to noisy feedback. The primary challenge in this process is determining direction and an optimal starting point for the denoising process. To address this, we incorporate a specialized denoising module that utilizes collaborative data as a guide for the denoising process. Furthermore, during the inference phase, we employ the average of item embeddings previously favored by users as the starting point to facilitate ideal item generation. Our thorough evaluations across three datasets and in conjunction with three classic backend models confirm its superior performance.
Plug-in Diffusion Model for Sequential Recommendation
Jan 05, 2024Pioneering efforts have verified the effectiveness of the diffusion models in exploring the informative uncertainty for recommendation. Considering the difference between recommendation and image synthesis tasks, existing methods have undertaken tailored refinements to the diffusion and reverse process. However, these approaches typically use the highest-score item in corpus for user interest prediction, leading to the ignorance of the user's generalized preference contained within other items, thereby remaining constrained by the data sparsity issue. To address this issue, this paper presents a novel Plug-in Diffusion Model for Recommendation (PDRec) framework, which employs the diffusion model as a flexible plugin to jointly take full advantage of the diffusion-generating user preferences on all items. Specifically, PDRec first infers the users' dynamic preferences on all items via a time-interval diffusion model and proposes a Historical Behavior Reweighting (HBR) mechanism to identify the high-quality behaviors and suppress noisy behaviors. In addition to the observed items, PDRec proposes a Diffusion-based Positive Augmentation (DPA) strategy to leverage the top-ranked unobserved items as the potential positive samples, bringing in informative and diverse soft signals to alleviate data sparsity. To alleviate the false negative sampling issue, PDRec employs Noise-free Negative Sampling (NNS) to select stable negative samples for ensuring effective model optimization. Extensive experiments and analyses on four datasets have verified the superiority of the proposed PDRec over the state-of-the-art baselines and showcased the universality of PDRec as a flexible plugin for commonly-used sequential encoders in different recommendation scenarios. The code is available in https://github.com/hulkima/PDRec.
A Survey on Cross-Domain Sequential Recommendation
Jan 19, 2024Cross-domain sequential recommendation (CDSR) shifts the modeling of user preferences from flat to stereoscopic by integrating and learning interaction information from multiple domains at different granularities (ranging from inter-sequence to intra-sequence and from single-domain to cross-domain). In this survey, we first define the CDSR problem using a four-dimensional tensor and then analyze its multi-type input representations under multidirectional dimensionality reductions. Following that, we provide a systematic overview from both macro and micro views. From a macro view, we abstract the multi-level fusion structures of various models across domains and discuss their bridges for fusion. From a micro view, focusing on the existing models, we specifically discuss the basic technologies and then explain the auxiliary learning technologies. Finally, we exhibit the available public datasets and the representative experimental results as well as provide some insights into future directions for research in CDSR.
Unlocking the `Why' of Buying: Introducing a New Dataset and Benchmark for Purchase Reason and Post-Purchase Experience
Feb 20, 2024Explanations are crucial for enhancing user trust and understanding within modern recommendation systems. To build truly explainable systems, we need high-quality datasets that elucidate why users make choices. While previous efforts have focused on extracting users' post-purchase sentiment in reviews, they ignore the reasons behind the decision to buy. In our work, we propose a novel purchase reason explanation task. To this end, we introduce an LLM-based approach to generate a dataset that consists of textual explanations of why real users make certain purchase decisions. We induce LLMs to explicitly distinguish between the reasons behind purchasing a product and the experience after the purchase in a user review. An automated, LLM-driven evaluation, as well as a small scale human evaluation, confirms the effectiveness of our approach to obtaining high-quality, personalized explanations. We benchmark this dataset on two personalized explanation generation tasks. We release the code and prompts to spur further research.
