 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Improving Object Detection Quality in Football Through Super-Resolution Techniques
Jan 31, 2024
This study explores the potential of super-resolution techniques in enhancing object detection accuracy in football. Given the sport's fast-paced nature and the critical importance of precise object (e.g. ball, player) tracking for both analysis and broadcasting, super-resolution could offer significant improvements. We investigate how advanced image processing through super-resolution impacts the accuracy and reliability of object detection algorithms in processing football match footage. Our methodology involved applying state-of-the-art super-resolution techniques to a diverse set of football match videos from SoccerNet, followed by object detection using Faster R-CNN. The performance of these algorithms, both with and without super-resolution enhancement, was rigorously evaluated in terms of detection accuracy. The results indicate a marked improvement in object detection accuracy when super-resolution preprocessing is applied. The improvement of object detection through the integration of super-resolution techniques yields significant benefits, especially for low-resolution scenarios, with a notable 12\% increase in mean Average Precision (mAP) at an IoU (Intersection over Union) range of 0.50:0.95 for 320x240 size images when increasing the resolution fourfold using RLFN. As the dimensions increase, the magnitude of improvement becomes more subdued; however, a discernible improvement in the quality of detection is consistently evident. Additionally, we discuss the implications of these findings for real-time sports analytics, player tracking, and the overall viewing experience. The study contributes to the growing field of sports technology by demonstrating the practical benefits and limitations of integrating super-resolution techniques in football analytics and broadcasting.
Few-Shot Object Detection with Sparse Context Transformers
Feb 14, 2024Few-shot detection is a major task in pattern recognition which seeks to localize objects using models trained with few labeled data. One of the mainstream few-shot methods is transfer learning which consists in pretraining a detection model in a source domain prior to its fine-tuning in a target domain. However, it is challenging for fine-tuned models to effectively identify new classes in the target domain, particularly when the underlying labeled training data are scarce. In this paper, we devise a novel sparse context transformer (SCT) that effectively leverages object knowledge in the source domain, and automatically learns a sparse context from only few training images in the target domain. As a result, it combines different relevant clues in order to enhance the discrimination power of the learned detectors and reduce class confusion. We evaluate the proposed method on two challenging few-shot object detection benchmarks, and empirical results show that the proposed method obtains competitive performance compared to the related state-of-the-art.
