 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Empirical and Experimental Perspectives on Big Data in Recommendation Systems: A Comprehensive Survey
Feb 01, 2024
This survey paper provides a comprehensive analysis of big data algorithms in recommendation systems, addressing the lack of depth and precision in existing literature. It proposes a two-pronged approach: a thorough analysis of current algorithms and a novel, hierarchical taxonomy for precise categorization. The taxonomy is based on a tri-level hierarchy, starting with the methodology category and narrowing down to specific techniques. Such a framework allows for a structured and comprehensive classification of algorithms, assisting researchers in understanding the interrelationships among diverse algorithms and techniques. Covering a wide range of algorithms, this taxonomy first categorizes algorithms into four main analysis types: User and Item Similarity-Based Methods, Hybrid and Combined Approaches, Deep Learning and Algorithmic Methods, and Mathematical Modeling Methods, with further subdivisions into sub-categories and techniques. The paper incorporates both empirical and experimental evaluations to differentiate between the techniques. The empirical evaluation ranks the techniques based on four criteria. The experimental assessments rank the algorithms that belong to the same category, sub-category, technique, and sub-technique. Also, the paper illuminates the future prospects of big data techniques in recommendation systems, underscoring potential advancements and opportunities for further research in this field
RimiRec: Modeling Refined Multi-interest in Hierarchical Structure for Recommendation
Feb 06, 2024Industrial recommender systems usually consist of the retrieval stage and the ranking stage, to handle the billion-scale of users and items. The retrieval stage retrieves candidate items relevant to user interests for recommendations and has attracted much attention. Frequently, a user shows refined multi-interests in a hierarchical structure. For example, a user likes Conan and Kuroba Kaito, which are the roles in hierarchical structure "Animation, Japanese Animation, Detective Conan". However, most existing methods ignore this hierarchical nature, and simply average the fine-grained interest information. Therefore, we propose a novel two-stage approach to explicitly modeling refined multi-interest in a hierarchical structure for recommendation. In the first hierarchical multi-interest mining stage, the hierarchical clustering and transformer-based model adaptively generate circles or sub-circles that users are interested in. In the second stage, the partition of retrieval space allows the EBR models to deal only with items within each circle and accurately capture users' refined interests. Experimental results show that the proposed approach achieves state-of-the-art performance. Our framework has also been deployed at Lofter.
CounterCLR: Counterfactual Contrastive Learning with Non-random Missing Data in Recommendation
Feb 08, 2024Recommender systems are designed to learn user preferences from observed feedback and comprise many fundamental tasks, such as rating prediction and post-click conversion rate (pCVR) prediction. However, the observed feedback usually suffer from two issues: selection bias and data sparsity, where biased and insufficient feedback seriously degrade the performance of recommender systems in terms of accuracy and ranking. Existing solutions for handling the issues, such as data imputation and inverse propensity score, are highly susceptible to additional trained imputation or propensity models. In this work, we propose a novel counterfactual contrastive learning framework for recommendation, named CounterCLR, to tackle the problem of non-random missing data by exploiting the advances in contrast learning. Specifically, the proposed CounterCLR employs a deep representation network, called CauNet, to infer non-random missing data in recommendations and perform user preference modeling by further introducing a self-supervised contrastive learning task. Our CounterCLR mitigates the selection bias problem without the need for additional models or estimators, while also enhancing the generalization ability in cases of sparse data. Experiments on real-world datasets demonstrate the effectiveness and superiority of our method.
