 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Optimizing Long-term Social Welfare in Recommender Systems: A Constrained Matching Approach
Jul 31, 2020
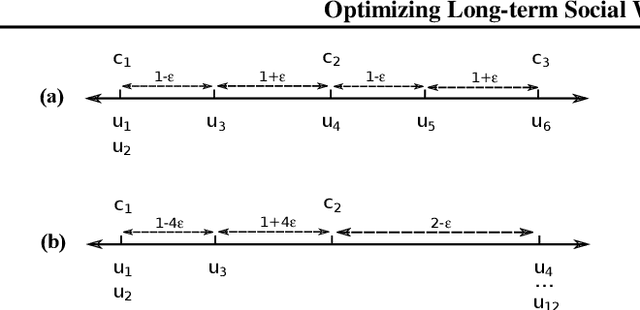
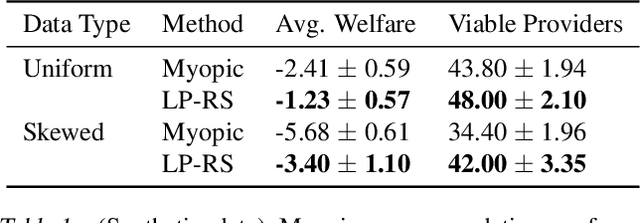
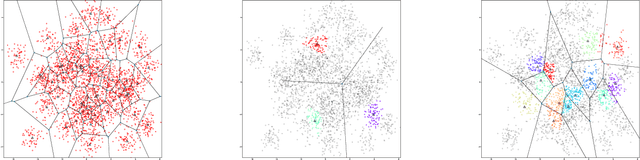
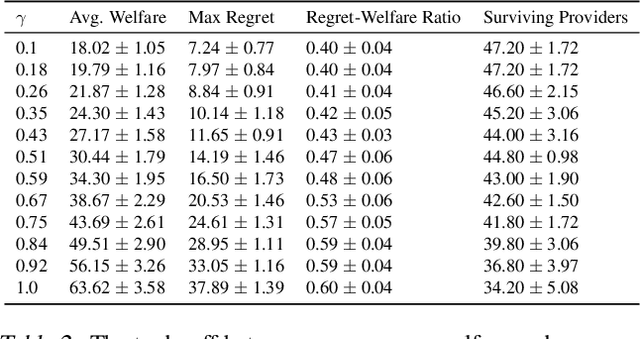
Most recommender systems (RS) research assumes that a user's utility can be maximized independently of the utility of the other agents (e.g., other users, content providers). In realistic settings, this is often not true---the dynamics of an RS ecosystem couple the long-term utility of all agents. In this work, we explore settings in which content providers cannot remain viable unless they receive a certain level of user engagement. We formulate the recommendation problem in this setting as one of equilibrium selection in the induced dynamical system, and show that it can be solved as an optimal constrained matching problem. Our model ensures the system reaches an equilibrium with maximal social welfare supported by a sufficiently diverse set of viable providers. We demonstrate that even in a simple, stylized dynamical RS model, the standard myopic approach to recommendation---always matching a user to the best provider---performs poorly. We develop several scalable techniques to solve the matching problem, and also draw connections to various notions of user regret and fairness, arguing that these outcomes are fairer in a utilitarian sense.