Continual Forgetting for Pre-trained Vision Models
Mar 18, 2024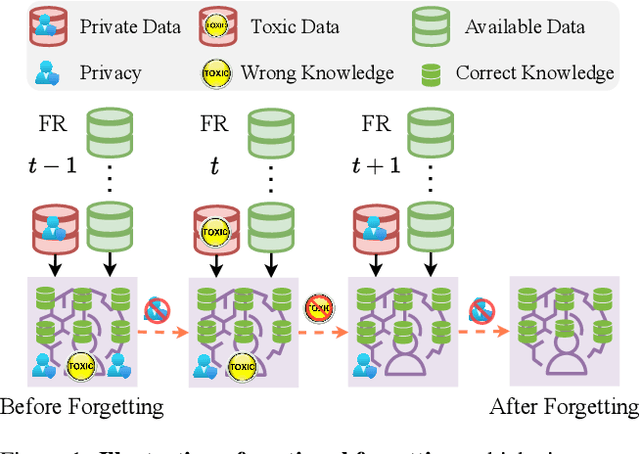
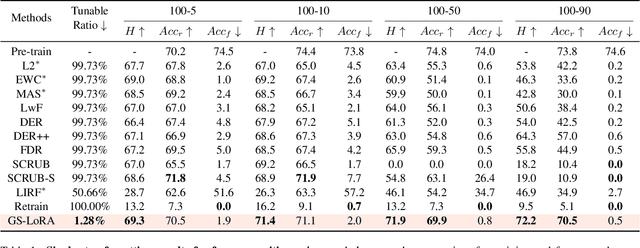
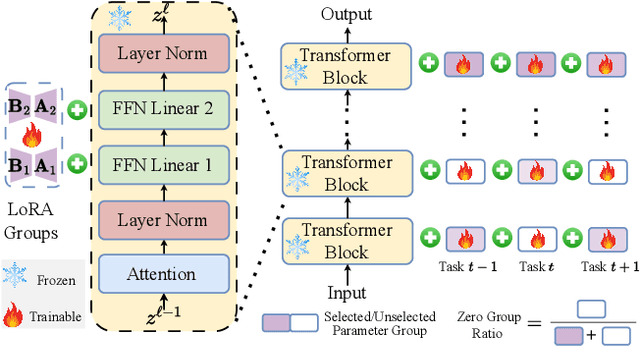
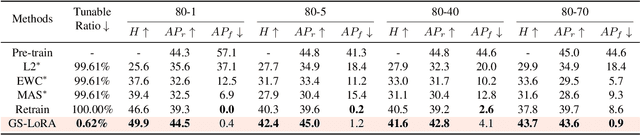
For privacy and security concerns, the need to erase unwanted information from pre-trained vision models is becoming evident nowadays. In real-world scenarios, erasure requests originate at any time from both users and model owners. These requests usually form a sequence. Therefore, under such a setting, selective information is expected to be continuously removed from a pre-trained model while maintaining the rest. We define this problem as continual forgetting and identify two key challenges. (i) For unwanted knowledge, efficient and effective deleting is crucial. (ii) For remaining knowledge, the impact brought by the forgetting procedure should be minimal. To address them, we propose Group Sparse LoRA (GS-LoRA). Specifically, towards (i), we use LoRA modules to fine-tune the FFN layers in Transformer blocks for each forgetting task independently, and towards (ii), a simple group sparse regularization is adopted, enabling automatic selection of specific LoRA groups and zeroing out the others. GS-LoRA is effective, parameter-efficient, data-efficient, and easy to implement. We conduct extensive experiments on face recognition, object detection and image classification and demonstrate that GS-LoRA manages to forget specific classes with minimal impact on other classes. Codes will be released on \url{https://github.com/bjzhb666/GS-LoRA}.
Towards Real-Time Fast Unmanned Aerial Vehicle Detection Using Dynamic Vision Sensors
Mar 18, 2024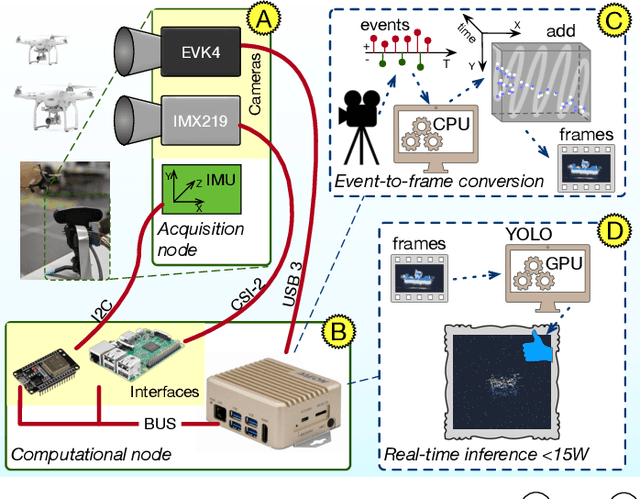



Unmanned Aerial Vehicles (UAVs) are gaining popularity in civil and military applications. However, uncontrolled access to restricted areas threatens privacy and security. Thus, prevention and detection of UAVs are pivotal to guarantee confidentiality and safety. Although active scanning, mainly based on radars, is one of the most accurate technologies, it can be expensive and less versatile than passive inspections, e.g., object recognition. Dynamic vision sensors (DVS) are bio-inspired event-based vision models that leverage timestamped pixel-level brightness changes in fast-moving scenes that adapt well to low-latency object detection. This paper presents F-UAV-D (Fast Unmanned Aerial Vehicle Detector), an embedded system that enables fast-moving drone detection. In particular, we propose a setup to exploit DVS as an alternative to RGB cameras in a real-time and low-power configuration. Our approach leverages the high-dynamic range (HDR) and background suppression of DVS and, when trained with various fast-moving drones, outperforms RGB input in suboptimal ambient conditions such as low illumination and fast-moving scenes. Our results show that F-UAV-D can (i) detect drones by using less than <15 W on average and (ii) perform real-time inference (i.e., <50 ms) by leveraging the CPU and GPU nodes of our edge computer.
