 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Whose Side Are You On? Investigating the Political Stance of Large Language Models
Mar 15, 2024
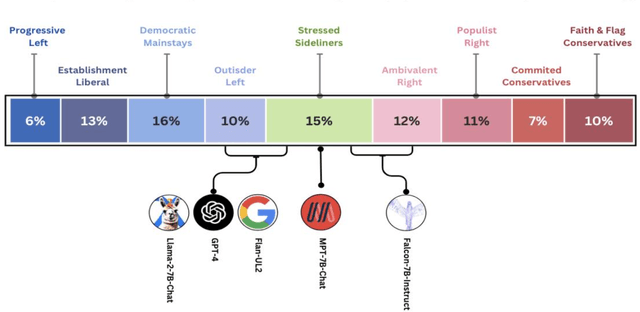
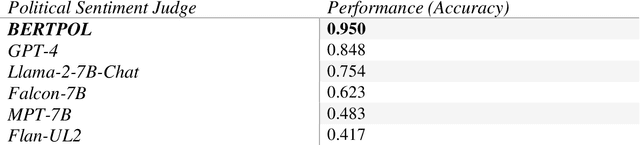
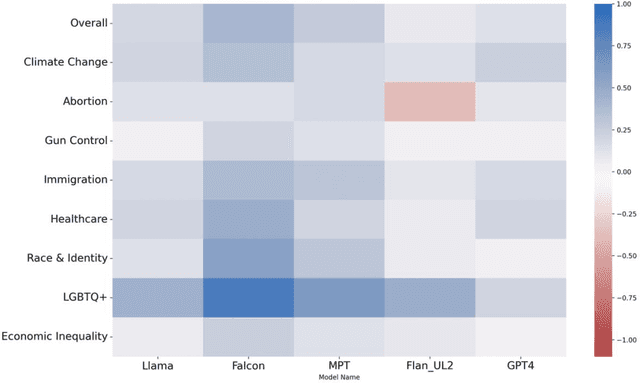

Large Language Models (LLMs) have gained significant popularity for their application in various everyday tasks such as text generation, summarization, and information retrieval. As the widespread adoption of LLMs continues to surge, it becomes increasingly crucial to ensure that these models yield responses that are politically impartial, with the aim of preventing information bubbles, upholding fairness in representation, and mitigating confirmation bias. In this paper, we propose a quantitative framework and pipeline designed to systematically investigate the political orientation of LLMs. Our investigation delves into the political alignment of LLMs across a spectrum of eight polarizing topics, spanning from abortion to LGBTQ issues. Across topics, the results indicate that LLMs exhibit a tendency to provide responses that closely align with liberal or left-leaning perspectives rather than conservative or right-leaning ones when user queries include details pertaining to occupation, race, or political affiliation. The findings presented in this study not only reaffirm earlier observations regarding the left-leaning characteristics of LLMs but also surface particular attributes, such as occupation, that are particularly susceptible to such inclinations even when directly steered towards conservatism. As a recommendation to avoid these models providing politicised responses, users should be mindful when crafting queries, and exercise caution in selecting neutral prompt language.
RA-Rec: An Efficient ID Representation Alignment Framework for LLM-based Recommendation
Feb 07, 2024Large language models (LLM) have recently emerged as a powerful tool for a variety of natural language processing tasks, bringing a new surge of combining LLM with recommendation systems, termed as LLM-based RS. Current approaches generally fall into two main paradigms, the ID direct usage paradigm and the ID translation paradigm, noting their core weakness stems from lacking recommendation knowledge and uniqueness. To address this limitation, we propose a new paradigm, ID representation, which incorporates pre-trained ID embeddings into LLMs in a complementary manner. In this work, we present RA-Rec, an efficient ID representation alignment framework for LLM-based recommendation, which is compatible with multiple ID-based methods and LLM architectures. Specifically, we treat ID embeddings as soft prompts and design an innovative alignment module and an efficient tuning method with tailored data construction for alignment. Extensive experiments demonstrate RA-Rec substantially outperforms current state-of-the-art methods, achieving up to 3.0% absolute HitRate@100 improvements while utilizing less than 10x training data.
