 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Decoupled Pseudo-labeling for Semi-Supervised Monocular 3D Object Detection
Mar 26, 2024
We delve into pseudo-labeling for semi-supervised monocular 3D object detection (SSM3OD) and discover two primary issues: a misalignment between the prediction quality of 3D and 2D attributes and the tendency of depth supervision derived from pseudo-labels to be noisy, leading to significant optimization conflicts with other reliable forms of supervision. We introduce a novel decoupled pseudo-labeling (DPL) approach for SSM3OD. Our approach features a Decoupled Pseudo-label Generation (DPG) module, designed to efficiently generate pseudo-labels by separately processing 2D and 3D attributes. This module incorporates a unique homography-based method for identifying dependable pseudo-labels in BEV space, specifically for 3D attributes. Additionally, we present a DepthGradient Projection (DGP) module to mitigate optimization conflicts caused by noisy depth supervision of pseudo-labels, effectively decoupling the depth gradient and removing conflicting gradients. This dual decoupling strategy-at both the pseudo-label generation and gradient levels-significantly improves the utilization of pseudo-labels in SSM3OD. Our comprehensive experiments on the KITTI benchmark demonstrate the superiority of our method over existing approaches.
Automatic Defect Detection in Sewer Network Using Deep Learning Based Object Detector
Apr 09, 2024Maintaining sewer systems in large cities is important, but also time and effort consuming, because visual inspections are currently done manually. To reduce the amount of aforementioned manual work, defects within sewer pipes should be located and classified automatically. In the past, multiple works have attempted solving this problem using classical image processing, machine learning, or a combination of those. However, each provided solution only focus on detecting a limited set of defect/structure types, such as fissure, root, and/or connection. Furthermore, due to the use of hand-crafted features and small training datasets, generalization is also problematic. In order to overcome these deficits, a sizable dataset with 14.7 km of various sewer pipes were annotated by sewer maintenance experts in the scope of this work. On top of that, an object detector (EfficientDet-D0) was trained for automatic defect detection. From the result of several expermients, peculiar