FlexCap: Generating Rich, Localized, and Flexible Captions in Images
Mar 18, 2024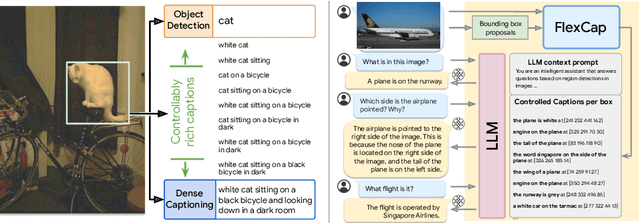

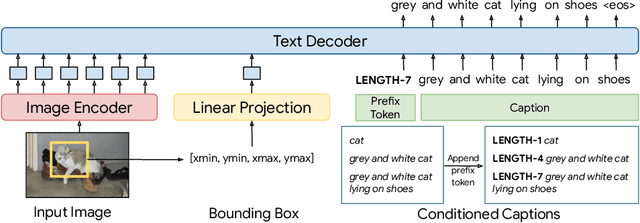

We introduce a versatile $\textit{flexible-captioning}$ vision-language model (VLM) capable of generating region-specific descriptions of varying lengths. The model, FlexCap, is trained to produce length-conditioned captions for input bounding boxes, and this allows control over the information density of its output, with descriptions ranging from concise object labels to detailed captions. To achieve this we create large-scale training datasets of image region descriptions of varying length, starting from captioned images. This flexible-captioning capability has several valuable applications. First, FlexCap demonstrates superior performance in dense captioning tasks on the Visual Genome dataset. Second, a visual question answering (VQA) system can be built by employing FlexCap to generate localized descriptions as inputs to a large language model. The resulting system achieves state-of-the-art zero-shot performance on a number of VQA datasets. We also demonstrate a $\textit{localize-then-describe}$ approach with FlexCap can be better at open-ended object detection than a $\textit{describe-then-localize}$ approach with other VLMs. We highlight a novel characteristic of FlexCap, which is its ability to extract diverse visual information through prefix conditioning. Finally, we qualitatively demonstrate FlexCap's broad applicability in tasks such as image labeling, object attribute recognition, and visual dialog. Project webpage: https://flex-cap.github.io .
Lifting Multi-View Detection and Tracking to the Bird's Eye View
Mar 19, 2024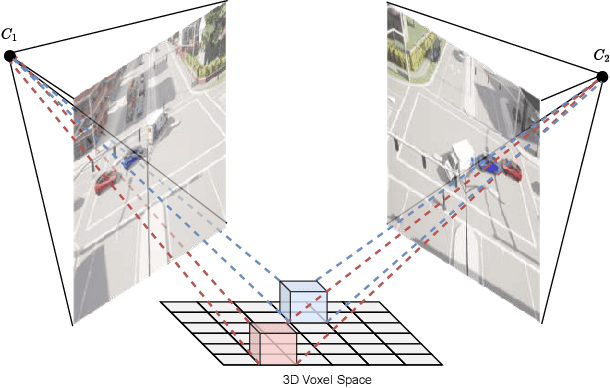
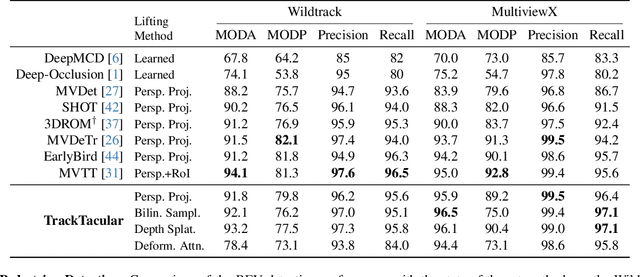
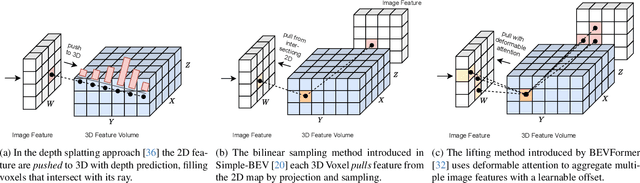
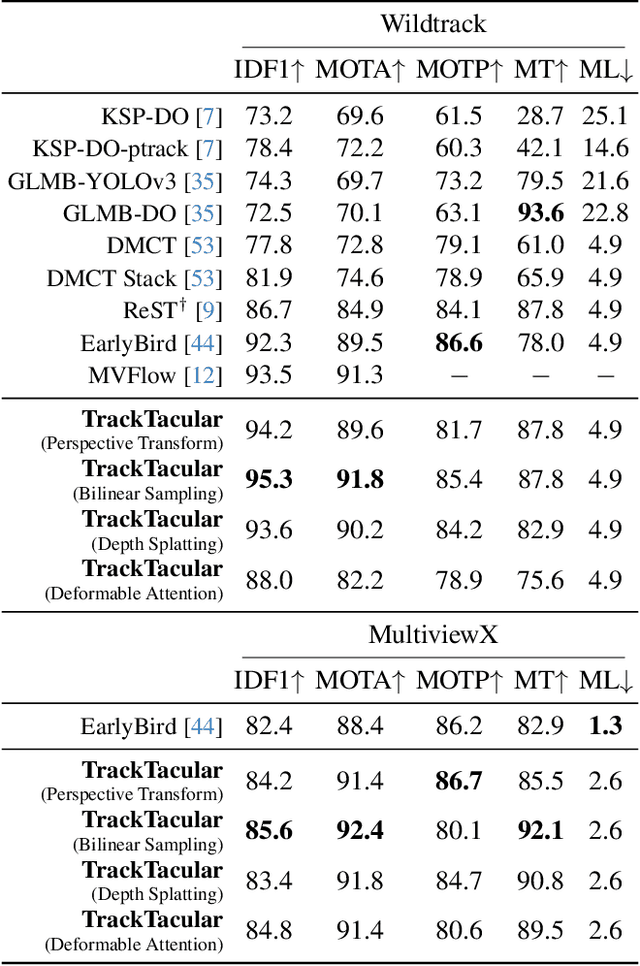
