 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Deep Reinforcement Learning for Solving Management Problems: Towards A Large Management Mode
Mar 01, 2024
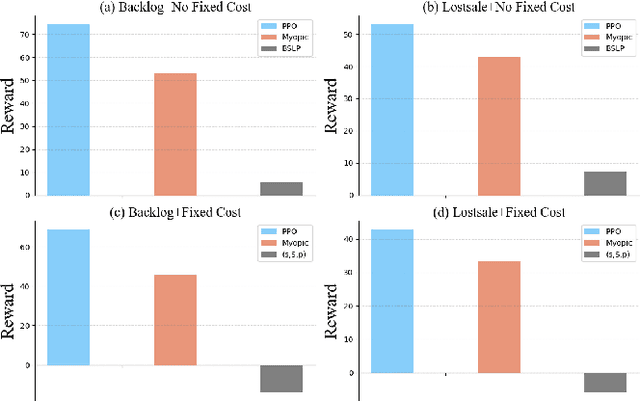
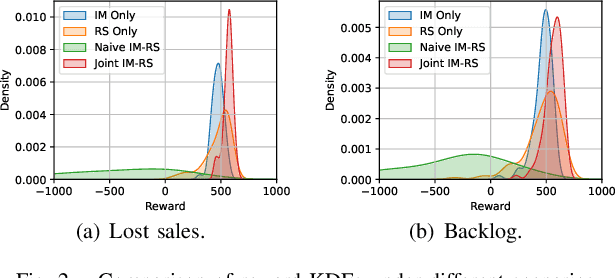
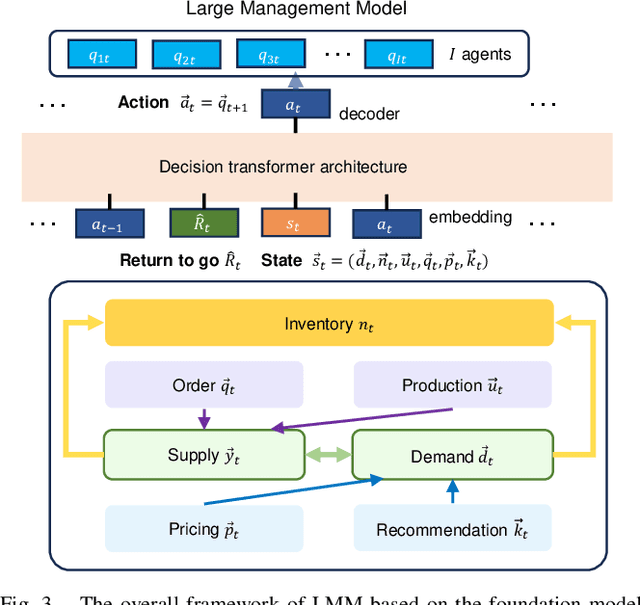
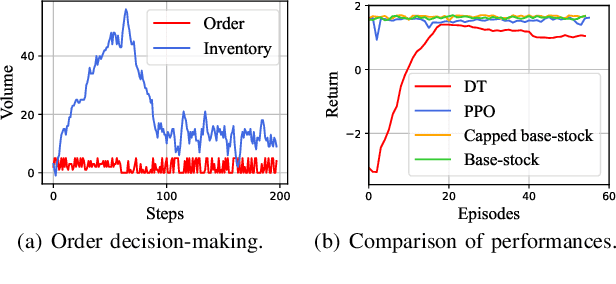
We introduce a deep reinforcement learning (DRL) approach for solving management problems including inventory management, dynamic pricing, and recommendation. This DRL approach has the potential to lead to a large management model based on certain transformer neural network structures, resulting in an artificial general intelligence paradigm for various management tasks. Traditional methods have limitations for solving complex real-world problems, and we demonstrate how DRL can surpass existing heuristic approaches for solving management tasks. We aim to solve the problems in a unified framework, considering the interconnections between different tasks. Central to our methodology is the development of a foundational decision model coordinating decisions across the different domains through generative decision-making. Our experimental results affirm the effectiveness of our DRL-based framework in complex and dynamic business environments. This work opens new pathways for the application of DRL in management problems, highlighting its potential to revolutionize traditional business management.