A General and Flexible Multi-concept Parsing Framework for Multilingual Semantic Matching
Mar 05, 2024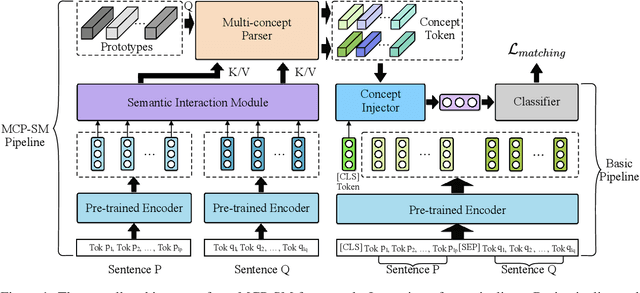
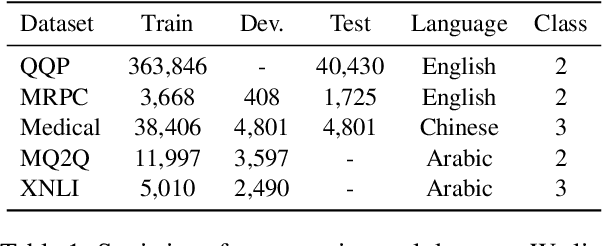
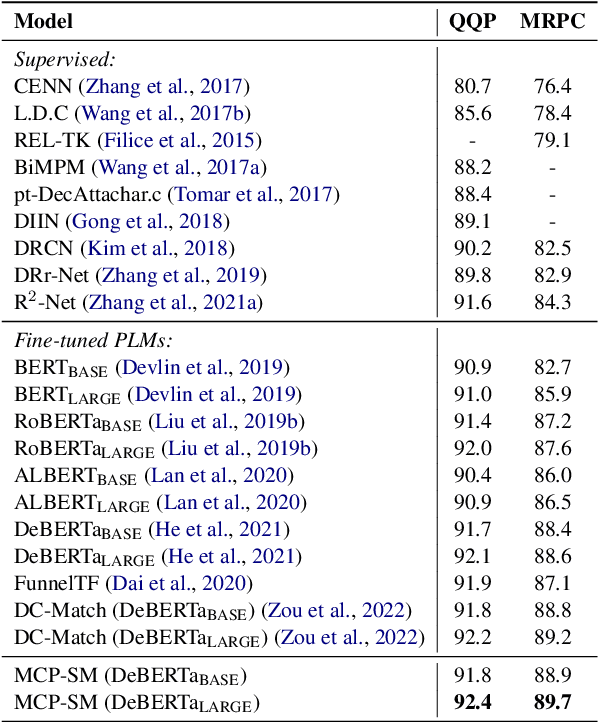
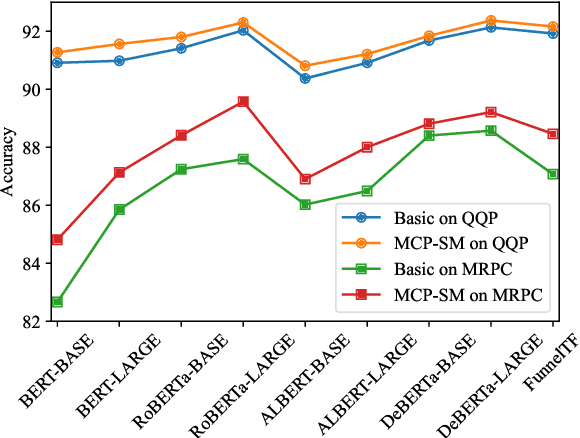
Sentence semantic matching is a research hotspot in natural language processing, which is considerably significant in various key scenarios, such as community question answering, searching, chatbot, and recommendation. Since most of the advanced models directly model the semantic relevance among words between two sentences while neglecting the \textit{keywords} and \textit{intents} concepts of them, DC-Match is proposed to disentangle keywords from intents and utilizes them to optimize the matching performance. Although DC-Match is a simple yet effective method for semantic matching, it highly depends on the external NER techniques to identify the keywords of sentences, which limits the performance of semantic matching for minor languages since satisfactory NER tools are usually hard to obtain. In this paper, we propose to generally and flexibly resolve the text into multi concepts for multilingual semantic matching to liberate the model from the reliance on NER models. To this end, we devise a \underline{M}ulti-\underline{C}oncept \underline{P}arsed \underline{S}emantic \underline{M}atching framework based on the pre-trained language models, abbreviated as \textbf{MCP-SM}, to extract various concepts and infuse them into the classification tokens. We conduct comprehensive experiments on English datasets QQP and MRPC, and Chinese dataset Medical-SM. Besides, we experiment on Arabic datasets MQ2Q and XNLI, the outstanding performance further prove MCP-SM's applicability in low-resource languages.
