 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Genetic Learning for Designing Sim-to-Real Data Augmentations
Mar 11, 2024
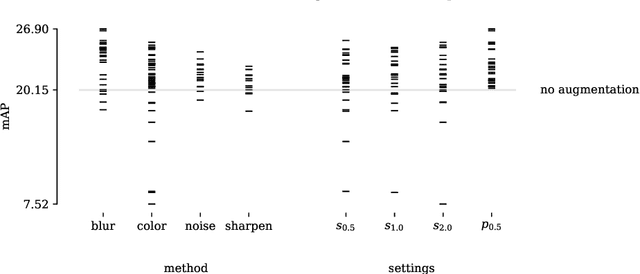
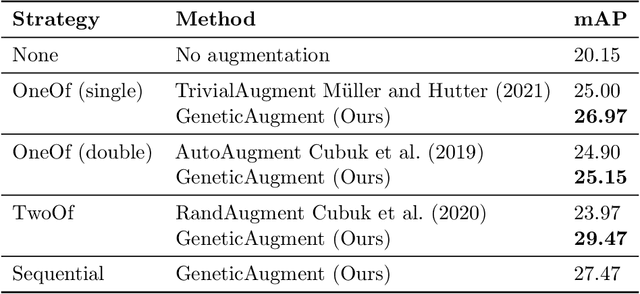
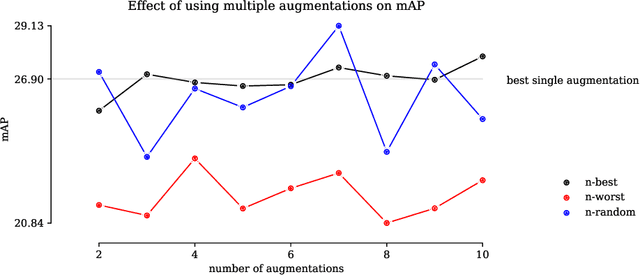

Data augmentations are useful in closing the sim-to-real domain gap when training on synthetic data. This is because they widen the training data distribution, thus encouraging the model to generalize better to other domains. Many image augmentation techniques exist, parametrized by different settings, such as strength and probability. This leads to a large space of different possible augmentation policies. Some policies work better than others for overcoming the sim-to-real gap for specific datasets, and it is unclear why. This paper presents two different interpretable metrics that can be combined to predict how well a certain augmentation policy will work for a specific sim-to-real setting, focusing on object detection. We validate our metrics by training many models with different augmentation policies and showing a strong correlation with performance on real data. Additionally, we introduce GeneticAugment, a genetic programming method that can leverage these metrics to automatically design an augmentation policy for a specific dataset without needing to train a model.
