 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
BAM: Box Abstraction Monitors for Real-time OoD Detection in Object Detection
Mar 27, 2024
Out-of-distribution (OoD) detection techniques for deep neural networks (DNNs) become crucial thanks to their filtering of abnormal inputs, especially when DNNs are used in safety-critical applications and interact with an open and dynamic environment. Nevertheless, integrating OoD detection into state-of-the-art (SOTA) object detection DNNs poses significant challenges, partly due to the complexity introduced by the SOTA OoD construction methods, which require the modification of DNN architecture and the introduction of complex loss functions. This paper proposes a simple, yet surprisingly effective, method that requires neither retraining nor architectural change in object detection DNN, called Box Abstraction-based Monitors (BAM). The novelty of BAM stems from using a finite union of convex box abstractions to capture the learned features of objects for in-distribution (ID) data, and an important observation that features from OoD data are more likely to fall outside of these boxes. The union of convex regions within the feature space allows the formation of non-convex and interpretable decision boundaries, overcoming the limitations of VOS-like detectors without sacrificing real-time performance. Experiments integrating BAM into Faster R-CNN-based object detection DNNs demonstrate a considerably improved performance against SOTA OoD detection techniques.
Cooperative Students: Navigating Unsupervised Domain Adaptation in Nighttime Object Detection
Apr 03, 2024Unsupervised Domain Adaptation (UDA) has shown significant advancements in object detection under well-lit conditions; however, its performance degrades notably in low-visibility scenarios, especially at night, posing challenges not only for its adaptability in low signal-to-noise ratio (SNR) conditions but also for the reliability and efficiency of automated vehicles. To address this problem, we propose a \textbf{Co}operative \textbf{S}tudents (\textbf{CoS}) framework that innovatively employs global-local transformations (GLT) and a proxy-based target consistency (PTC) mechanism to capture the spatial consistency in day- and night-time scenarios effectively, and thus bridge the significant domain shift across contexts. Building upon this, we further devise an adaptive IoU-informed thresholding (AIT) module to gradually avoid overlooking potential true positives and enrich the latent information in the target domain. Comprehensive experiments show that CoS essentially enhanced UDA performance in low-visibility conditions and surpasses current state-of-the-art techniques, achieving an increase in mAP of 3.0\%, 1.9\%, and 2.5\% on BDD100K, SHIFT, and ACDC datasets, respectively. Code is available at https://github.com/jichengyuan/Cooperitive_Students.
A Point-Based Approach to Efficient LiDAR Multi-Task Perception
Apr 19, 2024Multi-task networks can potentially improve performance and computational efficiency compared to single-task networks, facilitating online deployment. However, current multi-task architectures in point cloud perception combine multiple task-specific point cloud representations, each requiring a separate feature encoder and making the network structures bulky and slow. We propose PAttFormer, an efficient multi-task architecture for joint semantic segmentation and object detection in point clouds that only relies on a point-based representation. The network builds on transformer-based feature encoders using neighborhood attention and grid-pooling and a query-based detection decoder using a novel 3D deformable-attention detection head design. Unlike other LiDAR-based multi-task architectures, our proposed PAttFormer does not require separate feature encoders for multiple task-specific point cloud representations, resulting in a network that is 3x smaller and 1.4x faster while achieving competitive performance on the nuScenes and KITTI benchmarks for autonomous driving perception. Our extensive evaluations show substantial gains from multi-task learning, improving LiDAR semantic segmentation by +1.7% in mIou and 3D object detection by +1.7% in mAP on the nuScenes benchmark compared to the single-task models.
