 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Doubly Calibrated Estimator for Recommendation on Data Missing Not At Random
Feb 26, 2024
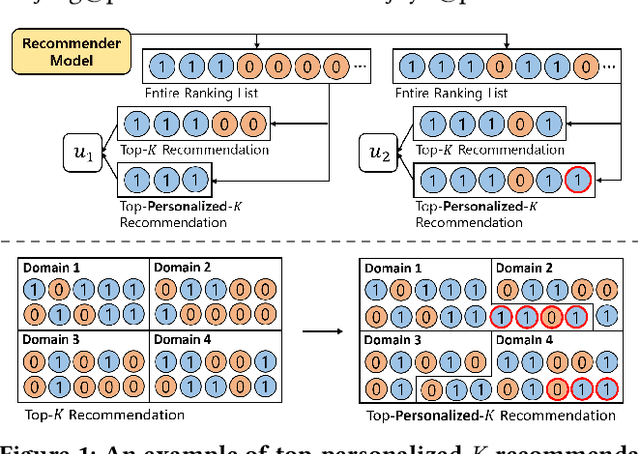
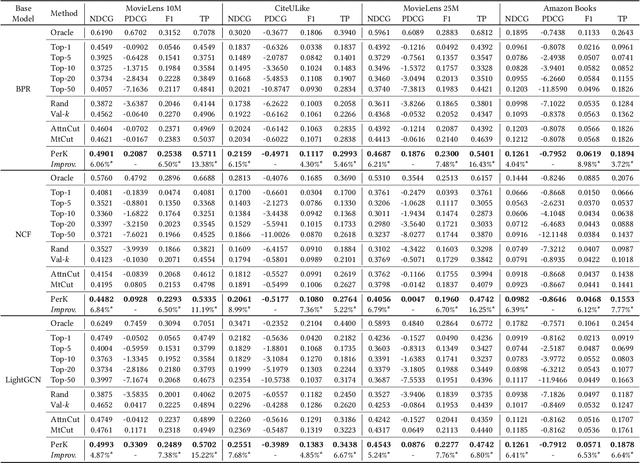
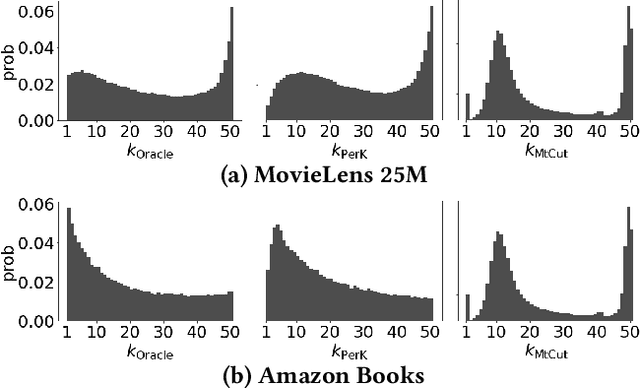
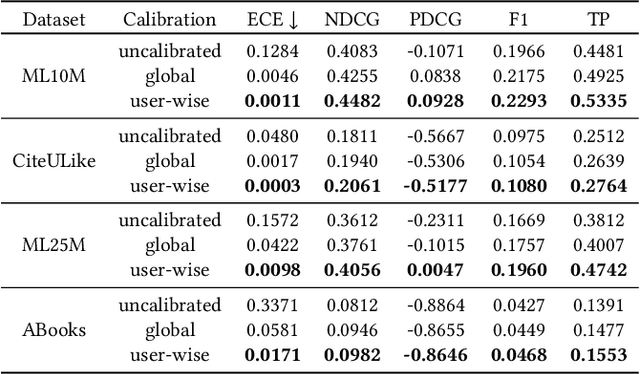
Recommender systems often suffer from selection bias as users tend to rate their preferred items. The datasets collected under such conditions exhibit entries missing not at random and thus are not randomized-controlled trials representing the target population. To address this challenge, a doubly robust estimator and its enhanced variants have been proposed as they ensure unbiasedness when accurate imputed errors or predicted propensities are provided. However, we argue that existing estimators rely on miscalibrated imputed errors and propensity scores as they depend on rudimentary models for estimation. We provide theoretical insights into how miscalibrated imputation and propensity models may limit the effectiveness of doubly robust estimators and validate our theorems using real-world datasets. On this basis, we propose a Doubly Calibrated Estimator that involves the calibration of both the imputation and propensity models. To achieve this, we introduce calibration experts that consider different logit distributions across users. Moreover, we devise a tri-level joint learning framework, allowing the simultaneous optimization of calibration experts alongside prediction and imputation models. Through extensive experiments on real-world datasets, we demonstrate the superiority of the Doubly Calibrated Estimator in the context of debiased recommendation tasks.