$V_kD:$ Improving Knowledge Distillation using Orthogonal Projections
Mar 10, 2024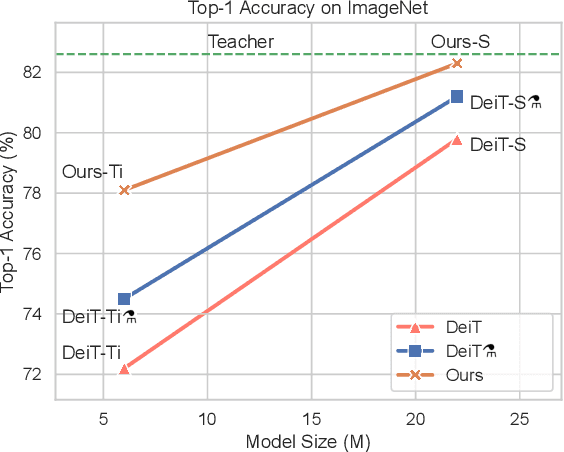
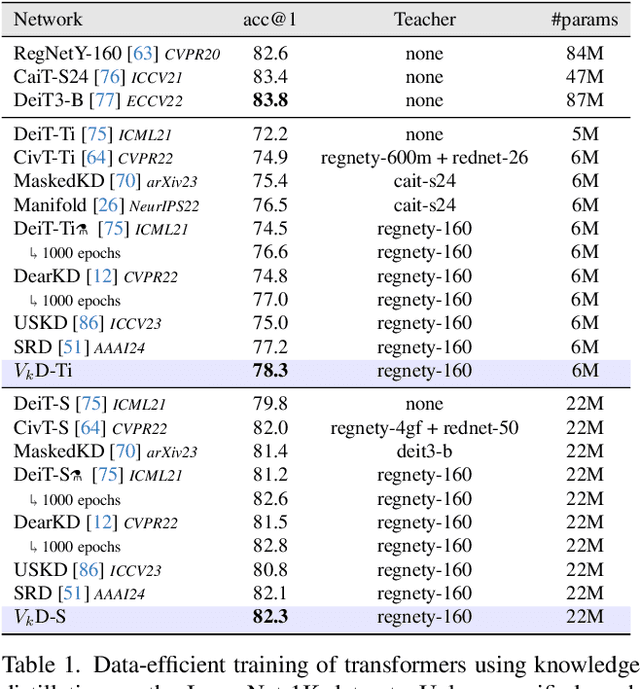
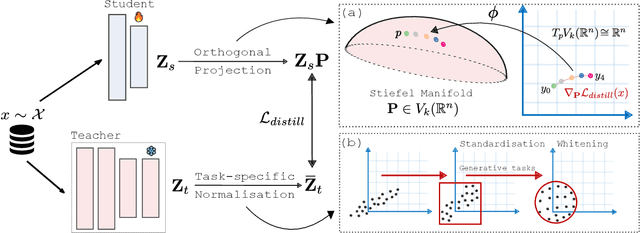
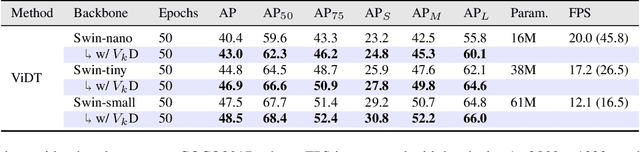
Knowledge distillation is an effective method for training small and efficient deep learning models. However, the efficacy of a single method can degenerate when transferring to other tasks, modalities, or even other architectures. To address this limitation, we propose a novel constrained feature distillation method. This method is derived from a small set of core principles, which results in two emerging components: an orthogonal projection and a task-specific normalisation. Equipped with both of these components, our transformer models can outperform all previous methods on ImageNet and reach up to a 4.4% relative improvement over the previous state-of-the-art methods. To further demonstrate the generality of our method, we apply it to object detection and image generation, whereby we obtain consistent and substantial performance improvements over state-of-the-art. Code and models are publicly available: https://github.com/roymiles/vkd
