 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Emerging Synergies Between Large Language Models and Machine Learning in Ecommerce Recommendations
Mar 12, 2024

With the boom of e-commerce and web applications, recommender systems have become an important part of our daily lives, providing personalized recommendations based on the user's preferences. Although deep neural networks (DNNs) have made significant progress in improving recommendation systems by simulating the interaction between users and items and incorporating their textual information, these DNN-based approaches still have some limitations, such as the difficulty of effectively understanding users' interests and capturing textual information. It is not possible to generalize to different seen/unseen recommendation scenarios and reason about their predictions. At the same time, the emergence of large language models (LLMs), represented by ChatGPT and GPT-4, has revolutionized the fields of natural language processing (NLP) and artificial intelligence (AI) due to their superior capabilities in the basic tasks of language understanding and generation, and their impressive generalization and reasoning capabilities. As a result, recent research has sought to harness the power of LLM to improve recommendation systems. Given the rapid development of this research direction in the field of recommendation systems, there is an urgent need for a systematic review of existing LLM-driven recommendation systems for researchers and practitioners in related fields to gain insight into. More specifically, we first introduced a representative approach to learning user and item representations using LLM as a feature encoder. We then reviewed the latest advances in LLMs techniques for collaborative filtering enhanced recommendation systems from the three paradigms of pre-training, fine-tuning, and prompting. Finally, we had a comprehensive discussion on the future direction of this emerging field.
An Aligning and Training Framework for Multimodal Recommendations
Mar 20, 2024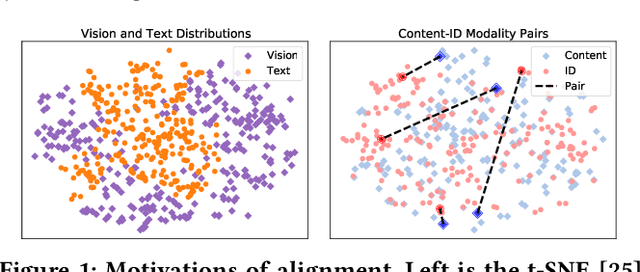
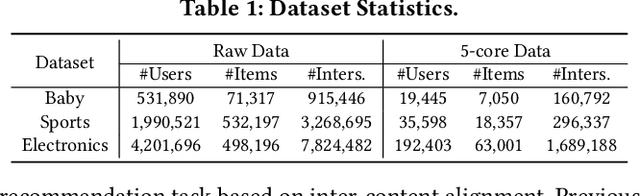
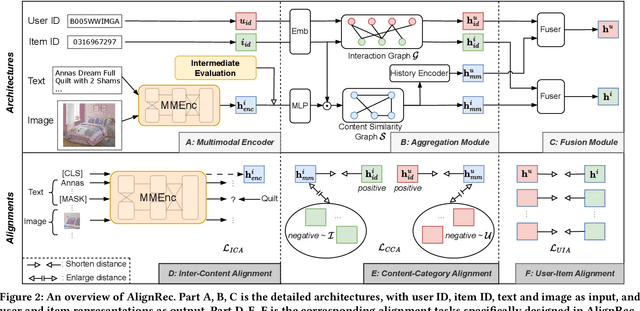
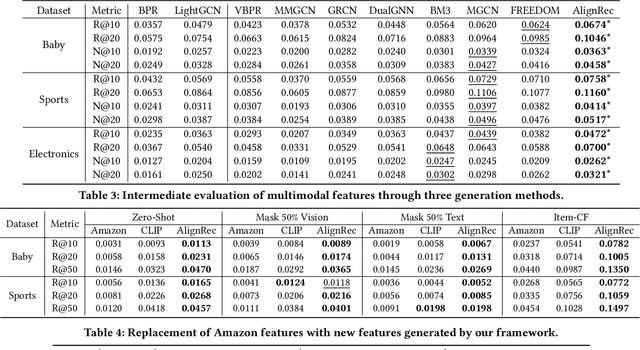
With the development of multimedia applications, multimodal recommendations are playing an essential role, as they can leverage rich contexts beyond user interactions. Existing methods mainly regard multimodal information as an auxiliary, using them to help learn ID features; however, there exist semantic gaps among multimodal content features and ID features, for which directly using multimodal information as an auxiliary would lead to misalignment in representations of users and items. In this paper, we first systematically investigate the misalignment issue in multimodal recommendations, and propose a solution named AlignRec. In AlignRec, the recommendation objective is decomposed into three alignments, namely alignment within contents, alignment between content and categorical ID, and alignment between users and items. Each alignment is characterized by a specific objective function and is integrated into our multimodal recommendation framework. To effectively train our AlignRec, we propose starting from pre-training the first alignment to obtain unified multimodal features and subsequently training the following two alignments together with these features as input. As it is essential to analyze whether each multimodal feature helps in training, we design three new classes of metrics to evaluate intermediate performance. Our extensive experiments on three real-world datasets consistently verify the superiority of AlignRec compared to nine baselines. We also find that the multimodal features generated by AlignRec are better than currently used ones, which are to be open-sourced.