KeNet:Knowledge-enhanced Doc-Label Attention Network for Multi-label text classification
Mar 04, 2024
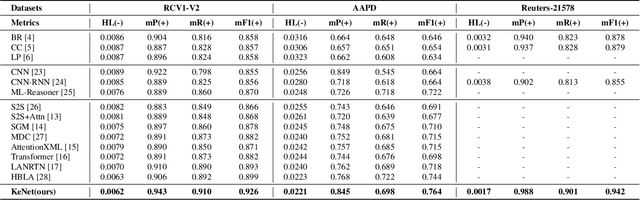
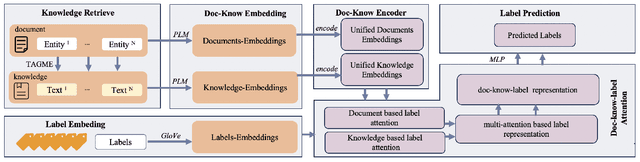
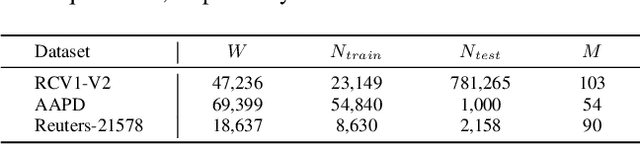
Multi-Label Text Classification (MLTC) is a fundamental task in the field of Natural Language Processing (NLP) that involves the assignment of multiple labels to a given text. MLTC has gained significant importance and has been widely applied in various domains such as topic recognition, recommendation systems, sentiment analysis, and information retrieval. However, traditional machine learning and Deep neural network have not yet addressed certain issues, such as the fact that some documents are brief but have a large number of labels and how to establish relationships between the labels. It is imperative to additionally acknowledge that the significance of knowledge is substantiated in the realm of MLTC. To address this issue, we provide a novel approach known as Knowledge-enhanced Doc-Label Attention Network (KeNet). Specifically, we design an Attention Network that incorporates external knowledge, label embedding, and a comprehensive attention mechanism. In contrast to conventional methods, we use comprehensive representation of documents, knowledge and labels to predict all labels for each single text. Our approach has been validated by comprehensive research conducted on three multi-label datasets. Experimental results demonstrate that our method outperforms state-of-the-art MLTC method. Additionally, a case study is undertaken to illustrate the practical implementation of KeNet.
Prompt-enhanced Federated Content Representation Learning for Cross-domain Recommendation
Jan 31, 2024Cross-domain Recommendation (CDR) as one of the effective techniques in alleviating the data sparsity issues has been widely studied in recent years. However, previous works may cause domain privacy leakage since they necessitate the aggregation of diverse domain data into a centralized server during the training process. Though several studies have conducted privacy preserving CDR via Federated Learning (FL), they still have the following limitations: 1) They need to upload users' personal information to the central server, posing the risk of leaking user privacy. 2) Existing federated methods mainly rely on atomic item IDs to represent items, which prevents them from modeling items in a unified feature space, increasing the challenge of knowledge transfer among domains. 3) They are all based on the premise of knowing overlapped users between domains, which proves impractical in real-world applications. To address the above limitations, we focus on Privacy-preserving Cross-domain Recommendation (PCDR) and propose PFCR as our solution. For Limitation 1, we develop a FL schema by exclusively utilizing users' interactions with local clients and devising an encryption method for gradient encryption. For Limitation 2, we model items in a universal feature space by their description texts. For Limitation 3, we initially learn federated content representations, harnessing the generality of natural language to establish bridges between domains. Subsequently, we craft two prompt fine-tuning strategies to tailor the pre-trained model to the target domain. Extensive experiments on two real-world datasets demonstrate the superiority of our PFCR method compared to the SOTA approaches.