Taking advantage of multi-view aggregation presents a promising solution to tackle challenges such as occlusion and missed detection in multi-object tracking and detection. Recent advancements in multi-view detection and 3D object recognition have significantly improved performance by strategically projecting all views onto the ground plane and conducting detection analysis from a Bird's Eye View. In this paper, we compare modern lifting methods, both parameter-free and parameterized, to multi-view aggregation. Additionally, we present an architecture that aggregates the features of multiple times steps to learn robust detection and combines appearance- and motion-based cues for tracking. Most current tracking approaches either focus on pedestrians or vehicles. In our work, we combine both branches and add new challenges to multi-view detection with cross-scene setups. Our method generalizes to three public datasets across two domains: (1) pedestrian: Wildtrack and MultiviewX, and (2) roadside perception: Synthehicle, achieving state-of-the-art performance in detection and tracking. https://github.com/tteepe/TrackTacular
MelNet: A Real-Time Deep Learning Algorithm for Object Detection
Jan 31, 2024In this study, a novel deep learning algorithm for object detection, named MelNet, was introduced. MelNet underwent training utilizing the KITTI dataset for object detection. Following 300 training epochs, MelNet attained an mAP (mean average precision) score of 0.732. Additionally, three alternative models -YOLOv5, EfficientDet, and Faster-RCNN-MobileNetv3- were trained on the KITTI dataset and juxtaposed with MelNet for object detection. The outcomes underscore the efficacy of employing transfer learning in certain instances. Notably, preexisting models trained on prominent datasets (e.g., ImageNet, COCO, and Pascal VOC) yield superior results. Another finding underscores the viability of creating a new model tailored to a specific scenario and training it on a specific dataset. This investigation demonstrates that training MelNet exclusively on the KITTI dataset also surpasses EfficientDet after 150 epochs. Consequently, post-training, MelNet's performance closely aligns with that of other pre-trained models.
