 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Locate Who You Are: Matching Geo-location to Text for Anchor Link Prediction
Apr 19, 2021
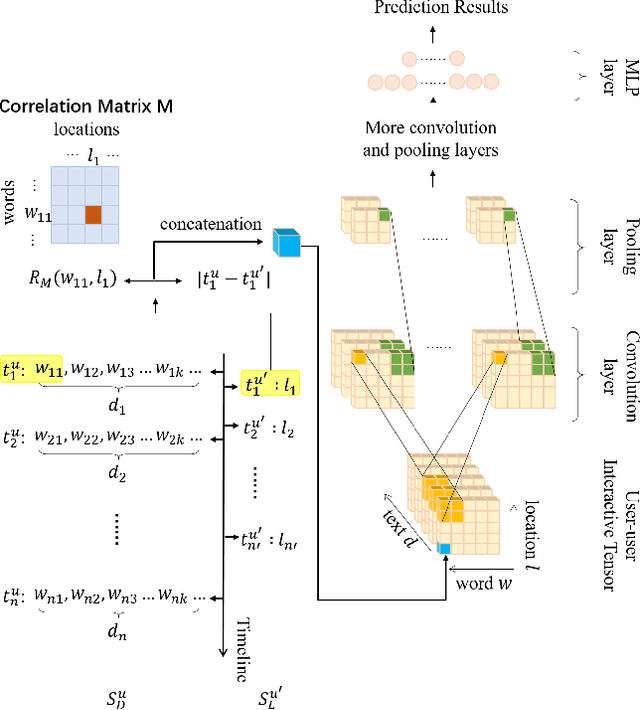
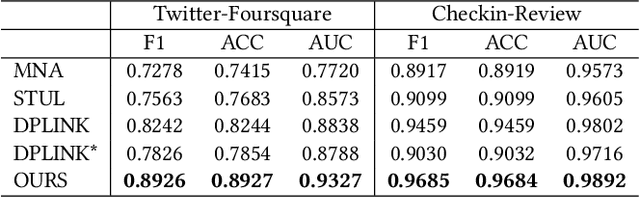
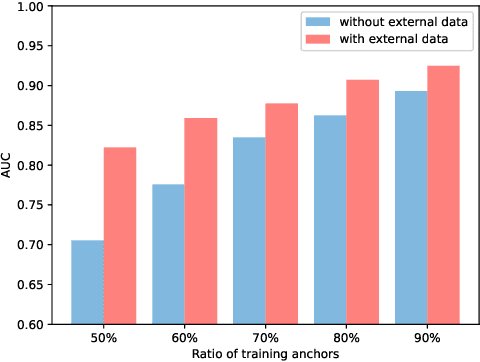
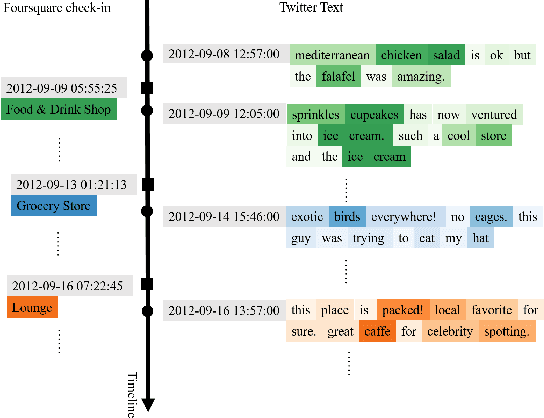
Nowadays, users are encouraged to activate across multiple online social networks simultaneously. Anchor link prediction, which aims to reveal the correspondence among different accounts of the same user across networks, has been regarded as a fundamental problem for user profiling, marketing, cybersecurity, and recommendation. Existing methods mainly address the prediction problem by utilizing profile, content, or structural features of users in symmetric ways. However, encouraged by online services, users would also post asymmetric information across networks, such as geo-locations and texts. It leads to an emerged challenge in aligning users with asymmetric information across networks. Instead of similarity evaluation applied in previous works, we formalize correlation between geo-locations and texts and propose a novel anchor link prediction framework for matching users across networks. Moreover, our model can alleviate the label scarcity problem by introducing external data. Experimental results on real-world datasets show that our approach outperforms existing methods and achieves state-of-the-art results.