Contrastive Pre-training for Deep Session Data Understanding
Mar 05, 2024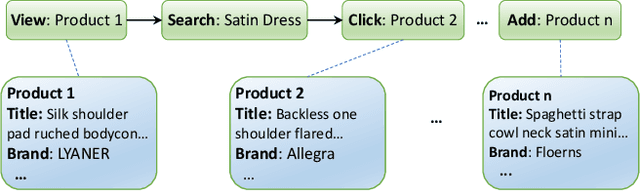
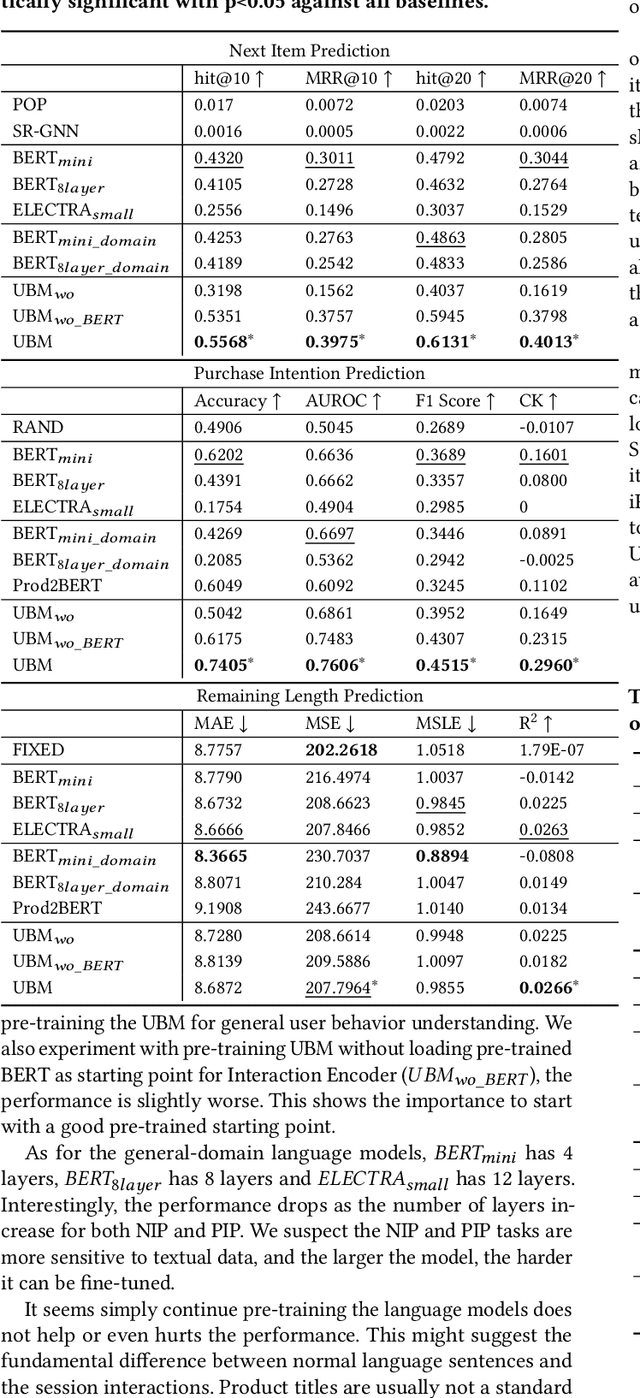
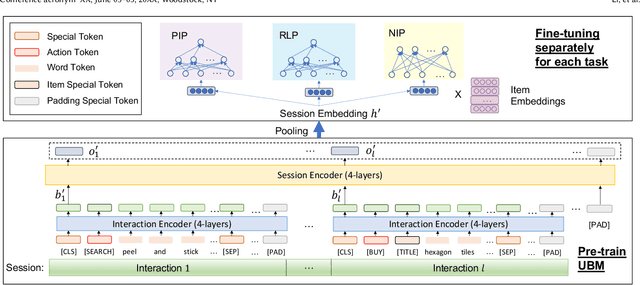
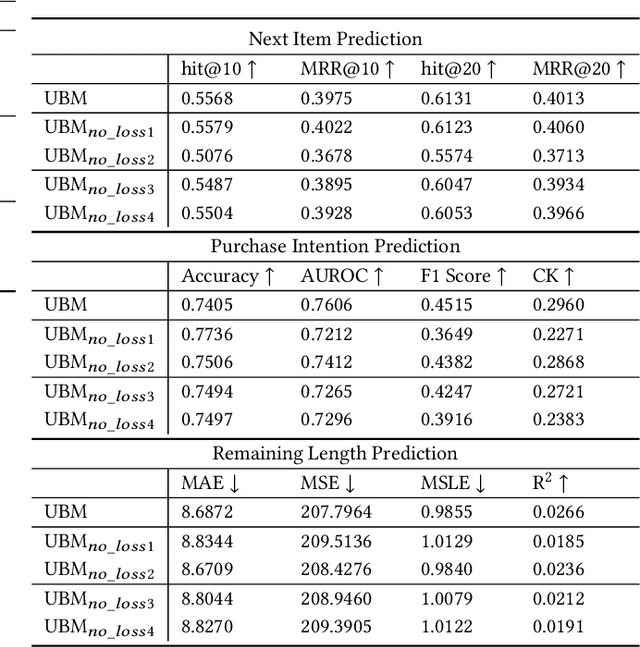
Session data has been widely used for understanding user's behavior in e-commerce. Researchers are trying to leverage session data for different tasks, such as purchase intention prediction, remaining length prediction, recommendation, etc., as it provides context clues about the user's dynamic interests. However, online shopping session data is semi-structured and complex in nature, which contains both unstructured textual data about the products, search queries, and structured user action sequences. Most existing works focus on leveraging the coarse-grained item sequences for specific tasks, while largely ignore the fine-grained information from text and user action details. In this work, we delve into deep session data understanding via scrutinizing the various clues inside the rich information in user sessions. Specifically, we propose to pre-train a general-purpose User Behavior Model (UBM) over large-scale session data with rich details, such as product title, attributes and various kinds of user actions. A two-stage pre-training scheme is introduced to encourage the model to self-learn from various augmentations with contrastive learning objectives, which spans different granularity levels of session data. Then the well-trained session understanding model can be easily fine-tuned for various downstream tasks. Extensive experiments show that UBM better captures the complex intra-item semantic relations, inter-item connections and inter-interaction dependencies, leading to large performance gains as compared to the baselines on several downstream tasks. And it also demonstrates strong robustness when data is sparse.