Poly Kernel Inception Network for Remote Sensing Detection
Mar 10, 2024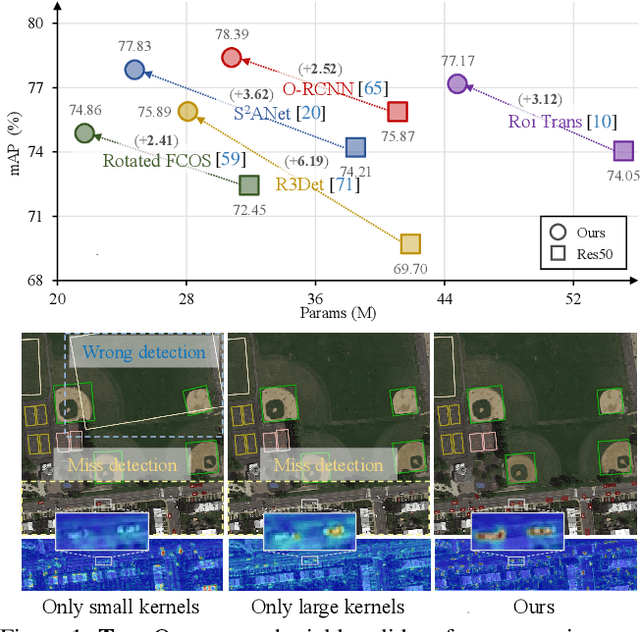
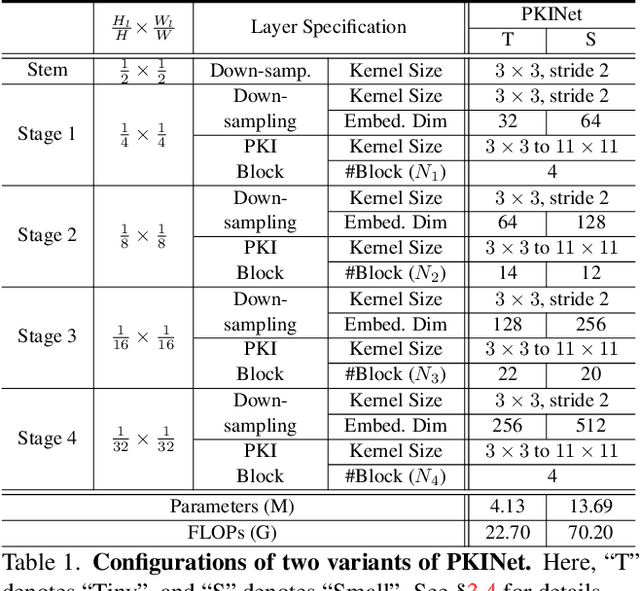
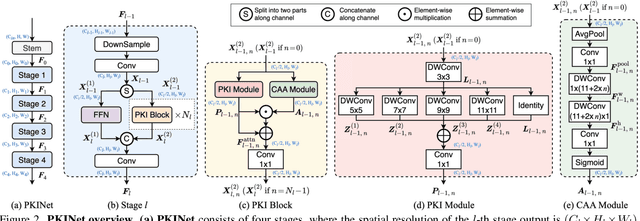
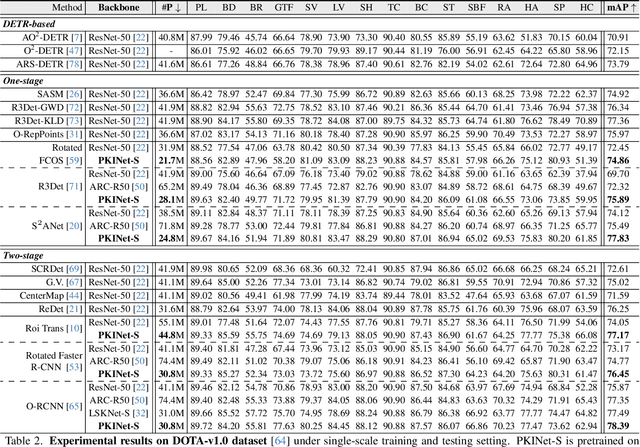
Object detection in remote sensing images (RSIs) often suffers from several increasing challenges, including the large variation in object scales and the diverse-ranging context. Prior methods tried to address these challenges by expanding the spatial receptive field of the backbone, either through large-kernel convolution or dilated convolution. However, the former typically introduces considerable background noise, while the latter risks generating overly sparse feature representations. In this paper, we introduce the Poly Kernel Inception Network (PKINet) to handle the above challenges. PKINet employs multi-scale convolution kernels without dilation to extract object features of varying scales and capture local context. In addition, a Context Anchor Attention (CAA) module is introduced in parallel to capture long-range contextual information. These two components work jointly to advance the performance of PKINet on four challenging remote sensing detection benchmarks, namely DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R.
FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything
Feb 29, 2024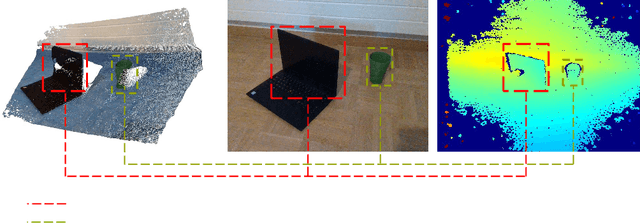



In the realm of computer vision, the integration of advanced techniques into the processing of RGB-D camera inputs poses a significant challenge, given the inherent complexities arising from diverse environmental conditions and varying object appearances. Therefore, this paper introduces FusionVision, an exhaustive pipeline adapted for the robust 3D segmentation of objects in RGB-D imagery. Traditional computer vision systems face limitations in simultaneously capturing precise object boundaries and achieving high-precision object detection on depth map as they are mainly proposed for RGB cameras. To address this challenge, FusionVision adopts an integrated approach by merging state-of-the-art object detection techniques, with advanced instance segmentation methods. The integration of these components enables a holistic (unified analysis of information obtained from both color \textit{RGB} and depth \textit{D} channels) interpretation of RGB-D data, facilitating the extraction of comprehensive and accurate object information. The proposed FusionVision pipeline employs YOLO for identifying objects within the RGB image domain. Subsequently, FastSAM, an innovative semantic segmentation model, is applied to delineate object boundaries, yielding refined segmentation masks. The synergy between these components and their integration into 3D scene understanding ensures a cohesive fusion of object detection and segmentation, enhancing overall precision in 3D object segmentation. The code and pre-trained models are publicly available at https://github.com/safouaneelg/FusionVision/.
YOLO-World: Real-Time Open-Vocabulary Object Detection
Feb 02, 2024The You Only Look Once (YOLO) series of detectors have established themselves as efficient and practical tools. However, their reliance on predefined and trained object categories limits their applicability in open scenarios. Addressing this limitation, we introduce YOLO-World, an innovative approach that enhances YOLO with open-vocabulary detection capabilities through vision-language modeling and pre-training on large-scale datasets. Specifically, we propose a new Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) and region-text contrastive loss to facilitate the interaction between visual and linguistic information. Our method excels in detecting a wide range of objects in a zero-shot manner with high efficiency. On the challenging LVIS dataset, YOLO-World achieves 35.4 AP with 52.0 FPS on V100, which outperforms many state-of-the-art methods in terms of both accuracy and speed. Furthermore, the fine-tuned YOLO-World achieves remarkable performance on several downstream tasks, including object detection and open-vocabulary instance segmentation.
Source-free Domain Adaptive Object Detection in Remote Sensing Images
Jan 31, 2024Recent studies have used unsupervised domain adaptive object detection (UDAOD) methods to bridge the domain gap in remote sensing (RS) images. However, UDAOD methods typically assume that the source domain data can be accessed during the domain adaptation process. This setting is often impractical in the real world due to RS data privacy and transmission difficulty. To address this challenge, we propose a practical source-free object detection (SFOD) setting for RS images, which aims to perform target domain adaptation using only the source pre-trained model. We propose a new SFOD method for RS images consisting of two parts: perturbed domain generation and alignment. The proposed multilevel perturbation constructs the perturbed domain in a simple yet efficient form by perturbing the domain-variant features at the image level and feature level according to the color and style bias. The proposed multilevel alignment calculates feature and label consistency between the perturbed domain and the target domain across the teacher-student network, and introduces the distillation of feature prototype to mitigate the noise of pseudo-labels. By requiring the detector to be consistent in the perturbed domain and the target domain, the detector is forced to focus on domaininvariant features. Extensive results of three synthetic-to-real experiments and three cross-sensor experiments have validated the effectiveness of our method which does not require access to source domain RS images. Furthermore, experiments on computer vision datasets show that our method can be extended to other fields as well. Our code will be available at: https://weixliu.github.io/ .
