 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
BOXREC: Recommending a Box of Preferred Outfits in Online Shopping
Feb 26, 2024
Over the past few years, automation of outfit composition has gained much attention from the research community. Most of the existing outfit recommendation systems focus on pairwise item compatibility prediction (using visual and text features) to score an outfit combination having several items, followed by recommendation of top-n outfits or a capsule wardrobe having a collection of outfits based on user's fashion taste. However, none of these consider user's preference of price-range for individual clothing types or an overall shopping budget for a set of items. In this paper, we propose a box recommendation framework - BOXREC - which at first, collects user preferences across different item types (namely, top-wear, bottom-wear and foot-wear) including price-range of each type and a maximum shopping budget for a particular shopping session. It then generates a set of preferred outfits by retrieving all types of preferred items from the database (according to user specified preferences including price-ranges), creates all possible combinations of three preferred items (belonging to distinct item types) and verifies each combination using an outfit scoring framework - BOXREC-OSF. Finally, it provides a box full of fashion items, such that different combinations of the items maximize the number of outfits suitable for an occasion while satisfying maximum shopping budget. Empirical results show superior performance of BOXREC-OSF over the baseline methods.
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
Mar 08, 2024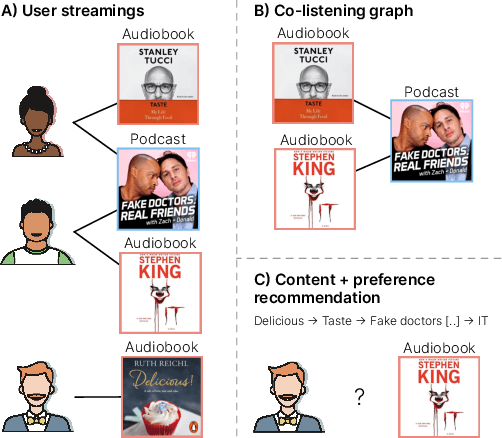
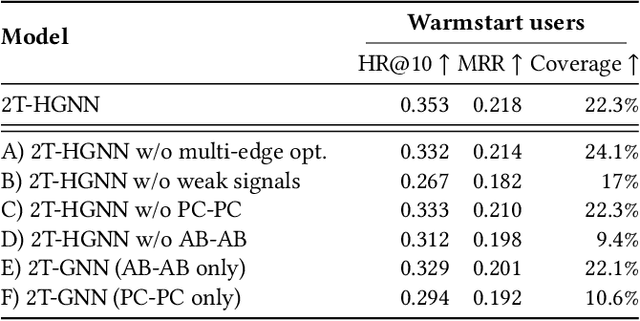
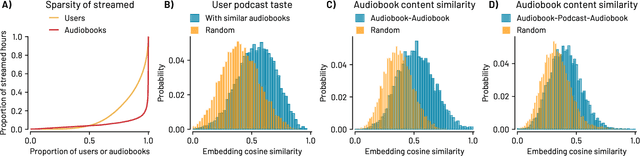
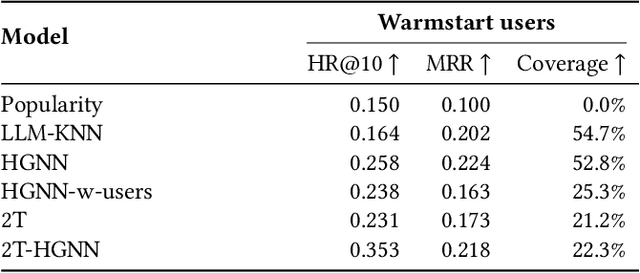
In the ever-evolving digital audio landscape, Spotify, well-known for its music and talk content, has recently introduced audiobooks to its vast user base. While promising, this move presents significant challenges for personalized recommendations. Unlike music and podcasts, audiobooks, initially available for a fee, cannot be easily skimmed before purchase, posing higher stakes for the relevance of recommendations. Furthermore, introducing a new content type into an existing platform confronts extreme data sparsity, as most users are unfamiliar with this new content type. Lastly, recommending content to millions of users requires the model to react fast and be scalable. To address these challenges, we leverage podcast and music user preferences and introduce 2T-HGNN, a scalable recommendation system comprising Heterogeneous Graph Neural Networks (HGNNs) and a Two Tower (2T) model. This novel approach uncovers nuanced item relationships while ensuring low latency and complexity. We decouple users from the HGNN graph and propose an innovative multi-link neighbor sampler. These choices, together with the 2T component, significantly reduce the complexity of the HGNN model. Empirical evaluations involving millions of users show significant improvement in the quality of personalized recommendations, resulting in a +46% increase in new audiobooks start rate and a +23% boost in streaming rates. Intriguingly, our model's impact extends beyond audiobooks, benefiting established products like podcasts.
