 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
mAPm: multi-scale Attention Pyramid module for Enhanced scale-variation in RLD detection
Feb 26, 2024
Detecting objects across various scales remains a significant challenge in computer vision, particularly in tasks such as Rice Leaf Disease (RLD) detection, where objects exhibit considerable scale variations. Traditional object detection methods often struggle to address these variations, resulting in missed detections or reduced accuracy. In this study, we propose the multi-scale Attention Pyramid module (mAPm), a novel approach that integrates dilated convolutions into the Feature Pyramid Network (FPN) to enhance multi-scale information ex-traction. Additionally, we incorporate a global Multi-Head Self-Attention (MHSA) mechanism and a deconvolutional layer to refine the up-sampling process. We evaluate mAPm on YOLOv7 using the MRLD and COCO datasets. Compared to vanilla FPN, BiFPN, NAS-FPN, PANET, and ACFPN, mAPm achieved a significant improvement in Average Precision (AP), with a +2.61% increase on the MRLD dataset compared to the baseline FPN method in YOLOv7. This demonstrates its effectiveness in handling scale variations. Furthermore, the versatility of mAPm allows its integration into various FPN-based object detection models, showcasing its potential to advance object detection techniques.
Object Detectors in the Open Environment: Challenges, Solutions, and Outlook
Mar 26, 2024With the emergence of foundation models, deep learning-based object detectors have shown practical usability in closed set scenarios. However, for real-world tasks, object detectors often operate in open environments, where crucial factors (e.g., data distribution, objective) that influence model learning are often changing. The dynamic and intricate nature of the open environment poses novel and formidable challenges to object detectors. Unfortunately, current research on object detectors in open environments lacks a comprehensive analysis of their distinctive characteristics, challenges, and corresponding solutions, which hinders their secure deployment in critical real-world scenarios. This paper aims to bridge this gap by conducting a comprehensive review and analysis of object detectors in open environments. We initially identified limitations of key structural components within the existing detection pipeline and propose the open environment object detector challenge framework that includes four quadrants (i.e., out-of-domain, out-of-category, robust learning, and incremental learning) based on the dimensions of the data / target changes. For each quadrant of challenges in the proposed framework, we present a detailed description and systematic analysis of the overarching goals and core difficulties, systematically review the corresponding solutions, and benchmark their performance over multiple widely adopted datasets. In addition, we engage in a discussion of open problems and potential avenues for future research. This paper aims to provide a fresh, comprehensive, and systematic understanding of the challenges and solutions associated with open-environment object detectors, thus catalyzing the development of more solid applications in real-world scenarios. A project related to this survey can be found at https://github.com/LiangSiyuan21/OEOD_Survey.
Source-free Domain Adaptive Object Detection in Remote Sensing Images
Jan 31, 2024Recent studies have used unsupervised domain adaptive object detection (UDAOD) methods to bridge the domain gap in remote sensing (RS) images. However, UDAOD methods typically assume that the source domain data can be accessed during the domain adaptation process. This setting is often impractical in the real world due to RS data privacy and transmission difficulty. To address this challenge, we propose a practical source-free object detection (SFOD) setting for RS images, which aims to perform target domain adaptation using only the source pre-trained model. We propose a new SFOD method for RS images consisting of two parts: perturbed domain generation and alignment. The proposed multilevel perturbation constructs the perturbed domain in a simple yet efficient form by perturbing the domain-variant features at the image level and feature level according to the color and style bias. The proposed multilevel alignment calculates feature and label consistency between the perturbed domain and the target domain across the teacher-student network, and introduces the distillation of feature prototype to mitigate the noise of pseudo-labels. By requiring the detector to be consistent in the perturbed domain and the target domain, the detector is forced to focus on domaininvariant features. Extensive results of three synthetic-to-real experiments and three cross-sensor experiments have validated the effectiveness of our method which does not require access to source domain RS images. Furthermore, experiments on computer vision datasets show that our method can be extended to other fields as well. Our code will be available at: https://weixliu.github.io/ .
