 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Bounding Box Stability against Feature Dropout Reflects Detector Generalization across Environments
Mar 20, 2024
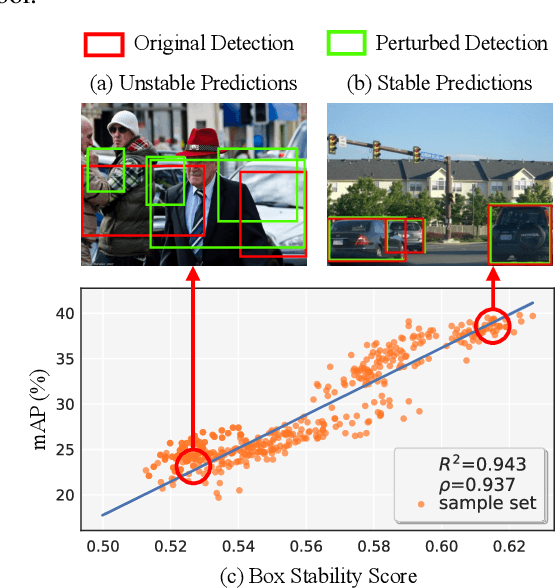
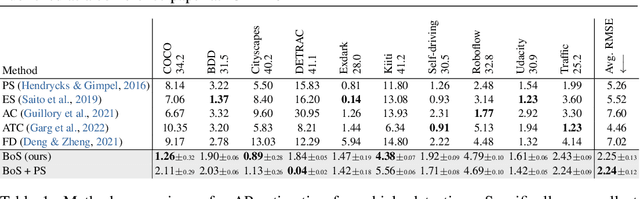
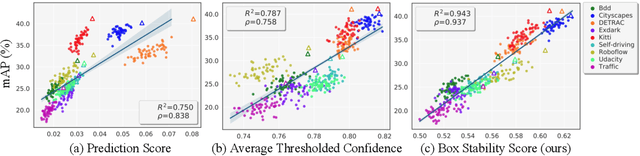
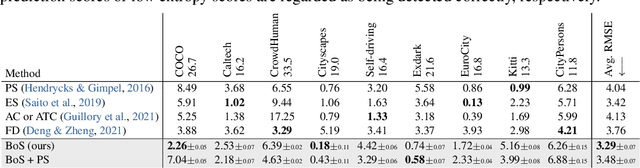
Bounding boxes uniquely characterize object detection, where a good detector gives accurate bounding boxes of categories of interest. However, in the real-world where test ground truths are not provided, it is non-trivial to find out whether bounding boxes are accurate, thus preventing us from assessing the detector generalization ability. In this work, we find under feature map dropout, good detectors tend to output bounding boxes whose locations do not change much, while bounding boxes of poor detectors will undergo noticeable position changes. We compute the box stability score (BoS score) to reflect this stability. Specifically, given an image, we compute a normal set of bounding boxes and a second set after feature map dropout. To obtain BoS score, we use bipartite matching to find the corresponding boxes between the two sets and compute the average Intersection over Union (IoU) across the entire test set. We contribute to finding that BoS score has a strong, positive correlation with detection accuracy measured by mean average precision (mAP) under various test environments. This relationship allows us to predict the accuracy of detectors on various real-world test sets without accessing test ground truths, verified on canonical detection tasks such as vehicle detection and pedestrian detection. Code and data are available at https://github.com/YangYangGirl/BoS.
