 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
FriendNet: Detection-Friendly Dehazing Network
Mar 07, 2024
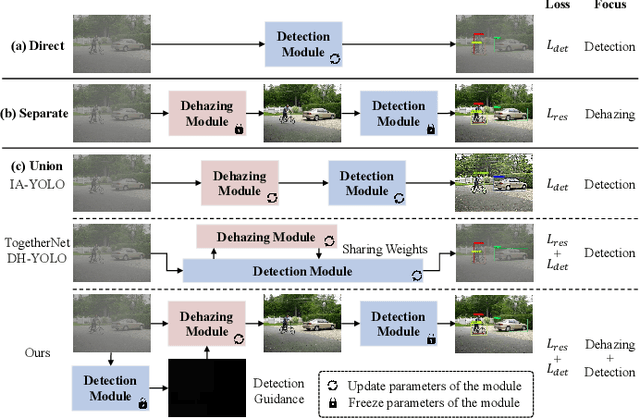
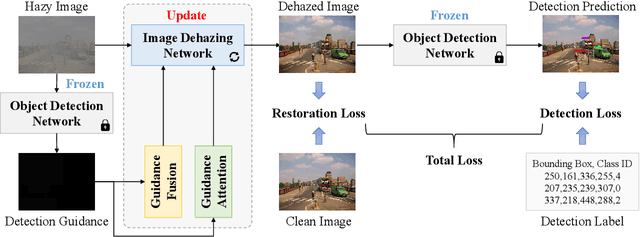
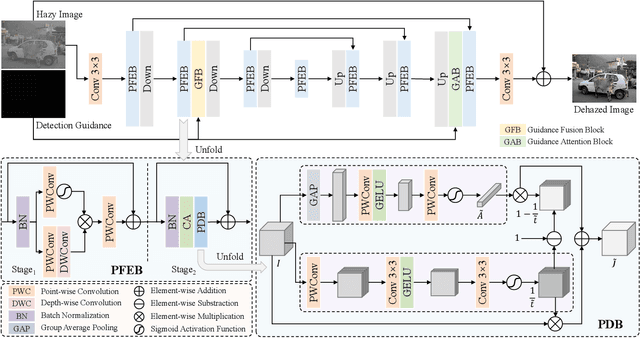
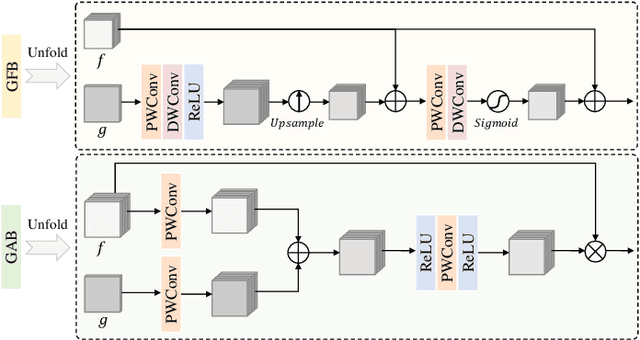
Adverse weather conditions often impair the quality of captured images, inevitably inducing cutting-edge object detection models for advanced driver assistance systems (ADAS) and autonomous driving. In this paper, we raise an intriguing question: can the combination of image restoration and object detection enhance detection performance in adverse weather conditions? To answer it, we propose an effective architecture that bridges image dehazing and object detection together via guidance information and task-driven learning to achieve detection-friendly dehazing, termed FriendNet. FriendNet aims to deliver both high-quality perception and high detection capacity. Different from existing efforts that intuitively treat image dehazing as pre-processing, FriendNet establishes a positive correlation between these two tasks. Clean features generated by the dehazing network potentially contribute to improvements in object detection performance. Conversely, object detection crucially guides the learning process of the image dehazing network under the task-driven learning scheme. We shed light on how downstream tasks can guide upstream dehazing processes, considering both network architecture and learning objectives. We design Guidance Fusion Block (GFB) and Guidance Attention Block (GAB) to facilitate the integration of detection information into the network. Furthermore, the incorporation of the detection task loss aids in refining the optimization process. Additionally, we introduce a new Physics-aware Feature Enhancement Block (PFEB), which integrates physics-based priors to enhance the feature extraction and representation capabilities. Extensive experiments on synthetic and real-world datasets demonstrate the superiority of our method over state-of-the-art methods on both image quality and detection precision. Our source code is available at https://github.com/fanyihua0309/FriendNet.