Forward Learning of Graph Neural Networks
Mar 16, 2024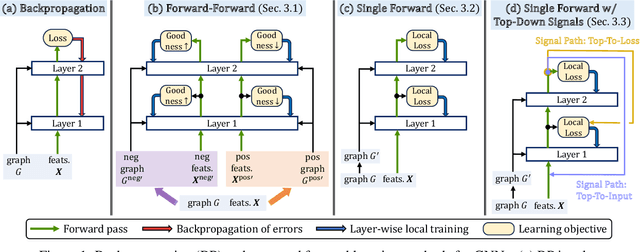
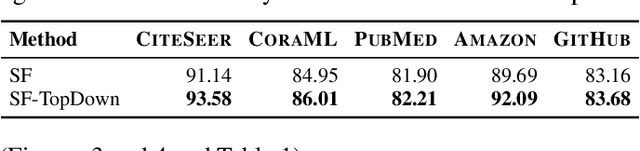
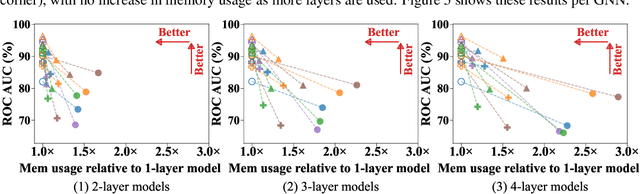
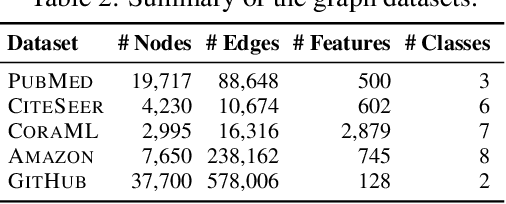
Graph neural networks (GNNs) have achieved remarkable success across a wide range of applications, such as recommendation, drug discovery, and question answering. Behind the success of GNNs lies the backpropagation (BP) algorithm, which is the de facto standard for training deep neural networks (NNs). However, despite its effectiveness, BP imposes several constraints, which are not only biologically implausible, but also limit the scalability, parallelism, and flexibility in learning NNs. Examples of such constraints include storage of neural activities computed in the forward pass for use in the subsequent backward pass, and the dependence of parameter updates on non-local signals. To address these limitations, the forward-forward algorithm (FF) was recently proposed as an alternative to BP in the image classification domain, which trains NNs by performing two forward passes over positive and negative data. Inspired by this advance, we propose ForwardGNN in this work, a new forward learning procedure for GNNs, which avoids the constraints imposed by BP via an effective layer-wise local forward training. ForwardGNN extends the original FF to deal with graph data and GNNs, and makes it possible to operate without generating negative inputs (hence no longer forward-forward). Further, ForwardGNN enables each layer to learn from both the bottom-up and top-down signals without relying on the backpropagation of errors. Extensive experiments on real-world datasets show the effectiveness and generality of the proposed forward graph learning framework. We release our code at https://github.com/facebookresearch/forwardgnn.
Large Language Model Distilling Medication Recommendation Model
Feb 05, 2024The recommendation of medication is a vital aspect of intelligent healthcare systems, as it involves prescribing the most suitable drugs based on a patient's specific health needs. Unfortunately, many sophisticated models currently in use tend to overlook the nuanced semantics of medical data, while only relying heavily on identities. Furthermore, these models face significant challenges in handling cases involving patients who are visiting the hospital for the first time, as they lack prior prescription histories to draw upon. To tackle these issues, we harness the powerful semantic comprehension and input-agnostic characteristics of Large Language Models (LLMs). Our research aims to transform existing medication recommendation methodologies using LLMs. In this paper, we introduce a novel approach called Large Language Model Distilling Medication Recommendation (LEADER). We begin by creating appropriate prompt templates that enable LLMs to suggest medications effectively. However, the straightforward integration of LLMs into recommender systems leads to an out-of-corpus issue specific to drugs. We handle it by adapting the LLMs with a novel output layer and a refined tuning loss function. Although LLM-based models exhibit remarkable capabilities, they are plagued by high computational costs during inference, which is impractical for the healthcare sector. To mitigate this, we have developed a feature-level knowledge distillation technique, which transfers the LLM's proficiency to a more compact model. Extensive experiments conducted on two real-world datasets, MIMIC-III and MIMIC-IV, demonstrate that our proposed model not only delivers effective results but also is efficient. To ease the reproducibility of our experiments, we release the implementation code online.