natures of defects in the context of object detection, which greatly effect annotation and training process, are found and discussed. At the end, the final detector was able to detect 83% of defects in the test set; out of the missing 17%, only 0.77% are very severe defects. This work provides an example of applying deep learning-based object detection into an important but quiet engineering field. It also gives some practical pointers on how to annotate peculiar "object", such as defects.
D-YOLO a robust framework for object detection in adverse weather conditions
Mar 20, 2024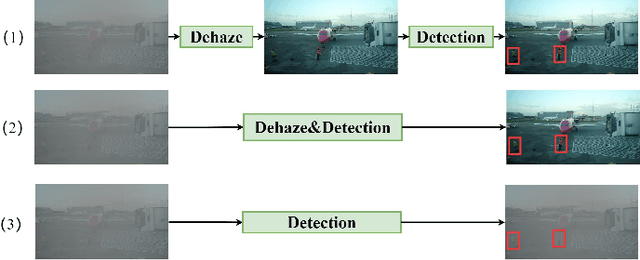
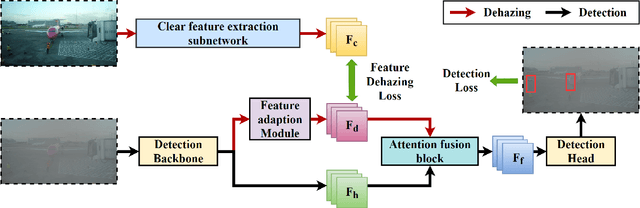
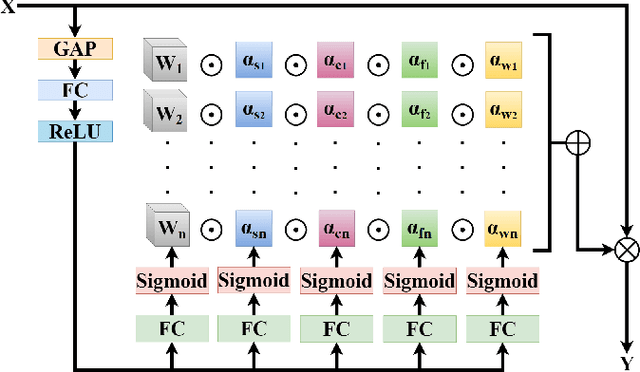
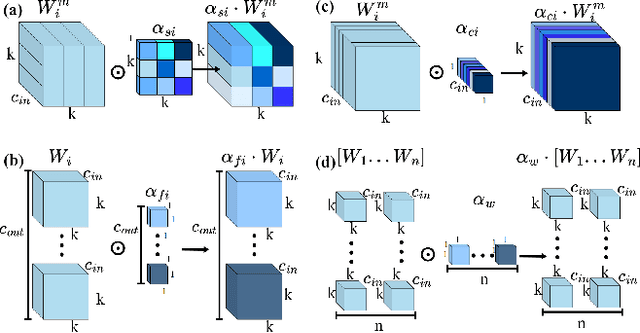
Adverse weather conditions including haze, snow and rain lead to decline in image qualities, which often causes a decline in performance for deep-learning based detection networks. Most existing approaches attempts to rectify hazy images before performing object detection, which increases the complexity of the network and may result in the loss in latent information. To better integrate image restoration and object detection tasks, we designed a double-route network with an attention feature fusion module, taking both hazy and dehazed features into consideration. We also proposed a subnetwork to provide haze-free features to the detection network. Specifically, our D-YOLO improves the performance of the detection network by minimizing the distance between the clear feature extraction subnetwork and detection network. Experiments on RTTS and FoggyCityscapes datasets show that D-YOLO demonstrates better performance compared to the state-of-the-art methods. It is a robust detection framework for bridging the gap between low-level dehazing and high-level detection.
3D Object Detection from Point Cloud via Voting Step Diffusion
Mar 21, 2024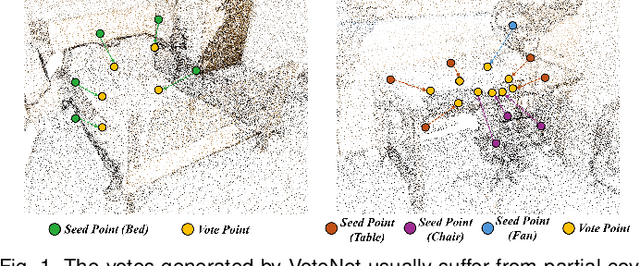
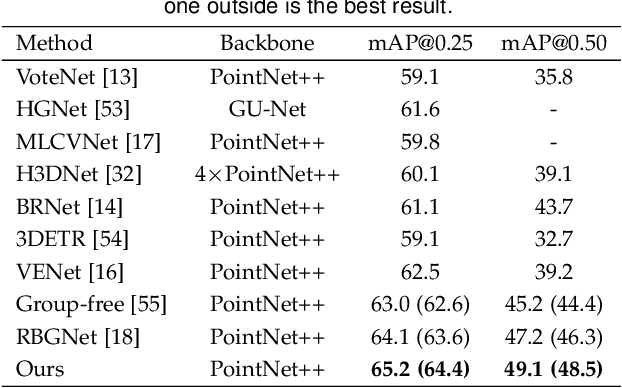
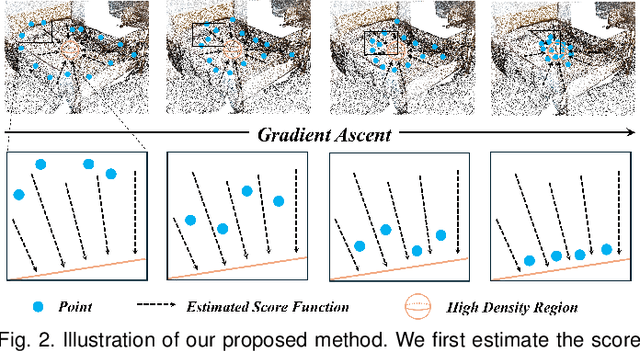
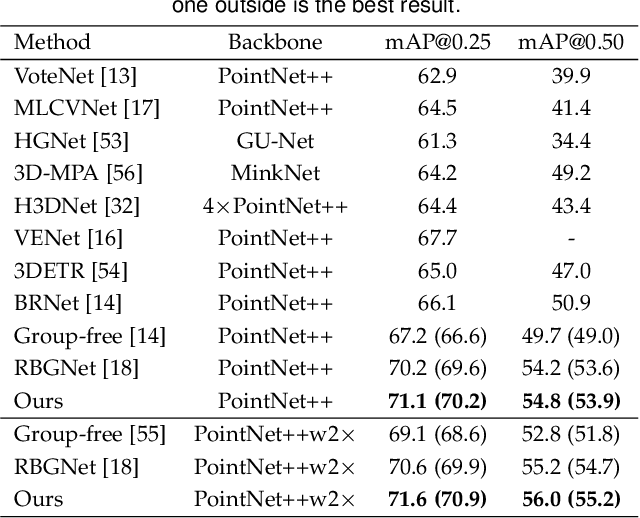
3D object detection is a fundamental task in scene understanding. Numerous research efforts have been dedicated to better incorporate Hough voting into the 3D object detection pipeline. However, due to the noisy, cluttered, and partial nature of real 3D scans, existing voting-based methods often receive votes from the partial surfaces of individual objects together with severe