Helen: Optimizing CTR Prediction Models with Frequency-wise Hessian Eigenvalue Regularization
Feb 23, 2024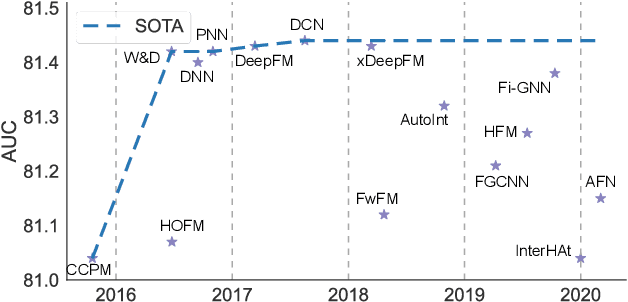
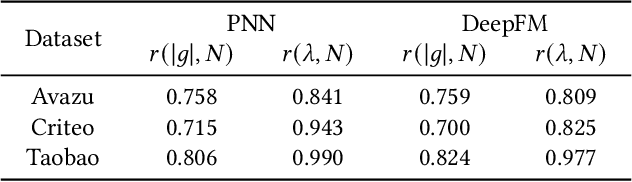
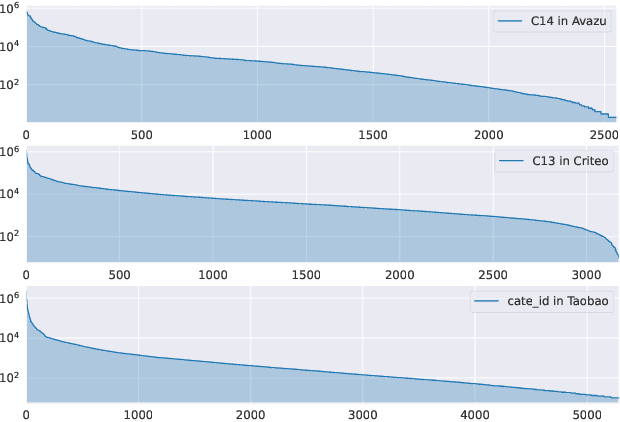
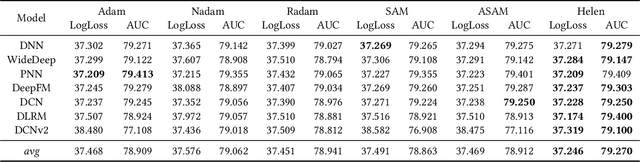
Click-Through Rate (CTR) prediction holds paramount significance in online advertising and recommendation scenarios. Despite the proliferation of recent CTR prediction models, the improvements in performance have remained limited, as evidenced by open-source benchmark assessments. Current researchers tend to focus on developing new models for various datasets and settings, often neglecting a crucial question: What is the key challenge that truly makes CTR prediction so demanding? In this paper, we approach the problem of CTR prediction from an optimization perspective. We explore the typical data characteristics and optimization statistics of CTR prediction, revealing a strong positive correlation between the top hessian eigenvalue and feature frequency. This correlation implies that frequently occurring features tend to converge towards sharp local minima, ultimately leading to suboptimal performance. Motivated by the recent advancements in sharpness-aware minimization (SAM), which considers the geometric aspects of the loss landscape during optimization, we present a dedicated optimizer crafted for CTR prediction, named Helen. Helen incorporates frequency-wise Hessian eigenvalue regularization, achieved through adaptive perturbations based on normalized feature frequencies. Empirical results under the open-source benchmark framework underscore Helen's effectiveness. It successfully constrains the top eigenvalue of the Hessian matrix and demonstrates a clear advantage over widely used optimization algorithms when applied to seven popular models across three public benchmark datasets on BARS. Our code locates at github.com/NUS-HPC-AI-Lab/Helen.
End-to-end Learnable Clustering for Intent Learning in Recommendation
Jan 11, 2024Mining users' intents plays a crucial role in sequential recommendation. The recent approach, ICLRec, was introduced to extract underlying users' intents using contrastive learning and clustering. While it has shown effectiveness, the existing method suffers from complex and cumbersome alternating optimization, leading to two main issues. Firstly, the separation of representation learning and clustering optimization within a generalized expectation maximization (EM) framework often results in sub-optimal performance. Secondly, performing clustering on the entire dataset hampers scalability for large-scale industry data. To address these challenges, we propose a novel intent learning method called \underline{ELCRec}, which integrates representation learning into an \underline{E}nd-to-end \underline{L}earnable \underline{C}lustering framework for \underline{Rec}ommendation. Specifically, we encode users' behavior sequences and initialize the cluster centers as learnable network parameters. Additionally, we design a clustering loss that guides the networks to differentiate between different cluster centers and pull similar samples towards their respective cluster centers. This allows simultaneous optimization of recommendation and clustering using mini-batch data. Moreover, we leverage the learned cluster centers as self-supervision signals for representation learning, resulting in further enhancement of recommendation performance. Extensive experiments conducted on open benchmarks and industry data validate the superiority, effectiveness, and efficiency of our proposed ELCRec method. Code is available at: https://github.com/yueliu1999/ELCRec.
MOReGIn: Multi-Objective Recommendation at the Global and Individual Levels
Jan 23, 2024Multi-Objective Recommender Systems (MORSs) emerged as a paradigm to guarantee multiple (often conflicting) goals. Besides accuracy, a MORS can operate at the global level, where additional beyond-accuracy goals are met for the system as a whole, or at the individual level, meaning that the recommendations are tailored to the needs of each user. The state-of-the-art MORSs either operate at the global or individual level, without assuming the co-existence of the two perspectives. In this study, we show that when global and individual objectives co-exist, MORSs are not able to meet both types of goals. To overcome this issue, we present an approach that regulates the recommendation lists so as to guarantee both global and individual perspectives, while preserving its effectiveness. Specifically, as individual perspective, we tackle genre calibration and, as global perspective, provider fairness. We validate our approach on two real-world datasets, publicly released with this paper.