Entity6K: A Large Open-Domain Evaluation Dataset for Real-World Entity Recognition
Mar 19, 2024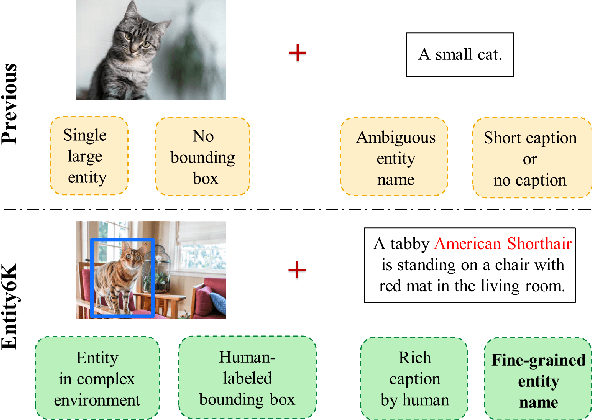

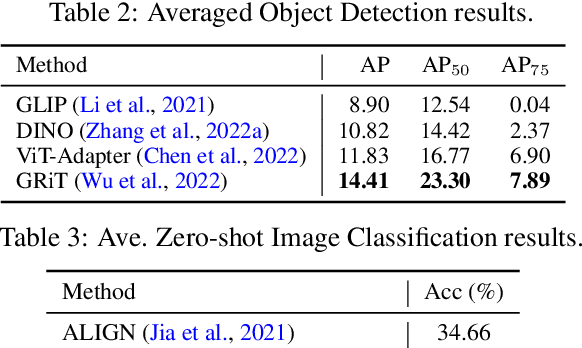
Open-domain real-world entity recognition is essential yet challenging, involving identifying various entities in diverse environments. The lack of a suitable evaluation dataset has been a major obstacle in this field due to the vast number of entities and the extensive human effort required for data curation. We introduce Entity6K, a comprehensive dataset for real-world entity recognition, featuring 5,700 entities across 26 categories, each supported by 5 human-verified images with annotations. Entity6K offers a diverse range of entity names and categorizations, addressing a gap in existing datasets. We conducted benchmarks with existing models on tasks like image captioning, object detection, zero-shot classification, and dense captioning to demonstrate Entity6K's effectiveness in evaluating models' entity recognition capabilities. We believe Entity6K will be a valuable resource for advancing accurate entity recognition in open-domain settings.
Wildfire danger prediction optimization with transfer learning
Mar 19, 2024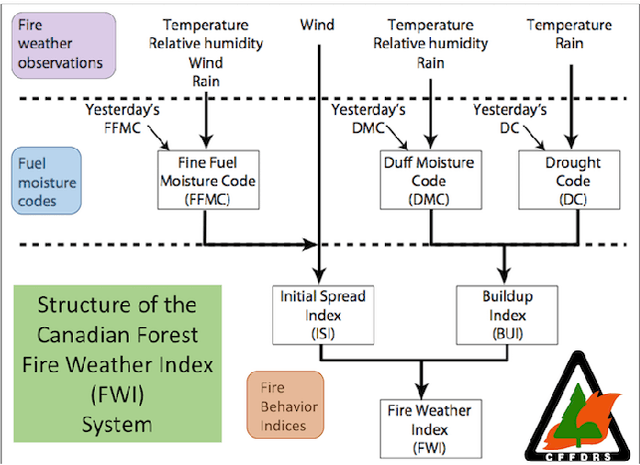
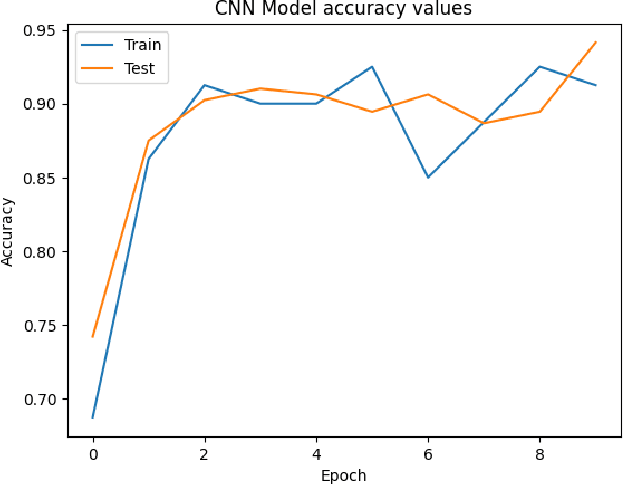
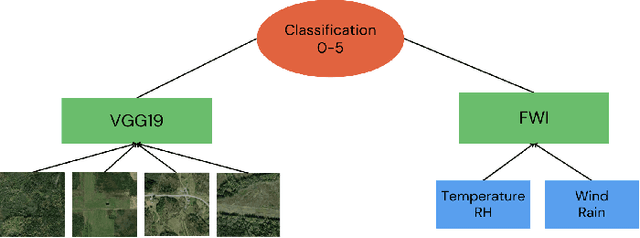

Convolutional Neural Networks (CNNs) have proven instrumental across various computer science domains, enabling advancements in object detection, classification, and anomaly detection. This paper explores the application of CNNs to analyze geospatial data specifically for identifying wildfire-affected areas. Leveraging transfer learning techniques, we fine-tuned CNN hyperparameters and integrated the Canadian Fire Weather Index (FWI) to assess moisture conditions. The study establishes a methodology for computing wildfire risk levels on a scale of 0 to 5, dynamically linked to weather patterns. Notably, through the integration of transfer learning, the CNN model achieved an impressive accuracy of 95\% in identifying burnt areas. This research sheds light on the inner workings of CNNs and their practical, real-time utility in predicting and mitigating wildfires. By combining transfer learning and CNNs, this study contributes a robust approach to assess burnt areas, facilitating timely interventions and preventative measures against conflagrations.
IllusionVQA: A Challenging Optical Illusion Dataset for Vision Language Models