Diffusion-based Negative Sampling on Graphs for Link Prediction
Mar 25, 2024Link prediction is a fundamental task for graph analysis with important applications on the Web, such as social network analysis and recommendation systems, etc. Modern graph link prediction methods often employ a contrastive approach to learn robust node representations, where negative sampling is pivotal. Typical negative sampling methods aim to retrieve hard examples based on either predefined heuristics or automatic adversarial approaches, which might be inflexible or difficult to control. Furthermore, in the context of link prediction, most previous methods sample negative nodes from existing substructures of the graph, missing out on potentially more optimal samples in the latent space. To address these issues, we investigate a novel strategy of multi-level negative sampling that enables negative node generation with flexible and controllable ``hardness'' levels from the latent space. Our method, called Conditional Diffusion-based Multi-level Negative Sampling (DMNS), leverages the Markov chain property of diffusion models to generate negative nodes in multiple levels of variable hardness and reconcile them for effective graph link prediction. We further demonstrate that DMNS follows the sub-linear positivity principle for robust negative sampling. Extensive experiments on several benchmark datasets demonstrate the effectiveness of DMNS.
Recommendation Algorithm Based on Recommendation Sessions
Feb 14, 2024The enormous development of the Internet, both in the geographical scale and in the area of using its possibilities in everyday life, determines the creation and collection of huge amounts of data. Due to the scale, it is not possible to analyse them using traditional methods, therefore it makes a necessary to use modern methods and techniques. Such methods are provided, among others, by the area of recommendations. The aim of this study is to present a new algorithm in the area of recommendation systems, the algorithm based on data from various sets of information, both static (categories of objects, features of objects) and dynamic (user behaviour).
* arXiv admin note: text overlap with arXiv:2402.08275
AFDGCF: Adaptive Feature De-correlation Graph Collaborative Filtering for Recommendations
Mar 26, 2024Collaborative filtering methods based on graph neural networks (GNNs) have witnessed significant success in recommender systems (RS), capitalizing on their ability to capture collaborative signals within intricate user-item relationships via message-passing mechanisms. However, these GNN-based RS inadvertently introduce excess linear correlation between user and item embeddings, contradicting the goal of providing personalized recommendations. While existing research predominantly ascribes this flaw to the over-smoothing problem, this paper underscores the critical, often overlooked role of the over-correlation issue in diminishing the effectiveness of GNN representations and subsequent recommendation performance. Up to now, the over-correlation issue remains unexplored in RS. Meanwhile, how to mitigate the impact of over-correlation while preserving collaborative filtering signals is a significant challenge. To this end, this paper aims to address the aforementioned gap by undertaking a comprehensive study of the over-correlation issue in graph collaborative filtering models. Firstly, we present empirical evidence to demonstrate the widespread prevalence of over-correlation in these models. Subsequently, we dive into a theoretical analysis which establishes a pivotal connection between the over-correlation and over-smoothing issues. Leveraging these insights, we introduce the Adaptive Feature De-correlation Graph Collaborative Filtering (AFDGCF) framework, which dynamically applies correlation penalties to the feature dimensions of the representation matrix, effectively alleviating both over-correlation and over-smoothing issues. The efficacy of the proposed framework is corroborated through extensive experiments conducted with four representative graph collaborative filtering models across four publicly available datasets.