You Only Look Bottom-Up for Monocular 3D Object Detection
Jan 27, 2024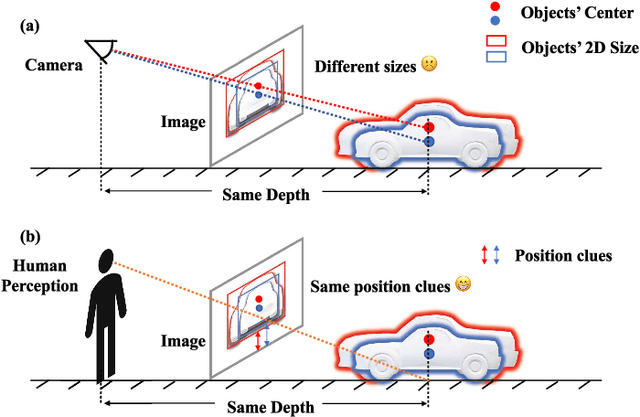
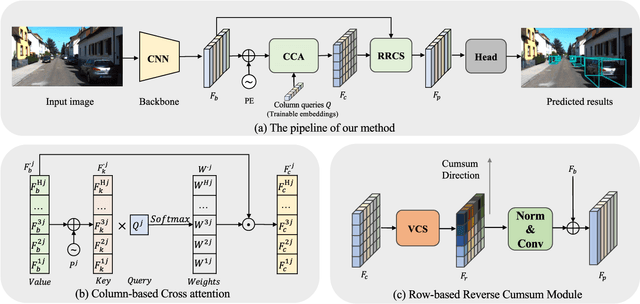
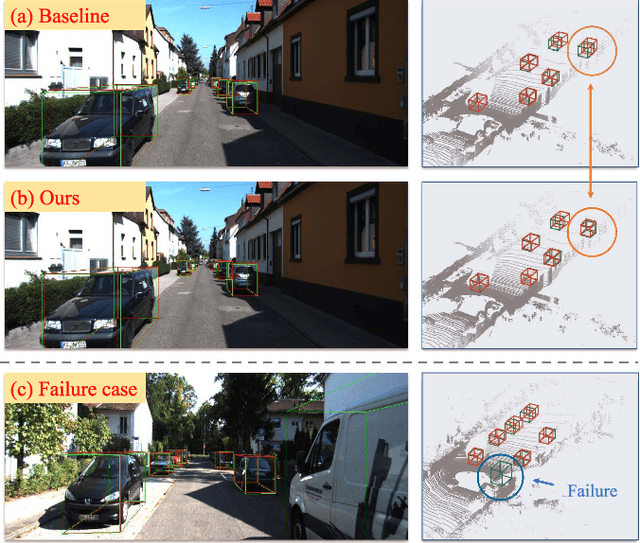
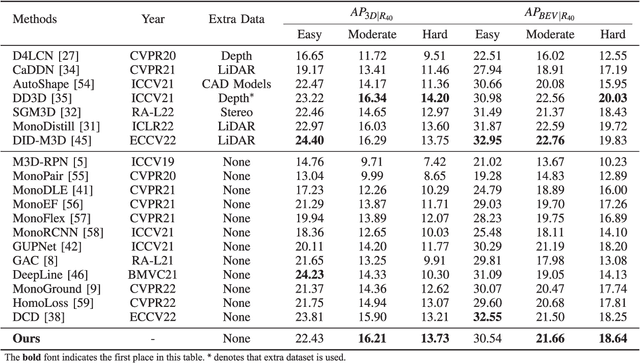
Monocular 3D Object Detection is an essential task for autonomous driving. Meanwhile, accurate 3D object detection from pure images is very challenging due to the loss of depth information. Most existing image-based methods infer objects' location in 3D space based on their 2D sizes on the image plane, which usually ignores the intrinsic position clues from images, leading to unsatisfactory performances. Motivated by the fact that humans could leverage the bottom-up positional clues to locate objects in 3D space from a single image, in this paper, we explore the position modeling from the image feature column and propose a new method named You Only Look Bottum-Up (YOLOBU). Specifically, our YOLOBU leverages Column-based Cross Attention to determine how much a pixel contributes to pixels above it. Next, the Row-based Reverse Cumulative Sum (RRCS) is introduced to build the connections of pixels in the bottom-up direction. Our YOLOBU fully explores the position clues for monocular 3D detection via building the relationship of pixels from the bottom-up way. Extensive experiments on the KITTI dataset demonstrate the effectiveness and superiority of our method.