Filter Bubble or Homogenization? Disentangling the Long-Term Effects of Recommendations on User Consumption Patterns
Feb 22, 2024Recommendation algorithms play a pivotal role in shaping our media choices, which makes it crucial to comprehend their long-term impact on user behavior. These algorithms are often linked to two critical outcomes: homogenization, wherein users consume similar content despite disparate underlying preferences, and the filter bubble effect, wherein individuals with differing preferences only consume content aligned with their preferences (without much overlap with other users). Prior research assumes a trade-off between homogenization and filter bubble effects and then shows that personalized recommendations mitigate filter bubbles by fostering homogenization. However, because of this assumption of a tradeoff between these two effects, prior work cannot develop a more nuanced view of how recommendation systems may independently impact homogenization and filter bubble effects. We develop a more refined definition of homogenization and the filter bubble effect by decomposing them into two key metrics: how different the average consumption is between users (inter-user diversity) and how varied an individual's consumption is (intra-user diversity). We then use a novel agent-based simulation framework that enables a holistic view of the impact of recommendation systems on homogenization and filter bubble effects. Our simulations show that traditional recommendation algorithms (based on past behavior) mainly reduce filter bubbles by affecting inter-user diversity without significantly impacting intra-user diversity. Building on these findings, we introduce two new recommendation algorithms that take a more nuanced approach by accounting for both types of diversity.
Large Language Model Interaction Simulator for Cold-Start Item Recommendation
Feb 14, 2024Recommending cold items is a long-standing challenge for collaborative filtering models because these cold items lack historical user interactions to model their collaborative features. The gap between the content of cold items and their behavior patterns makes it difficult to generate accurate behavioral embeddings for cold items. Existing cold-start models use mapping functions to generate fake behavioral embeddings based on the content feature of cold items. However, these generated embeddings have significant differences from the real behavioral embeddings, leading to a negative impact on cold recommendation performance. To address this challenge, we propose an LLM Interaction Simulator (LLM-InS) to model users' behavior patterns based on the content aspect. This simulator allows recommender systems to simulate vivid interactions for each cold item and transform them from cold to warm items directly. Specifically, we outline the designing and training process of a tailored LLM-simulator that can simulate the behavioral patterns of users and items. Additionally, we introduce an efficient "filtering-and-refining" approach to take full advantage of the simulation power of the LLMs. Finally, we propose an updating method to update the embeddings of the items. we unified trains for both cold and warm items within a recommender model based on the simulated and real interactions. Extensive experiments using real behavioral embeddings demonstrate that our proposed model, LLM-InS, outperforms nine state-of-the-art cold-start methods and three LLM models in cold-start item recommendations.
