 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Evaluating Recommender System Algorithms for Generating Local Music Playlists
Jul 17, 2019
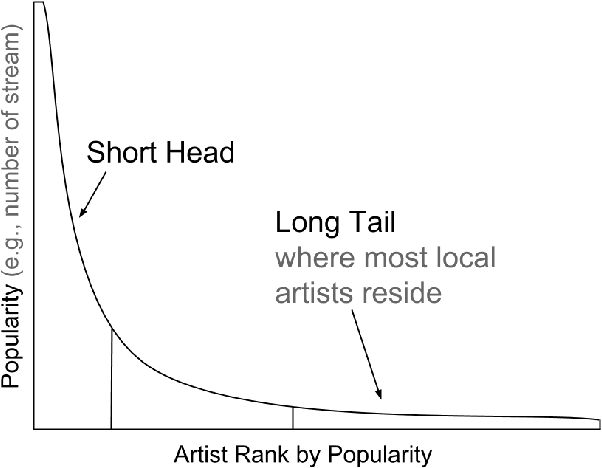


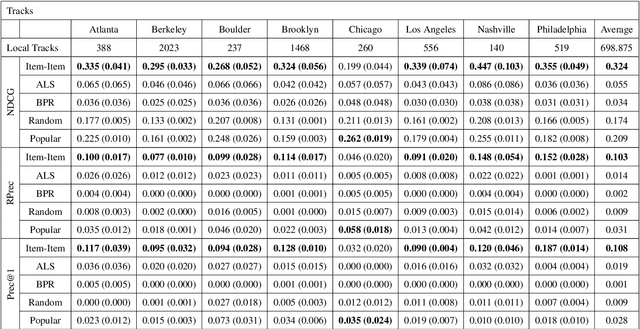
We explore the task of local music recommendation: provide listeners with personalized playlists of relevant tracks by artists who play most of their live events within a small geographic area. Most local artists tend to be obscure, long-tail artists and generally have little or no available user preference data associated with them. This creates a cold-start problem for collaborative filtering-based recommendation algorithms that depend on large amounts of such information to make accurate recommendations. In this paper, we compare the performance of three standard recommender system algorithms (Item-Item Neighborhood (IIN), Alternating Least Squares for Implicit Feedback (ALS), and Bayesian Personalized Ranking (BPR)) on the task of local music recommendation using the Million Playlist Dataset. To do this, we modify the standard evaluation procedure such that the algorithms only rank tracks by local artists for each of the eight different cities. Despite the fact that techniques based on matrix factorization (ALS, BPR) typically perform best on large recommendation tasks, we find that the neighborhood-based approach (IIN) performs best for long-tail local music recommendation.
Wide and Deep Graph Neural Network with Distributed Online Learning
Jul 19, 2021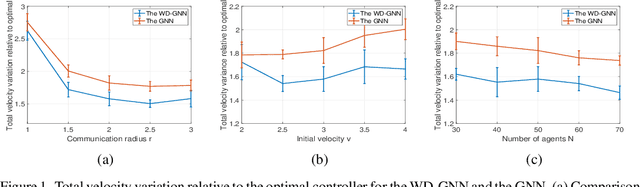
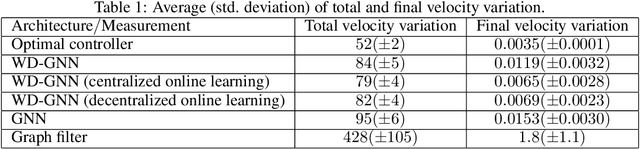
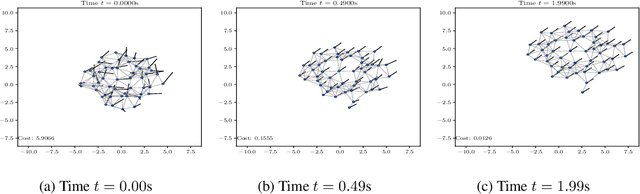
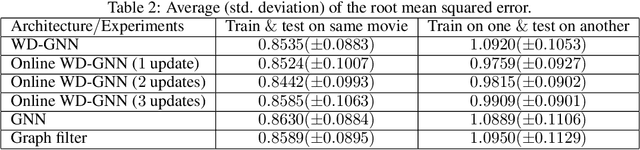
Graph neural networks (GNNs) are naturally distributed architectures for learning representations from network data. This renders them suitable candidates for decentralized tasks. In these scenarios, the underlying graph often changes with time due to link failures or topology variations, creating a mismatch between the graphs on