 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
MelNet: A Real-Time Deep Learning Algorithm for Object Detection
Jan 31, 2024
In this study, a novel deep learning algorithm for object detection, named MelNet, was introduced. MelNet underwent training utilizing the KITTI dataset for object detection. Following 300 training epochs, MelNet attained an mAP (mean average precision) score of 0.732. Additionally, three alternative models -YOLOv5, EfficientDet, and Faster-RCNN-MobileNetv3- were trained on the KITTI dataset and juxtaposed with MelNet for object detection. The outcomes underscore the efficacy of employing transfer learning in certain instances. Notably, preexisting models trained on prominent datasets (e.g., ImageNet, COCO, and Pascal VOC) yield superior results. Another finding underscores the viability of creating a new model tailored to a specific scenario and training it on a specific dataset. This investigation demonstrates that training MelNet exclusively on the KITTI dataset also surpasses EfficientDet after 150 epochs. Consequently, post-training, MelNet's performance closely aligns with that of other pre-trained models.
IllusionVQA: A Challenging Optical Illusion Dataset for Vision Language Models
Mar 30, 2024The advent of Vision Language Models (VLM) has allowed researchers to investigate the visual understanding of a neural network using natural language. Beyond object classification and detection, VLMs are capable of visual comprehension and common-sense reasoning. This naturally led to the question: How do VLMs respond when the image itself is inherently unreasonable? To this end, we present IllusionVQA: a diverse dataset of challenging optical illusions and hard-to-interpret scenes to test the capability of VLMs in two distinct multiple-choice VQA tasks - comprehension and soft localization. GPT4V, the best-performing VLM, achieves 62.99% accuracy (4-shot) on the comprehension task and 49.7% on the localization task (4-shot and Chain-of-Thought). Human evaluation reveals that humans achieve 91.03% and 100% accuracy in comprehension and localization. We discover that In-Context Learning (ICL) and Chain-of-Thought reasoning substantially degrade the performance of GeminiPro on the localization task. Tangentially, we discover a potential weakness in the ICL capabilities of VLMs: they fail to locate optical illusions even when the correct answer is in the context window as a few-shot example.
Just Add $100 More: Augmenting NeRF-based Pseudo-LiDAR Point Cloud for Resolving Class-imbalance Problem
Mar 20, 2024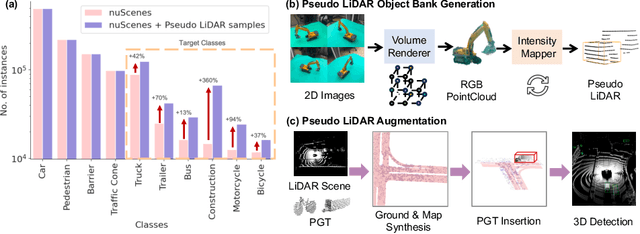
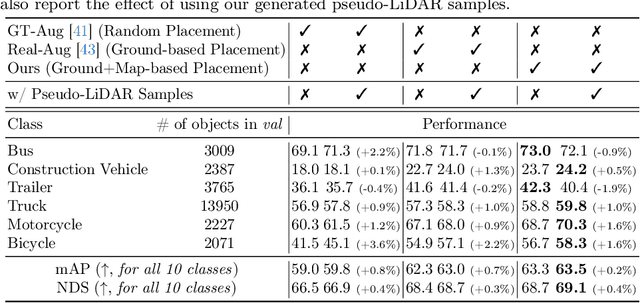
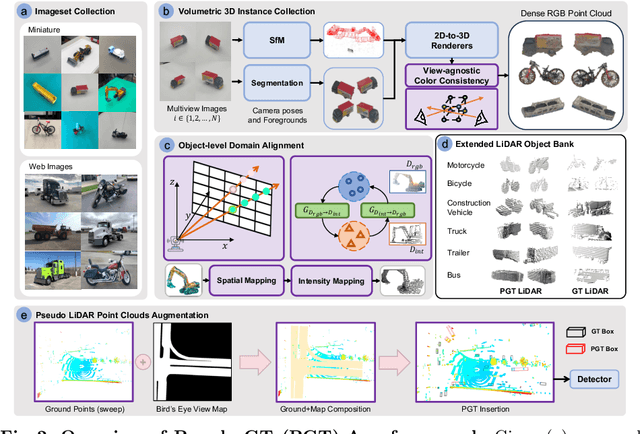
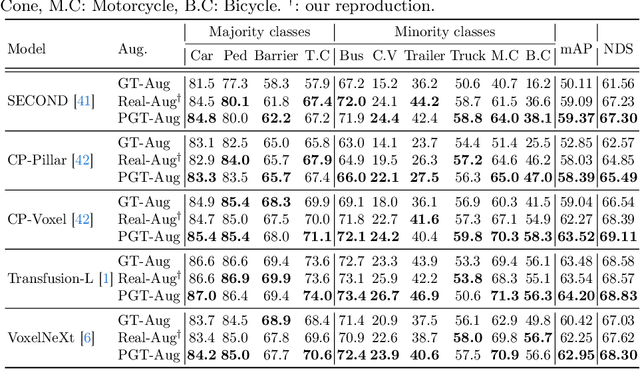
Typical LiDAR-based 3D object detection models are trained in a supervised manner with real-world data collection, which is often imbalanced over classes (or long-tailed). To deal with it, augmenting minority-class examples by sampling ground truth (GT) LiDAR points from a database and pasting them into a scene of interest is often used, but challenges still remain: inflexibility in locating GT samples and limited sample diversity. In this work, we propose to leverage pseudo-LiDAR point clouds generated (at