 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
YOLO-World: Real-Time Open-Vocabulary Object Detection
Jan 30, 2024
The You Only Look Once (YOLO) series of detectors have established themselves as efficient and practical tools. However, their reliance on predefined and trained object categories limits their applicability in open scenarios. Addressing this limitation, we introduce YOLO-World, an innovative approach that enhances YOLO with open-vocabulary detection capabilities through vision-language modeling and pre-training on large-scale datasets. Specifically, we propose a new Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) and region-text contrastive loss to facilitate the interaction between visual and linguistic information. Our method excels in detecting a wide range of objects in a zero-shot manner with high efficiency. On the challenging LVIS dataset, YOLO-World achieves 35.4 AP with 52.0 FPS on V100, which outperforms many state-of-the-art methods in terms of both accuracy and speed. Furthermore, the fine-tuned YOLO-World achieves remarkable performance on several downstream tasks, including object detection and open-vocabulary instance segmentation.
Do Object Detection Localization Errors Affect Human Performance and Trust?
Jan 31, 2024Bounding boxes are often used to communicate automatic object detection results to humans, aiding humans in a multitude of tasks. We investigate the relationship between bounding box localization errors and human task performance. We use observer performance studies on a visual multi-object counting task to measure both human trust and performance with different levels of bounding box accuracy. The results show that localization errors have no significant impact on human accuracy or trust in the system. Recall and precision errors impact both human performance and trust, suggesting that optimizing algorithms based on the F1 score is more beneficial in human-computer tasks. Lastly, the paper offers an improvement on bounding boxes in multi-object counting tasks with center dots, showing improved performance and better resilience to localization inaccuracy.
Capacity Constraint Analysis Using Object Detection for Smart Manufacturing
Jan 31, 2024The increasing popularity of Deep Learning (DL) based Object Detection (OD) methods and their real-world applications have opened new venues in smart manufacturing. Traditional industries struck by capacity constraints after Coronavirus Disease (COVID-19) require non-invasive methods for in-depth operations' analysis to optimize and increase their revenue. In this study, we have initially developed a Convolutional Neural Network (CNN) based OD model to tackle this issue. This model is trained to accurately identify the presence of chairs and individuals on the production floor. The identified objects are then passed to the CNN based tracker, which tracks them throughout their life cycle in the workstation. The extracted meta-data is further processed through a novel framework for the capacity constraint analysis. We identified that the Station C is only 70.6% productive through 6 months. Additionally, the time spent at each station is recorded and aggregated for each object. This data proves helpful in conducting annual audits and effectively managing labor and material over time.
Object Detectors in the Open Environment: Challenges, Solutions, and Outlook
Mar 26, 2024With the emergence of foundation models, deep learning-based object detectors have shown practical usability in closed set scenarios. However, for real-world tasks, object detectors often operate in open environments, where crucial factors (e.g., data distribution, objective) that influence model learning are often changing. The dynamic and intricate nature of the open environment poses novel and formidable challenges to object detectors. Unfortunately, current research on object detectors in open environments lacks a comprehensive analysis of their distinctive characteristics, challenges, and corresponding solutions, which hinders their secure deployment in critical real-world scenarios. This paper aims to bridge this gap by conducting a comprehensive review and analysis of object detectors in open environments. We initially identified limitations of key structural components within the existing detection pipeline and propose the open environment object detector challenge framework that includes four quadrants (i.e., out-of-domain, out-of-category, robust learning, and incremental learning) based on the dimensions of the data / target changes. For each quadrant of challenges in the proposed framework, we present a detailed description and systematic analysis of the overarching goals and core difficulties, systematically review the corresponding solutions, and benchmark their performance over multiple widely adopted datasets. In addition, we engage in a discussion of open problems and potential avenues for future research. This paper aims to provide a fresh, comprehensive, and systematic understanding of the challenges and solutions associated with open-environment object detectors, thus catalyzing the development of more solid applications in real-world scenarios. A project related to this survey can be found at https://github.com/LiangSiyuan21/OEOD_Survey.