SimPB: A Single Model for 2D and 3D Object Detection from Multiple Cameras
Mar 15, 2024
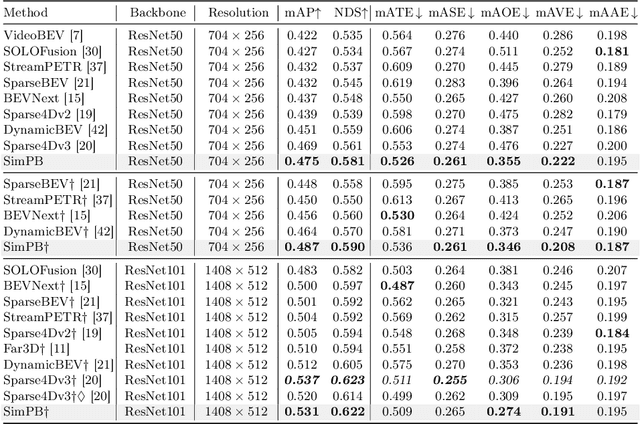
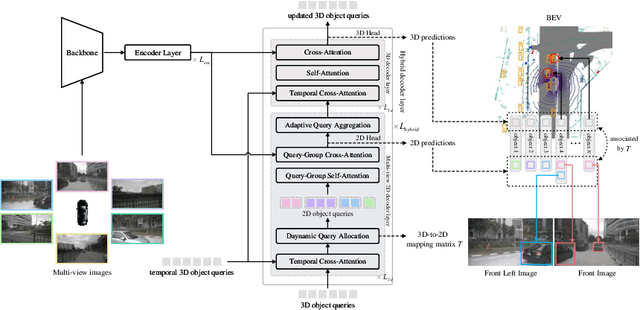
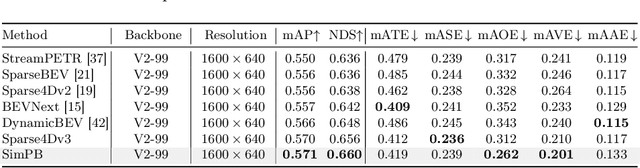
The field of autonomous driving has attracted considerable interest in approaches that directly infer 3D objects in the Bird's Eye View (BEV) from multiple cameras. Some attempts have also explored utilizing 2D detectors from single images to enhance the performance of 3D detection. However, these approaches rely on a two-stage process with separate detectors, where the 2D detection results are utilized only once for token selection or query initialization. In this paper, we present a single model termed SimPB, which simultaneously detects 2D objects in the perspective view and 3D objects in the BEV space from multiple cameras. To achieve this, we introduce a hybrid decoder consisting of several multi-view 2D decoder layers and several 3D decoder layers, specifically designed for their respective detection tasks. A Dynamic Query Allocation module and an Adaptive Query Aggregation module are proposed to continuously update and refine the interaction between 2D and 3D results, in a cyclic 3D-2D-3D manner. Additionally, Query-group Attention is utilized to strengthen the interaction among 2D queries within each camera group. In the experiments, we evaluate our method on the nuScenes dataset and demonstrate promising results for both 2D and 3D detection tasks. Our code is available at: https://github.com/nullmax-vision/SimPB.
EMIFF: Enhanced Multi-scale Image Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Feb 23, 2024In autonomous driving, cooperative perception makes use of multi-view cameras from both vehicles and infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Currently, two major challenges persist in vehicle-infrastructure cooperative 3D (VIC3D) object detection: $1)$ inherent pose errors when fusing multi-view images, caused by time asynchrony across cameras; $2)$ information loss in transmission process resulted from limited communication bandwidth. To address these issues, we propose a novel camera-based 3D detection framework for VIC3D task, Enhanced Multi-scale Image Feature Fusion (EMIFF). To fully exploit holistic perspectives from both vehicles and infrastructure, we propose Multi-scale Cross Attention (MCA) and Camera-aware Channel Masking (CCM) modules to enhance infrastructure and vehicle features at scale, spatial, and channel levels to correct the pose error introduced by camera asynchrony. We also introduce a Feature Compression (FC) module with channel and spatial compression blocks for transmission efficiency. Experiments show that EMIFF achieves SOTA on DAIR-V2X-C datasets, significantly outperforming previous early-fusion and late-fusion methods with comparable transmission costs.
TransformMix: Learning Transformation and Mixing Strategies from Data
Mar 19, 2024
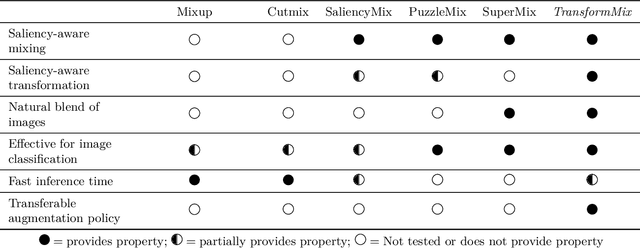

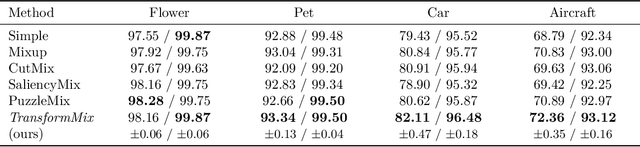
Data augmentation improves the generalization power of deep learning models by synthesizing more training samples. Sample-mixing is a popular data augmentation approach that creates additional data by combining existing samples. Recent sample-mixing methods, like Mixup and Cutmix, adopt simple mixing operations to blend multiple inputs. Although such a heuristic approach shows certain performance gains in some computer vision tasks, it mixes the images blindly and does not adapt to different datasets automatically. A mixing strategy that is effective for a particular dataset does not often generalize well to other datasets. If not properly configured, the methods may create misleading mixed images, which jeopardize the effectiveness of sample-mixing augmentations. In this work, we propose an automated approach, TransformMix, to learn better transformation and mixing augmentation strategies from data. In particular, TransformMix applies learned transformations and mixing masks to create compelling mixed images that contain correct and important information for the target tasks. We demonstrate the effectiveness of TransformMix on multiple datasets in transfer learning, classification, object detection, and knowledge distillation settings. Experimental results show that our method achieves better performance as well as efficiency when compared with strong sample-mixing baselines.