Mar 30, 2024The advent of Vision Language Models (VLM) has allowed researchers to investigate the visual understanding of a neural network using natural language. Beyond object classification and detection, VLMs are capable of visual comprehension and common-sense reasoning. This naturally led to the question: How do VLMs respond when the image itself is inherently unreasonable? To this end, we present IllusionVQA: a diverse dataset of challenging optical illusions and hard-to-interpret scenes to test the capability of VLMs in two distinct multiple-choice VQA tasks - comprehension and soft localization. GPT4V, the best-performing VLM, achieves 62.99% accuracy (4-shot) on the comprehension task and 49.7% on the localization task (4-shot and Chain-of-Thought). Human evaluation reveals that humans achieve 91.03% and 100% accuracy in comprehension and localization. We discover that In-Context Learning (ICL) and Chain-of-Thought reasoning substantially degrade the performance of GeminiPro on the localization task. Tangentially, we discover a potential weakness in the ICL capabilities of VLMs: they fail to locate optical illusions even when the correct answer is in the context window as a few-shot example.
Enhancing Embodied Object Detection through Language-Image Pre-training and Implicit Object Memory
Feb 06, 2024Deep-learning and large scale language-image training have produced image object detectors that generalise well to diverse environments and semantic classes. However, single-image object detectors trained on internet data are not optimally tailored for the embodied conditions inherent in robotics. Instead, robots must detect objects from complex multi-modal data streams involving depth, localisation and temporal correlation, a task termed embodied object detection. Paradigms such as Video Object Detection (VOD) and Semantic Mapping have been proposed to leverage such embodied data streams, but existing work fails to enhance performance using language-image training. In response, we investigate how an image object detector pre-trained using language-image data can be extended to perform embodied object detection. We propose a novel implicit object memory that uses projective geometry to aggregate the features of detected objects across long temporal horizons. The spatial and temporal information accumulated in memory is then used to enhance the image features of the base detector. When tested on embodied data streams sampled from diverse indoor scenes, our approach improves the base object detector by 3.09 mAP, outperforming alternative external memories designed for VOD and Semantic Mapping. Our method also shows a significant improvement of 16.90 mAP relative to baselines that perform embodied object detection without first training on language-image data, and is robust to sensor noise and domain shift experienced in real-world deployment.