EAS-SNN: End-to-End Adaptive Sampling and Representation for Event-based Detection with Recurrent Spiking Neural Networks
Mar 19, 2024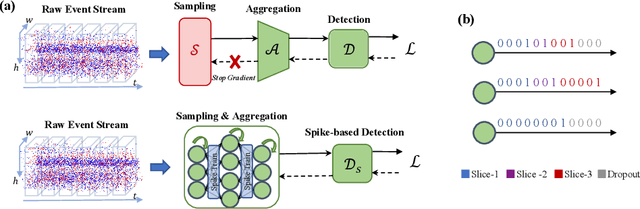
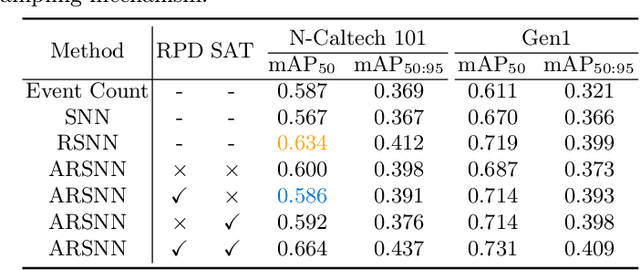
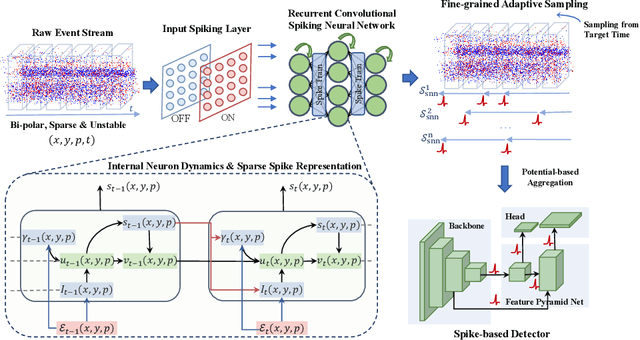
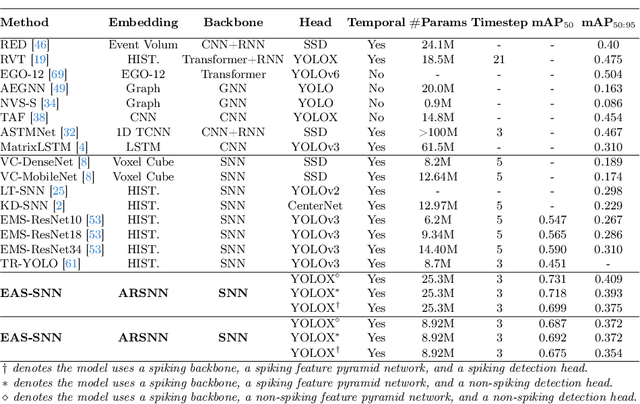
Event cameras, with their high dynamic range and temporal resolution, are ideally suited for object detection, especially under scenarios with motion blur and challenging lighting conditions. However, while most existing approaches prioritize optimizing spatiotemporal representations with advanced detection backbones and early aggregation functions, the crucial issue of adaptive event sampling remains largely unaddressed. Spiking Neural Networks (SNNs), which operate on an event-driven paradigm through sparse spike communication, emerge as a natural fit for addressing this challenge. In this study, we discover that the neural dynamics of spiking neurons align closely with the behavior of an ideal temporal event sampler. Motivated by this insight, we propose a novel adaptive sampling module that leverages recurrent convolutional SNNs enhanced with temporal memory, facilitating a fully end-to-end learnable framework for event-based detection. Additionally, we introduce Residual Potential Dropout (RPD) and Spike-Aware Training (SAT) to regulate potential distribution and address performance degradation encountered in spike-based sampling modules. Through rigorous testing on neuromorphic datasets for event-based detection, our approach demonstrably surpasses existing state-of-the-art spike-based methods, achieving superior performance with significantly fewer parameters and time steps. For instance, our method achieves a 4.4\% mAP improvement on the Gen1 dataset, while requiring 38\% fewer parameters and three time steps. Moreover, the applicability and effectiveness of our adaptive sampling methodology extend beyond SNNs, as demonstrated through further validation on conventional non-spiking detection models.
