 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
YOLO-Ant: A Lightweight Detector via Depthwise Separable Convolutional and Large Kernel Design for Antenna Interference Source Detection
Feb 20, 2024
In the era of 5G communication, removing interference sources that affect communication is a resource-intensive task. The rapid development of computer vision has enabled unmanned aerial vehicles to perform various high-altitude detection tasks. Because the field of object detection for antenna interference sources has not been fully explored, this industry lacks dedicated learning samples and detection models for this specific task. In this article, an antenna dataset is created to address important antenna interference source detection issues and serves as the basis for subsequent research. We introduce YOLO-Ant, a lightweight CNN and transformer hybrid detector specifically designed for antenna interference source detection. Specifically, we initially formulated a lightweight design for the network depth and width, ensuring that subsequent investigations were conducted within a lightweight framework. Then, we propose a DSLK-Block module based on depthwise separable convolution and large convolution kernels to enhance the network's feature extraction ability, effectively improving small object detection. To address challenges such as complex backgrounds and large interclass differences in antenna detection, we construct DSLKVit-Block, a powerful feature extraction module that combines DSLK-Block and transformer structures. Considering both its lightweight design and accuracy, our method not only achieves optimal performance on the antenna dataset but also yields competitive results on public datasets.
High-Speed Detector For Low-Powered Devices In Aerial Grasping
Mar 01, 2024Autonomous aerial harvesting is a highly complex problem because it requires numerous interdisciplinary algorithms to be executed on mini low-powered computing devices. Object detection is one such algorithm that is compute-hungry. In this context, we make the following contributions: (i) Fast Fruit Detector (FFD), a resource-efficient, single-stage, and postprocessing-free object detector based on our novel latent object representation (LOR) module, query assignment, and prediction strategy. FFD achieves 100FPS@FP32 precision on the latest 10W NVIDIA Jetson-NX embedded device while co-existing with other time-critical sub-systems such as control, grasping, SLAM, a major achievement of this work. (ii) a method to generate vast amounts of training data without exhaustive manual labelling of fruit images since they consist of a large number of instances, which increases the labelling cost and time. (iii) an open-source fruit detection dataset having plenty of very small-sized instances that are difficult to detect. Our exhaustive evaluations on our and MinneApple dataset show that FFD, being only a single-scale detector, is more accurate than many representative detectors, e.g. FFD is better than single-scale Faster-RCNN by 10.7AP, multi-scale Faster-RCNN by 2.3AP, and better than latest single-scale YOLO-v8 by 8AP and multi-scale YOLO-v8 by 0.3 while being considerably faster.
Theoretically Achieving Continuous Representation of Oriented Bounding Boxes
Feb 29, 2024Considerable efforts have been devoted to Oriented Object Detection (OOD). However, one lasting issue regarding the discontinuity in Oriented Bounding Box (OBB) representation remains unresolved, which is an inherent bottleneck for extant OOD methods. This paper endeavors to completely solve this issue in a theoretically guaranteed manner and puts an end to the ad-hoc efforts in this direction. Prior studies typically can only address one of the two cases of discontinuity: rotation and aspect ratio, and often inadvertently introduce decoding discontinuity, e.g. Decoding Incompleteness (DI) and Decoding Ambiguity (DA) as discussed in literature. Specifically, we propose a novel representation method called Continuous OBB (COBB), which can be readily integrated into existing detectors e.g. Faster-RCNN as a plugin. It can theoretically ensure continuity in bounding box regression which to our best knowledge, has not been achieved in literature for rectangle-based object representation. For fairness and transparency of experiments, we have developed a modularized benchmark based on the open-source deep learning framework Jittor's detection toolbox JDet for OOD evaluation. On the popular DOTA dataset, by integrating Faster-RCNN as the same baseline model, our new method outperforms the peer method Gliding Vertex by 1.13% mAP50 (relative improvement 1.54%), and 2.46% mAP75 (relative improvement 5.91%), without any tricks.