IAMCV Multi-Scenario Vehicle Interaction Dataset
Mar 13, 2024


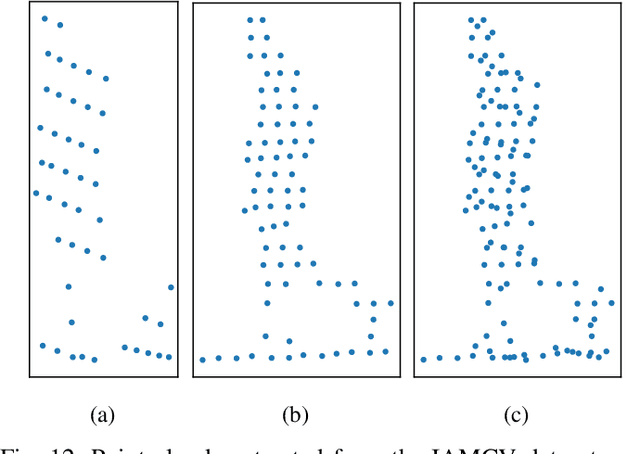
The acquisition and analysis of high-quality sensor data constitute an essential requirement in shaping the development of fully autonomous driving systems. This process is indispensable for enhancing road safety and ensuring the effectiveness of the technological advancements in the automotive industry. This study introduces the Interaction of Autonomous and Manually-Controlled Vehicles (IAMCV) dataset, a novel and extensive dataset focused on inter-vehicle interactions. The dataset, enriched with a sophisticated array of sensors such as Light Detection and Ranging, cameras, Inertial Measurement Unit/Global Positioning System, and vehicle bus data acquisition, provides a comprehensive representation of real-world driving scenarios that include roundabouts, intersections, country roads, and highways, recorded across diverse locations in Germany. Furthermore, the study shows the versatility of the IAMCV dataset through several proof-of-concept use cases. Firstly, an unsupervised trajectory clustering algorithm illustrates the dataset's capability in categorizing vehicle movements without the need for labeled training data. Secondly, we compare an online camera calibration method with the Robot Operating System-based standard, using images captured in the dataset. Finally, a preliminary test employing the YOLOv8 object-detection model is conducted, augmented by reflections on the transferability of object detection across various LIDAR resolutions. These use cases underscore the practical utility of the collected dataset, emphasizing its potential to advance research and innovation in the area of intelligent vehicles.
HASSOD: Hierarchical Adaptive Self-Supervised Object Detection
Feb 05, 2024The human visual perception system demonstrates exceptional capabilities in learning without explicit supervision and understanding the part-to-whole composition of objects. Drawing inspiration from these two abilities, we propose Hierarchical Adaptive Self-Supervised Object Detection (HASSOD), a novel approach that learns to detect objects and understand their compositions without human supervision. HASSOD employs a hierarchical adaptive clustering strategy to group regions into object masks based on self-supervised visual representations, adaptively determining the number of objects per image. Furthermore, HASSOD identifies the hierarchical levels of objects in terms of composition, by analyzing coverage relations between masks and constructing tree structures. This additional self-supervised learning task leads to improved detection performance and enhanced interpretability. Lastly, we abandon the inefficient multi-round self-training process utilized in prior methods and instead adapt the Mean Teacher framework from semi-supervised learning, which leads to a smoother and more efficient training process. Through extensive experiments on prevalent image datasets, we demonstrate the superiority of HASSOD over existing methods, thereby advancing the state of the art in self-supervised object detection. Notably, we improve Mask AR from 20.2 to 22.5 on LVIS, and from 17.0 to 26.0 on SA-1B. Project page: https://HASSOD-NeurIPS23.github.io.