Understanding the Ranking Loss for Recommendation with Sparse User Feedback
Mar 21, 2024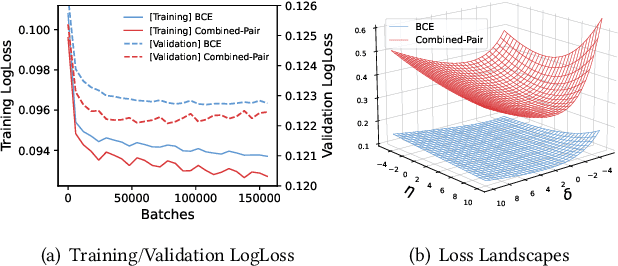
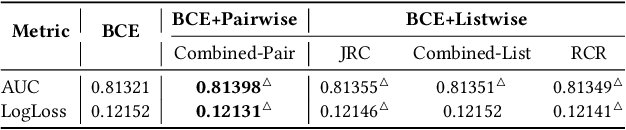
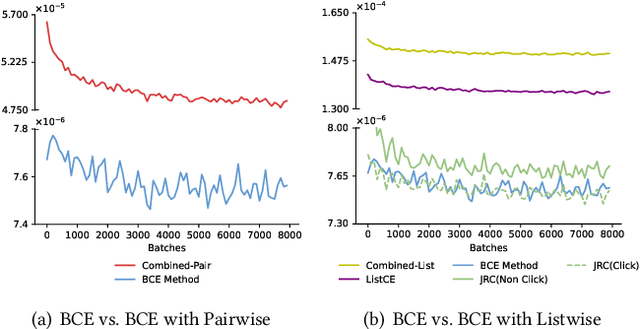

Click-through rate (CTR) prediction holds significant importance in the realm of online advertising. While many existing approaches treat it as a binary classification problem and utilize binary cross entropy (BCE) as the optimization objective, recent advancements have indicated that combining BCE loss with ranking loss yields substantial performance improvements. However, the full efficacy of this combination loss remains incompletely understood. In this paper, we uncover a new challenge associated with BCE loss in scenarios with sparse positive feedback, such as CTR prediction: the gradient vanishing for negative samples. Subsequently, we introduce a novel perspective on the effectiveness of ranking loss in CTR prediction, highlighting its ability to generate larger gradients on negative samples, thereby mitigating their optimization issues and resulting in improved classification ability. Our perspective is supported by extensive theoretical analysis and empirical evaluation conducted on publicly available datasets. Furthermore, we successfully deployed the ranking loss in Tencent's online advertising system, achieving notable lifts of 0.70% and 1.26% in Gross Merchandise Value (GMV) for two main scenarios. The code for our approach is openly accessible at the following GitHub repository: https://github.com/SkylerLinn/Understanding-the-Ranking-Loss.
Retention Induced Biases in a Recommendation System with Heterogeneous Users
Feb 21, 2024I examine a conceptual model of a recommendation system (RS) with user inflow and churn dynamics. When inflow and churn balance out, the user distribution reaches a steady state. Changing the recommendation algorithm alters the steady state and creates a transition period. During this period, the RS behaves differently from its new steady state. In particular, A/B experiment metrics obtained in transition periods are biased indicators of the RS's long term performance. Scholars and practitioners, however, often conduct A/B tests shortly after introducing new algorithms to validate their effectiveness. This A/B experiment paradigm, widely regarded as the gold standard for assessing RS improvements, may consequently yield false conclusions. I also briefly discuss the data bias caused by the user retention dynamics.
Ad Recommendation in a Collapsed and Entangled World
Feb 22, 2024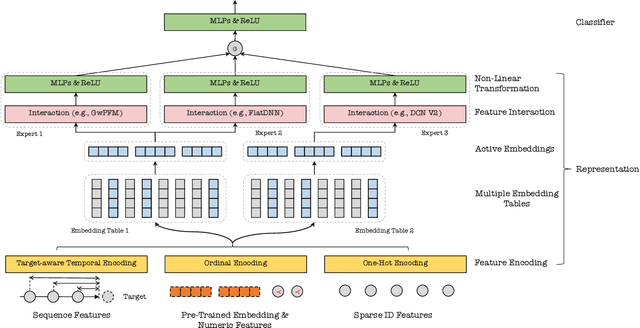
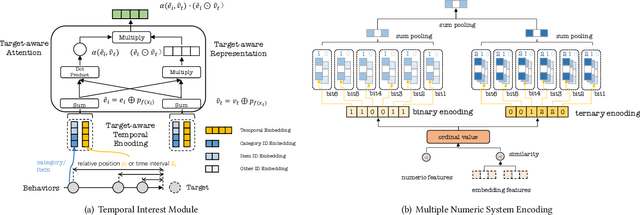
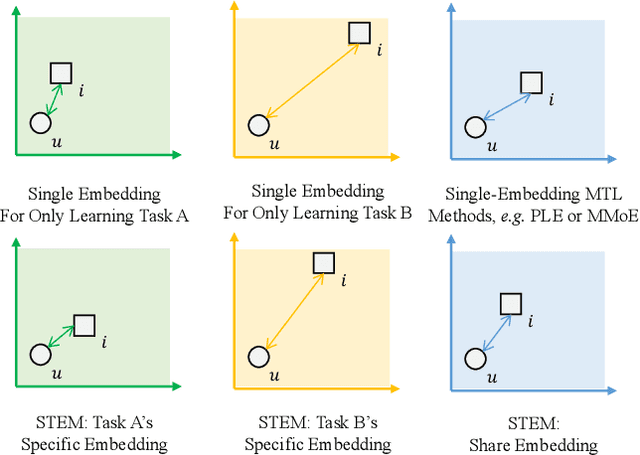
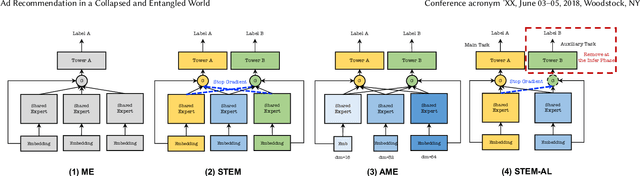
In this paper, we present an industry ad recommendation system, paying attention to the challenges and practices of learning appropriate representations. Our study begins by showcasing our approaches to preserving priors when encoding features of diverse types into embedding representations. Specifically, we address sequence features, numeric features, pre-trained embedding features, as well as sparse ID features. Moreover, we delve into two pivotal challenges associated with feature representation: the dimensional collapse of embeddings and the interest entanglement across various tasks or scenarios. Subsequently, we propose several practical approaches to