From Blurry to Brilliant Detection: YOLOv5-Based Aerial Object Detection with Super Resolution
Jan 26, 2024The demand for accurate object detection in aerial imagery has surged with the widespread use of drones and satellite technology. Traditional object detection models, trained on datasets biased towards large objects, struggle to perform optimally in aerial scenarios where small, densely clustered objects are prevalent. To address this challenge, we present an innovative approach that combines super-resolution and an adapted lightweight YOLOv5 architecture. We employ a range of datasets, including VisDrone-2023, SeaDroneSee, VEDAI, and NWPU VHR-10, to evaluate our model's performance. Our Super Resolved YOLOv5 architecture features Transformer encoder blocks, allowing the model to capture global context and context information, leading to improved detection results, especially in high-density, occluded conditions. This lightweight model not only delivers improved accuracy but also ensures efficient resource utilization, making it well-suited for real-time applications. Our experimental results demonstrate the model's superior performance in detecting small and densely clustered objects, underlining the significance of dataset choice and architectural adaptation for this specific task. In particular, the method achieves 52.5% mAP on VisDrone, exceeding top prior works. This approach promises to significantly advance object detection in aerial imagery, contributing to more accurate and reliable results in a variety of real-world applications.
Enhancing Lidar-based Object Detection in Adverse Weather using Offset Sequences in Time
Jan 17, 2024Automated vehicles require an accurate perception of their surroundings for safe and efficient driving. Lidar-based object detection is a widely used method for environment perception, but its performance is significantly affected by adverse weather conditions such as rain and fog. In this work, we investigate various strategies for enhancing the robustness of lidar-based object detection by processing sequential data samples generated by lidar sensors. Our approaches leverage temporal information to improve a lidar object detection model, without the need for additional filtering or pre-processing steps. We compare $10$ different neural network architectures that process point cloud sequences including a novel augmentation strategy introducing a temporal offset between