which GNNs were trained and the ones on which they are tested. Online learning can be leveraged to retrain GNNs at testing time to overcome this issue. However, most online algorithms are centralized and usually offer guarantees only on convex problems, which GNNs rarely lead to. This paper develops the Wide and Deep GNN (WD-GNN), a novel architecture that can be updated with distributed online learning mechanisms. The WD-GNN consists of two components: the wide part is a linear graph filter and the deep part is a nonlinear GNN. At training time, the joint wide and deep architecture learns nonlinear representations from data. At testing time, the wide, linear part is retrained, while the deep, nonlinear one remains fixed. This often leads to a convex formulation. We further propose a distributed online learning algorithm that can be implemented in a decentralized setting. We also show the stability of the WD-GNN to changes of the underlying graph and analyze the convergence of the proposed online learning procedure. Experiments on movie recommendation, source localization and robot swarm control corroborate theoretical findings and show the potential of the WD-GNN for distributed online learning.
Discovering long term dependencies in noisy time series data using deep learning
Nov 15, 2020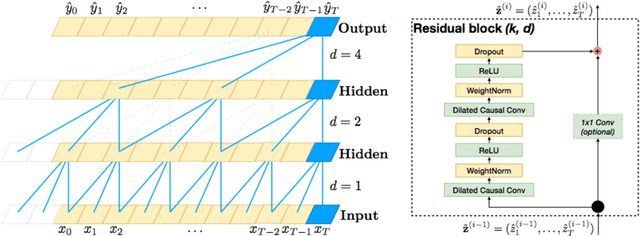
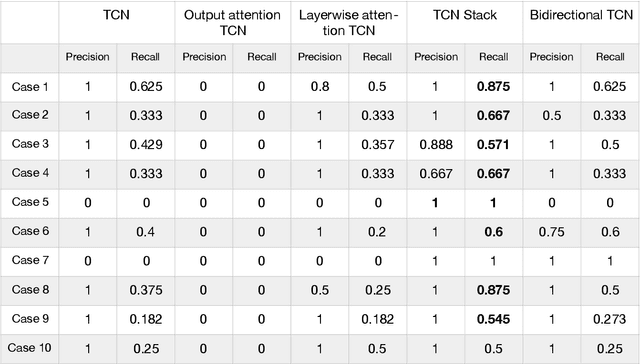
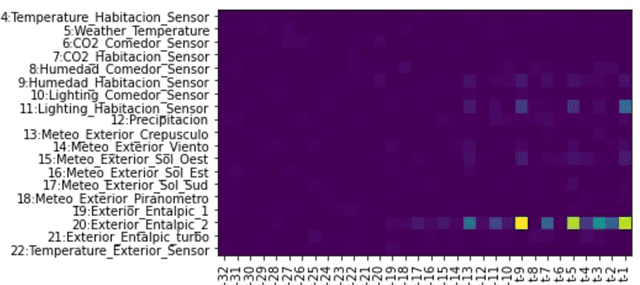
Time series modelling is essential for solving tasks such as predictive maintenance, quality control and optimisation. Deep learning is widely used for solving such problems. When managing complex manufacturing process with neural networks, engineers need to know why machine learning model made specific decision and what are possible outcomes of following model recommendation. In this paper we develop framework for capturing and explaining temporal dependencies in time series data using deep neural networks and test it on various synthetic and real world datasets.