YOLO-MED : Multi-Task Interaction Network for Biomedical Images
Mar 01, 2024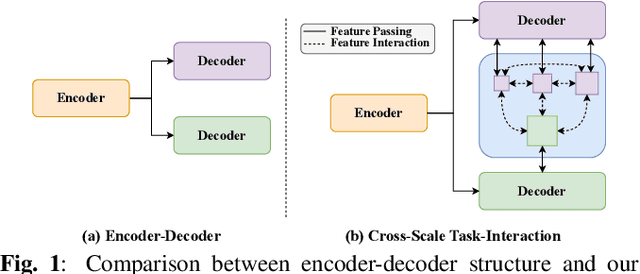
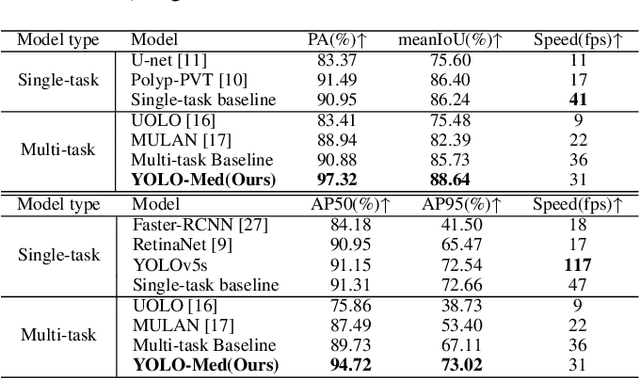
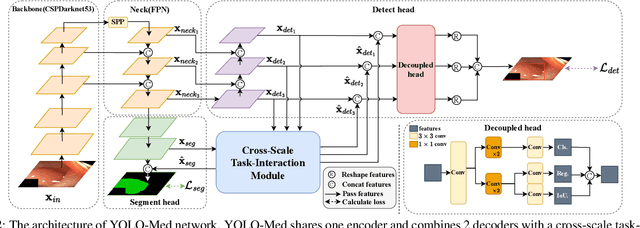
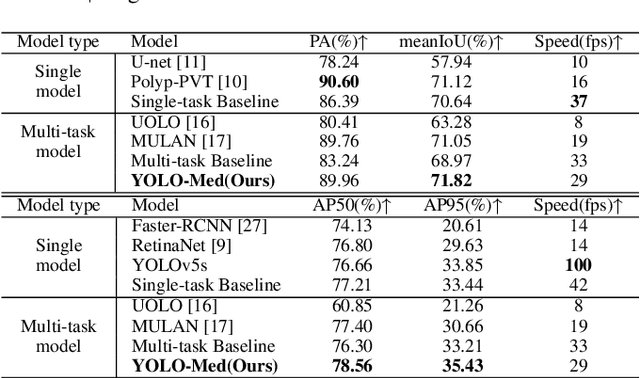
Object detection and semantic segmentation are pivotal components in biomedical image analysis. Current single-task networks exhibit promising outcomes in both detection and segmentation tasks. Multi-task networks have gained prominence due to their capability to simultaneously tackle segmentation and detection tasks, while also accelerating the segmentation inference. Nevertheless, recent multi-task networks confront distinct limitations such as the difficulty in striking a balance between accuracy and inference speed. Additionally, they often overlook the integration of cross-scale features, which is especially important for biomedical image analysis. In this study, we propose an efficient end-to-end multi-task network capable of concurrently performing object detection and semantic segmentation called YOLO-Med. Our model employs a backbone and a neck for multi-scale feature extraction, complemented by the inclusion of two task-specific decoders. A cross-scale task-interaction module is employed in order to facilitate information fusion between various tasks. Our model exhibits promising results in balancing accuracy and speed when evaluated on the Kvasir-seg dataset and a private biomedical image dataset.
Improve accessibility for Low Vision and Blind people using Machine Learning and Computer Vision
Mar 24, 2024With the ever-growing expansion of mobile technology worldwide, there is an increasing need for accommodation for those who are disabled. This project explores how machine learning and computer vision could be utilized to improve accessibility for people with visual impairments. There have been many attempts to develop various software that would improve accessibility in the day-to-day lives of blind people. However, applications on the market have low accuracy and only provide audio feedback. This project will concentrate on building a mobile application that helps blind people to orient in space by receiving audio and haptic feedback, e.g. vibrations, about their surroundings in real-time. The mobile application will have 3 main features. The initial feature is scanning text from the camera and reading it to a user. This feature can be used on paper with text, in the environment, and on road signs. The second feature is detecting objects around the user, and providing audio feedback about those objects. It also includes providing the description of the objects and their location, and giving haptic feedback if the user is too close to an object. The last feature is currency detection which provides a total amount of currency value to the user via the camera.