Cross-domain Multi-modal Few-shot Object Detection via Rich Text
Mar 24, 2024Cross-modal feature extraction and integration have led to steady performance improvements in few-shot learning tasks due to generating richer features. However, existing multi-modal object detection (MM-OD) methods degrade when facing significant domain-shift and are sample insufficient. We hypothesize that rich text information could more effectively help the model to build a knowledge relationship between the vision instance and its language description and can help mitigate domain shift. Specifically, we study the Cross-Domain few-shot generalization of MM-OD (CDMM-FSOD) and propose a meta-learning based multi-modal few-shot object detection method that utilizes rich text semantic information as an auxiliary modality to achieve domain adaptation in the context of FSOD. Our proposed network contains (i) a multi-modal feature aggregation module that aligns the vision and language support feature embeddings and (ii) a rich text semantic rectify module that utilizes bidirectional text feature generation to reinforce multi-modal feature alignment and thus to enhance the model's language understanding capability. We evaluate our model on common standard cross-domain object detection datasets and demonstrate that our approach considerably outperforms existing FSOD methods.
T-Rex2: Towards Generic Object Detection via Text-Visual Prompt Synergy
Mar 21, 2024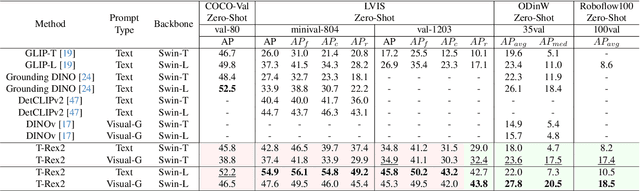


We present T-Rex2, a highly practical model for open-set object detection. Previous open-set object detection methods relying on text prompts effectively encapsulate the abstract concept of common objects, but struggle with rare or complex object representation due to data scarcity and descriptive limitations. Conversely, visual prompts excel in depicting novel objects through concrete visual examples, but fall short in conveying the abstract concept of objects as effectively as text prompts. Recognizing the complementary strengths and weaknesses of both text and visual prompts, we introduce T-Rex2 that synergizes both prompts within a single model through contrastive learning. T-Rex2 accepts inputs in diverse formats, including text prompts, visual prompts, and the combination of both, so that it can handle different scenarios by switching between the two prompt modalities. Comprehensive experiments demonstrate that T-Rex2 exhibits remarkable zero-shot object detection capabilities across a wide spectrum of scenarios. We show that text prompts and visual prompts can benefit from each other within the synergy, which is essential to cover massive and complicated real-world scenarios and pave the way towards generic object detection. Model API is now available at \url{https://github.com/IDEA-Research/T-Rex}.
Generative Region-Language Pretraining for Open-Ended Object Detection
Mar 15, 2024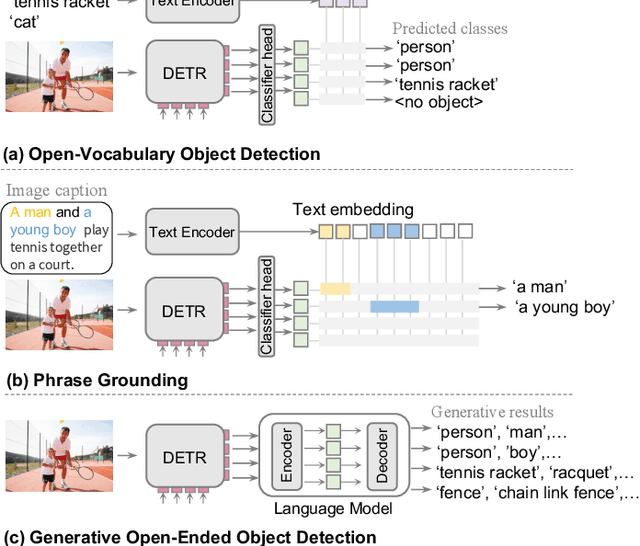


In recent research, significant attention has been devoted to the open-vocabulary object detection task, aiming to generalize beyond the limited number of classes labeled during training and detect objects described by arbitrary category names at inference. Compared with conventional object detection, open vocabulary object detection largely extends the object detection categories. However, it relies on calculating the similarity between image regions and a set of arbitrary category names with a pretrained vision-and-language model. This implies that, despite its open-set nature, the task still needs the predefined object categories during the inference stage. This raises the question: What if we do not have exact knowledge of object categories during inference? In this paper, we call such a new setting as generative open-ended object detection, which is a more general and practical problem. To address it, we formulate object detection as a generative problem and propose a simple framework named GenerateU, which can detect dense objects and generate their names in a free-form way. Particularly, we employ Deformable DETR as a region proposal generator with a language model translating visual regions to object names. To assess the free-form object detection task, we introduce an evaluation method designed to quantitatively measure the performance of generative outcomes. Extensive experiments demonstrate strong zero-shot detection performance of our GenerateU. For example, on the LVIS dataset, our GenerateU achieves comparable results to the open-vocabulary object detection method GLIP, even though the category names are not seen by GenerateU during inference. Code is available at: https:// github.com/FoundationVision/GenerateU .