Leveraging Federated Learning and Edge Computing for Recommendation Systems within Cloud Computing Networks
Mar 05, 2024
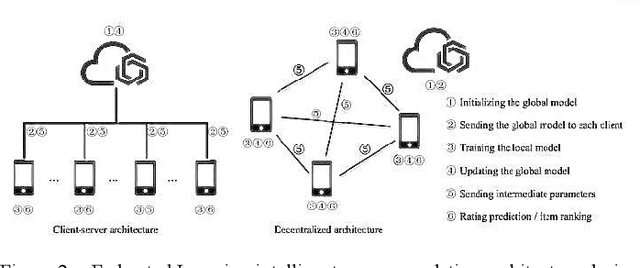
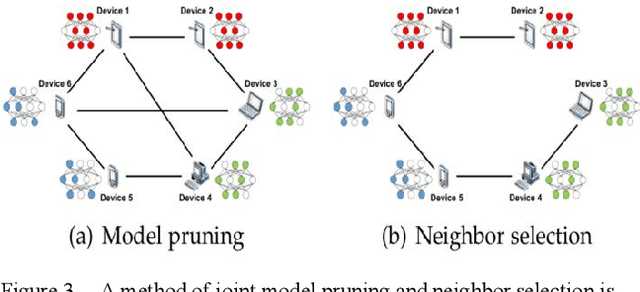

To enable large-scale and efficient deployment of artificial intelligence (AI), the combination of AI and edge computing has spawned Edge Intelligence, which leverages the computing and communication capabilities of end devices and edge servers to process data closer to where it is generated. A key technology for edge intelligence is the privacy-protecting machine learning paradigm known as Federated Learning (FL), which enables data owners to train models without having to transfer raw data to third-party servers. However, FL networks are expected to involve thousands of heterogeneous distributed devices. As a result, communication efficiency remains a key bottleneck. To reduce node failures and device exits, a Hierarchical Federated Learning (HFL) framework is proposed, where a designated cluster leader supports the data owner through intermediate model aggregation. Therefore, based on the improvement of edge server resource utilization, this paper can effectively make up for the limitation of cache capacity. In order to mitigate the impact of soft clicks on the quality of user experience (QoE), the authors model the user QoE as a comprehensive system cost. To solve the formulaic problem, the authors propose a decentralized caching algorithm with federated deep reinforcement learning (DRL) and federated learning (FL), where multiple agents learn and make decisions independently
LEGION: Harnessing Pre-trained Language Models for GitHub Topic Recommendations with Distribution-Balance Loss
Mar 09, 2024
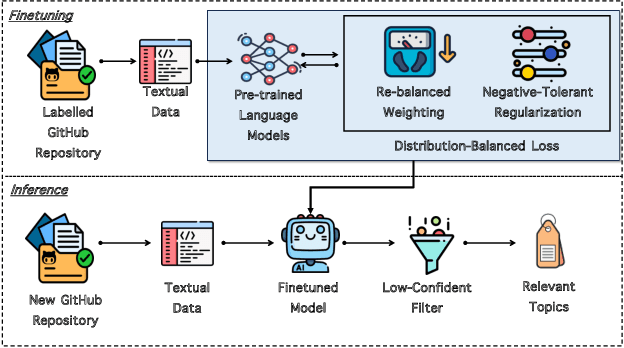


Open-source development has revolutionized the software industry by promoting collaboration, transparency, and community-driven innovation. Today, a vast amount of various kinds of open-source software, which form networks of repositories, is often hosted on GitHub - a popular software development platform. To enhance the discoverability of the repository networks, i.e., groups of similar repositories, GitHub introduced repository topics in 2017 that enable users to more easily explore relevant projects by type, technology, and more. It is thus crucial to accurately assign topics for each GitHub repository. Current methods for automatic topic recommendation rely heavily on TF-IDF for encoding textual data, presenting challenges in understanding semantic nuances. This paper addresses the limitations of existing techniques by proposing Legion, a novel approach that leverages Pre-trained Language Models (PTMs) for recommending topics for GitHub repositories. The key novelty of Legion is three-fold. First, Legion leverages the extensive capabilities of PTMs in language understanding to capture contextual information and semantic meaning in GitHub repositories. Second, Legion overcomes the challenge of long-tailed distribution, which results in a bias toward popular topics in PTMs, by proposing a Distribution-Balanced Loss (DB Loss) to better train the PTMs. Third, Legion employs a filter to eliminate vague recommendations, thereby improving the precision of PTMs. Our empirical evaluation on a benchmark dataset of real-world GitHub repositories shows that Legion can improve vanilla PTMs by up to 26% on recommending GitHubs topics. Legion also can suggest GitHub topics more precisely and effectively than the state-of-the-art baseline with an average improvement of 20% and 5% in terms of Precision and F1-score, respectively.
Intersectional Two-sided Fairness in Recommendation
Feb 05, 2024Fairness of recommender systems (RS) has attracted increasing attention recently. Based on the involved stakeholders, the fairness of RS can be divided into user fairness, item fairness, and two-sided fairness which considers both user and item fairness simultaneously. However, we argue that the intersectional two-sided unfairness may still exist even if the RS is two-sided fair, which is observed and shown by empirical studies on real-world data in this paper, and has not been well-studied previously. To mitigate this problem, we propose a novel approach called Intersectional Two-sided Fairness Recommendation (ITFR). Our method utilizes a sharpness-aware loss to perceive disadvantaged groups, and then uses collaborative loss balance to develop consistent distinguishing abilities for different intersectional groups. Additionally, predicted score normalization is leveraged to align positive predicted scores to fairly treat positives in different intersectional groups. Extensive experiments and analyses on three public datasets show that our proposed approach effectively alleviates the intersectional two-sided unfairness and consistently outperforms previous state-of-the-art methods.