Data-driven model for hydraulic fracturing design optimization. Part II: Inverse problem
Aug 02, 2021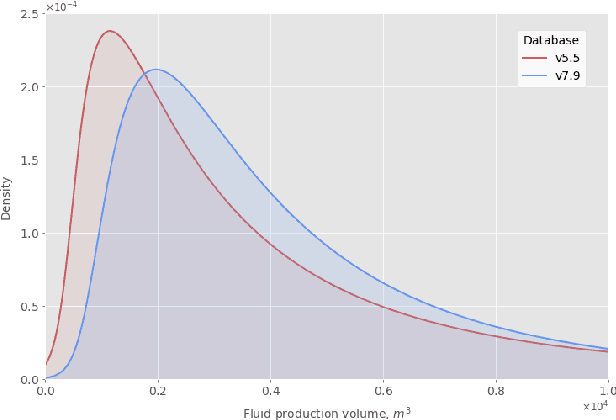
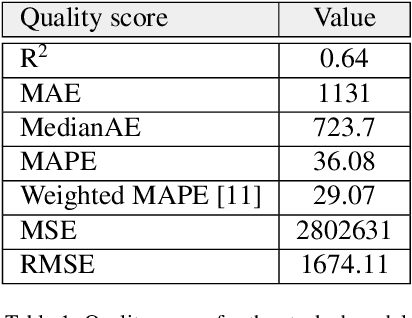
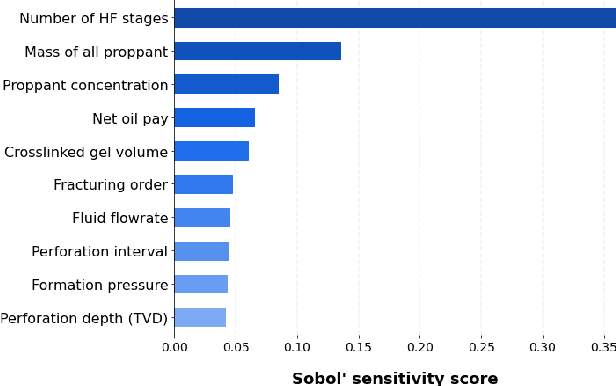
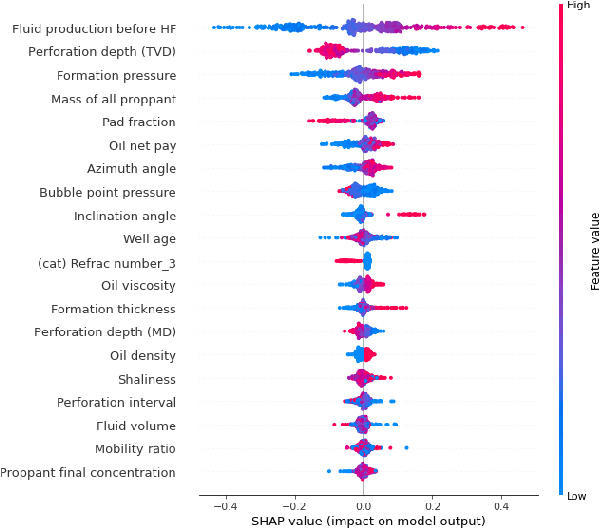
We describe a stacked model for predicting the cumulative fluid production for an oil well with a multistage-fracture completion based on a combination of Ridge Regression and CatBoost algorithms. The model is developed based on an extended digital field data base of reservoir, well and fracturing design parameters. The database now includes more than 5000 wells from 23 oilfields of Western Siberia (Russia), with 6687 fracturing operations in total. Starting with 387 parameters characterizing each well, including construction, reservoir properties, fracturing design features and production, we end up with 38 key parameters used as input features for each well in the model training process. The model demonstrates physically explainable dependencies plots of the target on the design parameters (number of stages, proppant mass, average and final proppant concentrations and fluid rate). We developed a set of methods including those based on the use of Euclidean distance and clustering techniques to perform similar (offset) wells search, which is useful for a field engineer to analyze earlier fracturing treatments on similar wells. These approaches are also adapted for obtaining the optimization parameters boundaries for the particular pilot well, as part of the field testing campaign of the methodology. An inverse problem (selecting an optimum set of fracturing design parameters to maximize production) is formulated as optimizing a high dimensional black box approximation function constrained by boundaries and solved with four different optimization methods: surrogate-based optimization, sequential least squares programming, particle swarm optimization and differential evolution. A recommendation system containing all the above methods is designed to advise a production stimulation engineer on an optimized fracturing design.