a low cost) from videos capturing a surround view of miniatures or real-world objects of minor classes. Our method, called Pseudo Ground Truth Augmentation (PGT-Aug), consists of three main steps: (i) volumetric 3D instance reconstruction using a 2D-to-3D view synthesis model, (ii) object-level domain alignment with LiDAR intensity estimation and (iii) a hybrid context-aware placement method from ground and map information. We demonstrate the superiority and generality of our method through performance improvements in extensive experiments conducted on three popular benchmarks, i.e., nuScenes, KITTI, and Lyft, especially for the datasets with large domain gaps captured by different LiDAR configurations. Our code and data will be publicly available upon publication.
Few-Shot Object Detection with Sparse Context Transformers
Feb 14, 2024Few-shot detection is a major task in pattern recognition which seeks to localize objects using models trained with few labeled data. One of the mainstream few-shot methods is transfer learning which consists in pretraining a detection model in a source domain prior to its fine-tuning in a target domain. However, it is challenging for fine-tuned models to effectively identify new classes in the target domain, particularly when the underlying labeled training data are scarce. In this paper, we devise a novel sparse context transformer (SCT) that effectively leverages object knowledge in the source domain, and automatically learns a sparse context from only few training images in the target domain. As a result, it combines different relevant clues in order to enhance the discrimination power of the learned detectors and reduce class confusion. We evaluate the proposed method on two challenging few-shot object detection benchmarks, and empirical results show that the proposed method obtains competitive performance compared to the related state-of-the-art.
TAPTR: Tracking Any Point with Transformers as Detection
Mar 19, 2024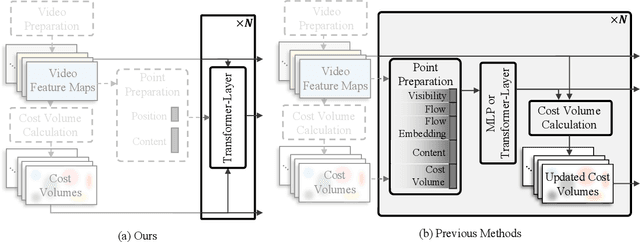
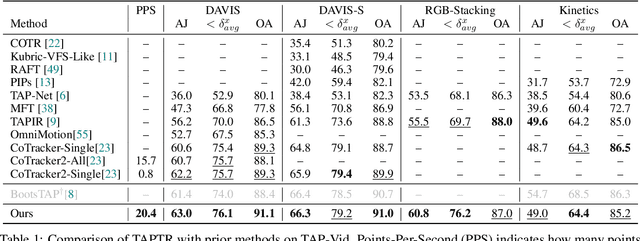
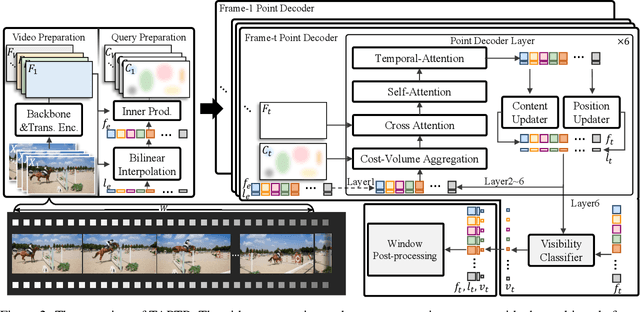

In this paper, we propose a simple and strong framework for Tracking Any Point with TRansformers (TAPTR). Based on the observation that point tracking bears a great resemblance to object detection and tracking, we borrow designs from DETR-like algorithms to address the task of TAP. In the proposed framework, in each video frame, each tracking point is represented as a point query, which consists of a positional part and a content part. As in DETR, each query (its position and content feature) is naturally updated layer by layer. Its visibility is predicted by its updated content feature. Queries belonging to the same tracking point can exchange information through self-attention along the temporal dimension. As all such operations are well-designed in DETR-like algorithms, the model is conceptually very simple. We also adopt some useful designs such as cost volume from optical flow models and develop simple designs to provide long temporal information while mitigating the feature drifting issue. Our framework demonstrates strong performance with state-of-the-art performance on various TAP datasets with faster inference speed.
