 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Web based disease prediction and recommender system
Jun 05, 2021
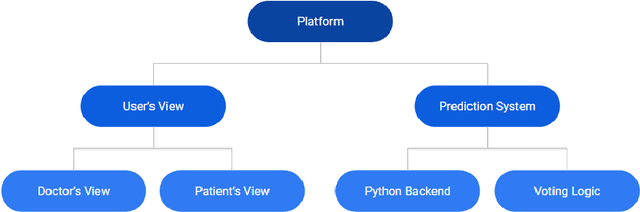
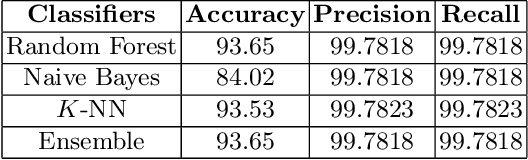
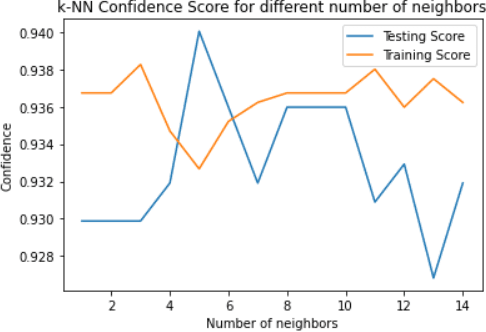
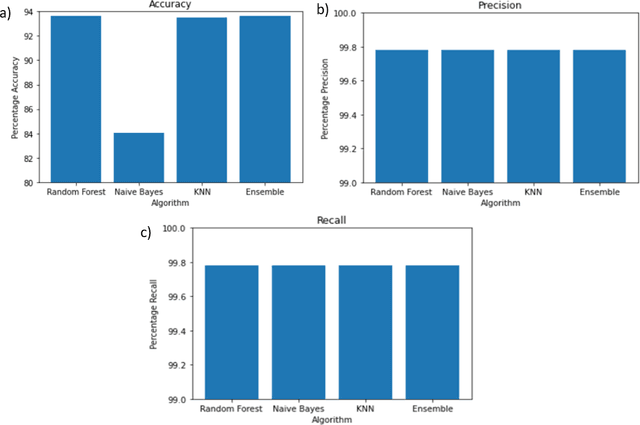
Worldwide, several cases go undiagnosed due to poor healthcare support in remote areas. In this context, a centralized system is needed for effective monitoring and analysis of the medical records. A web-based patient diagnostic system is a central platform to store the medical history and predict the possible disease based on the current symptoms experienced by a patient to ensure faster and accurate diagnosis. Early disease prediction can help the users determine the severity of the disease and take quick action. The proposed web-based disease prediction system utilizes machine learning based classification techniques on a data set acquired from the National Centre of Disease Control (NCDC). $K$-nearest neighbor (K-NN), random forest and naive bayes classification approaches are utilized and an ensemble voting algorithm is also proposed where each classifier is assigned weights dynamically based on the prediction confidence. The proposed system is also equipped with a recommendation scheme to recommend the type of tests based on the existing symptoms of the patient, so that necessary precautions can be taken. A centralized database ensures that the medical data is preserved and there is transparency in the system. The tampering into the system is prevented by giving the no "updation" rights once the diagnosis is created.
Robust Multi-Agent Multi-Armed Bandits
Jul 07, 2020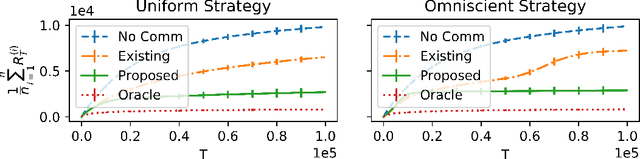
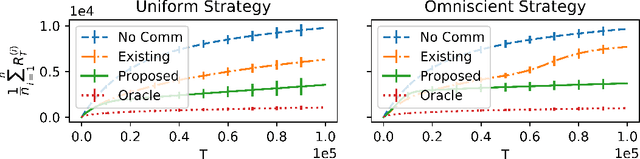
There has been recent interest in collaborative multi-agent bandits, where groups of agents share recommendations to decrease per-agent regret. However, these works assume that each agent always recommends their individual best-arm estimates to other agents, which is unrealistic in envisioned applications (machine faults in distributed computing or spam in social recommendation systems). Hence, we generalize the setting to include honest and malicious agents who recommend best-arm estimates and arbitrary arms, respectively. We show that even with a single malicious agent, existing collaboration-based algorithms fail to improve regret guarantees over a single-agent baseline. We propose a scheme where honest agents learn who is malicious and dynamically reduce communication with them, i.e., "blacklist" them. We show that collaboration indeed decreases regret for this algorithm, when the number of malicious agents is small compared to the number of arms, and crucially without assumptions on the malicious agents' behavior. Thus, our algorithm is robust against any malicious recommendation strategy.