LinkTeller: Recovering Private Edges from Graph Neural Networks via Influence Analysis
Aug 14, 2021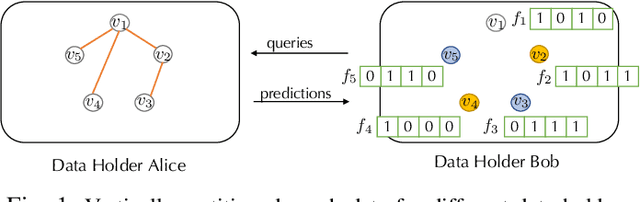
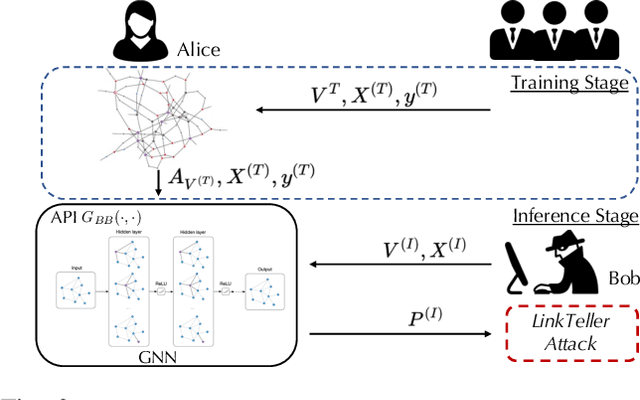
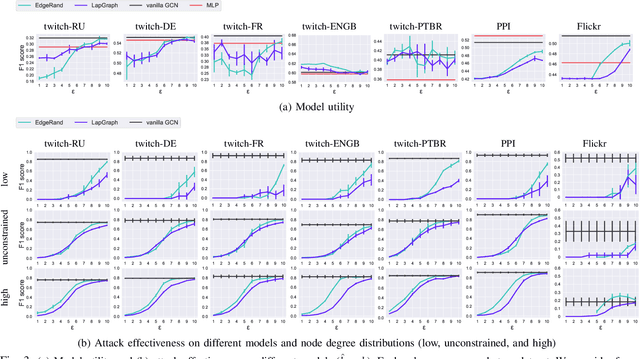
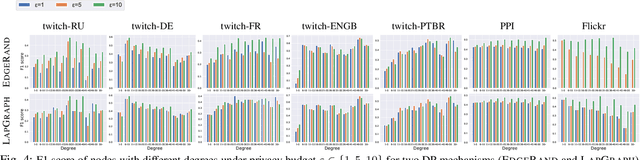
Graph structured data have enabled several successful applications such as recommendation systems and traffic prediction, given the rich node features and edges information. However, these high-dimensional features and high-order adjacency information are usually heterogeneous and held by different data holders in practice. Given such vertical data partition (e.g., one data holder will only own either the node features or edge information), different data holders have to develop efficient joint training protocols rather than directly transfer data to each other due to privacy concerns. In this paper, we focus on the edge privacy, and consider a training scenario where Bob with node features will first send training node features to Alice who owns the adjacency information. Alice will then train a graph neural network (GNN) with the joint information and release an inference API. During inference, Bob is able to provide test node features and query the API to obtain the predictions for test nodes. Under this setting, we first propose a privacy attack LinkTeller via influence analysis to infer the private edge information held by Alice via designing adversarial queries for Bob. We then empirically show that LinkTeller is able to recover a significant amount of private edges, outperforming existing baselines. To further evaluate the privacy leakage, we adapt an existing algorithm for differentially private graph convolutional network (DP GCN) training and propose a new DP GCN mechanism LapGraph. We show that these DP GCN mechanisms are not always resilient against LinkTeller empirically under mild privacy guarantees ($\varepsilon>5$). Our studies will shed light on future research towards designing more resilient privacy-preserving GCN models; in the meantime, provide an in-depth understanding of the tradeoff between GCN model utility and robustness against potential privacy attacks.