Customizing Visual-Language Foundation Models for Multi-modal Anomaly Detection and Reasoning
Mar 17, 2024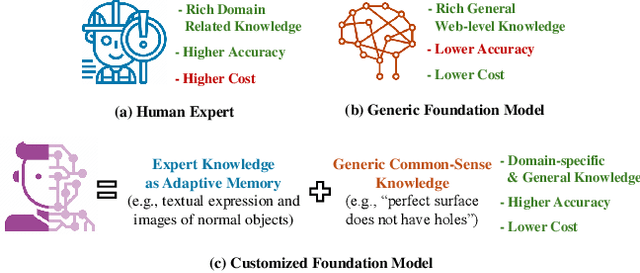
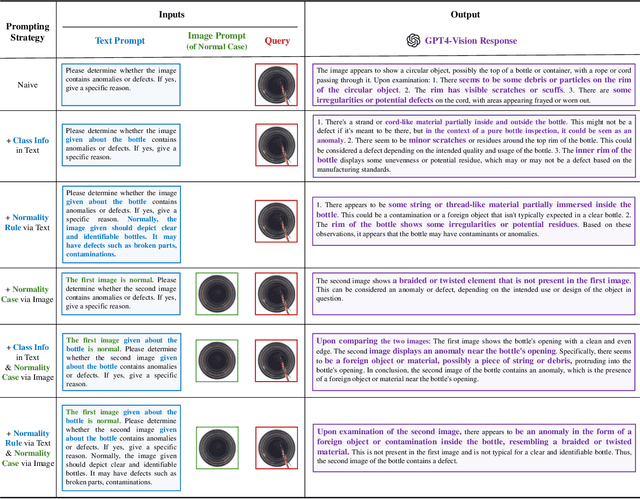

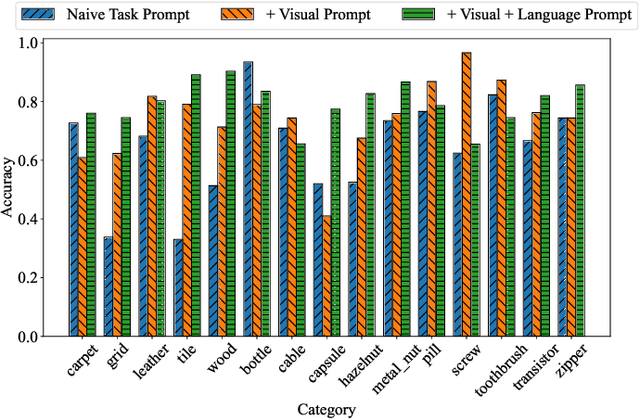
Anomaly detection is vital in various industrial scenarios, including the identification of unusual patterns in production lines and the detection of manufacturing defects for quality control. Existing techniques tend to be specialized in individual scenarios and lack generalization capacities. In this study, we aim to develop a generic anomaly detection model applicable across multiple scenarios. To achieve this, we customize generic visual-language foundation models that possess extensive knowledge and robust reasoning abilities into anomaly detectors and reasoners. Specifically, we introduce a multi-modal prompting strategy that incorporates domain knowledge from experts as conditions to guide the models. Our approach considers multi-modal prompt types, including task descriptions, class context, normality rules, and reference images. In addition, we unify the input representation of multi-modality into a 2D image format, enabling multi-modal anomaly detection and reasoning. Our preliminary studies demonstrate that combining visual and language prompts as conditions for customizing the models enhances anomaly detection performance. The customized models showcase the ability to detect anomalies across different data modalities such as images and point clouds. Qualitative case studies further highlight the anomaly detection and reasoning capabilities, particularly for multi-object scenes and temporal data. Our code is available at https://github.com/Xiaohao-Xu/Customizable-VLM.
A Comprehensive Survey of Convolutions in Deep Learning: Applications, Challenges, and Future Trends
Feb 28, 2024In today's digital age, Convolutional Neural Networks (CNNs), a subset of Deep Learning (DL), are widely used for various computer vision tasks such as image classification, object detection, and image segmentation. There are numerous types of CNNs designed to meet specific needs and requirements, including 1D, 2D, and 3D CNNs, as well as dilated, grouped, attention, depthwise convolutions, and NAS, among others. Each type of CNN has its unique structure and characteristics, making it suitable for specific tasks. It's crucial to gain a thorough understanding and perform a comparative analysis of these different CNN types to understand their strengths and weaknesses. Furthermore, studying the performance, limitations, and practical applications of each type of CNN can aid in the development of new and improved architectures in the future. We also dive into the platforms and frameworks that researchers utilize for their research or development from various perspectives. Additionally, we explore the main research fields of CNN like 6D vision, generative models, and meta-learning. This survey paper provides a comprehensive examination and comparison of various CNN architectures, highlighting their architectural differences and emphasizing their respective advantages, disadvantages, applications, challenges, and future trends.