Multiview Variational Graph Autoencoders for Canonical Correlation Analysis
Oct 30, 2020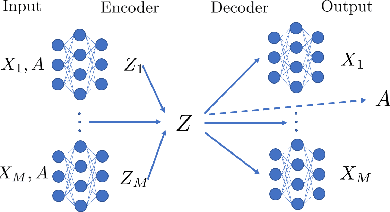
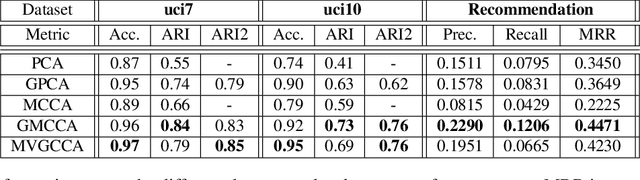
We present a novel multiview canonical correlation analysis model based on a variational approach. This is the first nonlinear model that takes into account the available graph-based geometric constraints while being scalable for processing large scale datasets with multiple views. It is based on an autoencoder architecture with graph convolutional neural network layers. We experiment with our approach on classification, clustering, and recommendation tasks on real datasets. The algorithm is competitive with state-of-the-art multiview representation learning techniques.
Optimisation using Natural Language Processing: Personalized Tour Recommendation for Museums
Jan 06, 2015
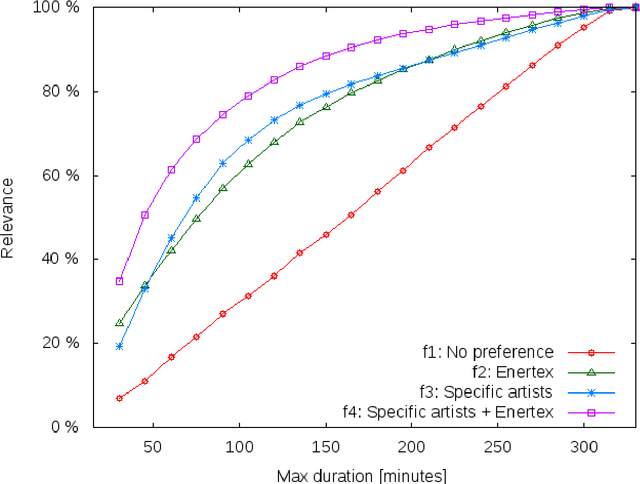
This paper proposes a new method to provide personalized tour recommendation for museum visits. It combines an optimization of preference criteria of visitors with an automatic extraction of artwork importance from museum information based on Natural Language Processing using textual energy. This project includes researchers from computer and social sciences. Some results are obtained with numerical experiments. They show that our model clearly improves the satisfaction of the visitor who follows the proposed tour. This work foreshadows some interesting outcomes and applications about on-demand personalized visit of museums in a very near future.