SimPB: A Single Model for 2D and 3D Object Detection from Multiple Cameras
Mar 15, 2024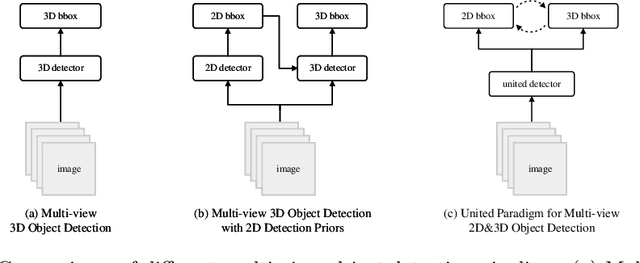
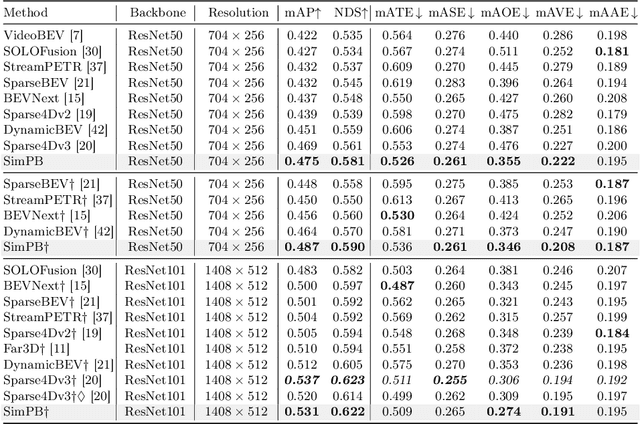
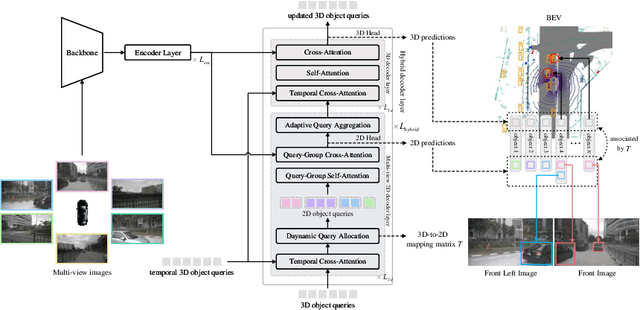
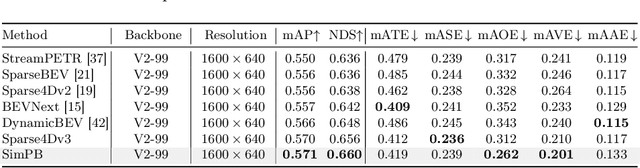
The field of autonomous driving has attracted considerable interest in approaches that directly infer 3D objects in the Bird's Eye View (BEV) from multiple cameras. Some attempts have also explored utilizing 2D detectors from single images to enhance the performance of 3D detection. However, these approaches rely on a two-stage process with separate detectors, where the 2D detection results are utilized only once for token selection or query initialization. In this paper, we present a single model termed SimPB, which simultaneously detects 2D objects in the perspective view and 3D objects in the BEV space from multiple cameras. To achieve this, we introduce a hybrid decoder consisting of several multi-view 2D decoder layers and several 3D decoder layers, specifically designed for their respective detection tasks. A Dynamic Query Allocation module and an Adaptive Query Aggregation module are proposed to continuously update and refine the interaction between 2D and 3D results, in a cyclic 3D-2D-3D manner. Additionally, Query-group Attention is utilized to strengthen the interaction among 2D queries within each camera group. In the experiments, we evaluate our method on the nuScenes dataset and demonstrate promising results for both 2D and 3D detection tasks. Our code is available at: https://github.com/nullmax-vision/SimPB.