FAIR: Fairness-Aware Information Retrieval Evaluation
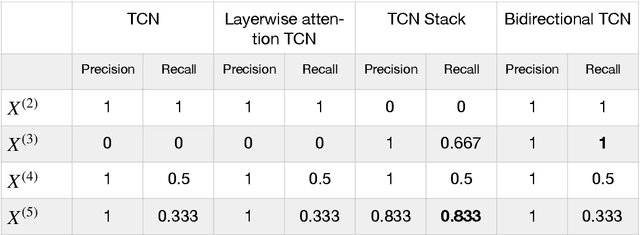
Jun 16, 2021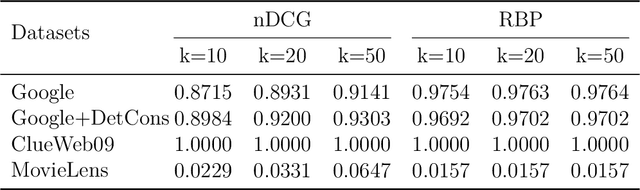
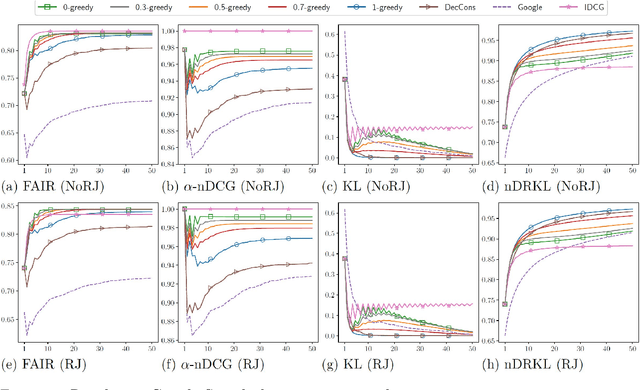
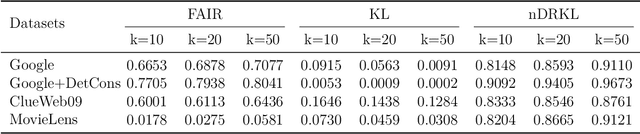
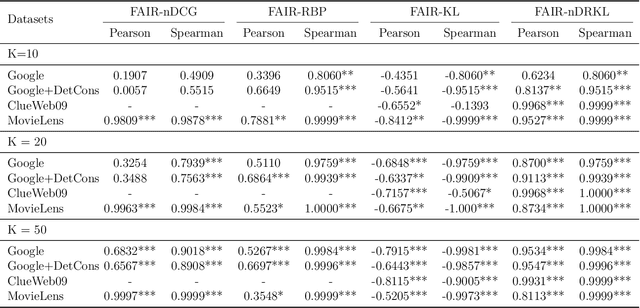
With the emerging needs of creating fairness-aware solutions for search and recommendation systems, a daunting challenge exists of evaluating such solutions. While many of the traditional information retrieval (IR) metrics can capture the relevance, diversity and novelty for the utility with respect to users, they are not suitable for inferring whether the presented results are fair from the perspective of responsible information exposure. On the other hand, various fairness metrics have been proposed but they do not account for the user utility or do not measure it adequately. To address this problem, we propose a new metric called Fairness-Aware IR (FAIR). By unifying standard IR metrics and fairness measures into an integrated metric, this metric offers a new perspective for evaluating fairness-aware ranking results. Based on this metric, we developed an effective ranking algorithm that jointly optimized user utility and fairness. The experimental results showed that our FAIR metric could highlight results with good user utility and fair information exposure. We showed how FAIR related to existing metrics and demonstrated the effectiveness of our FAIR-based algorithm. We believe our work opens up a new direction of pursuing a computationally feasible metric for evaluating and implementing the fairness-aware IR systems.