Data-driven model for hydraulic fracturing design optimization. Part II: Inverse problem
Aug 02, 2021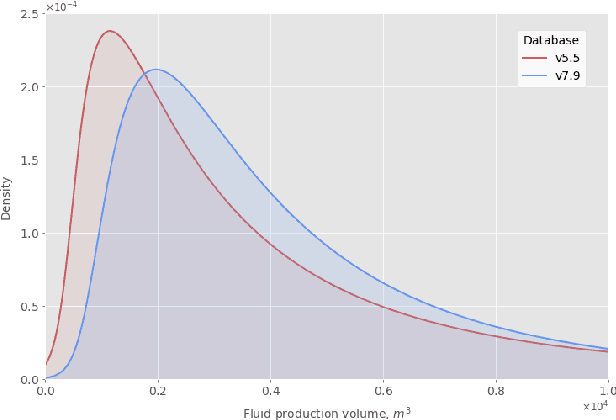
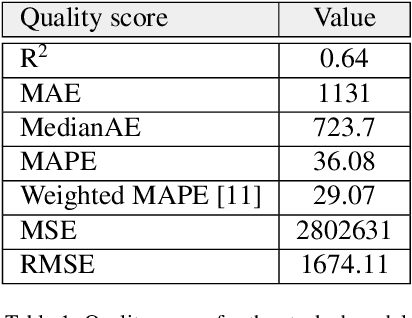
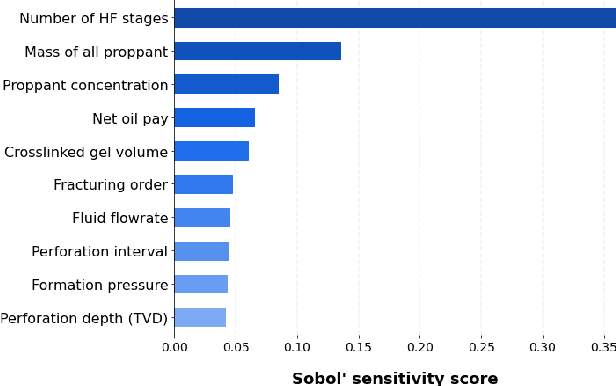
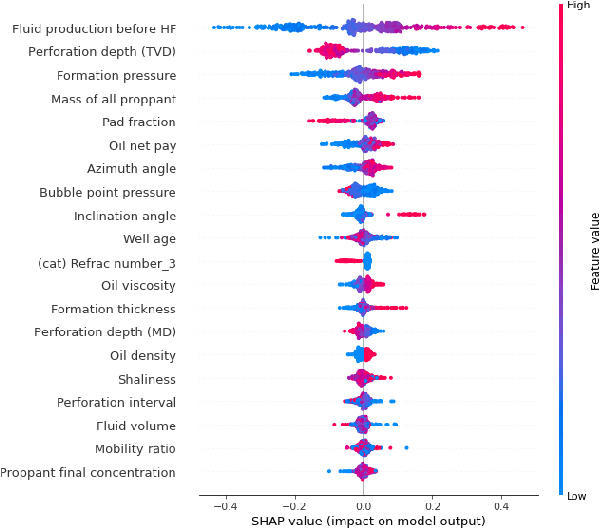
We describe a stacked model for predicting the cumulative fluid production for an oil well with a multistage-fracture completion based on a combination of Ridge Regression and CatBoost algorithms. The model is developed based on an extended digital field data base of reservoir, well and fracturing design parameters. The database now includes more than 5000 wells from 23 oilfields of Western Siberia (Russia), with 6687 fracturing operations in total. Starting with 387 parameters characterizing each well, including construction, reservoir properties, fracturing design features and production, we end up with 38 key parameters used as input features for each well in the model training process. The model demonstrates physically explainable dependencies plots of the target on the design parameters (number of stages, proppant mass, average and final proppant concentrations and fluid rate). We developed a set of methods including those based on the use of Euclidean distance and clustering techniques to perform similar (offset) wells search, which is useful for a field engineer to analyze earlier fracturing treatments on similar wells. These approaches are also adapted for obtaining the optimization parameters boundaries for the particular pilot well, as part of the field testing campaign of the methodology. An inverse problem (selecting an optimum set of fracturing design parameters to maximize production) is formulated as optimizing a high dimensional black box approximation function constrained by boundaries and solved with four different optimization methods: surrogate-based optimization, sequential least squares programming, particle swarm optimization and differential evolution. A recommendation system containing all the above methods is designed to advise a production stimulation engineer on an optimized fracturing design.