IAMCV Multi-Scenario Vehicle Interaction Dataset
Mar 13, 2024


The acquisition and analysis of high-quality sensor data constitute an essential requirement in shaping the development of fully autonomous driving systems. This process is indispensable for enhancing road safety and ensuring the effectiveness of the technological advancements in the automotive industry. This study introduces the Interaction of Autonomous and Manually-Controlled Vehicles (IAMCV) dataset, a novel and extensive dataset focused on inter-vehicle interactions. The dataset, enriched with a sophisticated array of sensors such as Light Detection and Ranging, cameras, Inertial Measurement Unit/Global Positioning System, and vehicle bus data acquisition, provides a comprehensive representation of real-world driving scenarios that include roundabouts, intersections, country roads, and highways, recorded across diverse locations in Germany. Furthermore, the study shows the versatility of the IAMCV dataset through several proof-of-concept use cases. Firstly, an unsupervised trajectory clustering algorithm illustrates the dataset's capability in categorizing vehicle movements without the need for labeled training data. Secondly, we compare an online camera calibration method with the Robot Operating System-based standard, using images captured in the dataset. Finally, a preliminary test employing the YOLOv8 object-detection model is conducted, augmented by reflections on the transferability of object detection across various LIDAR resolutions. These use cases underscore the practical utility of the collected dataset, emphasizing its potential to advance research and innovation in the area of intelligent vehicles.
Bounding Box Stability against Feature Dropout Reflects Detector Generalization across Environments
Mar 20, 2024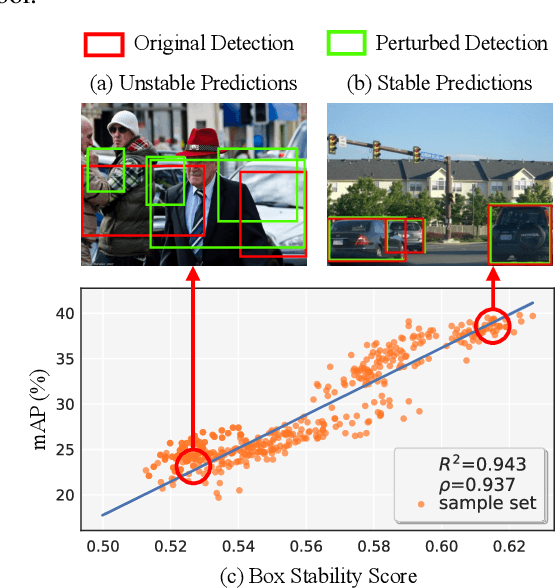
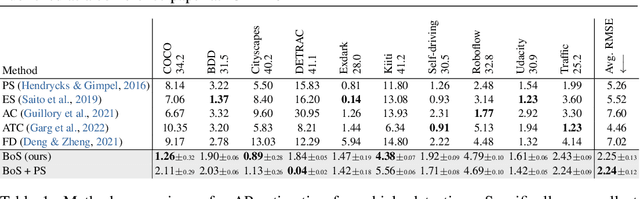
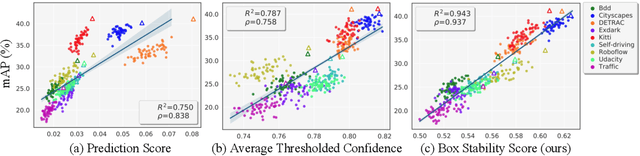
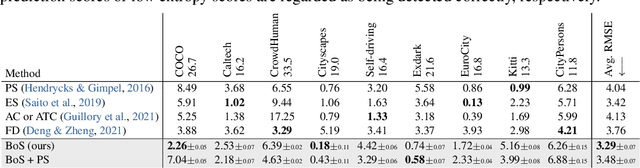
Bounding boxes uniquely characterize object detection, where a good detector gives accurate bounding boxes of categories of interest. However, in the real-world where test ground truths are not provided, it is non-trivial to find out whether bounding boxes are accurate, thus preventing us from assessing the detector generalization ability. In this work, we find under feature map dropout, good detectors tend to output bounding boxes whose locations do not change much, while bounding boxes of poor detectors will undergo noticeable position changes. We compute the box stability score (BoS score) to reflect this stability. Specifically, given an image, we compute a normal set of bounding boxes and a second set after feature map dropout. To obtain BoS score, we use bipartite matching to find the corresponding boxes between the two sets and compute the average Intersection over Union (IoU) across the entire test set. We contribute to finding that BoS score has a strong, positive correlation with detection accuracy measured by mean average precision (mAP) under various test environments. This relationship allows us to predict the accuracy of detectors on various real-world test sets without accessing test ground truths, verified on canonical detection tasks such as vehicle detection and pedestrian detection. Code and data are available at https://github.com/YangYangGirl/BoS.