Evaluating Tag Recommendations for E-Book Annotation Using a Semantic Similarity Metric
Aug 12, 2019
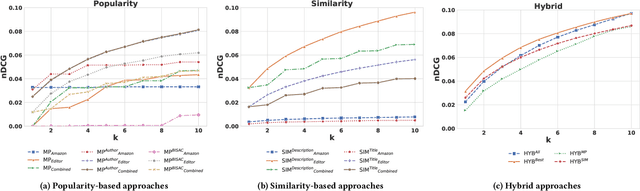
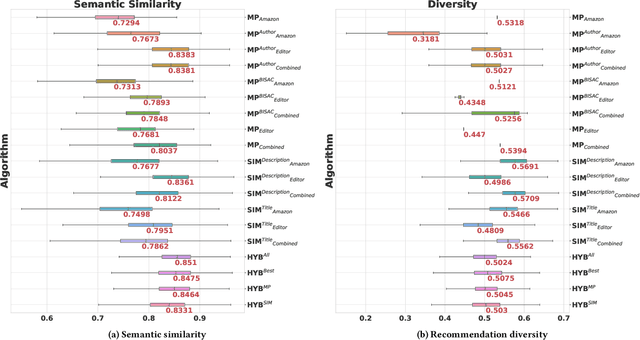
In this paper, we present our work to support publishers and editors in finding descriptive tags for e-books through tag recommendations. We propose a hybrid tag recommendation system for e-books, which leverages search query terms from Amazon users and e-book metadata, which is assigned by publishers and editors. Our idea is to mimic the vocabulary of users in Amazon, who search for and review e-books, and to combine these search terms with editor tags in a hybrid tag recommendation approach. In total, we evaluate 19 tag recommendation algorithms on the review content of Amazon users, which reflects the readers' vocabulary. Our results show that we can improve the performance of tag recommender systems for e-books both concerning tag recommendation accuracy, diversity as well as a novel semantic similarity metric, which we also propose in this paper.
A Systematic Literature Review on Process-Aware Recommender Systems
Mar 30, 2021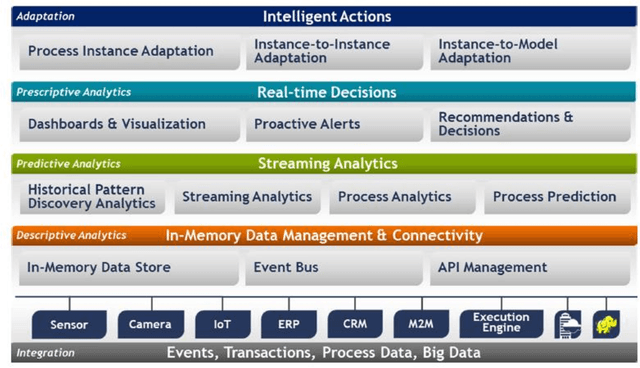
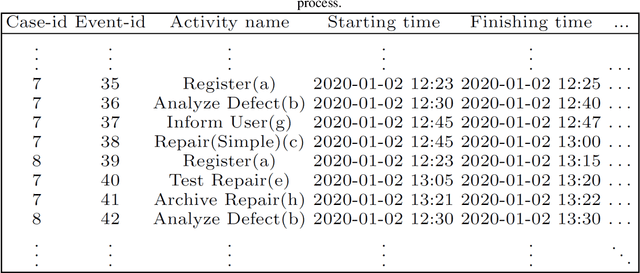
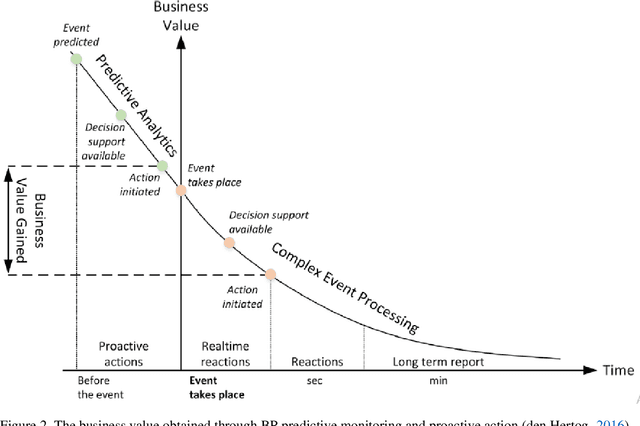
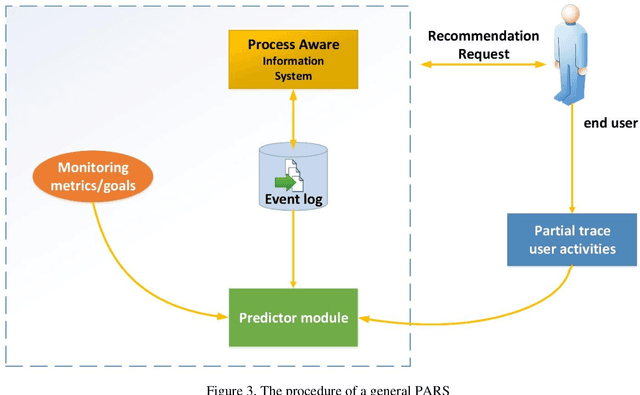
Considering processes of a business in a recommender system is highly advantageous. Although most studies in the business process analysis domain are of descriptive and predictive nature, the feasibility of constructing a process-aware recommender system is assessed in a few works. One reason can be the lack of knowledge on process mining potential for recommendation problems. Therefore, this paper aims to identify and analyze the published studies on process-aware recommender system techniques on business process management and process mining. A systematic review is run on 33 academic articles published between 2008 and 2020 according to several aspects. In this regard, we provide a state-of-the-art review with critical details and researchers with a better perception of which path to pursue in this field. Moreover, based on a knowledge base and holistic perspective, we discuss some research gaps and open challenges in this field.