An Order-Complexity Aesthetic Assessment Model for Aesthetic-aware Music Recommendation
Feb 13, 2024Computational aesthetic evaluation has made remarkable contribution to visual art works, but its application to music is still rare. Currently, subjective evaluation is still the most effective form of evaluating artistic works. However, subjective evaluation of artistic works will consume a lot of human and material resources. The popular AI generated content (AIGC) tasks nowadays have flooded all industries, and music is no exception. While compared to music produced by humans, AI generated music still sounds mechanical, monotonous, and lacks aesthetic appeal. Due to the lack of music datasets with rating annotations, we have to choose traditional aesthetic equations to objectively measure the beauty of music. In order to improve the quality of AI music generation and further guide computer music production, synthesis, recommendation and other tasks, we use Birkhoff's aesthetic measure to design a aesthetic model, objectively measuring the aesthetic beauty of music, and form a recommendation list according to the aesthetic feeling of music. Experiments show that our objective aesthetic model and recommendation method are effective.
Disentangled Graph Variational Auto-Encoder for Multimodal Recommendation with Interpretability
Feb 25, 2024Multimodal recommender systems amalgamate multimodal information (e.g., textual descriptions, images) into a collaborative filtering framework to provide more accurate recommendations. While the incorporation of multimodal information could enhance the interpretability of these systems, current multimodal models represent users and items utilizing entangled numerical vectors, rendering them arduous to interpret. To address this, we propose a Disentangled Graph Variational Auto-Encoder (DGVAE) that aims to enhance both model and recommendation interpretability. DGVAE initially projects multimodal information into textual contents, such as converting images to text, by harnessing state-of-the-art multimodal pre-training technologies. It then constructs a frozen item-item graph and encodes the contents and interactions into two sets of disentangled representations utilizing a simplified residual graph convolutional network. DGVAE further regularizes these disentangled representations through mutual information maximization, aligning the representations derived from the interactions between users and items with those learned from textual content. This alignment facilitates the interpretation of user binary interactions via text. Our empirical analysis conducted on three real-world datasets demonstrates that DGVAE significantly surpasses the performance of state-of-the-art baselines by a margin of 10.02%. We also furnish a case study from a real-world dataset to illustrate the interpretability of DGVAE. Code is available at: \url{https://github.com/enoche/DGVAE}.
UMAIR-FPS: User-aware Multi-modal Animation Illustration Recommendation Fusion with Painting Style
Feb 16, 2024The rapid advancement of high-quality image generation models based on AI has generated a deluge of anime illustrations. Recommending illustrations to users within massive data has become a challenging and popular task. However, existing anime recommendation systems have focused on text features but still need to integrate image features. In addition, most multi-modal recommendation research is constrained by tightly coupled datasets, limiting its applicability to anime illustrations. We propose the User-aware Multi-modal Animation Illustration Recommendation Fusion with Painting Style (UMAIR-FPS) to tackle these gaps. In the feature extract phase, for image features, we are the first to combine image painting style features with semantic features to construct a dual-output image encoder for enhancing representation. For text features, we obtain text embeddings based on fine-tuning Sentence-Transformers by incorporating domain knowledge that composes a variety of domain text pairs from multilingual mappings, entity relationships, and term explanation perspectives, respectively. In the multi-modal fusion phase, we novelly propose a user-aware multi-modal contribution measurement mechanism to weight multi-modal features dynamically according to user features at the interaction level and employ the DCN-V2 module to model bounded-degree multi-modal crosses effectively. UMAIR-FPS surpasses the stat-of-the-art baselines on large real-world datasets, demonstrating substantial performance enhancements.
Non-autoregressive Generative Models for Reranking Recommendation
Feb 10, 2024In a multi-stage recommendation system, reranking plays a crucial role by modeling the intra-list correlations among items.The key challenge of reranking lies in the exploration of optimal sequences within the combinatorial space of permutations. Recent research proposes a generator-evaluator learning paradigm, where the generator generates multiple feasible sequences and the evaluator picks out the best sequence based on the estimated listwise score. Generator is of vital importance, and generative models are well-suited for the generator function. Current generative models employ an autoregressive strategy for sequence generation. However, deploying autoregressive models in real-time industrial systems is challenging. Hence, we propose a Non-AutoRegressive generative model for reranking Recommendation (NAR4Rec) designed to enhance efficiency and effectiveness. To address challenges related to sparse training samples and dynamic candidates impacting model convergence, we introduce a matching model. Considering the diverse nature of user feedback, we propose a sequence-level unlikelihood training objective to distinguish feasible from unfeasible sequences. Additionally, to overcome the lack of dependency modeling in non-autoregressive models regarding target items, we introduce contrastive decoding to capture correlations among these items. Extensive offline experiments on publicly available datasets validate the superior performance of our proposed approach compared to the existing state-of-the-art reranking methods. Furthermore, our method has been fully deployed in a popular video app Kuaishou with over 300 million daily active users, significantly enhancing online recommendation quality, and demonstrating the effectiveness and efficiency of our approach.