frames of a sequence during training and evaluate the effectiveness of all strategies on lidar point clouds under adverse weather conditions through experiments. Our research provides a comprehensive study of effective methods for mitigating the effects of adverse weather on the reliability of lidar-based object detection using sequential data that are evaluated using public datasets such as nuScenes, Dense, and the Canadian Adverse Driving Conditions Dataset. Our findings demonstrate that our novel method, involving temporal offset augmentation through randomized frame skipping in sequences, enhances object detection accuracy compared to both the baseline model (Pillar-based Object Detection) and no augmentation.
Frequency-Adaptive Dilated Convolution for Semantic Segmentation
Mar 12, 2024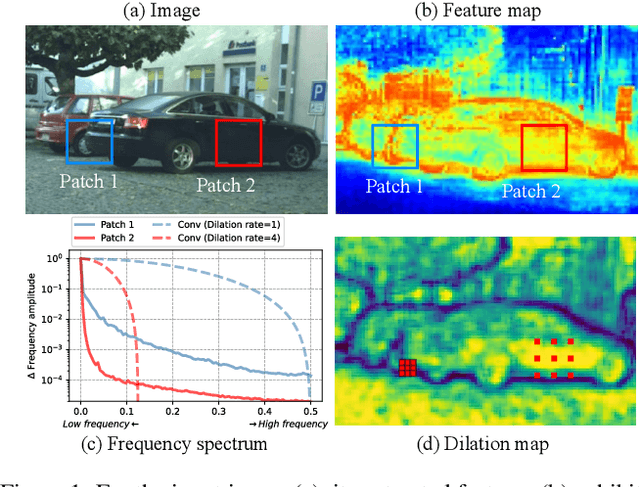
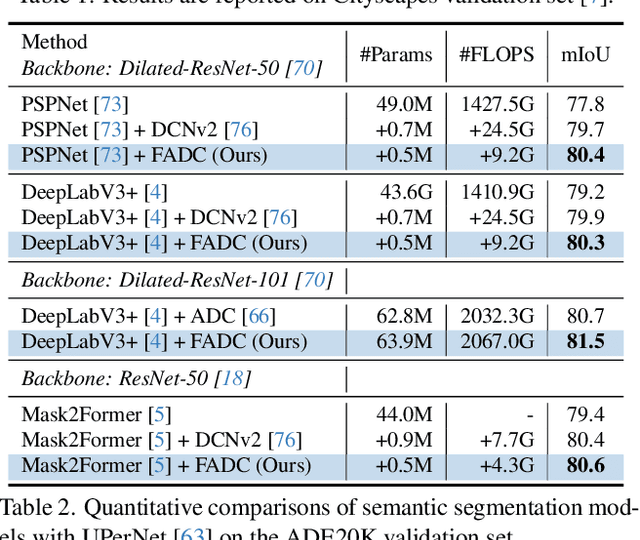
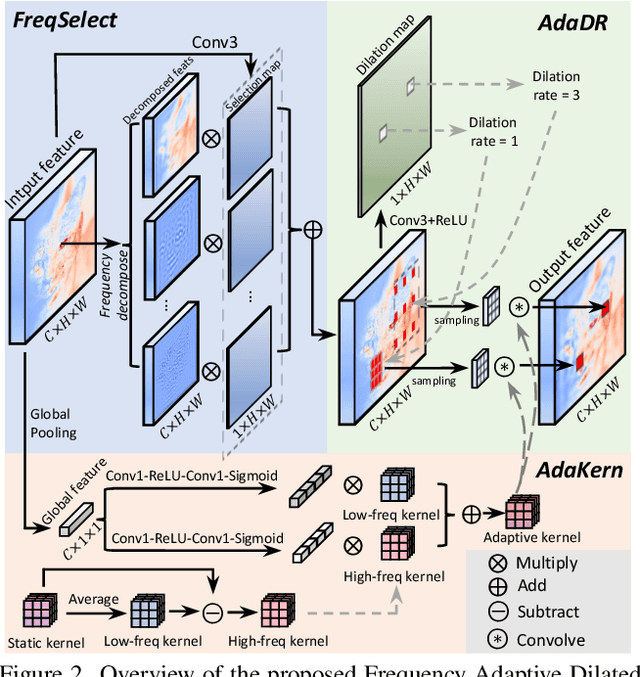
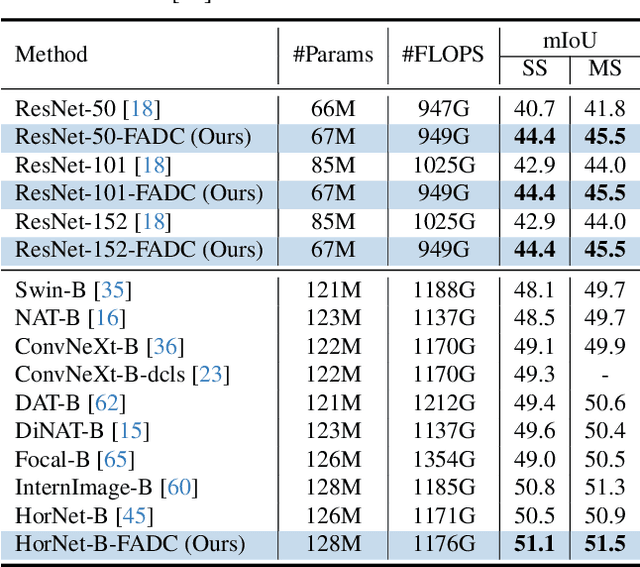
Dilated convolution, which expands the receptive field by inserting gaps between its consecutive elements, is widely employed in computer vision. In this study, we propose three strategies to improve individual phases of dilated convolution from the view of spectrum analysis. Departing from the conventional practice of fixing a global dilation rate as a hyperparameter, we introduce Frequency-Adaptive Dilated Convolution (FADC), which dynamically adjusts dilation rates spatially based on local frequency components. Subsequently, we design two plug-in modules to directly enhance effective bandwidth and receptive field size. The Adaptive Kernel (AdaKern) module decomposes convolution weights into low-frequency and high-frequency components, dynamically adjusting the ratio between these components on a per-channel basis. By increasing the high-frequency part of convolution weights, AdaKern captures more high-frequency components, thereby improving effective bandwidth. The Frequency Selection (FreqSelect) module optimally balances high- and low-frequency components in feature representations through spatially variant reweighting. It suppresses high frequencies in the background to encourage FADC to learn a larger dilation, thereby increasing the receptive field for an expanded scope. Extensive experiments on segmentation and object detection consistently validate the efficacy of our approach. The code is publicly available at \url{https://github.com/Linwei-Chen/FADC}.