Theoretical Modeling of the Iterative Properties of User Discovery in a Collaborative Filtering Recommender System
Aug 21, 2020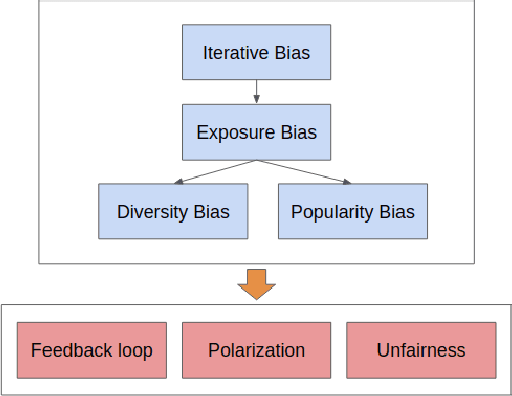

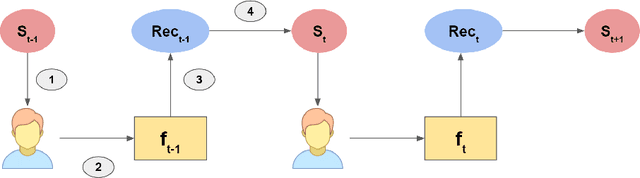

The closed feedback loop in recommender systems is a common setting that can lead to different types of biases. Several studies have dealt with these biases by designing methods to mitigate their effect on the recommendations. However, most existing studies do not consider the iterative behavior of the system where the closed feedback loop plays a crucial role in incorporating different biases into several parts of the recommendation steps. We present a theoretical framework to model the asymptotic evolution of the different components of a recommender system operating within a feedback loop setting, and derive theoretical bounds and convergence properties on quantifiable measures of the user discovery and blind spots. We also validate our theoretical findings empirically using a real-life dataset and empirically test the efficiency of a basic exploration strategy within our theoretical framework. Our findings lay the theoretical basis for quantifying the effect of feedback loops and for designing Artificial Intelligence and machine learning algorithms that explicitly incorporate the iterative nature of feedback loops in the machine learning and recommendation process.