CounterCLR: Counterfactual Contrastive Learning with Non-random Missing Data in Recommendation
Feb 08, 2024Recommender systems are designed to learn user preferences from observed feedback and comprise many fundamental tasks, such as rating prediction and post-click conversion rate (pCVR) prediction. However, the observed feedback usually suffer from two issues: selection bias and data sparsity, where biased and insufficient feedback seriously degrade the performance of recommender systems in terms of accuracy and ranking. Existing solutions for handling the issues, such as data imputation and inverse propensity score, are highly susceptible to additional trained imputation or propensity models. In this work, we propose a novel counterfactual contrastive learning framework for recommendation, named CounterCLR, to tackle the problem of non-random missing data by exploiting the advances in contrast learning. Specifically, the proposed CounterCLR employs a deep representation network, called CauNet, to infer non-random missing data in recommendations and perform user preference modeling by further introducing a self-supervised contrastive learning task. Our CounterCLR mitigates the selection bias problem without the need for additional models or estimators, while also enhancing the generalization ability in cases of sparse data. Experiments on real-world datasets demonstrate the effectiveness and superiority of our method.
Empirical and Experimental Perspectives on Big Data in Recommendation Systems: A Comprehensive Survey
Feb 01, 2024This survey paper provides a comprehensive analysis of big data algorithms in recommendation systems, addressing the lack of depth and precision in existing literature. It proposes a two-pronged approach: a thorough analysis of current algorithms and a novel, hierarchical taxonomy for precise categorization. The taxonomy is based on a tri-level hierarchy, starting with the methodology category and narrowing down to specific techniques. Such a framework allows for a structured and comprehensive classification of algorithms, assisting researchers in understanding the interrelationships among diverse algorithms and techniques. Covering a wide range of algorithms, this taxonomy first categorizes algorithms into four main analysis types: User and Item Similarity-Based Methods, Hybrid and Combined Approaches, Deep Learning and Algorithmic Methods, and Mathematical Modeling Methods, with further subdivisions into sub-categories and techniques. The paper incorporates both empirical and experimental evaluations to differentiate between the techniques. The empirical evaluation ranks the techniques based on four criteria. The experimental assessments rank the algorithms that belong to the same category, sub-category, technique, and sub-technique. Also, the paper illuminates the future prospects of big data techniques in recommendation systems, underscoring potential advancements and opportunities for further research in this field
RimiRec: Modeling Refined Multi-interest in Hierarchical Structure for Recommendation
Feb 06, 2024Industrial recommender systems usually consist of the retrieval stage and the ranking stage, to handle the billion-scale of users and items. The retrieval stage retrieves candidate items relevant to user interests for recommendations and has attracted much attention. Frequently, a user shows refined multi-interests in a hierarchical structure. For example, a user likes Conan and Kuroba Kaito, which are the roles in hierarchical structure "Animation, Japanese Animation, Detective Conan". However, most existing methods ignore this hierarchical nature, and simply average the fine-grained interest information. Therefore, we propose a novel two-stage approach to explicitly modeling refined multi-interest in a hierarchical structure for recommendation. In the first hierarchical multi-interest mining stage, the hierarchical clustering and transformer-based model adaptively generate circles or sub-circles that users are interested in. In the second stage, the partition of retrieval space allows the EBR models to deal only with items within each circle and accurately capture users' refined interests. Experimental results show that the proposed approach achieves state-of-the-art performance. Our framework has also been deployed at Lofter.