Loss Design for Single-carrier Joint Communication and Neural Network-based Sensing
Mar 05, 2024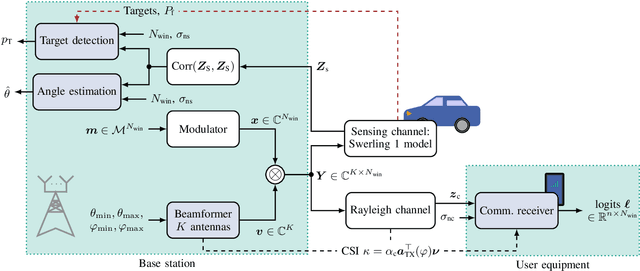
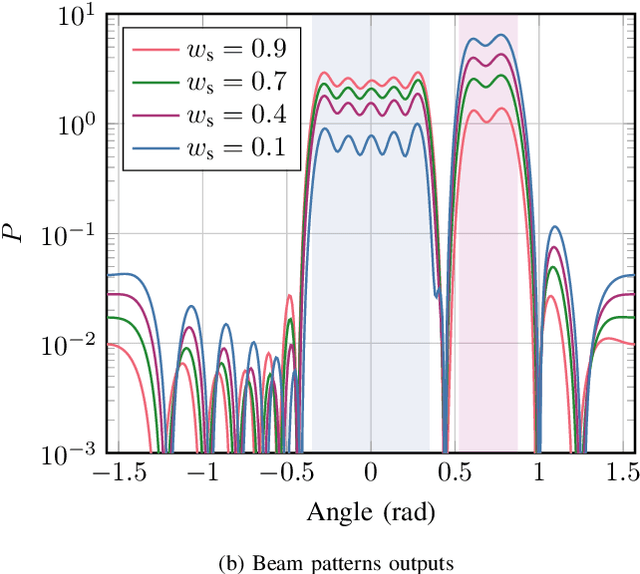
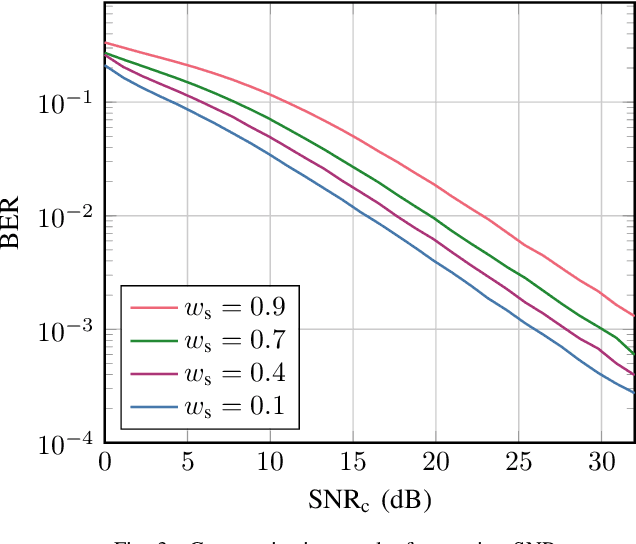
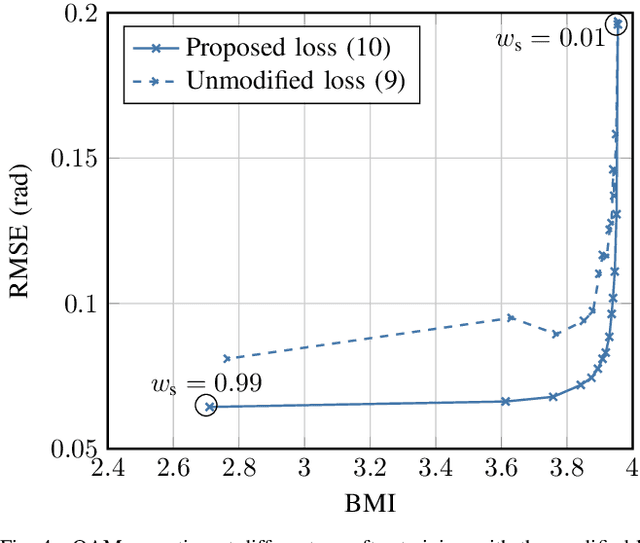
We evaluate the influence of multi-snapshot sensing and varying signal-to-noise ratio (SNR) on the overall performance of neural network (NN)-based joint communication and sensing (JCAS) systems. To enhance the training behavior, we decouple the loss functions from the respective SNR values and the number of sensing snapshots, using bounds of the sensing performance. Pre-processing is done through conventional sensing signal processing steps on the inputs to the sensing NN. The proposed method outperforms classical algorithms, such as a Neyman-Pearson-based power detector for object detection and ESPRIT for angle of arrival (AoA) estimation for quadrature amplitude modulation (QAM) at low SNRs.