Clustering Introductory Computer Science Exercises Using Topic Modeling Methods
Apr 21, 2021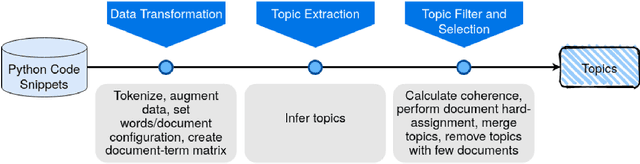
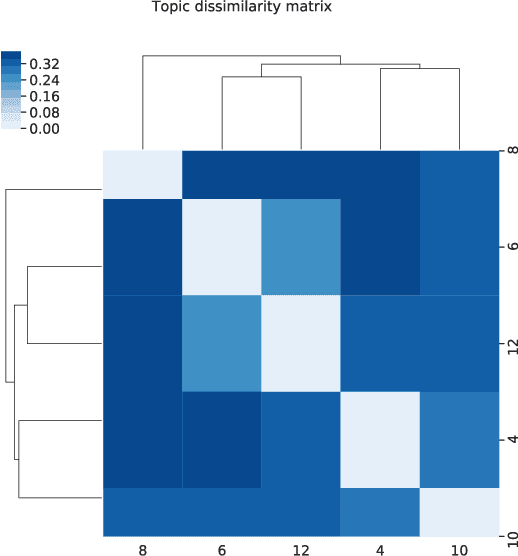
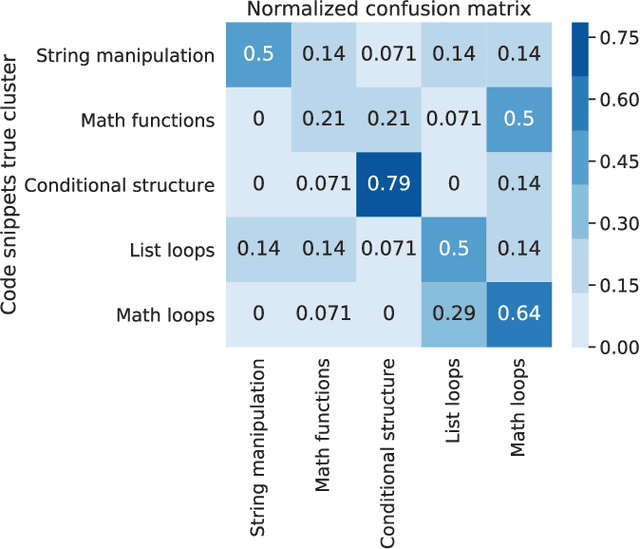

Manually determining concepts present in a group of questions is a challenging and time-consuming process. However, the process is an essential step while modeling a virtual learning environment since a mapping between concepts and questions using mastery level assessment and recommendation engines are required. We investigated unsupervised semantic models (known as topic modeling techniques) to assist computer science teachers in this task and propose a method to transform Computer Science 1 teacher-provided code solutions into representative text documents, including the code structure information. By applying non-negative matrix factorization and latent Dirichlet allocation techniques, we extract the underlying relationship between questions and validate the results using an external dataset. We consider the interpretability of the learned concepts using 14 university professors' data, and the results confirm six semantically coherent clusters using the current dataset. Moreover, the six topics comprise the main concepts present in the test dataset, achieving 0.75 in the normalized pointwise mutual information metric. The metric correlates with human ratings, making the proposed method useful and providing semantics for large amounts of unannotated code.
* 13 pages, 11 figures, published in IEEE Transactions on Learning Technologies
SciRecSys: A Recommendation System for Scientific Publication by Discovering Keyword Relationships
Feb 27, 2015



In this work, we propose a new approach for discovering various relationships among keywords over the scientific publications based on a Markov Chain model. It is an important problem since keywords are the basic elements for representing abstract objects such as documents, user profiles, topics and many things else. Our model is very effective since it combines four important factors in scientific publications: content, publicity, impact and randomness. Particularly, a recommendation system (called SciRecSys) has been presented to support users to efficiently find out relevant articles.
Learning to Recommend Signal Plans under Incidents with Real-Time Traffic Prediction
May 21, 2020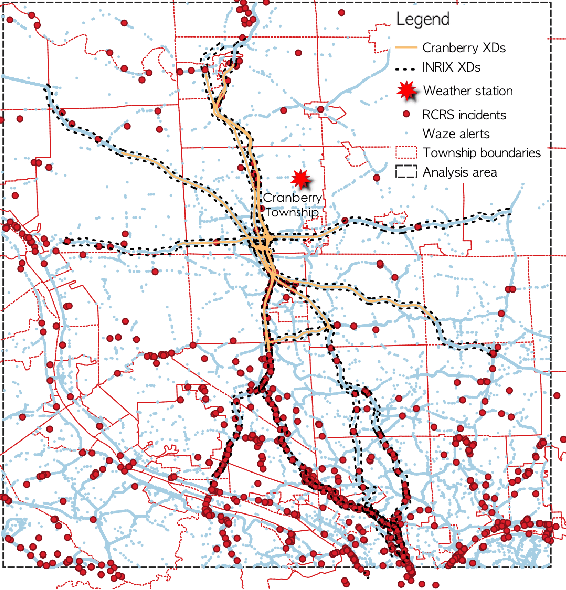
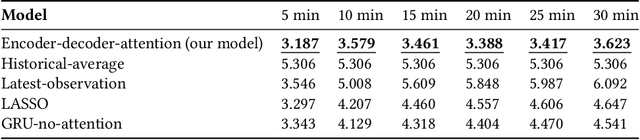
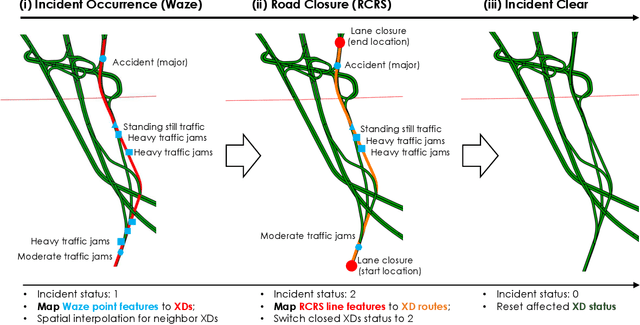
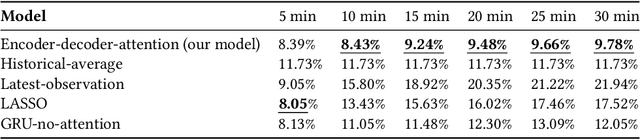