LinkTeller: Recovering Private Edges from Graph Neural Networks via Influence Analysis
Aug 14, 2021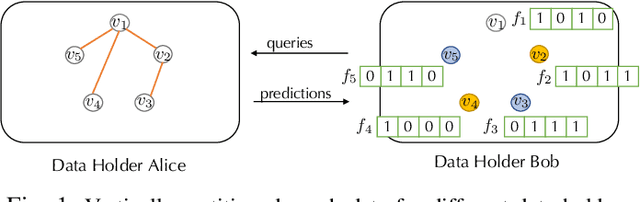
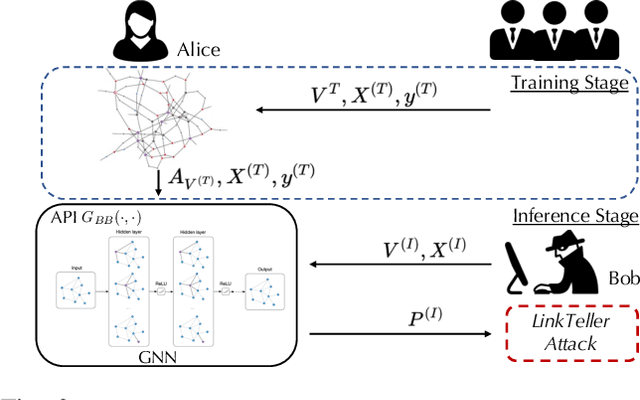
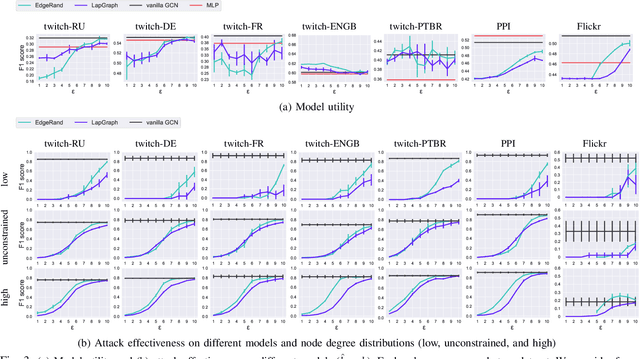
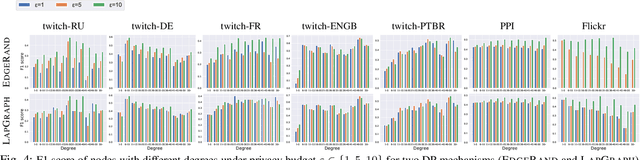
Graph structured data have enabled several successful applications such as recommendation systems and traffic prediction, given the rich node features and edges information. However, these high-dimensional features and high-order adjacency information are usually heterogeneous and held by different data holders in practice. Given such vertical data partition (e.g., one data holder will only own either the node features or edge information), different data holders have to develop efficient joint training protocols rather than directly transfer data to each other due to privacy concerns. In this paper, we focus on the edge privacy, and consider a training scenario where Bob with node features will first send training node features to Alice who owns the adjacency information. Alice will then train a graph neural network (GNN) with the joint information and release an inference API. During inference, Bob is able to provide test node features and query the API to obtain the predictions for test nodes. Under this setting, we first propose a privacy attack LinkTeller via influence analysis to infer the private edge information held by Alice via designing adversarial queries for Bob. We then empirically show that LinkTeller is able to recover a significant amount of private edges, outperforming existing baselines. To further evaluate the privacy leakage, we adapt an existing algorithm for differentially private graph convolutional network (DP GCN) training and propose a new DP GCN mechanism LapGraph. We show that these DP GCN mechanisms are not always resilient against LinkTeller empirically under mild privacy guarantees ($\varepsilon>5$). Our studies will shed light on future research towards designing more resilient privacy-preserving GCN models; in the meantime, provide an in-depth understanding of the tradeoff between GCN model utility and robustness against potential privacy attacks.