RAR: Retrieving And Ranking Augmented MLLMs for Visual Recognition
Mar 20, 2024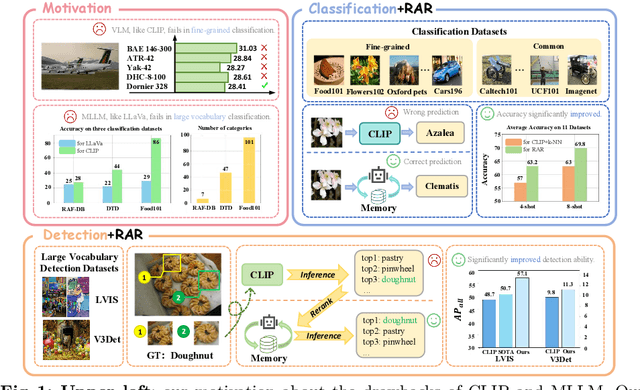
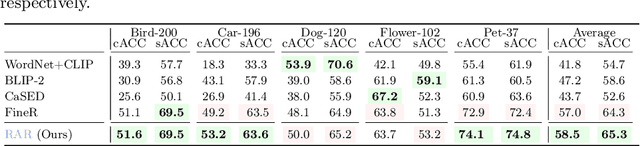
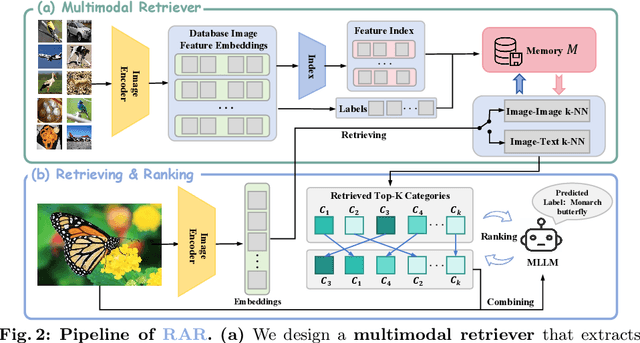
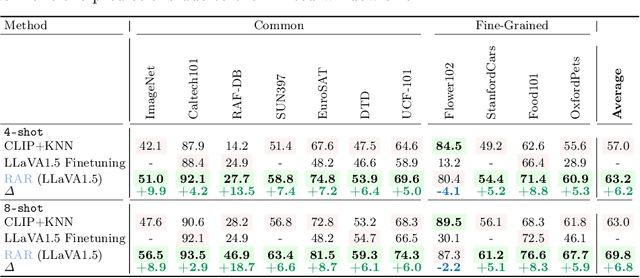
CLIP (Contrastive Language-Image Pre-training) uses contrastive learning from noise image-text pairs to excel at recognizing a wide array of candidates, yet its focus on broad associations hinders the precision in distinguishing subtle differences among fine-grained items. Conversely, Multimodal Large Language Models (MLLMs) excel at classifying fine-grained categories, thanks to their substantial knowledge from pre-training on web-level corpora. However, the performance of MLLMs declines with an increase in category numbers, primarily due to growing complexity and constraints of limited context window size. To synergize the strengths of both approaches and enhance the few-shot/zero-shot recognition abilities for datasets characterized by extensive and fine-grained vocabularies, this paper introduces RAR, a Retrieving And Ranking augmented method for MLLMs. We initially establish a multi-modal retriever based on CLIP to create and store explicit memory for different categories beyond the immediate context window. During inference, RAR retrieves the top-k similar results from the memory and uses MLLMs to rank and make the final predictions. Our proposed approach not only addresses the inherent limitations in fine-grained recognition but also preserves the model's comprehensive knowledge base, significantly boosting accuracy across a range of vision-language recognition tasks. Notably, our approach demonstrates a significant improvement in performance on 5 fine-grained visual recognition benchmarks, 11 few-shot image recognition datasets, and the 2 object detection datasets under the zero-shot recognition setting.
Improving Object Detection Quality in Football Through Super-Resolution Techniques
Jan 31, 2024This study explores the potential of super-resolution techniques in enhancing object detection accuracy in football. Given the sport's fast-paced nature and the critical importance of precise object (e.g. ball, player) tracking for both analysis and broadcasting, super-resolution could offer significant improvements. We investigate how advanced image processing through super-resolution impacts the accuracy and reliability of object detection algorithms in processing football match footage. Our methodology involved applying state-of-the-art super-resolution techniques to a diverse set of football match videos from SoccerNet, followed by object detection using Faster R-CNN. The performance of these algorithms, both with and without super-resolution enhancement, was rigorously evaluated in terms of detection accuracy. The results indicate a marked improvement in object detection accuracy when super-resolution preprocessing is applied. The improvement of object detection through the integration of super-resolution techniques yields significant benefits, especially for low-resolution scenarios, with a notable 12\% increase in mean Average Precision (mAP) at an IoU (Intersection over Union) range of 0.50:0.95 for 320x240 size images when increasing the resolution fourfold using RLFN. As the dimensions increase, the magnitude of improvement becomes more subdued; however, a discernible improvement in the quality of detection is consistently evident. Additionally, we discuss the implications of these findings for real-time sports analytics, player tracking, and the overall viewing experience. The study contributes to the growing field of sports technology by demonstrating the practical benefits and limitations of integrating super-resolution techniques in football analytics and broadcasting.