You Only Look Bottom-Up for Monocular 3D Object Detection
Jan 27, 2024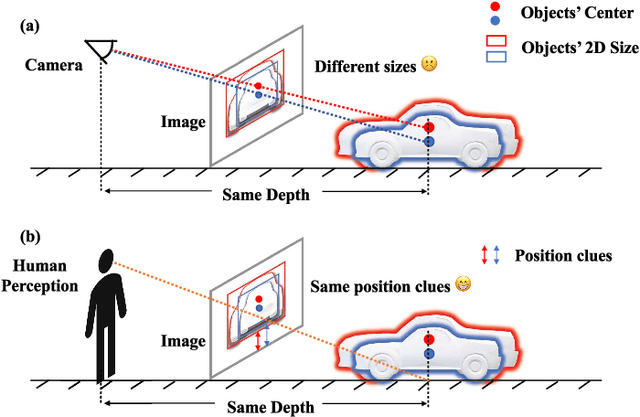
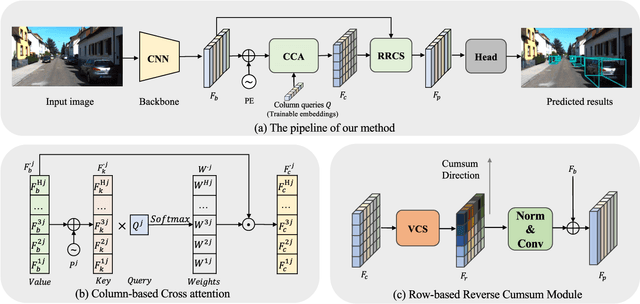
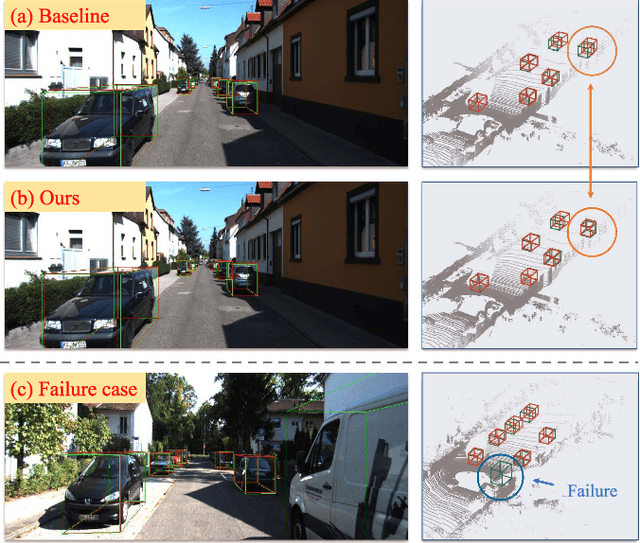
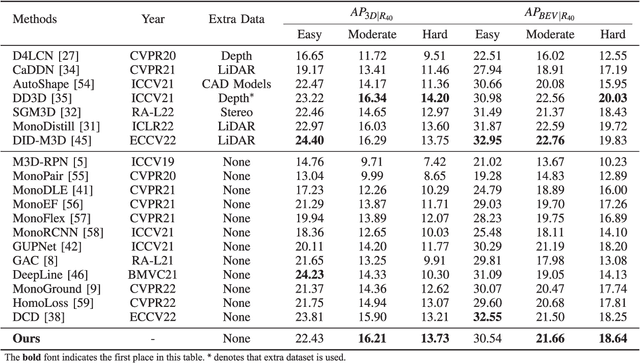
Monocular 3D Object Detection is an essential task for autonomous driving. Meanwhile, accurate 3D object detection from pure images is very challenging due to the loss of depth information. Most existing image-based methods infer objects' location in 3D space based on their 2D sizes on the image plane, which usually ignores the intrinsic position clues from images, leading to unsatisfactory performances. Motivated by the fact that humans could leverage the bottom-up positional clues to locate objects in 3D space from a single image, in this paper, we explore the position modeling from the image feature column and propose a new method named You Only Look Bottum-Up (YOLOBU). Specifically, our YOLOBU leverages Column-based Cross Attention to determine how much a pixel contributes to pixels above it. Next, the Row-based Reverse Cumulative Sum (RRCS) is introduced to build the connections of pixels in the bottom-up direction. Our YOLOBU fully explores the position clues for monocular 3D detection via building the relationship of pixels from the bottom-up way. Extensive experiments on the KITTI dataset demonstrate the effectiveness and superiority of our method.