The devil is in the object boundary: towards annotation-free instance segmentation using Foundation Models
Apr 18, 2024Foundation models, pre-trained on a large amount of data have demonstrated impressive zero-shot capabilities in various downstream tasks. However, in object detection and instance segmentation, two fundamental computer vision tasks heavily reliant on extensive human annotations, foundation models such as SAM and DINO struggle to achieve satisfactory performance. In this study, we reveal that the devil is in the object boundary, \textit{i.e.}, these foundation models fail to discern boundaries between individual objects. For the first time, we probe that CLIP, which has never accessed any instance-level annotations, can provide a highly beneficial and strong instance-level boundary prior in the clustering results of its particular intermediate layer. Following this surprising observation, we propose $\textbf{Zip}$ which $\textbf{Z}$ips up CL$\textbf{ip}$ and SAM in a novel classification-first-then-discovery pipeline, enabling annotation-free, complex-scene-capable, open-vocabulary object detection and instance segmentation. Our Zip significantly boosts SAM's mask AP on COCO dataset by 12.5% and establishes state-of-the-art performance in various settings, including training-free, self-training, and label-efficient finetuning. Furthermore, annotation-free Zip even achieves comparable performance to the best-performing open-vocabulary object detecters using base annotations. Code is released at https://github.com/ChengShiest/Zip-Your-CLIP
CPA-Enhancer: Chain-of-Thought Prompted Adaptive Enhancer for Object Detection under Unknown Degradations
Mar 22, 2024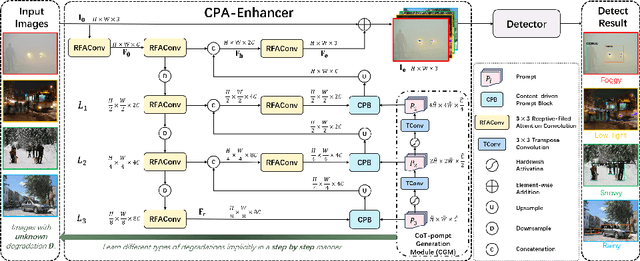
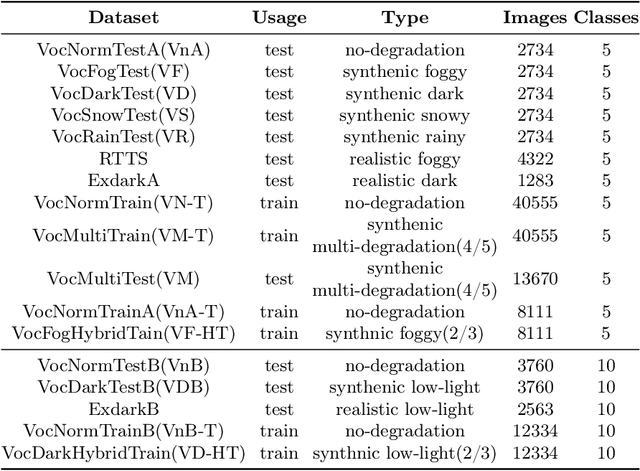
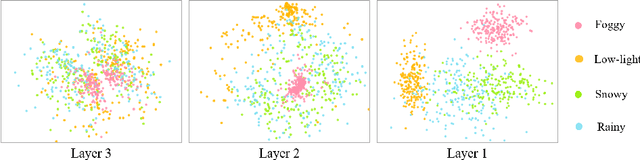
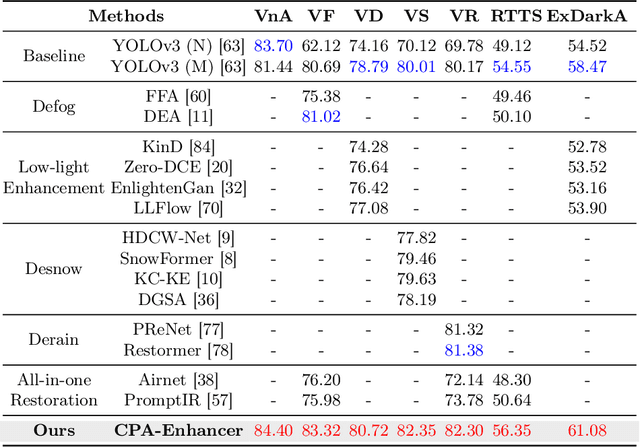
Object detection methods under known single degradations have been extensively investigated. However, existing approaches require prior knowledge of the degradation type and train a separate model for each, limiting their practical applications in unpredictable environments. To address this challenge, we propose a chain-of-thought (CoT) prompted adaptive enhancer, CPA-Enhancer, for object detection under unknown degradations. Specifically, CPA-Enhancer progressively adapts its enhancement strategy under the step-by-step guidance of CoT prompts, that encode degradation-related information. To the best of our knowledge, it's the first work that exploits CoT prompting for object detection tasks. Overall, CPA-Enhancer is a plug-and-play enhancement model that can be integrated into any generic detectors to achieve substantial gains on degraded images, without knowing the degradation type priorly. Experimental results demonstrate that CPA-Enhancer not only sets the new state of the art for object detection but also boosts the performance of other downstream vision tasks under unknown degradations.