Fostc3net:A Lightweight YOLOv5 Based On the Network Structure Optimization
Mar 20, 2024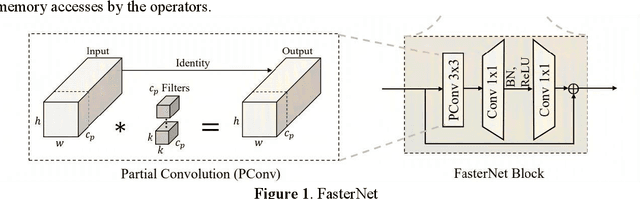
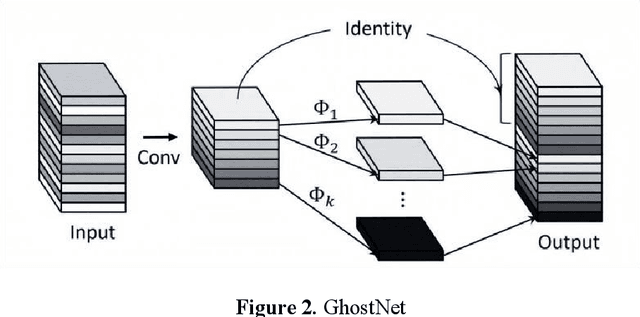
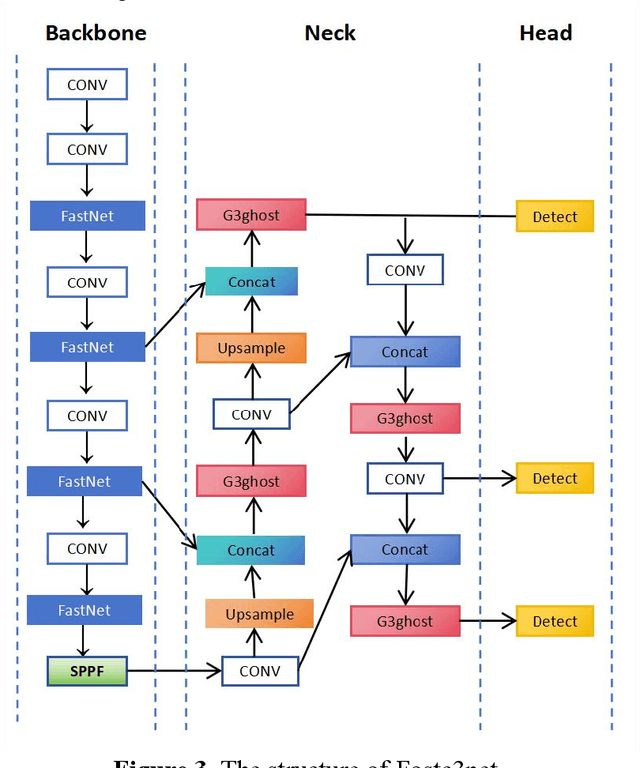

Transmission line detection technology is crucial for automatic monitoring and ensuring the safety of electrical facilities. The YOLOv5 series is currently one of the most advanced and widely used methods for object detection. However, it faces inherent challenges, such as high computational load on devices and insufficient detection accuracy. To address these concerns, this paper presents an enhanced lightweight YOLOv5 technique customized for mobile devices, specifically intended for identifying objects associated with transmission lines. The C3Ghost module is integrated into the convolutional network of YOLOv5 to reduce floating point operations per second (FLOPs) in the feature channel fusion process and improve feature expression performance. In addition, a FasterNet module is introduced to replace the c3 module in the YOLOv5 Backbone. The FasterNet module uses Partial Convolutions to process only a portion of the input channels, improving feature extraction efficiency and reducing computational overhead. To address the imbalance between simple and challenging samples in the dataset and the diversity of aspect ratios of bounding boxes, the wIoU v3 LOSS is adopted as the loss function. To validate the performance of the proposed approach, Experiments are conducted on a custom dataset of transmission line poles. The results show that the proposed model achieves a 1% increase in detection accuracy, a 13% reduction in FLOPs, and a 26% decrease in model parameters compared to the existing YOLOv5.In the ablation experiment, it was also discovered that while the Fastnet module and the CSghost module improved the precision of the original YOLOv5 baseline model, they caused a decrease in the mAP@.5-.95 metric. However, the improvement of the wIoUv3 loss function significantly mitigated the decline of the mAP@.5-.95 metric.
GraphKD: Exploring Knowledge Distillation Towards Document Object Detection with Structured Graph Creation
Feb 20, 2024Object detection in documents is a key step to automate the structural elements identification process in a digital or scanned document through understanding the hierarchical structure and relationships between different elements. Large and complex models, while achieving high accuracy, can be computationally expensive and memory-intensive, making them impractical for deployment on resource constrained devices. Knowledge distillation allows us to create small and more efficient models that retain much of the performance of their larger counterparts. Here we present a graph-based knowledge distillation framework to correctly identify and localize the document objects in a document image. Here, we design a structured graph with nodes containing proposal-level features and edges representing the relationship between the different proposal regions. Also, to reduce text bias an adaptive node sampling strategy is designed to prune the weight distribution and put more weightage on non-text nodes. We encode the complete graph as a knowledge representation and transfer it from the teacher to the student through the proposed distillation loss by effectively capturing both local and global information concurrently. Extensive experimentation on competitive benchmarks demonstrates that the proposed framework outperforms the current state-of-the-art approaches. The code will be available at: https://github.com/ayanban011/GraphKD.