High-Performance FPGA-based Accelerator for Bayesian Neural Networks
May 12, 2021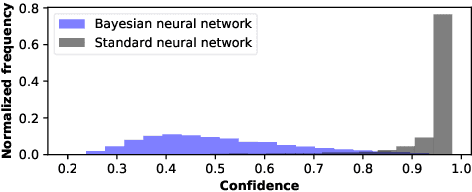
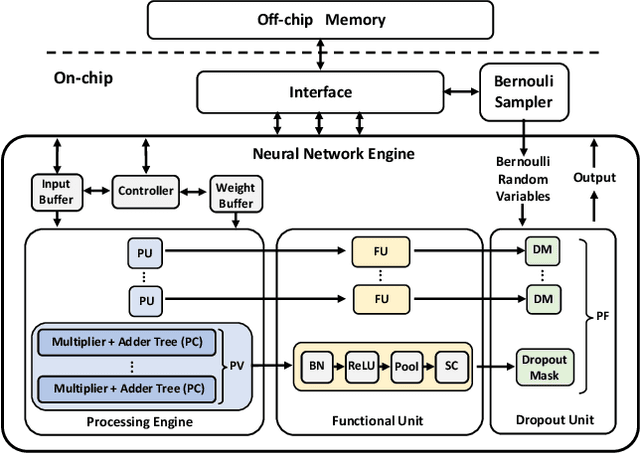
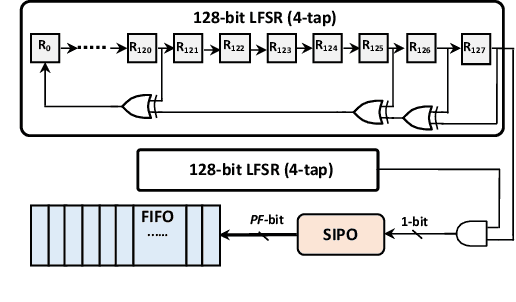
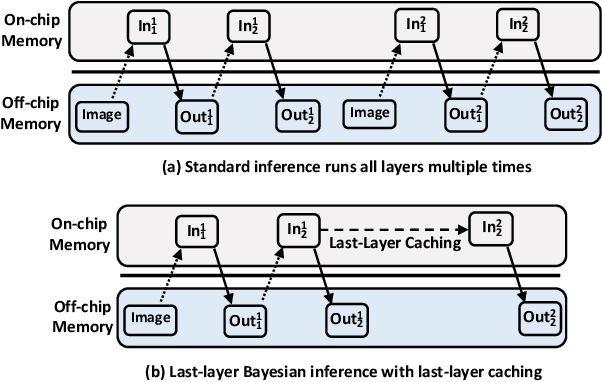
Neural networks (NNs) have demonstrated their potential in a wide range of applications such as image recognition, decision making or recommendation systems. However, standard NNs are unable to capture their model uncertainty which is crucial for many safety-critical applications including healthcare and autonomous vehicles. In comparison, Bayesian neural networks (BNNs) are able to express uncertainty in their prediction via a mathematical grounding. Nevertheless, BNNs have not been as widely used in industrial practice, mainly because of their expensive computational cost and limited hardware performance. This work proposes a novel FPGA-based hardware architecture to accelerate BNNs inferred through Monte Carlo Dropout. Compared with other state-of-the-art BNN accelerators, the proposed accelerator can achieve up to 4 times higher energy efficiency and 9 times better compute efficiency. Considering partial Bayesian inference, an automatic framework is proposed, which explores the trade-off between hardware and algorithmic performance. Extensive experiments are conducted to demonstrate that our proposed framework can effectively find the optimal points in the design space.
CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]
Dec 29, 2019![Figure 1 for CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9b3eae952e9328441c29809c18a0be822fee16be%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9b3eae952e9328441c29809c18a0be822fee16be%2F4-Table1-1.png&w=640&q=75)
![Figure 3 for CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9b3eae952e9328441c29809c18a0be822fee16be%2F3-Figure2-1.png&w=640&q=75)
![Figure 4 for CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9b3eae952e9328441c29809c18a0be822fee16be%2F4-Figure3-1.png&w=640&q=75)
Recommender Systems (RS) have became a popular research topic and, since 2016, Deep Learning methods and techniques have been increasingly explored in this area. News RS are aimed to personalize users experiences and help them discover relevant articles from a large and dynamic search space. The main contribution of this research was named CHAMELEON, a Deep Learning meta-architecture designed to tackle the specific challenges of news recommendation. It consists of a modular reference architecture which can be instantiated using different neural building blocks. As information about users' past interactions is scarce in the news domain, the user context can be leveraged to deal with the user cold-start problem. Articles' content is also important to tackle the item cold-start problem. Additionally, the temporal decay of items (articles) relevance is very accelerated in the news domain. Furthermore, external breaking events may temporally attract global readership attention, a phenomenon generally known as concept drift in machine learning. All those characteristics are explicitly modeled on this research by a contextual hybrid session-based recommendation approach using Recurrent Neural Networks. The task addressed by this research is session-based news recommendation, i.e., next-click prediction using only information available in the current user session. A method is proposed for a realistic temporal offline evaluation of such task, replaying the stream of user clicks and fresh articles being continuously published in a news portal. Experiments performed with two large datasets have shown the effectiveness of the CHAMELEON for news recommendation on many quality factors such as accuracy, item coverage, novelty, and reduced item cold-start problem, when compared to other traditional and state-of-the-art session-based recommendation algorithms.
An Exploratory Study of Log Placement Recommendation in an Enterprise System
Mar 02, 2021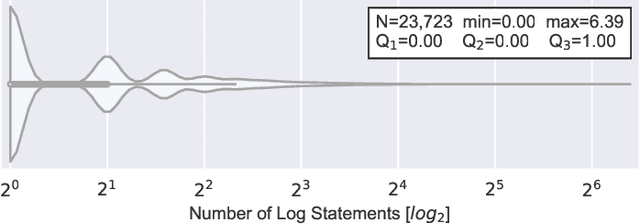



Logging is a development practice that plays an important role in the operations and monitoring of complex systems. Developers place log statements in the source code and use log data to understand how the system behaves in production. Unfortunately, anticipating where to log during development is challenging. Previous studies show the feasibility of leveraging machine learning to recommend log placement despite the data imbalance since logging is a fraction of the overall code base. However, it remains unknown how those techniques apply to an industry setting, and little is known about the effect of imbalanced data and sampling techniques. In this paper, we study the log placement problem in the code base of Adyen, a large-scale payment company. We analyze 34,526 Java files and 309,527 methods that sum up +2M SLOC. We systematically measure the effectiveness of five models based on code metrics, explore the effect of sampling techniques, understand which features models consider to be relevant for the prediction, and evaluate whether we can exploit 388,086 methods from 29 Apache projects to learn where to log in an industry setting. Our best performing model achieves 79% of balanced accuracy, 81% of precision, 60% of recall. While sampling techniques improve recall, they penalize precision at a prohibitive cost. Experiments with open-source data yield under-performing models over Adyen's test set; nevertheless, they are useful due to their low rate of false positives. Our supporting scripts and tools are available to the community.