Ember: No-Code Context Enrichment via Similarity-Based Keyless Joins
Jun 02, 2021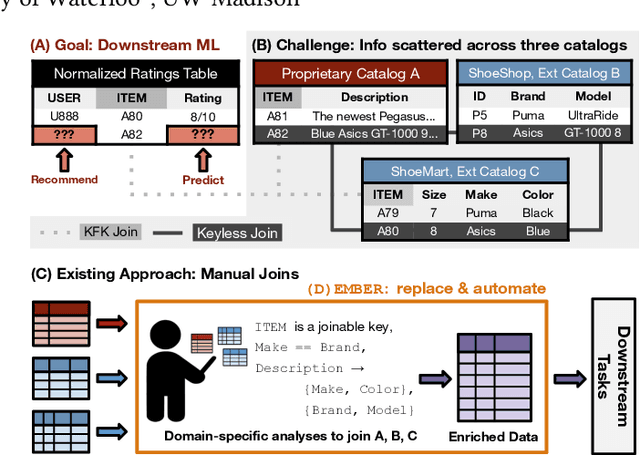
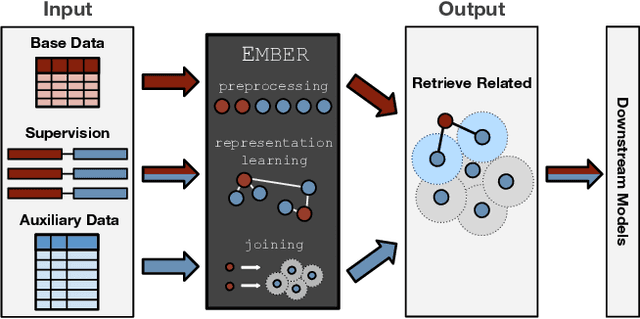
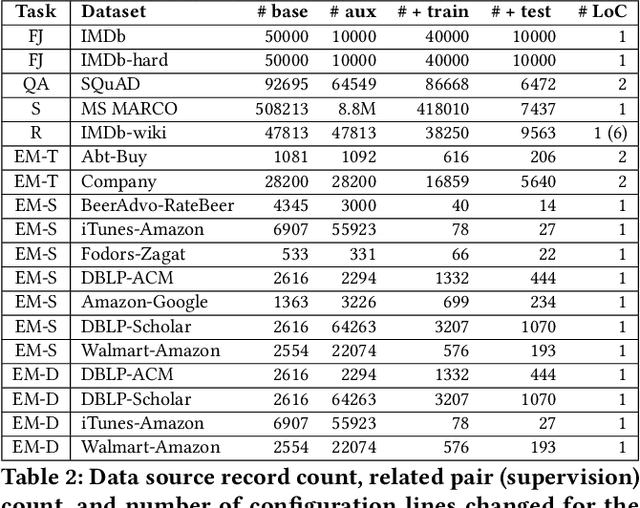
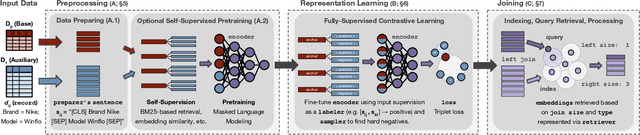
Structured data, or data that adheres to a pre-defined schema, can suffer from fragmented context: information describing a single entity can be scattered across multiple datasets or tables tailored for specific business needs, with no explicit linking keys (e.g., primary key-foreign key relationships or heuristic functions). Context enrichment, or rebuilding fragmented context, using keyless joins is an implicit or explicit step in machine learning (ML) pipelines over structured data sources. This process is tedious, domain-specific, and lacks support in now-prevalent no-code ML systems that let users create ML pipelines using just input data and high-level configuration files. In response, we propose Ember, a system that abstracts and automates keyless joins to generalize context enrichment. Our key insight is that Ember can enable a general keyless join operator by constructing an index populated with task-specific embeddings. Ember learns these embeddings by leveraging Transformer-based representation learning techniques. We describe our core architectural principles and operators when developing Ember, and empirically demonstrate that Ember allows users to develop no-code pipelines for five domains, including search, recommendation and question answering, and can exceed alternatives by up to 39% recall, with as little as a single line configuration change.