The main question to address in this paper is to recommend optimal signal timing plans in real time under incidents by incorporating domain knowledge developed with the traffic signal timing plans tuned for possible incidents, and learning from historical data of both traffic and implemented signals timing. The effectiveness of traffic incident management is often limited by the late response time and excessive workload of traffic operators. This paper proposes a novel decision-making framework that learns from both data and domain knowledge to real-time recommend contingency signal plans that accommodate non-recurrent traffic, with the outputs from real-time traffic prediction at least 30 minutes in advance. Specifically, considering the rare occurrences of engagement of contingency signal plans for incidents, we propose to decompose the end-to-end recommendation task into two hierarchical models: real-time traffic prediction and plan association. We learn the connections between the two models through metric learning, which reinforces partial-order preferences observed from historical signal engagement records. We demonstrate the effectiveness of our approach by testing this framework on the traffic network in Cranberry Township in 2019. Results show that our recommendation system has a precision score of 96.75% and recall of 87.5% on the testing plan, and make recommendation of an average of 22.5 minutes lead time ahead of Waze alerts. The results suggest that our framework is capable of giving traffic operators a significant time window to access the conditions and respond appropriately.
Subgraph nomination: Query by Example Subgraph Retrieval in Networks
Jan 29, 2021
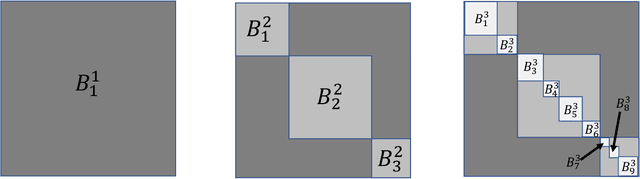
This paper introduces the subgraph nomination inference task, in which example subgraphs of interest are used to query a network for similarly interesting subgraphs. This type of problem appears time and again in real world problems connected to, for example, user recommendation systems and structural retrieval tasks in social and biological/connectomic networks. We formally define the subgraph nomination framework with an emphasis on the notion of a user-in-the-loop in the subgraph nomination pipeline. In this setting, a user can provide additional post-nomination light supervision that can be incorporated into the retrieval task. After introducing and formalizing the retrieval task, we examine the nuanced effect that user-supervision can have on performance, both analytically and across real and simulated data examples.