A Text Extraction-Based Smart Knowledge Graph Composition for Integrating Lessons Learned during the Microchip Design
May 11, 2021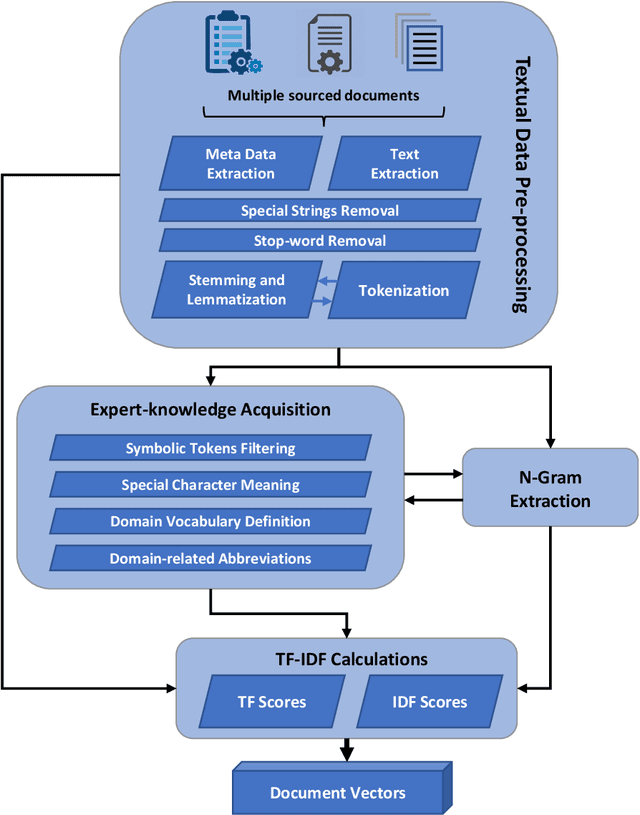
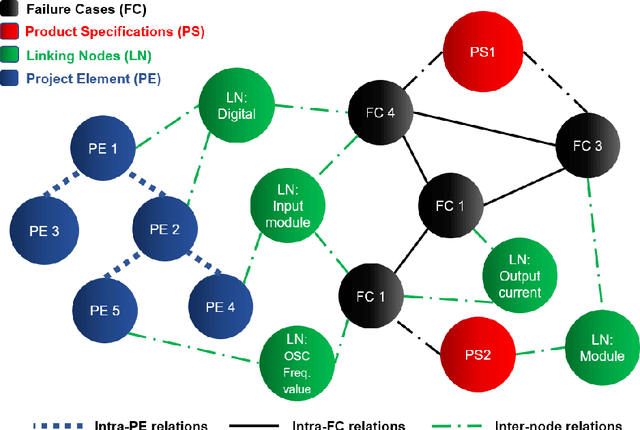

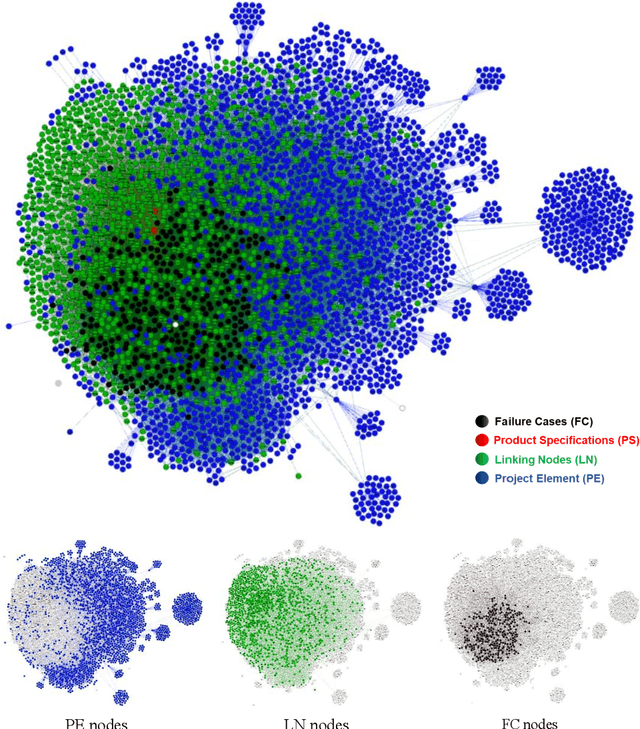
The production of microchips is a complex and thus well documented process. Therefore, available textual data about the production can be overwhelming in terms of quantity. This affects the visibility and retrieval of a certain piece of information when it is most needed. In this paper, we propose a dynamic approach to interlink the information extracted from multisource production-relevant documents through the creation of a knowledge graph. This graph is constructed in order to support searchability and enhance user's access to large-scale production information. Text mining methods are firstly utilized to extract data from multiple documentation sources. Document relations are then mined and extracted for the composition of the knowledge graph. Graph search functionality is then supported with a recommendation use-case to enhance users' access to information that is related to the initial documents. The proposed approach is tailored to and tested on microchip design-relevant documents. It enhances the visibility and findability of previous design-failure-cases during the process of a new chip design.