Deep Reinforcement Learning for Solving Management Problems: Towards A Large Management Mode
Mar 01, 2024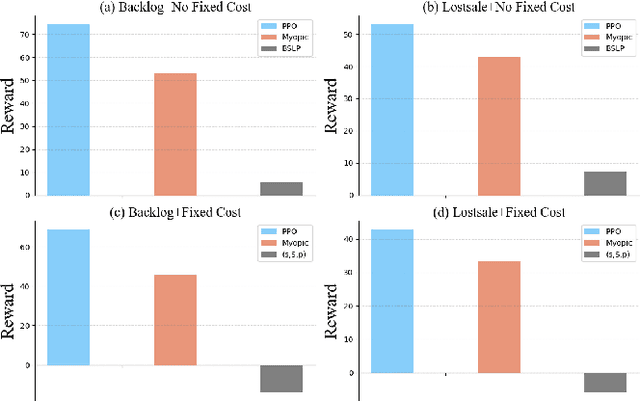
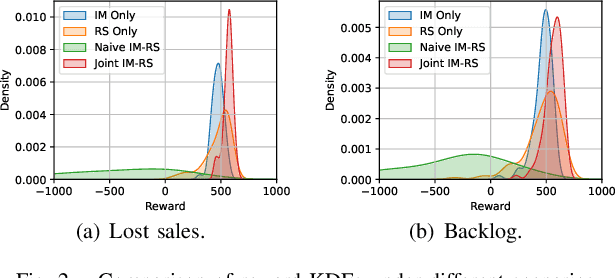
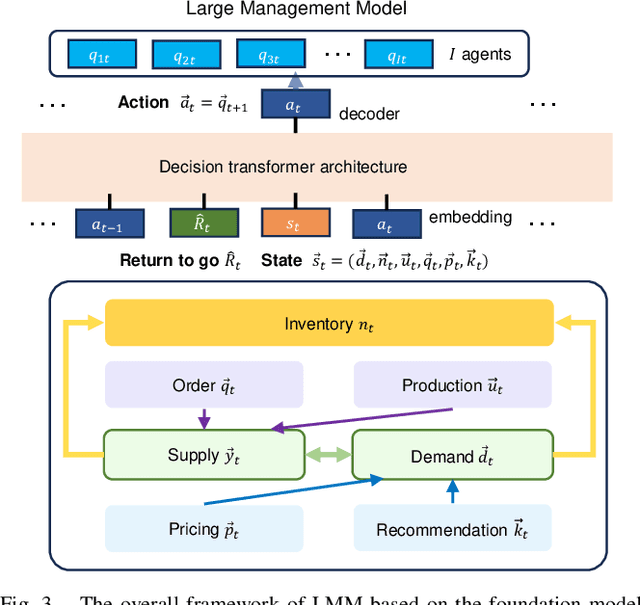
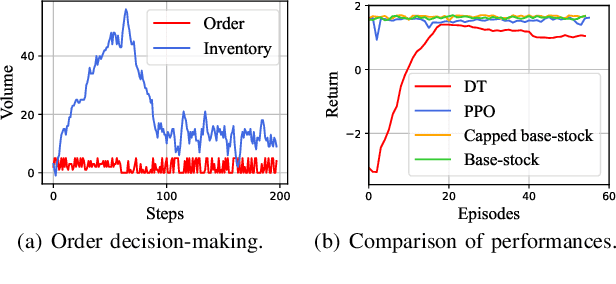
We introduce a deep reinforcement learning (DRL) approach for solving management problems including inventory management, dynamic pricing, and recommendation. This DRL approach has the potential to lead to a large management model based on certain transformer neural network structures, resulting in an artificial general intelligence paradigm for various management tasks. Traditional methods have limitations for solving complex real-world problems, and we demonstrate how DRL can surpass existing heuristic approaches for solving management tasks. We aim to solve the problems in a unified framework, considering the interconnections between different tasks. Central to our methodology is the development of a foundational decision model coordinating decisions across the different domains through generative decision-making. Our experimental results affirm the effectiveness of our DRL-based framework in complex and dynamic business environments. This work opens new pathways for the application of DRL in management problems, highlighting its potential to revolutionize traditional business management.
PromptMM: Multi-Modal Knowledge Distillation for Recommendation with Prompt-Tuning