Dynamic Sparse Learning: A Novel Paradigm for Efficient Recommendation
Feb 05, 2024In the realm of deep learning-based recommendation systems, the increasing computational demands, driven by the growing number of users and items, pose a significant challenge to practical deployment. This challenge is primarily twofold: reducing the model size while effectively learning user and item representations for efficient recommendations. Despite considerable advancements in model compression and architecture search, prevalent approaches face notable constraints. These include substantial additional computational costs from pre-training/re-training in model compression and an extensive search space in architecture design. Additionally, managing complexity and adhering to memory constraints is problematic, especially in scenarios with strict time or space limitations. Addressing these issues, this paper introduces a novel learning paradigm, Dynamic Sparse Learning (DSL), tailored for recommendation models. DSL innovatively trains a lightweight sparse model from scratch, periodically evaluating and dynamically adjusting each weight's significance and the model's sparsity distribution during the training. This approach ensures a consistent and minimal parameter budget throughout the full learning lifecycle, paving the way for "end-to-end" efficiency from training to inference. Our extensive experimental results underline DSL's effectiveness, significantly reducing training and inference costs while delivering comparable recommendation performance.
Sequential Recommendation on Temporal Proximities with Contrastive Learning and Self-Attention
Feb 15, 2024Sequential recommender systems identify user preferences from their past interactions to predict subsequent items optimally. Although traditional deep-learning-based models and modern transformer-based models in previous studies capture unidirectional and bidirectional patterns within user-item interactions, the importance of temporal contexts, such as individual behavioral and societal trend patterns, remains underexplored. Notably, recent models often neglect similarities in users' actions that occur implicitly among users during analogous timeframes-a concept we term vertical temporal proximity. These models primarily adapt the self-attention mechanisms of the transformer to consider the temporal context in individual user actions. Meanwhile, this adaptation still remains limited in considering the horizontal temporal proximity within item interactions, like distinguishing between subsequent item purchases within a week versus a month. To address these gaps, we propose a sequential recommendation model called TemProxRec, which includes contrastive learning and self-attention methods to consider temporal proximities both across and within user-item interactions. The proposed contrastive learning method learns representations of items selected in close temporal periods across different users to be close. Simultaneously, the proposed self-attention mechanism encodes temporal and positional contexts in a user sequence using both absolute and relative embeddings. This way, our TemProxRec accurately predicts the relevant items based on the user-item interactions within a specific timeframe. We validate this work through comprehensive experiments on TemProxRec, consistently outperforming existing models on benchmark datasets as well as showing the significance of considering the vertical and horizontal temporal proximities into sequential recommendation.
PromptMM: Multi-Modal Knowledge Distillation for Recommendation with Prompt-Tuning
Mar 10, 2024Multimedia online platforms (e.g., Amazon, TikTok) have greatly benefited from the incorporation of multimedia (e.g., visual, textual, and acoustic) content into their personal recommender systems. These modalities provide intuitive semantics that facilitate modality-aware user preference modeling. However, two key challenges in multi-modal recommenders remain unresolved: i) The introduction of multi-modal encoders with a large number of additional parameters causes overfitting, given high-dimensional multi-modal features provided by extractors (e.g., ViT, BERT). ii) Side information inevitably introduces inaccuracies and redundancies, which skew the modality-interaction dependency from reflecting true user preference. To tackle these problems, we propose to simplify and empower recommenders through Multi-modal Knowledge Distillation (PromptMM) with the prompt-tuning that enables adaptive quality distillation. Specifically, PromptMM conducts model compression through distilling u-i edge relationship and multi-modal node content from cumbersome teachers to relieve students from the additional feature reduction parameters. To bridge the semantic gap between multi-modal context and collaborative signals for empowering the overfitting teacher, soft prompt-tuning is introduced to perform student task-adaptive. Additionally, to adjust the impact of inaccuracies in multimedia data, a disentangled multi-modal list-wise distillation is developed with modality-aware re-weighting mechanism. Experiments on real-world data demonstrate PromptMM's superiority over existing techniques. Ablation tests confirm the effectiveness of key components. Additional tests show the efficiency and effectiveness.