Near-optimal Individualized Treatment Recommendations
Apr 06, 2020
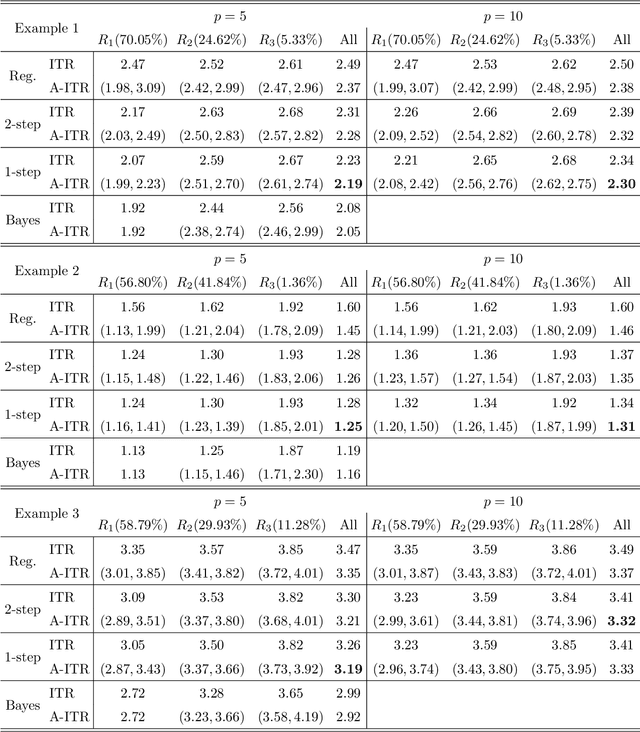
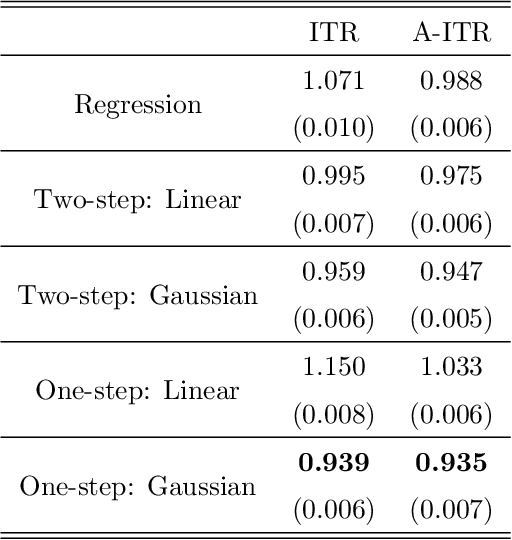
Individualized treatment recommendation (ITR) is an important analytic framework for precision medicine. The goal is to assign proper treatments to patients based on their individual characteristics. From the machine learning perspective, the solution to an ITR problem can be formulated as a weighted classification problem to maximize the average benefit that patients receive from the recommended treatments. Several methods have been proposed for ITR in both binary and multicategory treatment setups. In practice, one may prefer a more flexible recommendation with multiple treatment options. This motivates us to develop methods to obtain a set of near-optimal individualized treatment recommendations alternative to each other, called alternative individualized treatment recommendations (A-ITR). We propose two methods to estimate the optimal A-ITR within the outcome weighted learning (OWL) framework. We show the consistency of these methods and obtain an upper bound for the risk between the theoretically optimal recommendation and the estimated one. We also conduct simulation studies, and apply our methods to a real data set for Type 2 diabetic patients with injectable antidiabetic treatments. These numerical studies have shown the usefulness of the proposed A-ITR framework. We develop a R package aitr which can be found at https://github.com/menghaomiao/aitr.
A Subjective Model of Human Decision Making Based on Quantum Decision Theory
Jan 14, 2021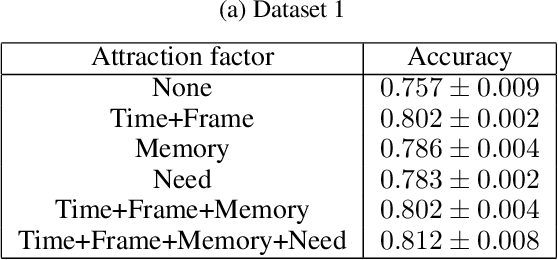
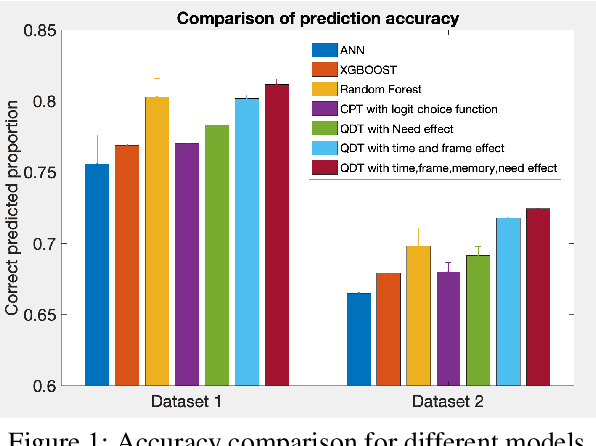
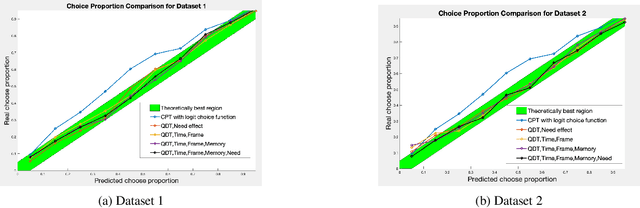
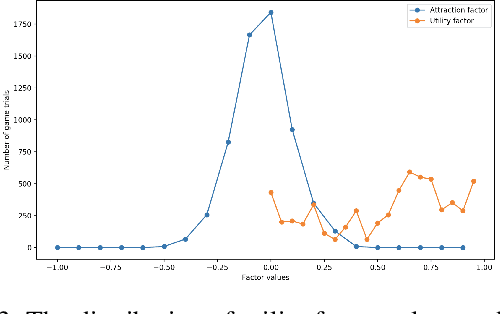
Computer modeling of human decision making is of large importance for, e.g., sustainable transport, urban development, and online recommendation systems. In this paper we present a model for predicting the behavior of an individual during a binary game under different amounts of risk, gain, and time pressure. The model is based on Quantum Decision Theory (QDT), which has been shown to enable modeling of the irrational and subjective aspects of the decision making, not accounted for by the classical Cumulative Prospect Theory (CPT). Experiments on two different datasets show that our QDT-based approach outperforms both a CPT-based approach and data driven approaches such as feed-forward neural networks and random forests.