Feb 27, 2024Multimedia online platforms (e.g., Amazon, TikTok) have greatly benefited from the incorporation of multimedia (e.g., visual, textual, and acoustic) content into their personal recommender systems. These modalities provide intuitive semantics that facilitate modality-aware user preference modeling. However, two key challenges in multi-modal recommenders remain unresolved: i) The introduction of multi-modal encoders with a large number of additional parameters causes overfitting, given high-dimensional multi-modal features provided by extractors (e.g., ViT, BERT). ii) Side information inevitably introduces inaccuracies and redundancies, which skew the modality-interaction dependency from reflecting true user preference. To tackle these problems, we propose to simplify and empower recommenders through Multi-modal Knowledge Distillation (PromptMM) with the prompt-tuning that enables adaptive quality distillation. Specifically, PromptMM conducts model compression through distilling u-i edge relationship and multi-modal node content from cumbersome teachers to relieve students from the additional feature reduction parameters. To bridge the semantic gap between multi-modal context and collaborative signals for empowering the overfitting teacher, soft prompt-tuning is introduced to perform student task-adaptive. Additionally, to adjust the impact of inaccuracies in multimedia data, a disentangled multi-modal list-wise distillation is developed with modality-aware re-weighting mechanism. Experiments on real-world data demonstrate PromptMM's superiority over existing techniques. Ablation tests confirm the effectiveness of key components. Additional tests show the efficiency and effectiveness.