TrajectoryNAS: A Neural Architecture Search for Trajectory Prediction
Mar 18, 2024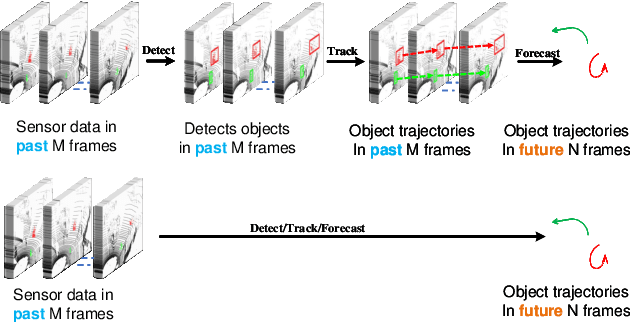
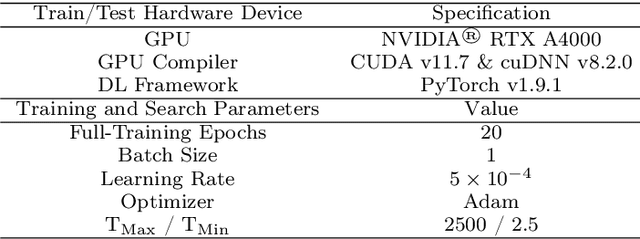
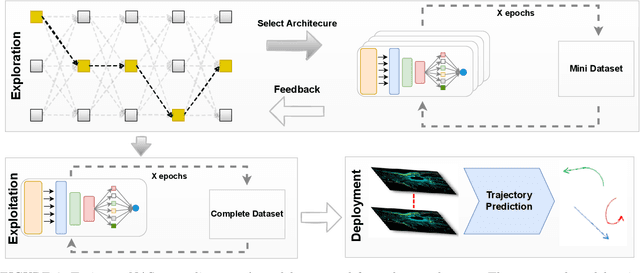

Autonomous driving systems are a rapidly evolving technology that enables driverless car production. Trajectory prediction is a critical component of autonomous driving systems, enabling cars to anticipate the movements of surrounding objects for safe navigation. Trajectory prediction using Lidar point-cloud data performs better than 2D images due to providing 3D information. However, processing point-cloud data is more complicated and time-consuming than 2D images. Hence, state-of-the-art 3D trajectory predictions using point-cloud data suffer from slow and erroneous predictions. This paper introduces TrajectoryNAS, a pioneering method that focuses on utilizing point cloud data for trajectory prediction. By leveraging Neural Architecture Search (NAS), TrajectoryNAS automates the design of trajectory prediction models, encompassing object detection, tracking, and forecasting in a cohesive manner. This approach not only addresses the complex interdependencies among these tasks but also emphasizes the importance of accuracy and efficiency in trajectory modeling. Through empirical studies, TrajectoryNAS demonstrates its effectiveness in enhancing the performance of autonomous driving systems, marking a significant advancement in the field.Experimental results reveal that TrajcetoryNAS yield a minimum of 4.8 higger accuracy and 1.1* lower latency over competing methods on the NuScenes dataset.
Few-Shot Object Detection with Sparse Context Transformers
Feb 14, 2024Few-shot detection is a major task in pattern recognition which seeks to localize objects using models trained with few labeled data. One of the mainstream few-shot methods is transfer learning which consists in pretraining a detection model in a source domain prior to its fine-tuning in a target domain. However, it is challenging for fine-tuned models to effectively identify new classes in the target domain, particularly when the underlying labeled training data are scarce. In this paper, we devise a novel sparse context transformer (SCT) that effectively leverages object knowledge in the source domain, and automatically learns a sparse context from only few training images in the target domain. As a result, it combines different relevant clues in order to enhance the discrimination power of the learned detectors and reduce class confusion. We evaluate the proposed method on two challenging few-shot object detection benchmarks, and empirical results show that the proposed method obtains competitive performance compared to the related state-of-the-art.