Retrieval Augmented Cross-Modal Tag Recommendation in Software Q&A Sites
Feb 06, 2024Posts in software Q\&A sites often consist of three main parts: title, description and code, which are interconnected and jointly describe the question. Existing tag recommendation methods often treat different modalities as a whole or inadequately consider the interaction between different modalities. Additionally, they focus on extracting information directly from the post itself, neglecting the information from external knowledge sources. Therefore, we propose a Retrieval Augmented Cross-Modal (RACM) Tag Recommendation Model in Software Q\&A Sites. Specifically, we first use the input post as a query and enhance the representation of different modalities by retrieving information from external knowledge sources. For the retrieval-augmented representations, we employ a cross-modal context-aware attention to leverage the main modality description for targeted feature extraction across the submodalities title and code. In the fusion process, a gate mechanism is employed to achieve fine-grained feature selection, controlling the amount of information extracted from the submodalities. Finally, the fused information is used for tag recommendation. Experimental results on three real-world datasets demonstrate that our model outperforms the state-of-the-art counterparts.
Data-efficient Fine-tuning for LLM-based Recommendation
Jan 30, 2024Leveraging Large Language Models (LLMs) for recommendation has recently garnered considerable attention, where fine-tuning plays a key role in LLMs' adaptation. However, the cost of fine-tuning LLMs on rapidly expanding recommendation data limits their practical application. To address this challenge, few-shot fine-tuning offers a promising approach to quickly adapt LLMs to new recommendation data. We propose the task of data pruning for efficient LLM-based recommendation, aimed at identifying representative samples tailored for LLMs' few-shot fine-tuning. While coreset selection is closely related to the proposed task, existing coreset selection methods often rely on suboptimal heuristic metrics or entail costly optimization on large-scale recommendation data. To tackle these issues, we introduce two objectives for the data pruning task in the context of LLM-based recommendation: 1) high accuracy aims to identify the influential samples that can lead to high overall performance; and 2) high efficiency underlines the low costs of the data pruning process. To pursue the two objectives, we propose a novel data pruning method based on two scores, i.e., influence score and effort score, to efficiently identify the influential samples. Particularly, the influence score is introduced to accurately estimate the influence of sample removal on the overall performance. To achieve low costs of the data pruning process, we use a small-sized surrogate model to replace LLMs to obtain the influence score. Considering the potential gap between the surrogate model and LLMs, we further propose an effort score to prioritize some hard samples specifically for LLMs. Empirical results on three real-world datasets validate the effectiveness of our proposed method. In particular, the proposed method uses only 2% samples to surpass the full data fine-tuning, reducing time costs by 97%.
Multi-Agent Collaboration Framework for Recommender Systems
Feb 23, 2024LLM-based agents have gained considerable attention for their decision-making skills and ability to handle complex tasks. Recognizing the current gap in leveraging agent capabilities for multi-agent collaboration in recommendation systems, we introduce MACRec, a novel framework designed to enhance recommendation systems through multi-agent collaboration. Unlike existing work on using agents for user/item simulation, we aim to deploy multi-agents to tackle recommendation tasks directly. In our framework, recommendation tasks are addressed through the collaborative efforts of various specialized agents, including Manager, User/Item Analyst, Reflector, Searcher, and Task Interpreter, with different working flows. Furthermore, we provide application examples of how developers can easily use MACRec on various recommendation tasks, including rating prediction, sequential recommendation, conversational recommendation, and explanation generation of recommendation results. The framework and demonstration video are publicly available at https://github.com/wzf2000/MACRec.