noises, leading to sub-optimal detection performance. In this work, we focus on the distributional properties of point clouds and formulate the voting process as generating new points in the high-density region of the distribution of object centers. To achieve this, we propose a new method to move random 3D points toward the high-density region of the distribution by estimating the score function of the distribution with a noise conditioned score network. Specifically, we first generate a set of object center proposals to coarsely identify the high-density region of the object center distribution. To estimate the score function, we perturb the generated object center proposals by adding normalized Gaussian noise, and then jointly estimate the score function of all perturbed distributions. Finally, we generate new votes by moving random 3D points to the high-density region of the object center distribution according to the estimated score function. Extensive experiments on two large scale indoor 3D scene datasets, SUN RGB-D and ScanNet V2, demonstrate the superiority of our proposed method. The code will be released at https://github.com/HHrEtvP/DiffVote.
Simplifying Two-Stage Detectors for On-Device Inference in Remote Sensing
Apr 11, 2024Deep learning has been successfully applied to object detection from remotely sensed images. Images are typically processed on the ground rather than on-board due to the computation power of the ground system. Such offloaded processing causes delays in acquiring target mission information, which hinders its application to real-time use cases. For on-device object detection, researches have been conducted on designing efficient detectors or model compression to reduce inference latency. However, highly accurate two-stage detectors still need further exploitation for acceleration. In this paper, we propose a model simplification method for two-stage object detectors. Instead of constructing a general feature pyramid, we utilize only one feature extraction in the two-stage detector. To compensate for the accuracy drop, we apply a high pass filter to the RPN's score map. Our approach is applicable to any two-stage detector using a feature pyramid network. In the experiments with state-of-the-art two-stage detectors such as ReDet, Oriented-RCNN, and LSKNet, our method reduced computation costs upto 61.2% with the accuracy loss within 2.1% on the DOTAv1.5 dataset. Source code will be released.