Review Regularized Neural Collaborative Filtering
Aug 20, 2020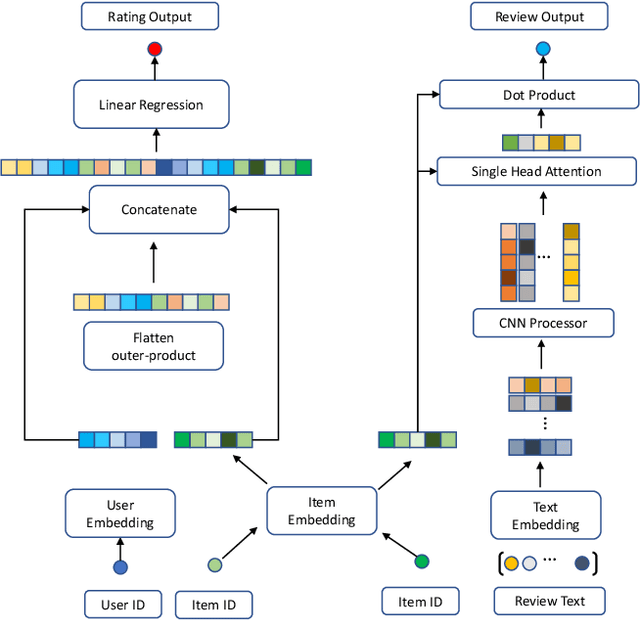
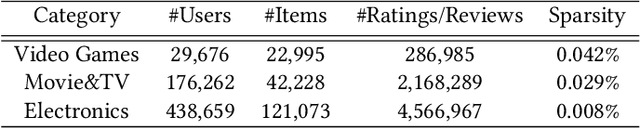


In recent years, text-aware collaborative filtering methods have been proposed to address essential challenges in recommendations such as data sparsity, cold start problem, and long-tail distribution. However, many of these text-oriented methods rely heavily on the availability of text information for every user and item, which obviously does not hold in real-world scenarios. Furthermore, specially designed network structures for text processing are highly inefficient for on-line serving and are hard to integrate into current systems. In this paper, we propose a flexible neural recommendation framework, named Review Regularized Recommendation, short as R3. It consists of a neural collaborative filtering part that focuses on prediction output, and a text processing part that serves as a regularizer. This modular design incorporates text information as richer data sources in the training phase while being highly friendly for on-line serving as it needs no on-the-fly text processing in serving time. Our preliminary results show that by using a simple text processing approach, it could achieve better prediction performance than state-of-the-art text-aware methods.
Feature Based Task Recommendation in Crowdsourcing with Implicit Observations
Sep 07, 2016
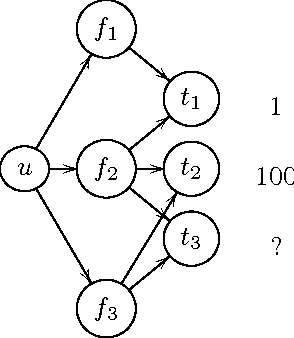
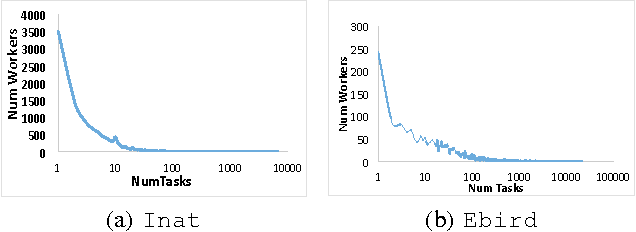
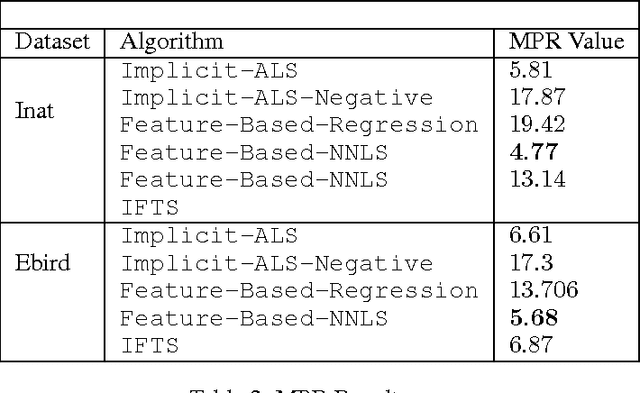
Existing research in crowdsourcing has investigated how to recommend tasks to workers based on which task the workers have already completed, referred to as {\em implicit feedback}. We, on the other hand, investigate the task recommendation problem, where we leverage both implicit feedback and explicit features of the task. We assume that we are given a set of workers, a set of tasks, interactions (such as the number of times a worker has completed a particular task), and the presence of explicit features of each task (such as, task location). We intend to recommend tasks to the workers by exploiting the implicit interactions, and the presence or absence of explicit features in the tasks. We formalize the problem as an optimization problem, propose two alternative problem formulations and respective solutions that exploit implicit feedback, explicit features, as well as similarity between the tasks. We compare the efficacy of our proposed solutions against multiple state-of-the-art techniques using two large scale real world datasets.