STAR: Shape-focused Texture Agnostic Representations for Improved Object Detection and 6D Pose Estimation
Feb 07, 2024Recent advances in machine learning have greatly benefited object detection and 6D pose estimation for robotic grasping. However, textureless and metallic objects still pose a significant challenge due to fewer visual cues and the texture bias of CNNs. To address this issue, we propose a texture-agnostic approach that focuses on learning from CAD models and emphasizes object shape features. To achieve a focus on learning shape features, the textures are randomized during the rendering of the training data. By treating the texture as noise, the need for real-world object instances or their final appearance during training data generation is eliminated. The TLESS and ITODD datasets, specifically created for industrial settings in robotics and featuring textureless and metallic objects, were used for evaluation. Texture agnosticity also increases the robustness against image perturbations such as imaging noise, motion blur, and brightness changes, which are common in robotics applications. Code and datasets are publicly available at github.com/hoenigpeter/randomized_texturing.
Improve accessibility for Low Vision and Blind people using Machine Learning and Computer Vision
Mar 24, 2024With the ever-growing expansion of mobile technology worldwide, there is an increasing need for accommodation for those who are disabled. This project explores how machine learning and computer vision could be utilized to improve accessibility for people with visual impairments. There have been many attempts to develop various software that would improve accessibility in the day-to-day lives of blind people. However, applications on the market have low accuracy and only provide audio feedback. This project will concentrate on building a mobile application that helps blind people to orient in space by receiving audio and haptic feedback, e.g. vibrations, about their surroundings in real-time. The mobile application will have 3 main features. The initial feature is scanning text from the camera and reading it to a user. This feature can be used on paper with text, in the environment, and on road signs. The second feature is detecting objects around the user, and providing audio feedback about those objects. It also includes providing the description of the objects and their location, and giving haptic feedback if the user is too close to an object. The last feature is currency detection which provides a total amount of currency value to the user via the camera.
Not just Birds and Cars: Generic, Scalable and Explainable Models for Professional Visual Recognition
Mar 08, 2024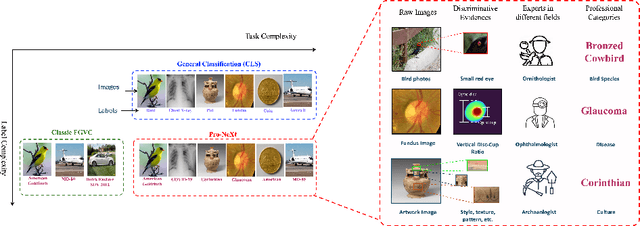
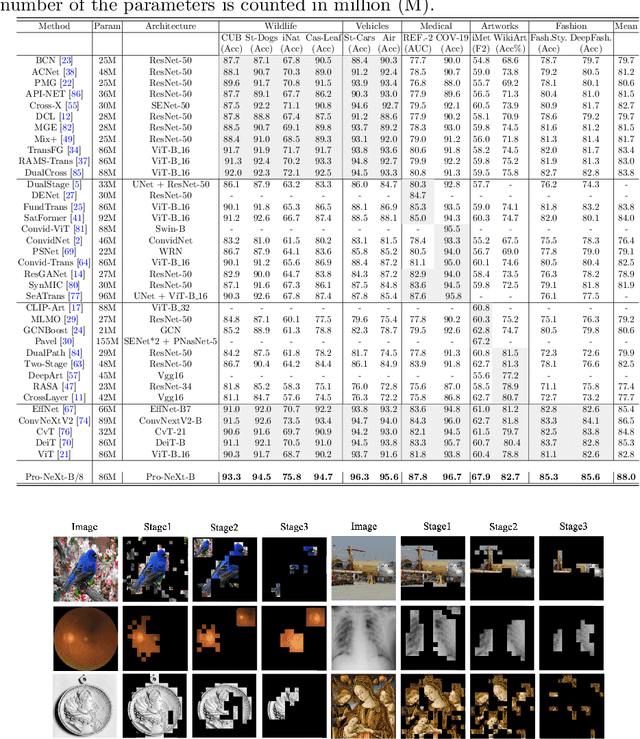