As Firm As Their Foundations: Can open-sourced foundation models be used to create adversarial examples for downstream tasks?
Mar 19, 2024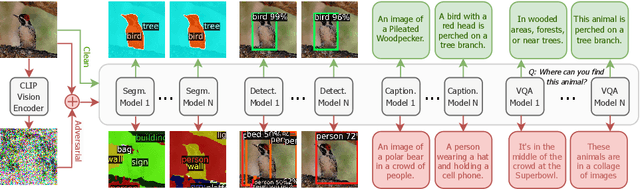
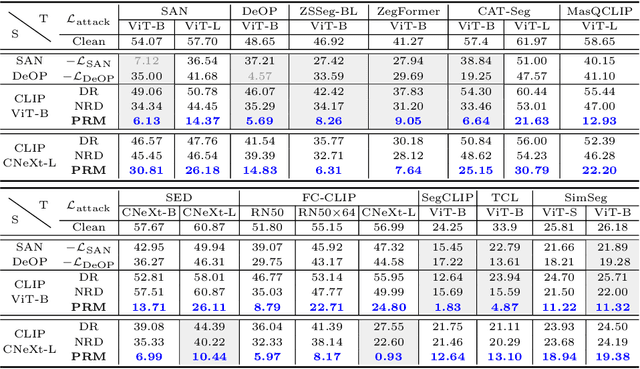
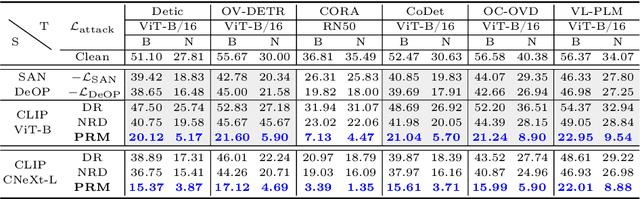
Foundation models pre-trained on web-scale vision-language data, such as CLIP, are widely used as cornerstones of powerful machine learning systems. While pre-training offers clear advantages for downstream learning, it also endows downstream models with shared adversarial vulnerabilities that can be easily identified through the open-sourced foundation model. In this work, we expose such vulnerabilities in CLIP's downstream models and show that foundation models can serve as a basis for attacking their downstream systems. In particular, we propose a simple yet effective adversarial attack strategy termed Patch Representation Misalignment (PRM). Solely based on open-sourced CLIP vision encoders, this method produces adversaries that simultaneously fool more than 20 downstream models spanning 4 common vision-language tasks (semantic segmentation, object detection, image captioning and visual question-answering). Our findings highlight the concerning safety risks introduced by the extensive usage of public foundational models in the development of downstream systems, calling for extra caution in these scenarios.
SceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
Mar 19, 2024

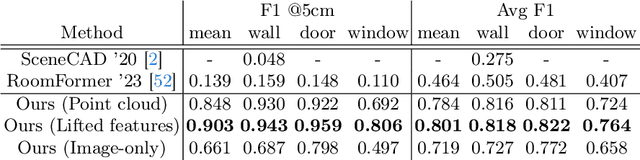
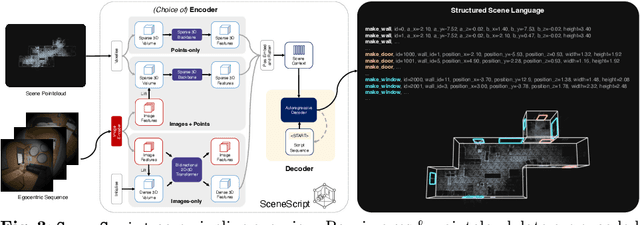
We introduce SceneScript, a method that directly produces full scene models as a sequence of structured language commands using an autoregressive, token-based approach. Our proposed scene representation is inspired by recent successes in transformers & LLMs, and departs from more traditional methods which commonly describe scenes as meshes, voxel grids, point clouds or radiance fields. Our method infers the set of structured language commands directly from encoded visual data using a scene language encoder-decoder architecture. To train SceneScript, we generate and release a large-scale synthetic dataset called Aria Synthetic Environments consisting of 100k high-quality in-door scenes, with photorealistic and ground-truth annotated renders of egocentric scene walkthroughs. Our method gives state-of-the art results in architectural layout estimation, and competitive results in 3D object detection. Lastly, we explore an advantage for SceneScript, which is the ability to readily adapt to new commands via simple additions to the structured language, which we illustrate for tasks such as coarse 3D object part reconstruction.