TransformMix: Learning Transformation and Mixing Strategies from Data
Mar 19, 2024
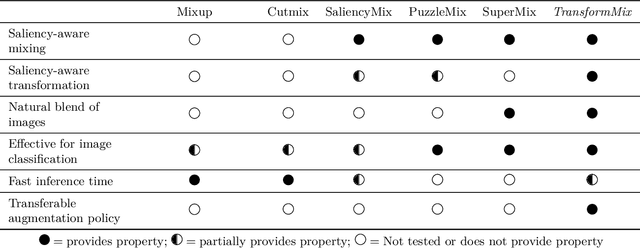

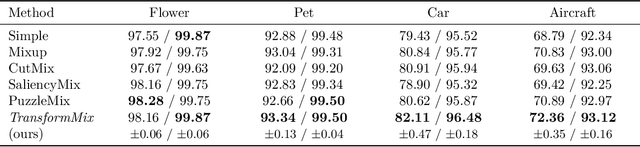
Data augmentation improves the generalization power of deep learning models by synthesizing more training samples. Sample-mixing is a popular data augmentation approach that creates additional data by combining existing samples. Recent sample-mixing methods, like Mixup and Cutmix, adopt simple mixing operations to blend multiple inputs. Although such a heuristic approach shows certain performance gains in some computer vision tasks, it mixes the images blindly and does not adapt to different datasets automatically. A mixing strategy that is effective for a particular dataset does not often generalize well to other datasets. If not properly configured, the methods may create misleading mixed images, which jeopardize the effectiveness of sample-mixing augmentations. In this work, we propose an automated approach, TransformMix, to learn better transformation and mixing augmentation strategies from data. In particular, TransformMix applies learned transformations and mixing masks to create compelling mixed images that contain correct and important information for the target tasks. We demonstrate the effectiveness of TransformMix on multiple datasets in transfer learning, classification, object detection, and knowledge distillation settings. Experimental results show that our method achieves better performance as well as efficiency when compared with strong sample-mixing baselines.
GraphKD: Exploring Knowledge Distillation Towards Document Object Detection with Structured Graph Creation
Feb 20, 2024Object detection in documents is a key step to automate the structural elements identification process in a digital or scanned document through understanding the hierarchical structure and relationships between different elements. Large and complex models, while achieving high accuracy, can be computationally expensive and memory-intensive, making them impractical for deployment on resource constrained devices. Knowledge distillation allows us to create small and more efficient models that retain much of the performance of their larger counterparts. Here we present a graph-based knowledge distillation framework to correctly identify and localize the document objects in a document image. Here, we design a structured graph with nodes containing proposal-level features and edges representing the relationship between the different proposal regions. Also, to reduce text bias an adaptive node sampling strategy is designed to prune the weight distribution and put more weightage on non-text nodes. We encode the complete graph as a knowledge representation and transfer it from the teacher to the student through the proposed distillation loss by effectively capturing both local and global information concurrently. Extensive experimentation on competitive benchmarks demonstrates that the proposed framework outperforms the current state-of-the-art approaches. The code will be available at: https://github.com/ayanban011/GraphKD.