UADA3D: Unsupervised Adversarial Domain Adaptation for 3D Object Detection with Sparse LiDAR and Large Domain Gaps
Mar 28, 2024In this study, we address a gap in existing unsupervised domain adaptation approaches on LiDAR-based 3D object detection, which have predominantly concentrated on adapting between established, high-density autonomous driving datasets. We focus on sparser point clouds, capturing scenarios from different perspectives: not just from vehicles on the road but also from mobile robots on sidewalks, which encounter significantly different environmental conditions and sensor configurations. We introduce Unsupervised Adversarial Domain Adaptation for 3D Object Detection (UADA3D). UADA3D does not depend on pre-trained source models or teacher-student architectures. Instead, it uses an adversarial approach to directly learn domain-invariant features. We demonstrate its efficacy in various adaptation scenarios, showing significant improvements in both self-driving car and mobile robot domains. Our code is open-source and will be available soon.
Modality Translation for Object Detection Adaptation Without Forgetting Prior Knowledge
Apr 01, 2024A common practice in deep learning consists of training large neural networks on massive datasets to perform accurately for different domains and tasks. While this methodology may work well in numerous application areas, it only applies across modalities due to a larger distribution shift in data captured using different sensors. This paper focuses on the problem of adapting a large object detection model to one or multiple modalities while being efficient. To do so, we propose ModTr as an alternative to the common approach of fine-tuning large models. ModTr consists of adapting the input with a small transformation network trained to minimize the detection loss directly. The original model can therefore work on the translated inputs without any further change or fine-tuning to its parameters. Experimental results on translating from IR to RGB images on two well-known datasets show that this simple ModTr approach provides detectors that can perform comparably or better than the standard fine-tuning without forgetting the original knowledge. This opens the doors to a more flexible and efficient service-based detection pipeline in which, instead of using a different detector for each modality, a unique and unaltered server is constantly running, where multiple modalities with the corresponding translations can query it. Code: https://github.com/heitorrapela/ModTr.