LF Tracy: A Unified Single-Pipeline Approach for Salient Object Detection in Light Field Cameras
Jan 30, 2024Leveraging the rich information extracted from light field (LF) cameras is instrumental for dense prediction tasks. However, adapting light field data to enhance Salient Object Detection (SOD) still follows the traditional RGB methods and remains under-explored in the community. Previous approaches predominantly employ a custom two-stream design to discover the implicit angular feature within light field cameras, leading to significant information isolation between different LF representations. In this study, we propose an efficient paradigm (LF Tracy) to address this limitation. We eschew the conventional specialized fusion and decoder architecture for a dual-stream backbone in favor of a unified, single-pipeline approach. This comprises firstly a simple yet effective data augmentation strategy called MixLD to bridge the connection of spatial, depth, and implicit angular information under different LF representations. A highly efficient information aggregation (IA) module is then introduced to boost asymmetric feature-wise information fusion. Owing to this innovative approach, our model surpasses the existing state-of-the-art methods, particularly demonstrating a 23% improvement over previous results on the latest large-scale PKU dataset. By utilizing only 28.9M parameters, the model achieves a 10% increase in accuracy with 3M additional parameters compared to its backbone using RGB images and an 86% rise to its backbone using LF images. The source code will be made publicly available at https://github.com/FeiBryantkit/LF-Tracy.
LiSTA: Geometric Object-Based Change Detection in Cluttered Environments
Mar 05, 2024
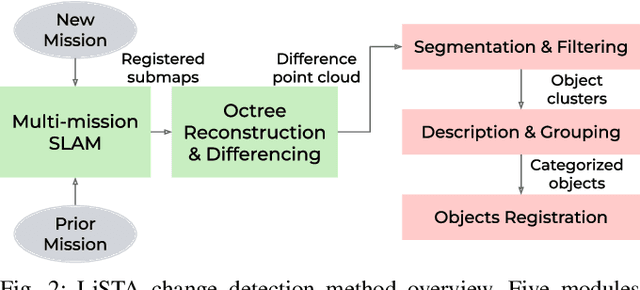
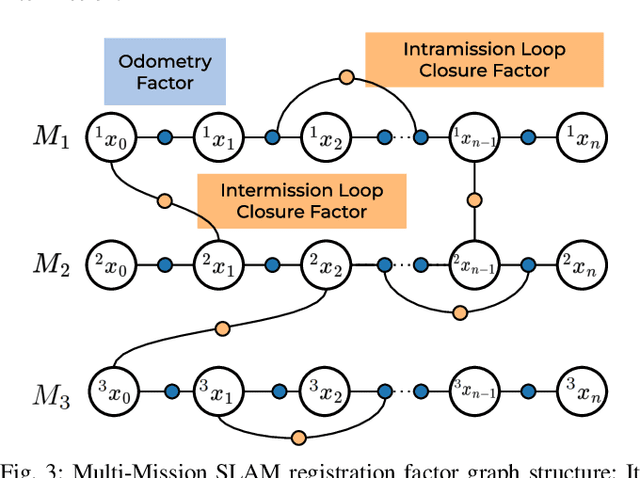

We present LiSTA (LiDAR Spatio-Temporal Analysis), a system to detect probabilistic object-level change over time using multi-mission SLAM. Many applications require such a system, including construction, robotic navigation, long-term autonomy, and environmental monitoring. We focus on the semi-static scenario where objects are added, subtracted, or changed in position over weeks or months. Our system combines multi-mission LiDAR SLAM, volumetric differencing, object instance description, and correspondence grouping using learned descriptors to keep track of an open set of objects. Object correspondences between missions are determined by clustering the object's learned descriptors. We demonstrate our approach using datasets collected in a simulated environment and a real-world dataset captured using a LiDAR system mounted on a quadruped robot monitoring an industrial facility containing static, semi-static, and dynamic objects. Our method demonstrates superior performance in detecting changes in semi-static environments compared to existing methods.
Prompt-Driven Dynamic Object-Centric Learning for Single Domain Generalization
Feb 28, 2024Single-domain generalization aims to learn a model from single source domain data to achieve generalized performance on other unseen target domains. Existing works primarily focus on improving the generalization ability of static networks. However, static networks are unable to dynamically adapt to the diverse variations in different image scenes, leading to limited generalization capability. Different scenes exhibit varying levels of complexity, and the complexity of images further varies significantly in cross-domain scenarios. In this paper, we propose a dynamic object-centric perception network based on prompt learning, aiming to adapt to the variations in image complexity. Specifically, we propose an object-centric gating module based on prompt learning to focus attention on the object-centric features guided by the various scene prompts. Then, with the object-centric gating masks, the dynamic selective module dynamically selects highly correlated feature regions in both spatial and channel dimensions enabling the model to adaptively perceive object-centric relevant features, thereby enhancing the generalization capability. Extensive experiments were conducted on single-domain generalization tasks in image classification and object detection. The experimental results demonstrate that our approach outperforms state-of-the-art methods, which validates the effectiveness and generally of our proposed method.