Cross-Domain Few-Shot Object Detection via Enhanced Open-Set Object Detector
Feb 05, 2024This paper addresses the challenge of cross-domain few-shot object detection (CD-FSOD), aiming to develop an accurate object detector for novel domains with minimal labeled examples. While transformer-based open-set detectors e.g., DE-ViT~\cite{zhang2023detect} have excelled in both open-vocabulary object detection and traditional few-shot object detection, detecting categories beyond those seen during training, we thus naturally raise two key questions: 1) can such open-set detection methods easily generalize to CD-FSOD? 2) If no, how to enhance the results of open-set methods when faced with significant domain gaps? To address the first question, we introduce several metrics to quantify domain variances and establish a new CD-FSOD benchmark with diverse domain metric values. Some State-Of-The-Art (SOTA) open-set object detection methods are evaluated on this benchmark, with evident performance degradation observed across out-of-domain datasets. This indicates the failure of adopting open-set detectors directly for CD-FSOD. Sequentially, to overcome the performance degradation issue and also to answer the second proposed question, we endeavor to enhance the vanilla DE-ViT. With several novel components including finetuning, a learnable prototype module, and a lightweight attention module, we present an improved Cross-Domain Vision Transformer for CD-FSOD (CD-ViTO). Experiments show that our CD-ViTO achieves impressive results on both out-of-domain and in-domain target datasets, establishing new SOTAs for both CD-FSOD and FSOD. All the datasets, codes, and models will be released to the community.
Just Add $100 More: Augmenting NeRF-based Pseudo-LiDAR Point Cloud for Resolving Class-imbalance Problem
Mar 20, 2024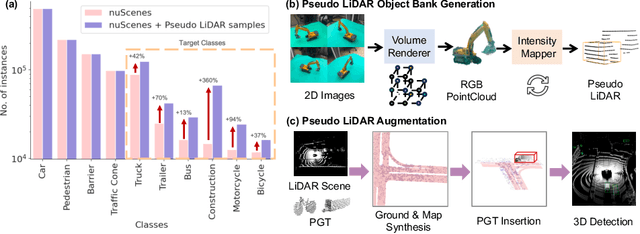
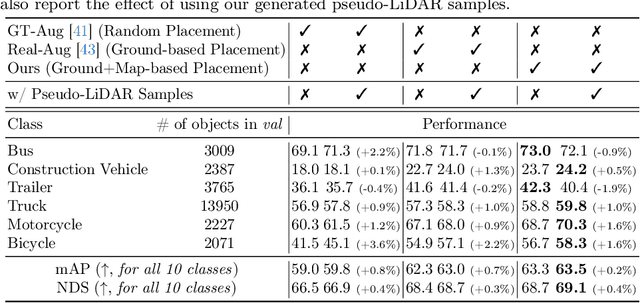
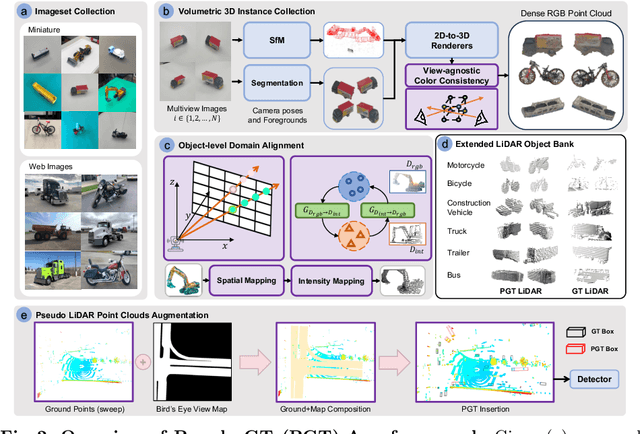
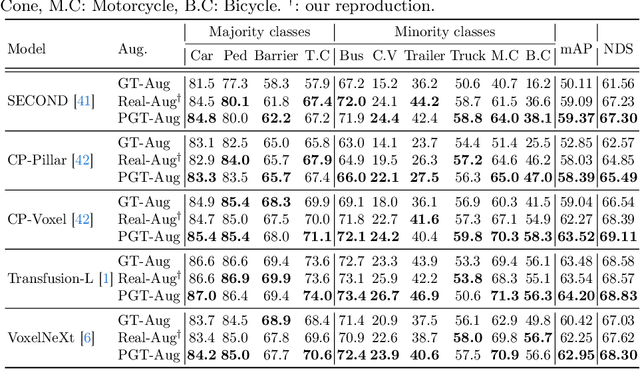