The Cold-start Problem: Minimal Users' Activity Estimation
May 31, 2021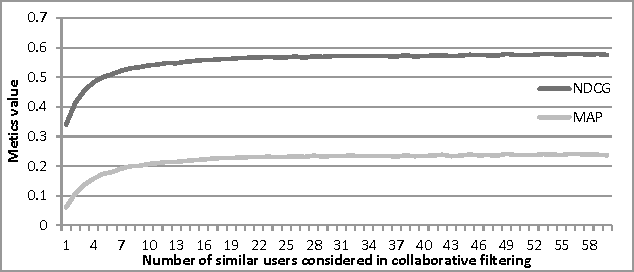
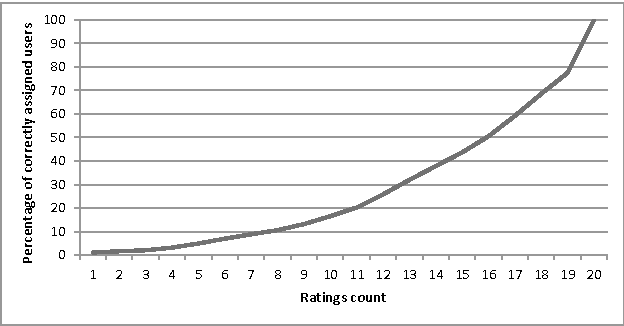
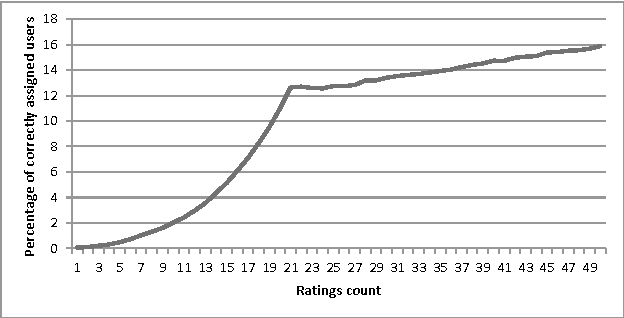
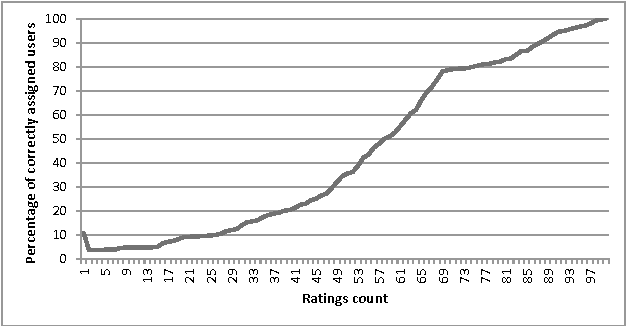
Cold-start problem, which arises upon the new users arrival, is one of the fundamental problems in today's recommender approaches. Moreover, in some domains as TV or multime-dia-items take long time to experience by users, thus users usually do not provide rich preference information. In this paper we analyze the minimal amount of ratings needs to be done by a user over a set of items, in order to solve or reduce the cold-start problem. In our analysis we applied clustering data mining technique in order to identify minimal amount of item's ratings required from recommender system's users, in order to be assigned to a correct cluster. In this context, cluster quality is being monitored and in case of reaching certain cluster quality threshold, the rec-ommender system could start to generate recommendations for given user, as in this point cold-start problem is considered as resolved. Our proposed approach is applicable to any domain in which user preferences are received based on explicit items rating. Our experiments are performed within the movie and jokes recommendation domain using the MovieLens and Jester dataset.