Mixed-Precision Embedding Using a Cache
Oct 23, 2020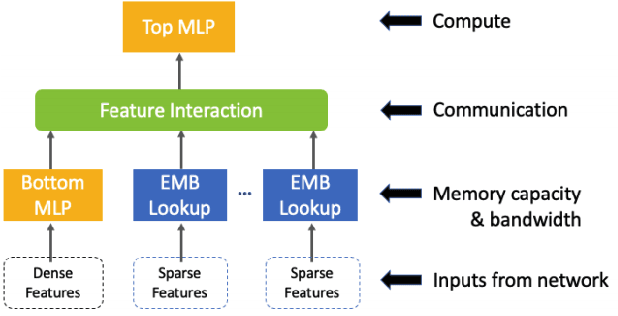

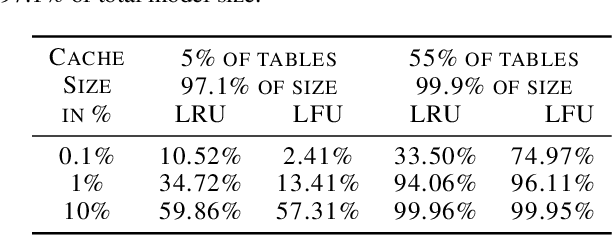
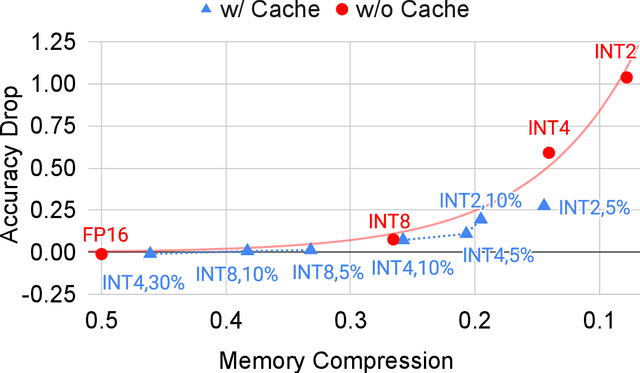
In recommendation systems, practitioners observed that increase in the number of embedding tables and their sizes often leads to significant improvement in model performances. Given this and the business importance of these models to major internet companies, embedding tables for personalization tasks have grown to terabyte scale and continue to grow at a significant rate. Meanwhile, these large-scale models are often trained with GPUs where high-performance memory is a scarce resource, thus motivating numerous work on embedding table compression during training. We propose a novel change to embedding tables using a cache memory architecture, where the majority of rows in an embedding is trained in low precision, and the most frequently or recently accessed rows cached and trained in full precision. The proposed architectural change works in conjunction with standard precision reduction and computer arithmetic techniques such as quantization and stochastic rounding. For an open source deep learning recommendation model (DLRM) running with Criteo-Kaggle dataset, we achieve 3x memory reduction with INT8 precision embedding tables and full-precision cache whose size are 5% of the embedding tables, while maintaining accuracy. For an industrial scale model and dataset, we achieve even higher >7x memory reduction with INT4 precision and cache size 1% of embedding tables, while maintaining accuracy, and 16% end-to-end training speedup by reducing GPU-to-host data transfers.