Credible Teacher for Semi-Supervised Object Detection in Open Scene
Jan 03, 2024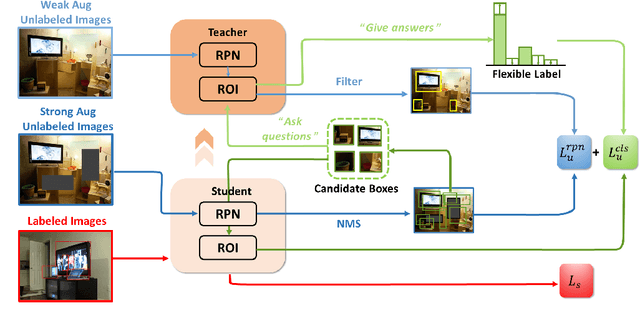
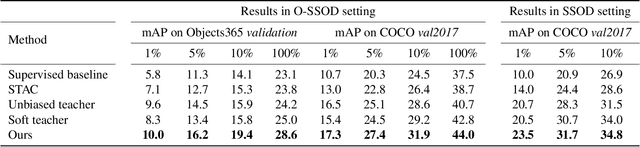
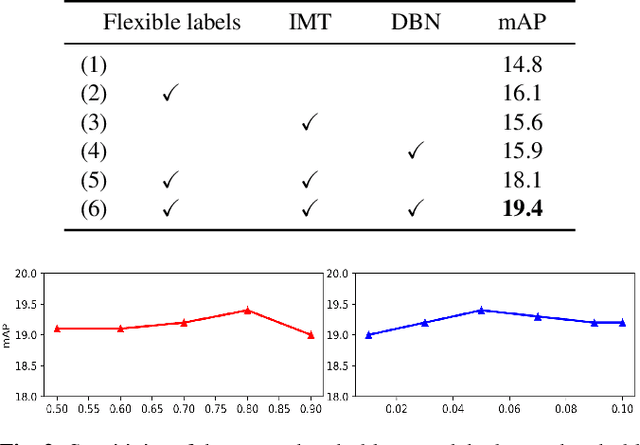
Semi-Supervised Object Detection (SSOD) has achieved resounding success by leveraging unlabeled data to improve detection performance. However, in Open Scene Semi-Supervised Object Detection (O-SSOD), unlabeled data may contains unknown objects not observed in the labeled data, which will increase uncertainty in the model's predictions for known objects. It is detrimental to the current methods that mainly rely on self-training, as more uncertainty leads to the lower localization and classification precision of pseudo labels. To this end, we propose Credible Teacher, an end-to-end framework. Credible Teacher adopts an interactive teaching mechanism using flexible labels to prevent uncertain pseudo labels from misleading the model and gradually reduces its uncertainty through the guidance of other credible pseudo labels. Empirical results have demonstrated our method effectively restrains the adverse effect caused by O-SSOD and significantly outperforms existing counterparts.
SDGE: Stereo Guided Depth Estimation for 360$^\circ$ Camera Sets
Feb 29, 2024Depth estimation is a critical technology in autonomous driving, and multi-camera systems are often used to achieve a 360$^\circ$ perception. These 360$^\circ$ camera sets often have limited or low-quality overlap regions, making multi-view stereo methods infeasible for the entire image. Alternatively, monocular methods may not produce consistent cross-view predictions. To address these issues, we propose the Stereo Guided Depth Estimation (SGDE) method, which enhances depth estimation of the full image by explicitly utilizing multi-view stereo results on the overlap. We suggest building virtual pinhole cameras to resolve the distortion problem of fisheye cameras and unify the processing for the two types of 360$^\circ$ cameras. For handling the varying noise on camera poses caused by unstable movement, the approach employs a self-calibration method to obtain highly accurate relative poses of the adjacent cameras with minor overlap. These enable the use of robust stereo methods to obtain high-quality depth prior in the overlap region. This prior serves not only as an additional input but also as pseudo-labels that enhance the accuracy of depth estimation methods and improve cross-view prediction consistency. The effectiveness of SGDE is evaluated on one fisheye camera dataset, Synthetic Urban, and two pinhole camera datasets, DDAD and nuScenes. Our experiments demonstrate that SGDE is effective for both supervised and self-supervised depth estimation, and highlight the potential of our method for advancing downstream autonomous driving technologies, such as 3D object detection and occupancy prediction.