Prompt-enhanced Federated Content Representation Learning for Cross-domain Recommendation
Jan 31, 2024Cross-domain Recommendation (CDR) as one of the effective techniques in alleviating the data sparsity issues has been widely studied in recent years. However, previous works may cause domain privacy leakage since they necessitate the aggregation of diverse domain data into a centralized server during the training process. Though several studies have conducted privacy preserving CDR via Federated Learning (FL), they still have the following limitations: 1) They need to upload users' personal information to the central server, posing the risk of leaking user privacy. 2) Existing federated methods mainly rely on atomic item IDs to represent items, which prevents them from modeling items in a unified feature space, increasing the challenge of knowledge transfer among domains. 3) They are all based on the premise of knowing overlapped users between domains, which proves impractical in real-world applications. To address the above limitations, we focus on Privacy-preserving Cross-domain Recommendation (PCDR) and propose PFCR as our solution. For Limitation 1, we develop a FL schema by exclusively utilizing users' interactions with local clients and devising an encryption method for gradient encryption. For Limitation 2, we model items in a universal feature space by their description texts. For Limitation 3, we initially learn federated content representations, harnessing the generality of natural language to establish bridges between domains. Subsequently, we craft two prompt fine-tuning strategies to tailor the pre-trained model to the target domain. Extensive experiments on two real-world datasets demonstrate the superiority of our PFCR method compared to the SOTA approaches.
PromptMM: Multi-Modal Knowledge Distillation for Recommendation with Prompt-Tuning
Feb 27, 2024Multimedia online platforms (e.g., Amazon, TikTok) have greatly benefited from the incorporation of multimedia (e.g., visual, textual, and acoustic) content into their personal recommender systems. These modalities provide intuitive semantics that facilitate modality-aware user preference modeling. However, two key challenges in multi-modal recommenders remain unresolved: i) The introduction of multi-modal encoders with a large number of additional parameters causes overfitting, given high-dimensional multi-modal features provided by extractors (e.g., ViT, BERT). ii) Side information inevitably introduces inaccuracies and redundancies, which skew the modality-interaction dependency from reflecting true user preference. To tackle these problems, we propose to simplify and empower recommenders through Multi-modal Knowledge Distillation (PromptMM) with the prompt-tuning that enables adaptive quality distillation. Specifically, PromptMM conducts model compression through distilling u-i edge relationship and multi-modal node content from cumbersome teachers to relieve students from the additional feature reduction parameters. To bridge the semantic gap between multi-modal context and collaborative signals for empowering the overfitting teacher, soft prompt-tuning is introduced to perform student task-adaptive. Additionally, to adjust the impact of inaccuracies in multimedia data, a disentangled multi-modal list-wise distillation is developed with modality-aware re-weighting mechanism. Experiments on real-world data demonstrate PromptMM's superiority over existing techniques. Ablation tests confirm the effectiveness of key components. Additional tests show the efficiency and effectiveness.
Influencing Bandits: Arm Selection for Preference Shaping
Feb 29, 2024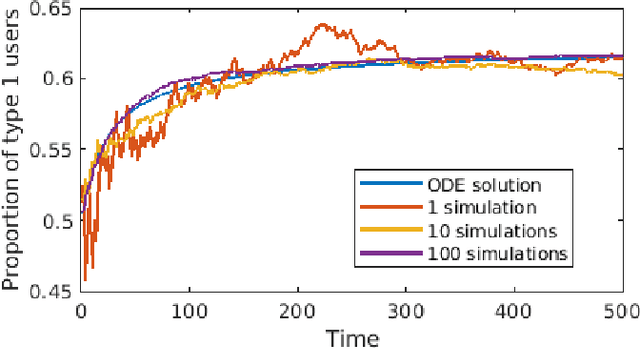
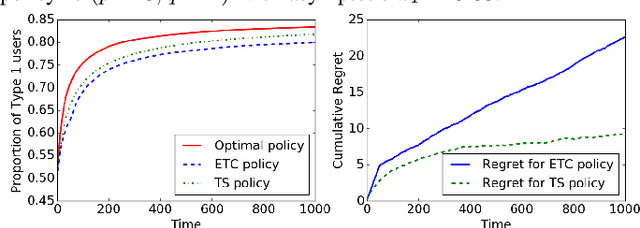
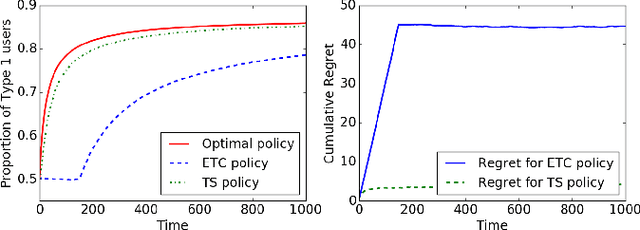
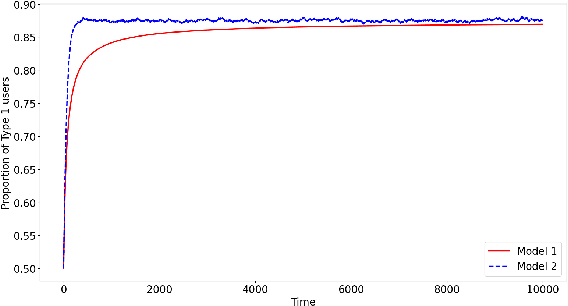