Real-Time Vehicle Detection and Urban Traffic Behavior Analysis Based on UAV Traffic Videos on Mobile Devices
Feb 26, 2024This paper focuses on a real-time vehicle detection and urban traffic behavior analysis system based on Unmanned Aerial Vehicle (UAV) traffic video. By using UAV to collect traffic data and combining the YOLOv8 model and SORT tracking algorithm, the object detection and tracking functions are implemented on the iOS mobile platform. For the problem of traffic data acquisition and analysis, the dynamic computing method is used to process the performance in real time and calculate the micro and macro traffic parameters of the vehicles, and real-time traffic behavior analysis is conducted and visualized. The experiment results reveals that the vehicle object detection can reach 98.27% precision rate and 87.93% recall rate, and the real-time processing capacity is stable at 30 frames per seconds. This work integrates drone technology, iOS development, and deep learning techniques to integrate traffic video acquisition, object detection, object tracking, and traffic behavior analysis functions on mobile devices. It provides new possibilities for lightweight traffic information collection and data analysis, and offers innovative solutions to improve the efficiency of analyzing road traffic conditions and addressing transportation issues for transportation authorities.
Streamlined Hybrid Annotation Framework using Scalable Codestream for Bandwidth-Restricted UAV Object Detection
Feb 07, 2024Emergency response missions depend on the fast relay of visual information, a task to which unmanned aerial vehicles are well adapted. However, the effective use of unmanned aerial vehicles is often compromised by bandwidth limitations that impede fast data transmission, thereby delaying the quick decision-making necessary in emergency situations. To address these challenges, this paper presents a streamlined hybrid annotation framework that utilizes the JPEG 2000 compression algorithm to facilitate object detection under limited bandwidth. The proposed framework employs a fine-tuned deep learning network for initial image annotation at lower resolutions and uses JPEG 2000's scalable codestream to selectively enhance the image resolution in critical areas that require human expert annotation. We show that our proposed hybrid framework reduces the response time by a factor of 34 in emergency situations compared to a baseline approach.
From Blurry to Brilliant Detection: YOLOv5-Based Aerial Object Detection with Super Resolution
Jan 26, 2024The demand for accurate object detection in aerial imagery has surged with the widespread use of drones and satellite technology. Traditional object detection models, trained on datasets biased towards large objects, struggle to perform optimally in aerial scenarios where small, densely clustered objects are prevalent. To address this challenge, we present an innovative approach that combines super-resolution and an adapted lightweight YOLOv5 architecture. We employ a range of datasets, including VisDrone-2023, SeaDroneSee, VEDAI, and NWPU VHR-10, to evaluate our model's performance. Our Super Resolved YOLOv5 architecture features Transformer encoder blocks, allowing the model to capture global context and context information, leading to improved detection results, especially in high-density, occluded conditions. This lightweight model not only delivers improved accuracy but also ensures efficient resource utilization, making it well-suited for real-time applications. Our experimental results demonstrate the model's superior performance in detecting small and densely clustered objects, underlining the significance of dataset choice and architectural adaptation for this specific task. In particular, the method achieves 52.5% mAP on VisDrone, exceeding top prior works. This approach promises to significantly advance object detection in aerial imagery, contributing to more accurate and reliable results in a variety of real-world applications.