Transformer based Multitask Learning for Image Captioning and Object Detection
Mar 10, 2024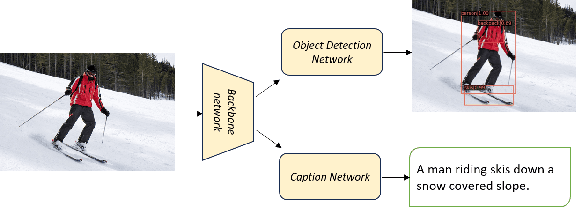
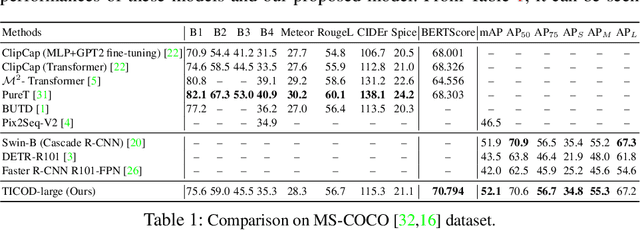
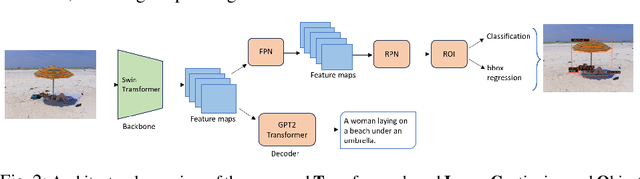
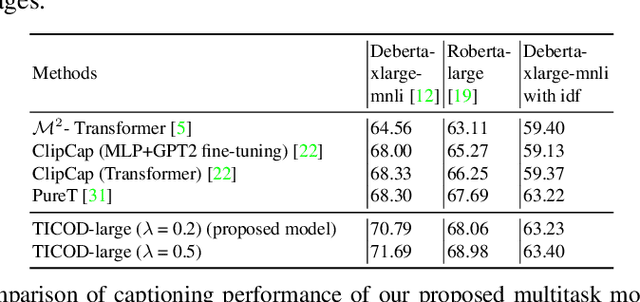
In several real-world scenarios like autonomous navigation and mobility, to obtain a better visual understanding of the surroundings, image captioning and object detection play a crucial role. This work introduces a novel multitask learning framework that combines image captioning and object detection into a joint model. We propose TICOD, Transformer-based Image Captioning and Object detection model for jointly training both tasks by combining the losses obtained from image captioning and object detection networks. By leveraging joint training, the model benefits from the complementary information shared between the two tasks, leading to improved performance for image captioning. Our approach utilizes a transformer-based architecture that enables end-to-end network integration for image captioning and object detection and performs both tasks jointly. We evaluate the effectiveness of our approach through comprehensive experiments on the MS-COCO dataset. Our model outperforms the baselines from image captioning literature by achieving a 3.65% improvement in BERTScore.
LISO: Lidar-only Self-Supervised 3D Object Detection
Mar 11, 2024
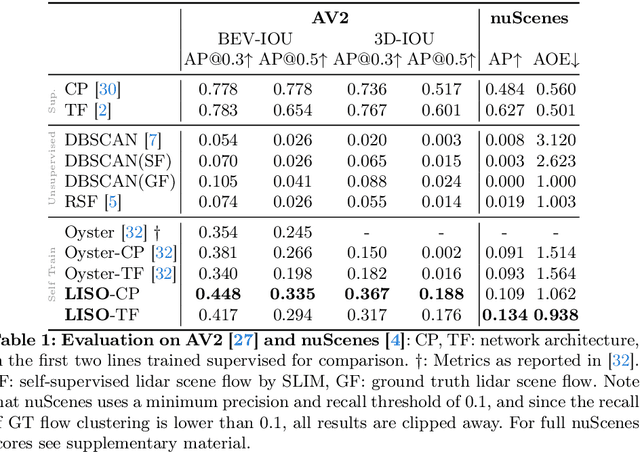

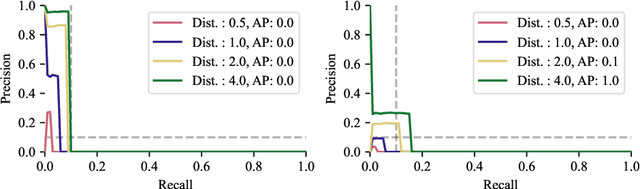
3D object detection is one of the most important components in any Self-Driving stack, but current state-of-the-art (SOTA) lidar object detectors require costly & slow manual annotation of 3D bounding boxes to perform well. Recently, several methods emerged to generate pseudo ground truth without human supervision, however, all of these methods have various drawbacks: Some methods require sensor rigs with full camera coverage and accurate calibration, partly supplemented by an auxiliary optical flow engine. Others require expensive high-precision localization to find objects that disappeared over multiple drives. We introduce a novel self-supervised method to train SOTA lidar object detection networks which works on unlabeled sequences of lidar point clouds only, which we call trajectory-regularized self-training. It utilizes a SOTA self-supervised lidar scene flow network under the hood to generate, track, and iteratively refine pseudo ground truth. We demonstrate the effectiveness of our approach for multiple SOTA object detection networks across multiple real-world datasets. Code will be released.