effectively tackle these two challenges. We then explore several training techniques to facilitate model optimization, reduce bias, and enhance exploration. Furthermore, we introduce three analysis tools that enable us to comprehensively study feature correlation, dimensional collapse, and interest entanglement. This work builds upon the continuous efforts of Tencent's ads recommendation team in the last decade. It not only summarizes general design principles but also presents a series of off-the-shelf solutions and analysis tools. The reported performance is based on our online advertising platform, which handles hundreds of billions of requests daily, serving millions of ads to billions of users.
BMLP: Behavior-aware MLP for Heterogeneous Sequential Recommendation
Feb 20, 2024In real recommendation scenarios, users often have different types of behaviors, such as clicking and buying. Existing research methods show that it is possible to capture the heterogeneous interests of users through different types of behaviors. However, most multi-behavior approaches have limitations in learning the relationship between different behaviors. In this paper, we propose a novel multilayer perceptron (MLP)-based heterogeneous sequential recommendation method, namely behavior-aware multilayer perceptron (BMLP). Specifically, it has two main modules, including a heterogeneous interest perception (HIP) module, which models behaviors at multiple granularities through behavior types and transition relationships, and a purchase intent perception (PIP) module, which adaptively fuses subsequences of auxiliary behaviors to capture users' purchase intent. Compared with mainstream sequence models, MLP is competitive in terms of accuracy and has unique advantages in simplicity and efficiency. Extensive experiments show that BMLP achieves significant improvement over state-of-the-art algorithms on four public datasets. In addition, its pure MLP architecture leads to a linear time complexity.
Debiasing Recommendation with Personal Popularity
Feb 12, 2024Global popularity (GP) bias is the phenomenon that popular items are recommended much more frequently than they should be, which goes against the goal of providing personalized recommendations and harms user experience and recommendation accuracy. Many methods have been proposed to reduce GP bias but they fail to notice the fundamental problem of GP, i.e., it considers popularity from a \textit{global} perspective of \textit{all users} and uses a single set of popular items, and thus cannot capture the interests of individual users. As such, we propose a user-aware version of item popularity named \textit{personal popularity} (PP), which identifies different popular items for each user by considering the users that share similar interests. As PP models the preferences of individual users, it naturally helps to produce personalized recommendations and mitigate GP bias. To integrate PP into recommendation, we design a general \textit{personal popularity aware counterfactual} (PPAC) framework, which adapts easily to existing recommendation models. In particular, PPAC recognizes that PP and GP have both direct and indirect effects on recommendations and controls direct effects with counterfactual inference techniques for unbiased recommendations. All codes and datasets are available at \url{https://github.com/Stevenn9981/PPAC}.