Text Understanding and Generation Using Transformer Models for Intelligent E-commerce Recommendations
Feb 25, 2024With the rapid development of artificial intelligence technology, Transformer structural pre-training model has become an important tool for large language model (LLM) tasks. In the field of e-commerce, these models are especially widely used, from text understanding to generating recommendation systems, which provide powerful technical support for improving user experience and optimizing service processes. This paper reviews the core application scenarios of Transformer pre-training model in e-commerce text understanding and recommendation generation, including but not limited to automatic generation of product descriptions, sentiment analysis of user comments, construction of personalized recommendation system and automated processing of customer service conversations. Through a detailed analysis of the model's working principle, implementation process, and application effects in specific cases, this paper emphasizes the unique advantages of pre-trained models in understanding complex user intentions and improving the quality of recommendations. In addition, the challenges and improvement directions for the future are also discussed, such as how to further improve the generalization ability of the model, the ability to handle large-scale data sets, and technical strategies to protect user privacy. Ultimately, the paper points out that the application of Transformer structural pre-training models in e-commerce has not only driven technological innovation, but also brought substantial benefits to merchants and consumers, and looking forward, these models will continue to play a key role in e-commerce and beyond.
Prototypical Contrastive Learning through Alignment and Uniformity for Recommendation
Feb 03, 2024Graph Collaborative Filtering (GCF), one of the most widely adopted recommendation system methods, effectively captures intricate relationships between user and item interactions. Graph Contrastive Learning (GCL) based GCF has gained significant attention as it leverages self-supervised techniques to extract valuable signals from real-world scenarios. However, many methods usually learn the instances of discrimination tasks that involve the construction of contrastive pairs through random sampling. GCL approaches suffer from sampling bias issues, where the negatives might have a semantic structure similar to that of the positives, thus leading to a loss of effective feature representation. To address these problems, we present the \underline{Proto}typical contrastive learning through \underline{A}lignment and \underline{U}niformity for recommendation, which is called \textbf{ProtoAU}. Specifically, we first propose prototypes (cluster centroids) as a latent space to ensure consistency across different augmentations from the origin graph, aiming to eliminate the need for random sampling of contrastive pairs. Furthermore, the absence of explicit negatives means that directly optimizing the consistency loss between instance and prototype could easily result in dimensional collapse issues. Therefore, we propose aligning and maintaining uniformity in the prototypes of users and items as optimization objectives to prevent falling into trivial solutions. Finally, we conduct extensive experiments on four datasets and evaluate their performance on the task of link prediction. Experimental results demonstrate that the proposed ProtoAU outperforms other representative methods. The source codes of our proposed ProtoAU are available at \url{https://github.com/oceanlvr/ProtoAU}.
CAREForMe: Contextual Multi-Armed Bandit Recommendation Framework for Mental Health
Jan 26, 2024The COVID-19 pandemic has intensified the urgency for effective and accessible mental health interventions in people's daily lives. Mobile Health (mHealth) solutions, such as AI Chatbots and Mindfulness Apps, have gained traction as they expand beyond traditional clinical settings to support daily life. However, the effectiveness of current mHealth solutions is impeded by the lack of context-awareness, personalization, and modularity to foster their reusability. This paper introduces CAREForMe, a contextual multi-armed bandit (CMAB) recommendation framework for mental health. Designed with context-awareness, personalization, and modularity at its core, CAREForMe harnesses mobile sensing and integrates online learning algorithms with user clustering capability to deliver timely, personalized recommendations. With its modular design, CAREForMe serves as both a customizable recommendation framework to guide future research, and a collaborative platform to facilitate interdisciplinary contributions in mHealth research. We showcase CAREForMe's versatility through its implementation across various platforms (e.g., Discord, Telegram) and its customization to diverse recommendation features.