Unsupervised Path Representation Learning with Curriculum Negative Sampling
Jun 17, 2021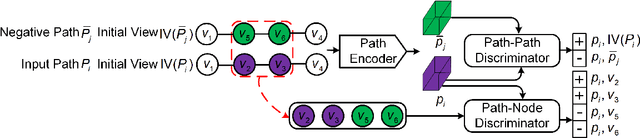
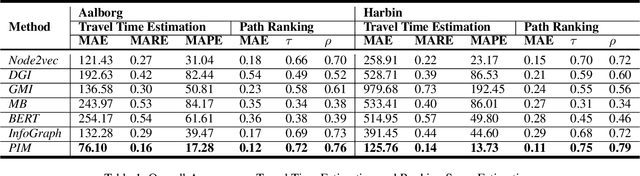
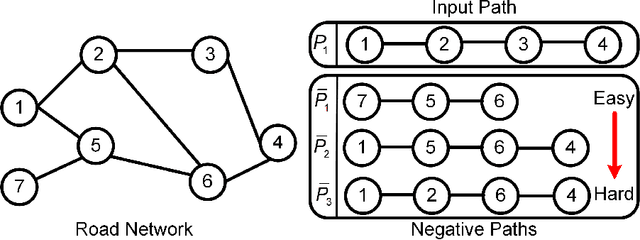
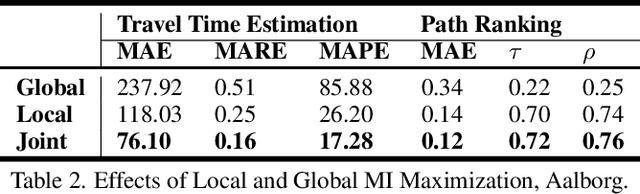
Path representations are critical in a variety of transportation applications, such as estimating path ranking in path recommendation systems and estimating path travel time in navigation systems. Existing studies often learn task-specific path representations in a supervised manner, which require a large amount of labeled training data and generalize poorly to other tasks. We propose an unsupervised learning framework Path InfoMax (PIM) to learn generic path representations that work for different downstream tasks. We first propose a curriculum negative sampling method, for each input path, to generate a small amount of negative paths, by following the principles of curriculum learning. Next, \emph{PIM} employs mutual information maximization to learn path representations from both a global and a local view. In the global view, PIM distinguishes the representations of the input paths from those of the negative paths. In the local view, \emph{PIM} distinguishes the input path representations from the representations of the nodes that appear only in the negative paths. This enables the learned path representations to encode both global and local information at different scales. Extensive experiments on two downstream tasks, ranking score estimation and travel time estimation, using two road network datasets suggest that PIM significantly outperforms other unsupervised methods and is also able to be used as a pre-training method to enhance supervised path representation learning.
An Empirical Analysis on Transparent Algorithmic Exploration in Recommender Systems
Aug 12, 2021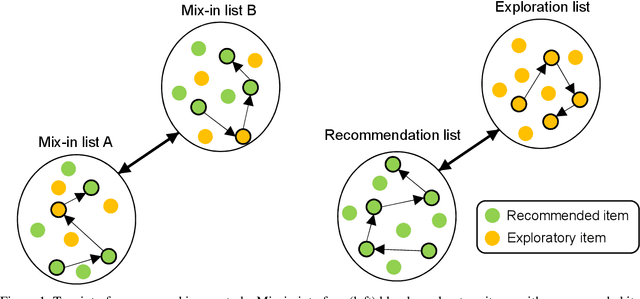

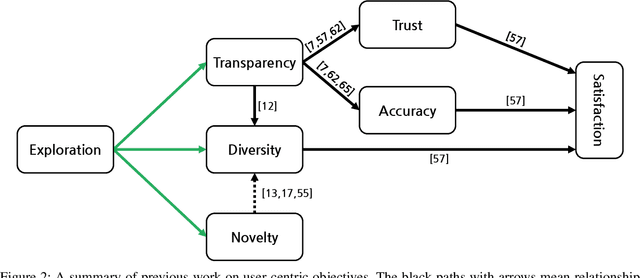
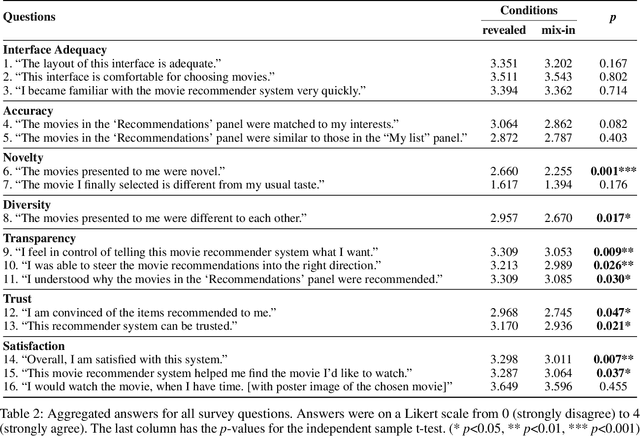
All learning algorithms for recommendations face inevitable and critical trade-off between exploiting partial knowledge of a user's preferences for short-term satisfaction and exploring additional user preferences for long-term coverage. Although exploration is indispensable for long success of a recommender system, the exploration has been considered as the risk to decrease user satisfaction. The reason for the risk is that items chosen for exploration frequently mismatch with the user's interests. To mitigate this risk, recommender systems have mixed items chosen for exploration into a recommendation list, disguising the items as recommendations to elicit feedback on the items to discover the user's additional tastes. This mix-in approach has been widely used in many recommenders, but there is rare research, evaluating the effectiveness of the mix-in approach or proposing a new approach for eliciting user feedback without deceiving users. In this work, we aim to propose a new approach for feedback elicitation without any deception and compare our approach to the conventional mix-in approach for evaluation. To this end, we designed a recommender interface that reveals which items are for exploration and conducted a within-subject study with 94 MTurk workers. Our results indicated that users left significantly more feedback on items chosen for exploration with our interface. Besides, users evaluated that our new interface is better than the conventional mix-in interface in terms of novelty, diversity, transparency, trust, and satisfaction. Finally, path analysis show that, in only our new interface, exploration caused to increase user-centric evaluation metrics. Our work paves the way for how to design an interface, which utilizes learning algorithm based on users' feedback signals, giving better user experience and gathering more feedback data.