Pre-Trained Model Recommendation for Downstream Fine-tuning
Mar 11, 2024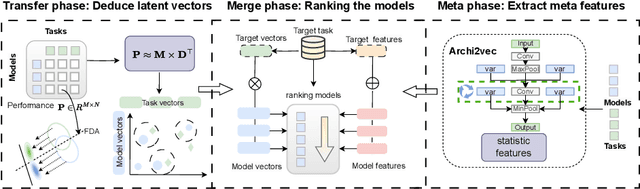
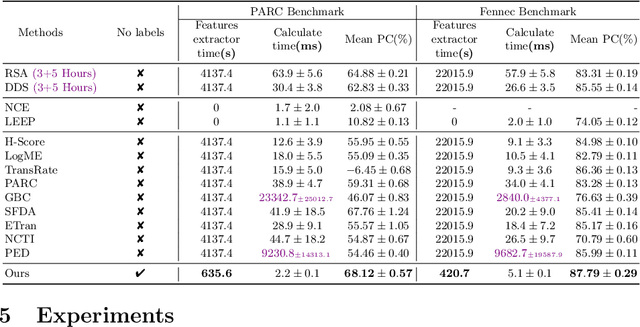
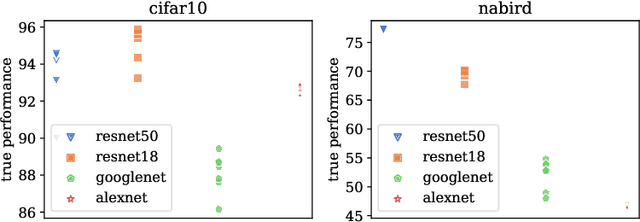
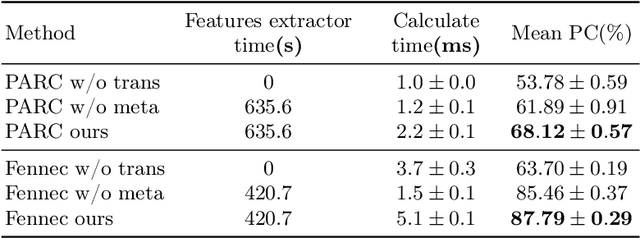
As a fundamental problem in transfer learning, model selection aims to rank off-the-shelf pre-trained models and select the most suitable one for the new target task. Existing model selection techniques are often constrained in their scope and tend to overlook the nuanced relationships between models and tasks. In this paper, we present a pragmatic framework \textbf{Fennec}, delving into a diverse, large-scale model repository while meticulously considering the intricate connections between tasks and models. The key insight is to map all models and historical tasks into a transfer-related subspace, where the distance between model vectors and task vectors represents the magnitude of transferability. A large vision model, as a proxy, infers a new task's representation in the transfer space, thereby circumventing the computational burden of extensive forward passes. We also investigate the impact of the inherent inductive bias of models on transfer results and propose a novel method called \textbf{archi2vec} to encode the intricate structures of models. The transfer score is computed through straightforward vector arithmetic with a time complexity of $\mathcal{O}(1)$. Finally, we make a substantial contribution to the field by releasing a comprehensive benchmark. We validate the effectiveness of our framework through rigorous testing on two benchmarks. The benchmark and the code will be publicly available in the near future.