We consider a non stationary multi-armed bandit in which the population preferences are positively and negatively reinforced by the observed rewards. The objective of the algorithm is to shape the population preferences to maximize the fraction of the population favouring a predetermined arm. For the case of binary opinions, two types of opinion dynamics are considered -- decreasing elasticity (modeled as a Polya urn with increasing number of balls) and constant elasticity (using the voter model). For the first case, we describe an Explore-then-commit policy and a Thompson sampling policy and analyse the regret for each of these policies. We then show that these algorithms and their analyses carry over to the constant elasticity case. We also describe a Thompson sampling based algorithm for the case when more than two types of opinions are present. Finally, we discuss the case where presence of multiple recommendation systems gives rise to a trade-off between their popularity and opinion shaping objectives.
On Practical Diversified Recommendation with Controllable Category Diversity Framework
Feb 06, 2024Recommender systems have made significant strides in various industries, primarily driven by extensive efforts to enhance recommendation accuracy. However, this pursuit of accuracy has inadvertently given rise to echo chamber/filter bubble effects. Especially in industry, it could impair user's experiences and prevent user from accessing a wider range of items. One of the solutions is to take diversity into account. However, most of existing works focus on user's explicit preferences, while rarely exploring user's non-interaction preferences. These neglected non-interaction preferences are especially important for broadening user's interests in alleviating echo chamber/filter bubble effects.Therefore, in this paper, we first define diversity as two distinct definitions, i.e., user-explicit diversity (U-diversity) and user-item non-interaction diversity (N-diversity) based on user historical behaviors. Then, we propose a succinct and effective method, named as Controllable Category Diversity Framework (CCDF) to achieve both high U-diversity and N-diversity simultaneously.Specifically, CCDF consists of two stages, User-Category Matching and Constrained Item Matching. The User-Category Matching utilizes the DeepU2C model and a combined loss to capture user's preferences in categories, and then selects the top-$K$ categories with a controllable parameter $K$.These top-$K$ categories will be used as trigger information in Constrained Item Matching. Offline experimental results show that our proposed DeepU2C outperforms state-of-the-art diversity-oriented methods, especially on N-diversity task. The whole framework is validated in a real-world production environment by conducting online A/B testing.
* A Two-stage Controllable Category Diversity Framework for Recommendation
A Review of Data Mining in Personalized Education: Current Trends and Future Prospects
Feb 27, 2024Personalized education, tailored to individual student needs, leverages educational technology and artificial intelligence (AI) in the digital age to enhance learning effectiveness. The integration of AI in educational platforms provides insights into academic performance, learning preferences, and behaviors, optimizing the personal learning process. Driven by data mining techniques, it not only benefits students but also provides educators and institutions with tools to craft customized learning experiences. To offer a comprehensive review of recent advancements in personalized educational data mining, this paper focuses on four primary scenarios: educational recommendation, cognitive diagnosis, knowledge tracing, and learning analysis. This paper presents a structured taxonomy for each area, compiles commonly used datasets, and identifies future research directions, emphasizing the role of data mining in enhancing personalized education and paving the way for future exploration and innovation.
* 25 pages, 5 figures