Latent Unexpected Recommendations
Jul 27, 2020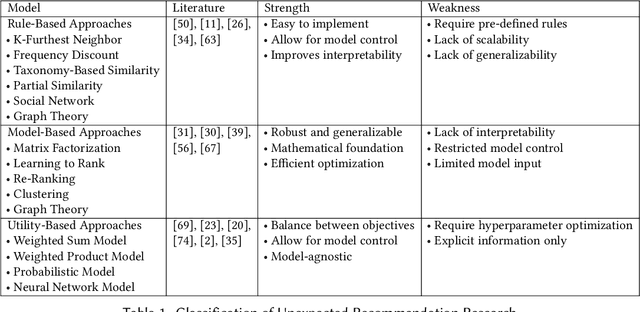
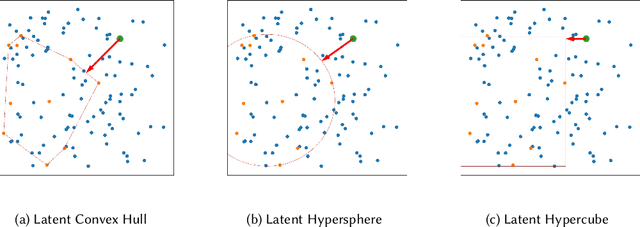
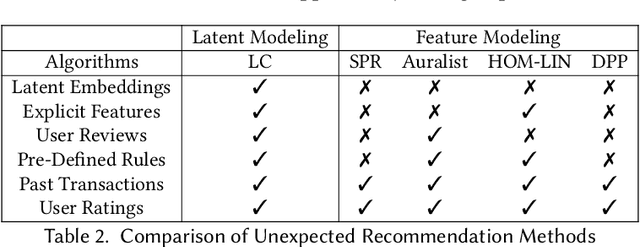
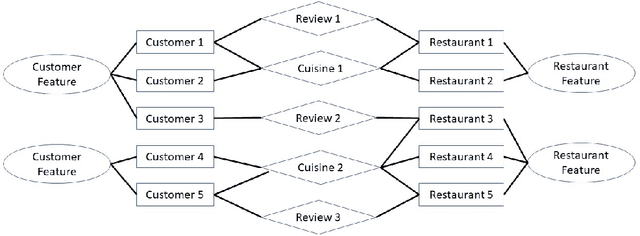
Unexpected recommender system constitutes an important tool to tackle the problem of filter bubbles and user boredom, which aims at providing unexpected and satisfying recommendations to target users at the same time. Previous unexpected recommendation methods only focus on the straightforward relations between current recommendations and user expectations by modeling unexpectedness in the feature space, thus resulting in the loss of accuracy measures in order to improve unexpectedness performance. Contrast to these prior models, we propose to model unexpectedness in the latent space of user and item embeddings, which allows to capture hidden and complex relations between new recommendations and historic purchases. In addition, we develop a novel Latent Closure (LC) method to construct hybrid utility function and provide unexpected recommendations based on the proposed model. Extensive experiments on three real-world datasets illustrate superiority of our proposed approach over the state-of-the-art unexpected recommendation models, which leads to significant increase in unexpectedness measure without sacrificing any accuracy metric under all experimental settings in this paper.