ConsistencyDet: Robust Object Detector with Denoising Paradigm of Consistency Model
Apr 11, 2024Object detection, a quintessential task in the realm of perceptual computing, can be tackled using a generative methodology. In the present study, we introduce a novel framework designed to articulate object detection as a denoising diffusion process, which operates on perturbed bounding boxes of annotated entities. This framework, termed ConsistencyDet, leverages an innovative denoising concept known as the Consistency Model. The hallmark of this model is its self-consistency feature, which empowers the model to map distorted information from any temporal stage back to its pristine state, thereby realizing a ``one-step denoising'' mechanism. Such an attribute markedly elevates the operational efficiency of the model, setting it apart from the conventional Diffusion Model. Throughout the training phase, ConsistencyDet initiates the diffusion sequence with noise-infused boxes derived from the ground-truth annotations and conditions the model to perform the denoising task. Subsequently, in the inference stage, the model employs a denoising sampling strategy that commences with bounding boxes randomly sampled from a normal distribution. Through iterative refinement, the model transforms an assortment of arbitrarily generated boxes into the definitive detections. Comprehensive evaluations employing standard benchmarks, such as MS-COCO and LVIS, corroborate that ConsistencyDet surpasses other leading-edge detectors in performance metrics.
Detecting Every Object from Events
Apr 08, 2024Object detection is critical in autonomous driving, and it is more practical yet challenging to localize objects of unknown categories: an endeavour known as Class-Agnostic Object Detection (CAOD). Existing studies on CAOD predominantly rely on ordinary cameras, but these frame-based sensors usually have high latency and limited dynamic range, leading to safety risks in real-world scenarios. In this study, we turn to a new modality enabled by the so-called event camera, featured by its sub-millisecond latency and high dynamic range, for robust CAOD. We propose Detecting Every Object in Events (DEOE), an approach tailored for achieving high-speed, class-agnostic open-world object detection in event-based vision. Built upon the fast event-based backbone: recurrent vision transformer, we jointly consider the spatial and temporal consistencies to identify potential objects. The discovered potential objects are assimilated as soft positive samples to avoid being suppressed as background. Moreover, we introduce a disentangled objectness head to separate the foreground-background classification and novel object discovery tasks, enhancing the model's generalization in localizing novel objects while maintaining a strong ability to filter out the background. Extensive experiments confirm the superiority of our proposed DEOE in comparison with three strong baseline methods that integrate the state-of-the-art event-based object detector with advancements in RGB-based CAOD. Our code is available at https://github.com/Hatins/DEOE.
A Real-Time Framework for Domain-Adaptive Underwater Object Detection with Image Enhancement
Mar 28, 2024In recent years, significant progress has been made in the field of underwater image enhancement (UIE). However, its practical utility for high-level vision tasks, such as underwater object detection (UOD) in Autonomous Underwater Vehicles (AUVs), remains relatively unexplored. It may be attributed to several factors: (1) Existing methods typically employ UIE as a pre-processing step, which inevitably introduces considerable computational overhead and latency. (2) The process of enhancing images prior to training object detectors may not necessarily yield performance improvements. (3) The complex underwater environments can induce significant domain shifts across different scenarios, seriously deteriorating the UOD performance. To address these challenges, we introduce EnYOLO, an integrated real-time framework designed for simultaneous UIE and UOD with domain-adaptation capability. Specifically, both the UIE and UOD task heads share the same network backbone and utilize a lightweight design. Furthermore, to ensure balanced training for both tasks, we present a multi-stage training strategy aimed at consistently enhancing their performance. Additionally, we propose a novel domain-adaptation strategy to align feature embeddings originating from diverse underwater environments. Comprehensive experiments demonstrate that our framework not only achieves state-of-the-art (SOTA) performance in both UIE and UOD tasks, but also shows superior adaptability when applied to different underwater scenarios. Our efficiency analysis further highlights the substantial potential of our framework for onboard deployment.