Graph Attention Collaborative Similarity Embedding for Recommender System
Feb 05, 2021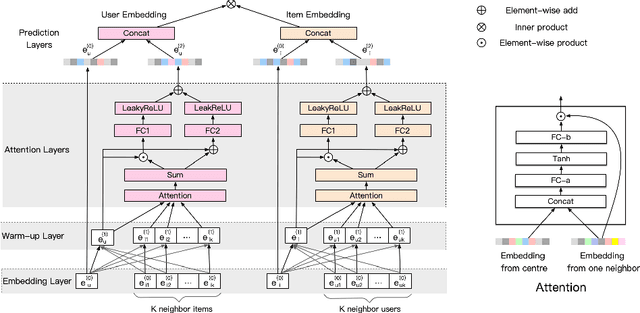
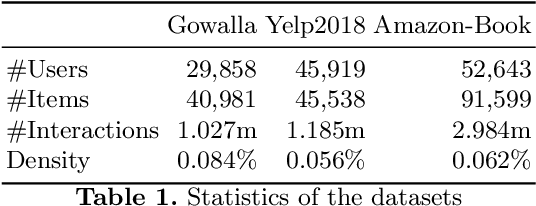
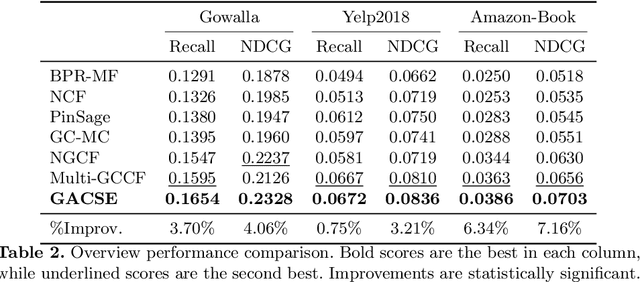
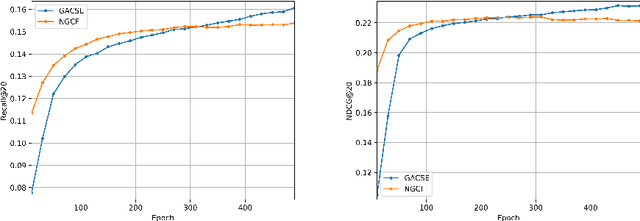
We present Graph Attention Collaborative Similarity Embedding (GACSE), a new recommendation framework that exploits collaborative information in the user-item bipartite graph for representation learning. Our framework consists of two parts: the first part is to learn explicit graph collaborative filtering information such as user-item association through embedding propagation with attention mechanism, and the second part is to learn implicit graph collaborative information such as user-user similarities and item-item similarities through auxiliary loss. We design a new loss function that combines BPR loss with adaptive margin and similarity loss for the similarities learning. Extensive experiments on three benchmarks show that our model is consistently better than the latest state-of-the-art models.
CoupleNet: Paying Attention to Couples with Coupled Attention for Relationship Recommendation
May 29, 2018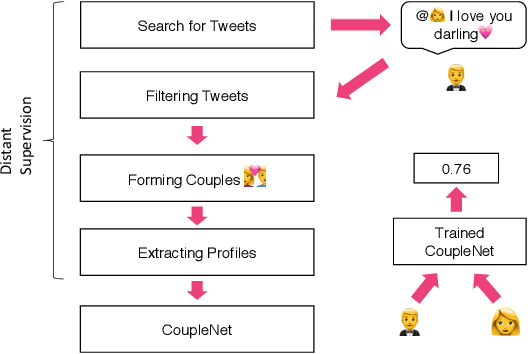
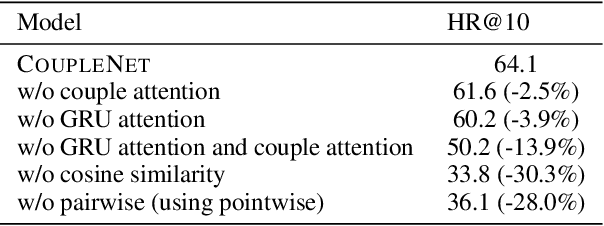
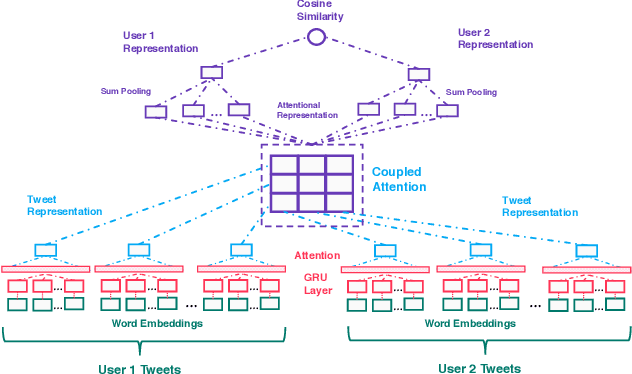

Dating and romantic relationships not only play a huge role in our personal lives but also collectively influence and shape society. Today, many romantic partnerships originate from the Internet, signifying the importance of technology and the web in modern dating. In this paper, we present a text-based computational approach for estimating the relationship compatibility of two users on social media. Unlike many previous works that propose reciprocal recommender systems for online dating websites, we devise a distant supervision heuristic to obtain real world couples from social platforms such as Twitter. Our approach, the CoupleNet is an end-to-end deep learning based estimator that analyzes the social profiles of two users and subsequently performs a similarity match between the users. Intuitively, our approach performs both user profiling and match-making within a unified end-to-end framework. CoupleNet utilizes hierarchical recurrent neural models for learning representations of user profiles and subsequently coupled attention mechanisms to fuse information aggregated from two users. To the best of our knowledge, our approach is the first data-driven deep learning approach for our novel relationship recommendation problem. We benchmark our CoupleNet against several machine learning and deep learning baselines. Experimental results show that our approach outperforms all approaches significantly in terms of precision. Qualitative analysis shows that our model is capable of also producing explainable results to users.