Typical LiDAR-based 3D object detection models are trained in a supervised manner with real-world data collection, which is often imbalanced over classes (or long-tailed). To deal with it, augmenting minority-class examples by sampling ground truth (GT) LiDAR points from a database and pasting them into a scene of interest is often used, but challenges still remain: inflexibility in locating GT samples and limited sample diversity. In this work, we propose to leverage pseudo-LiDAR point clouds generated (at a low cost) from videos capturing a surround view of miniatures or real-world objects of minor classes. Our method, called Pseudo Ground Truth Augmentation (PGT-Aug), consists of three main steps: (i) volumetric 3D instance reconstruction using a 2D-to-3D view synthesis model, (ii) object-level domain alignment with LiDAR intensity estimation and (iii) a hybrid context-aware placement method from ground and map information. We demonstrate the superiority and generality of our method through performance improvements in extensive experiments conducted on three popular benchmarks, i.e., nuScenes, KITTI, and Lyft, especially for the datasets with large domain gaps captured by different LiDAR configurations. Our code and data will be publicly available upon publication.
TAPTR: Tracking Any Point with Transformers as Detection
Mar 19, 2024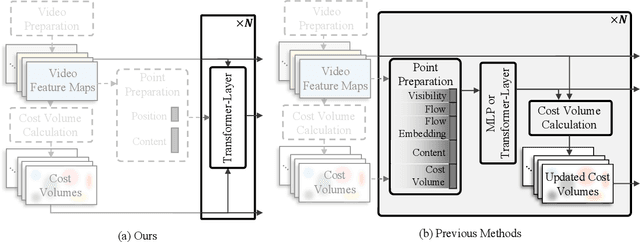
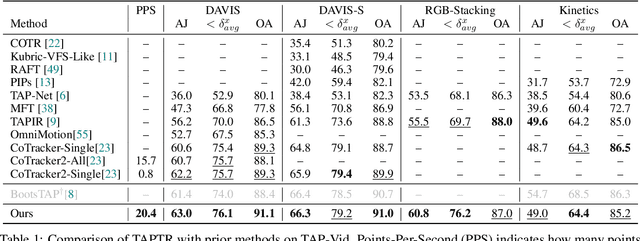
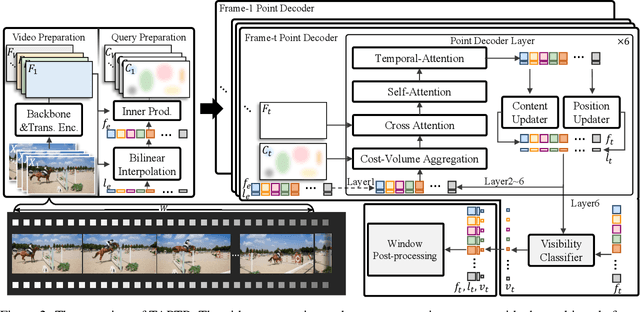

In this paper, we propose a simple and strong framework for Tracking Any Point with TRansformers (TAPTR). Based on the observation that point tracking bears a great resemblance to object detection and tracking, we borrow designs from DETR-like algorithms to address the task of TAP. In the proposed framework, in each video frame, each tracking point is represented as a point query, which consists of a positional part and a content part. As in DETR, each query (its position and content feature) is naturally updated layer by layer. Its visibility is predicted by its updated content feature. Queries belonging to the same tracking point can exchange information through self-attention along the temporal dimension. As all such operations are well-designed in DETR-like algorithms, the model is conceptually very simple. We also adopt some useful designs such as cost volume from optical flow models and develop simple designs to provide long temporal information while mitigating the feature drifting issue. Our framework demonstrates strong performance with state-of-the-art performance on various TAP datasets with faster inference speed.