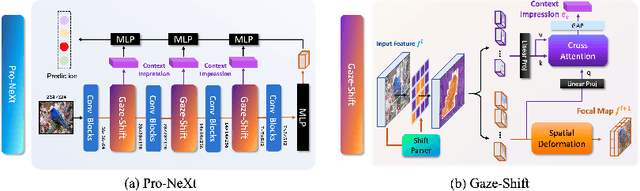
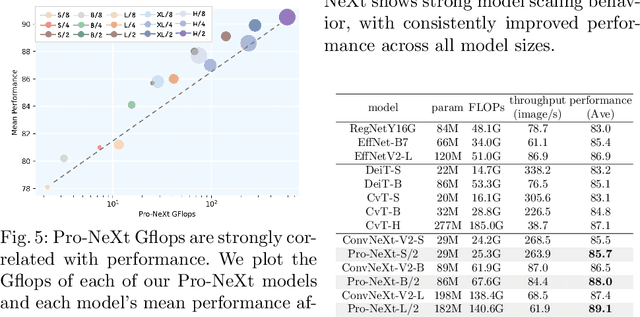
Some visual recognition tasks are more challenging then the general ones as they require professional categories of images. The previous efforts, like fine-grained vision classification, primarily introduced models tailored to specific tasks, like identifying bird species or car brands with limited scalability and generalizability. This paper aims to design a scalable and explainable model to solve Professional Visual Recognition tasks from a generic standpoint. We introduce a biologically-inspired structure named Pro-NeXt and reveal that Pro-NeXt exhibits substantial generalizability across diverse professional fields such as fashion, medicine, and art-areas previously considered disparate. Our basic-sized Pro-NeXt-B surpasses all preceding task-specific models across 12 distinct datasets within 5 diverse domains. Furthermore, we find its good scaling property that scaling up Pro-NeXt in depth and width with increasing GFlops can consistently enhances its accuracy. Beyond scalability and adaptability, the intermediate features of Pro-NeXt achieve reliable object detection and segmentation performance without extra training, highlighting its solid explainability. We will release the code to foster further research in this area.
Semantic-Aware and Goal-Oriented Communications for Object Detection in Wireless End-to-End Image Transmission
Feb 01, 2024Semantic communication is focused on optimizing the exchange of information by transmitting only the most relevant data required to convey the intended message to the receiver and achieve the desired communication goal. For example, if we consider images as the information and the goal of the communication is object detection at the receiver side, the semantic of information would be the objects in each image. Therefore, by only transferring the semantics of images we can achieve the communication goal. In this paper, we propose a design framework for implementing semantic-aware and goal-oriented communication of images. To achieve this, we first define the baseline problem as a set of mathematical problems that can be optimized to improve the efficiency and effectiveness of the communication system. We consider two scenarios in which either the data rate or the error at the receiver is the limiting constraint. Our proposed system model and solution is inspired by the concept of auto-encoders, where the encoder and the decoder are respectively implemented at the transmitter and receiver to extract semantic information for specific object detection goals. Our numerical results validate the proposed design framework to achieve low error or near-optimal in a goal-oriented communication system while reducing the amount of data transfers.