Strategic Mitigation of Agent Inattention in Drivers with Open-Quantum Cognition Models
Jul 21, 2021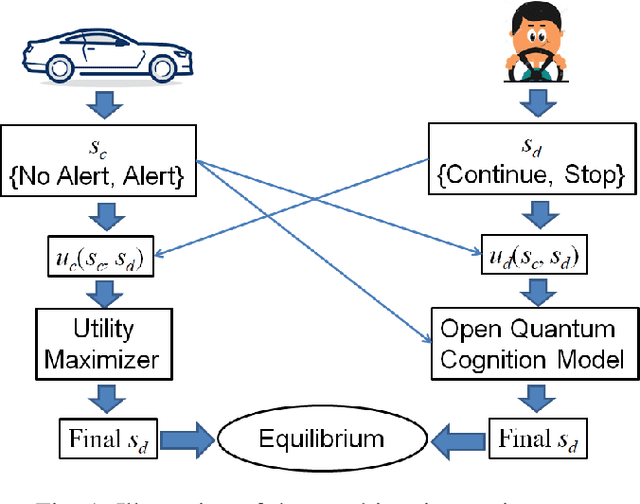
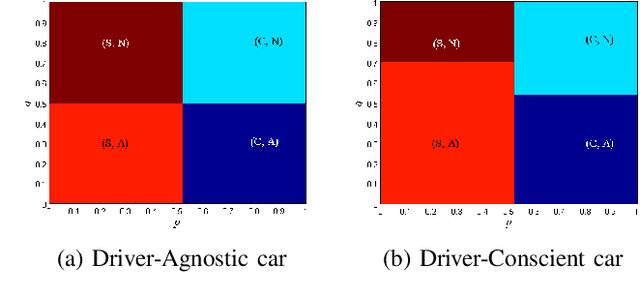
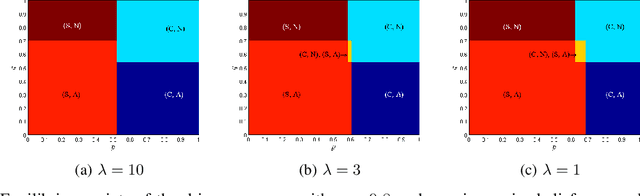

State-of-the-art driver-assist systems have failed to effectively mitigate driver inattention and had minimal impacts on the ever-growing number of road mishaps (e.g. life loss, physical injuries due to accidents caused by various factors that lead to driver inattention). This is because traditional human-machine interaction settings are modeled in classical and behavioral game-theoretic domains which are technically appropriate to characterize strategic interaction between either two utility maximizing agents, or human decision makers. Therefore, in an attempt to improve the persuasive effectiveness of driver-assist systems, we develop a novel strategic and personalized driver-assist system which adapts to the driver's mental state and choice behavior. First, we propose a novel equilibrium notion in human-system interaction games, where the system maximizes its expected utility and human decisions can be characterized using any general decision model. Then we use this novel equilibrium notion to investigate the strategic driver-vehicle interaction game where the car presents a persuasive recommendation to steer the driver towards safer driving decisions. We assume that the driver employs an open-quantum system cognition model, which captures complex aspects of human decision making such as violations to classical law of total probability and incompatibility of certain mental representations of information. We present closed-form expressions for players' final responses to each other's strategies so that we can numerically compute both pure and mixed equilibria. Numerical results are presented to illustrate both kinds of equilibria.