Collaborative Filtering Approach to Link Prediction
Mar 14, 2021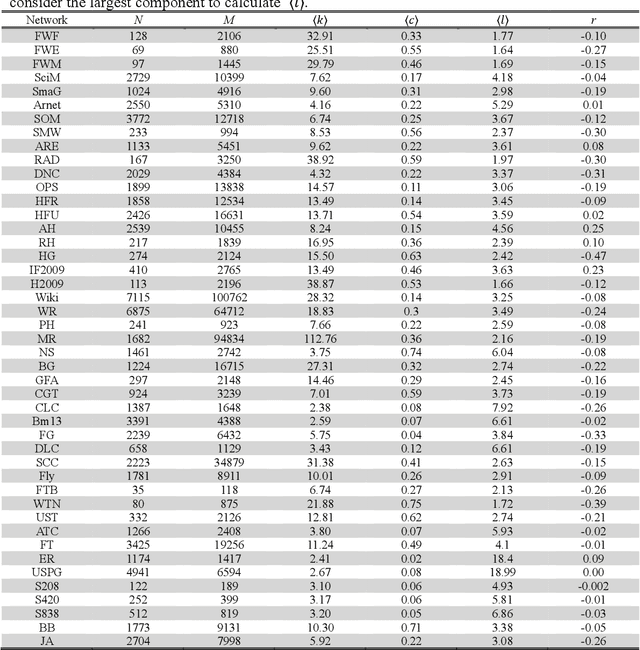
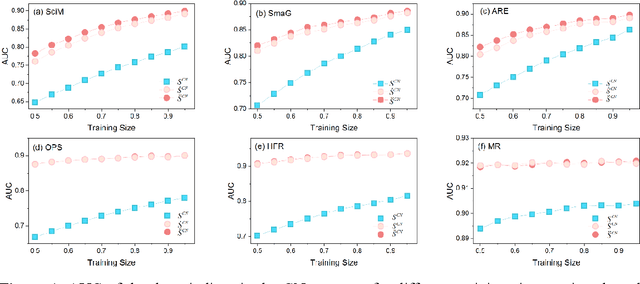
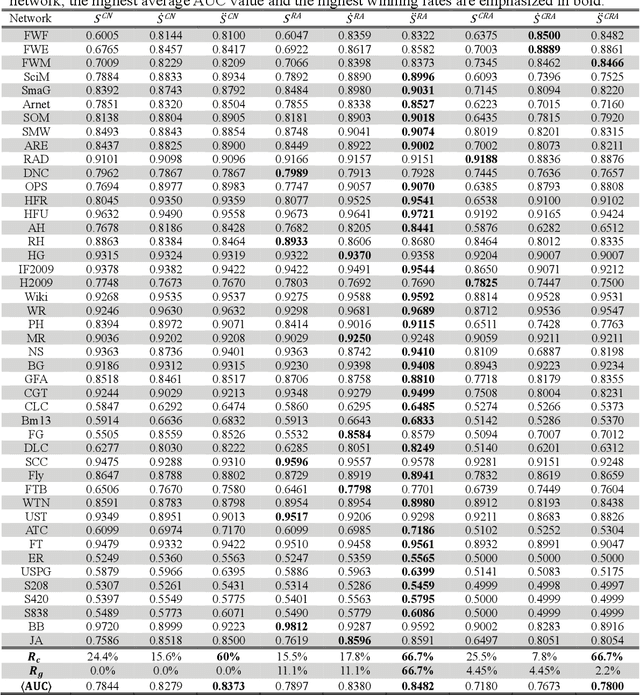

Link prediction is a fundamental challenge in network science. Among various methods, local similarity indices are widely used for their high cost-performance. However, the performance is less robust: for some networks local indices are highly competitive to state-of-the-art algorithms while for some other networks they are very poor. Inspired by techniques developed for recommender systems, we propose an enhancement framework for local indices based on collaborative filtering (CF). Considering the delicate but important difference between personalized recommendation and link prediction, we further propose an improved framework named as self-included collaborative filtering (SCF). The SCF framework significantly improved the accuracy and robustness of well-known local indices. The combination of SCF framework and a simple local index can produce an index with competitive performance and much lower complexity compared with elaborately-designed state-of-the-art algorithms.