PillarGen: Enhancing Radar Point Cloud Density and Quality via Pillar-based Point Generation Network
Mar 08, 2024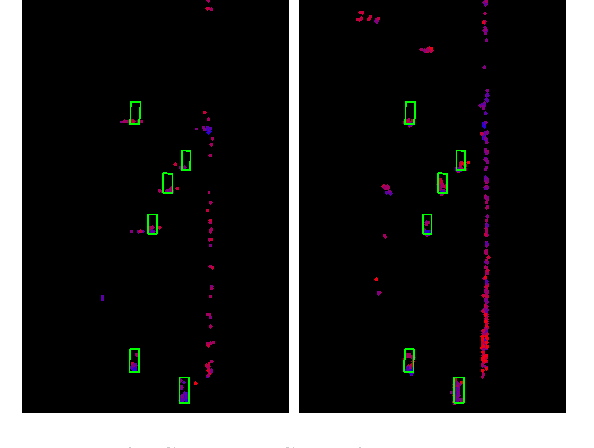
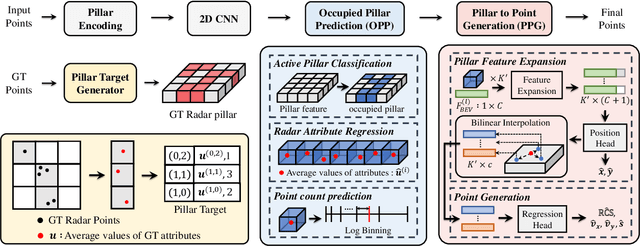
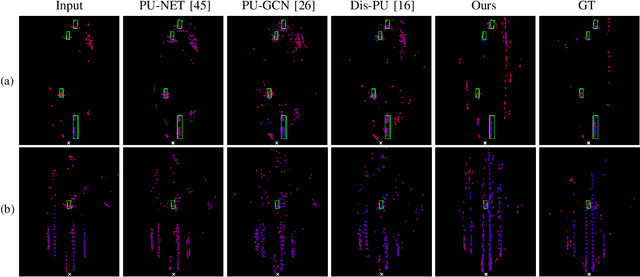
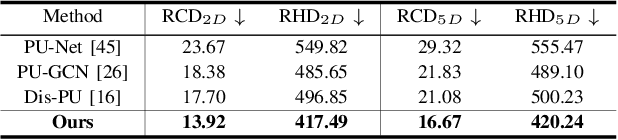
In this paper, we present a novel point generation model, referred to as Pillar-based Point Generation Network (PillarGen), which facilitates the transformation of point clouds from one domain into another. PillarGen can produce synthetic point clouds with enhanced density and quality based on the provided input point clouds. The PillarGen model performs the following three steps: 1) pillar encoding, 2) Occupied Pillar Prediction (OPP), and 3) Pillar to Point Generation (PPG). The input point clouds are encoded using a pillar grid structure to generate pillar features. Then, OPP determines the active pillars used for point generation and predicts the center of points and the number of points to be generated for each active pillar. PPG generates the synthetic points for each active pillar based on the information provided by OPP. We evaluate the performance of PillarGen using our proprietary radar dataset, focusing on enhancing the density and quality of short-range radar data using the long-range radar data as supervision. Our experiments demonstrate that PillarGen outperforms traditional point upsampling methods in quantitative and qualitative measures. We also confirm that when PillarGen is incorporated into bird's eye view object detection, a significant improvement in detection accuracy is achieved.
ActiveAnno3D -- An Active Learning Framework for Multi-Modal 3D Object Detection
Feb 05, 2024The curation of large-scale datasets is still costly and requires much time and resources. Data is often manually labeled, and the challenge of creating high-quality datasets remains. In this work, we fill the research gap using active learning for multi-modal 3D object detection. We propose ActiveAnno3D, an active learning framework to select data samples for labeling that are of maximum informativeness for training. We explore various continuous training methods and integrate the most efficient method regarding computational demand and detection performance. Furthermore, we perform extensive experiments and ablation studies with BEVFusion and PV-RCNN on the nuScenes and TUM Traffic Intersection dataset. We show that we can achieve almost the same performance with PV-RCNN and the entropy-based query strategy when using only half of the training data (77.25 mAP compared to 83.50 mAP) of the TUM Traffic Intersection dataset. BEVFusion achieved an mAP of 64.31 when using half of the training data and 75.0 mAP when using the complete nuScenes dataset. We integrate our active learning framework into the proAnno labeling tool to enable AI-assisted data selection and labeling and minimize the labeling costs. Finally, we provide code, weights, and visualization results on our website: https://active3d-framework.github.io/active3d-framework.