Explainable Recommendations via Attentive Multi-Persona Collaborative Filtering
Sep 26, 2020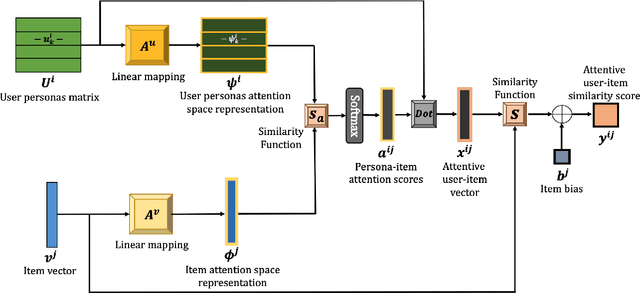
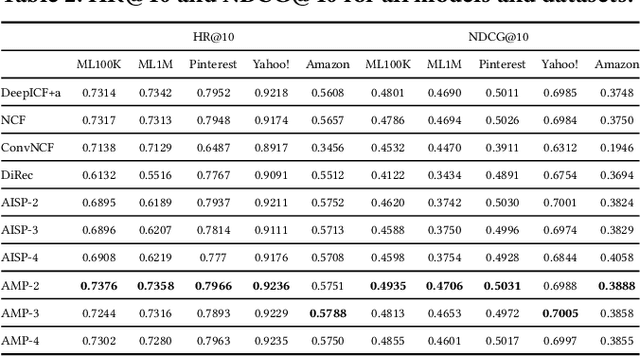
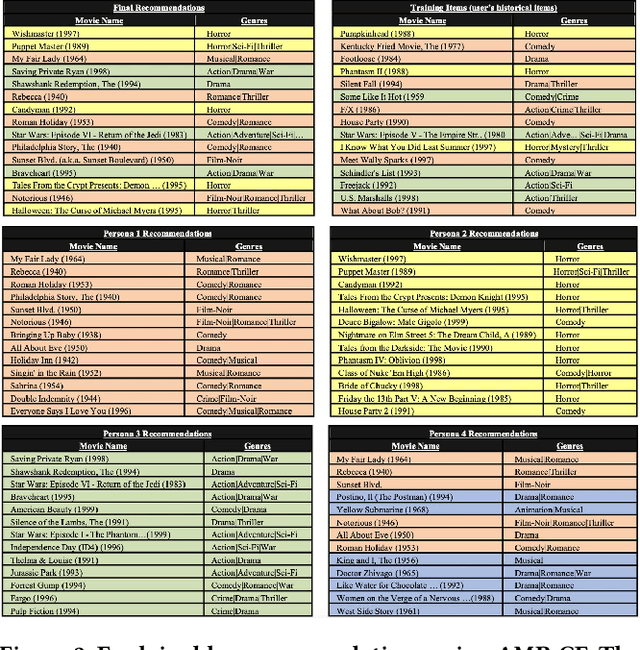
Two main challenges in recommender systems are modeling users with heterogeneous taste, and providing explainable recommendations. In this paper, we propose the neural Attentive Multi-Persona Collaborative Filtering (AMP-CF) model as a unified solution for both problems. AMP-CF breaks down the user to several latent 'personas' (profiles) that identify and discern the different tastes and inclinations of the user. Then, the revealed personas are used to generate and explain the final recommendation list for the user. AMP-CF models users as an attentive mixture of personas, enabling a dynamic user representation that changes based on the item under consideration. We demonstrate AMP-CF on five collaborative filtering datasets from the domains of movies, music, video games and social networks. As an additional contribution, we propose a novel evaluation scheme for comparing the different items in a recommendation list based on the distance from the underlying distribution of "tastes" in the user's historical items. Experimental results show that AMP-CF is competitive with other state-of-the-art models. Finally, we provide qualitative results to showcase the ability of AMP-CF to explain its recommendations.