Modeling Balanced Explicit and Implicit Relations with Contrastive Learning for Knowledge Concept Recommendation in MOOCs
Feb 13, 2024The knowledge concept recommendation in Massive Open Online Courses (MOOCs) is a significant issue that has garnered widespread attention. Existing methods primarily rely on the explicit relations between users and knowledge concepts on the MOOC platforms for recommendation. However, there are numerous implicit relations (e.g., shared interests or same knowledge levels between users) generated within the users' learning activities on the MOOC platforms. Existing methods fail to consider these implicit relations, and these relations themselves are difficult to learn and represent, causing poor performance in knowledge concept recommendation and an inability to meet users' personalized needs. To address this issue, we propose a novel framework based on contrastive learning, which can represent and balance the explicit and implicit relations for knowledge concept recommendation in MOOCs (CL-KCRec). Specifically, we first construct a MOOCs heterogeneous information network (HIN) by modeling the data from the MOOC platforms. Then, we utilize a relation-updated graph convolutional network and stacked multi-channel graph neural network to represent the explicit and implicit relations in the HIN, respectively. Considering that the quantity of explicit relations is relatively fewer compared to implicit relations in MOOCs, we propose a contrastive learning with prototypical graph to enhance the representations of both relations to capture their fruitful inherent relational knowledge, which can guide the propagation of students' preferences within the HIN. Based on these enhanced representations, to ensure the balanced contribution of both towards the final recommendation, we propose a dual-head attention mechanism for balanced fusion. Experimental results demonstrate that CL-KCRec outperforms several state-of-the-art baselines on real-world datasets in terms of HR, NDCG and MRR.
Sequential Recommendation on Temporal Proximities with Contrastive Learning and Self-Attention
Feb 18, 2024Sequential recommender systems identify user preferences from their past interactions to predict subsequent items optimally. Although traditional deep-learning-based models and modern transformer-based models in previous studies capture unidirectional and bidirectional patterns within user-item interactions, the importance of temporal contexts, such as individual behavioral and societal trend patterns, remains underexplored. Notably, recent models often neglect similarities in users' actions that occur implicitly among users during analogous timeframes-a concept we term vertical temporal proximity. These models primarily adapt the self-attention mechanisms of the transformer to consider the temporal context in individual user actions. Meanwhile, this adaptation still remains limited in considering the horizontal temporal proximity within item interactions, like distinguishing between subsequent item purchases within a week versus a month. To address these gaps, we propose a sequential recommendation model called TemProxRec, which includes contrastive learning and self-attention methods to consider temporal proximities both across and within user-item interactions. The proposed contrastive learning method learns representations of items selected in close temporal periods across different users to be close. Simultaneously, the proposed self-attention mechanism encodes temporal and positional contexts in a user sequence using both absolute and relative embeddings. This way, our TemProxRec accurately predicts the relevant items based on the user-item interactions within a specific timeframe. We validate this work through comprehensive experiments on TemProxRec, consistently outperforming existing models on benchmark datasets as well as showing the significance of considering the vertical and horizontal temporal proximities into sequential recommendation.
PAP-REC: Personalized Automatic Prompt for Recommendation Language Model
Feb 01, 2024Recently emerged prompt-based Recommendation Language Models (RLM) can solve multiple recommendation tasks uniformly. The RLMs make full use of the inherited knowledge learned from the abundant pre-training data to solve the downstream recommendation tasks by prompts, without introducing additional parameters or network training. However, handcrafted prompts require significant expertise and human effort since slightly rewriting prompts may cause massive performance changes. In this paper, we propose PAP-REC, a framework to generate the Personalized Automatic Prompt for RECommendation language models to mitigate the inefficiency and ineffectiveness problems derived from manually designed prompts. Specifically, personalized automatic prompts allow different users to have different prompt tokens for the same task, automatically generated using a gradient-based method. One challenge for personalized automatic prompt generation for recommendation language models is the extremely large search space, leading to a long convergence time. To effectively and efficiently address the problem, we develop surrogate metrics and leverage an alternative updating schedule for prompting recommendation language models. Experimental results show that our PAP-REC framework manages to generate personalized prompts, and the automatically generated prompts outperform manually constructed prompts and also outperform various baseline recommendation models. The source code of the work is available at https://github.com/rutgerswiselab/PAP-REC.
Discrete Semantic Tokenization for Deep CTR Prediction
Mar 13, 2024Incorporating item content information into click-through rate (CTR) prediction models remains a challenge, especially with the time and space constraints of industrial scenarios. The content-encoding paradigm, which integrates user and item encoders directly into CTR models, prioritizes space over time. In contrast, the embedding-based paradigm transforms item and user semantics into latent embeddings and then caches them, prioritizes space over time. In this paper, we introduce a new semantic-token paradigm and propose a discrete semantic tokenization approach, namely UIST, for user and item representation. UIST facilitates swift training and inference while maintaining a conservative memory footprint. Specifically, UIST quantizes dense embedding vectors into discrete tokens with shorter lengths and employs a hierarchical mixture inference module to weigh the contribution of each user--item token pair. Our experimental results on news recommendation showcase the effectiveness and efficiency (about 200-fold space compression) of UIST for CTR prediction.