 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Improving Distant 3D Object Detection Using 2D Box Supervision
Mar 14, 2024
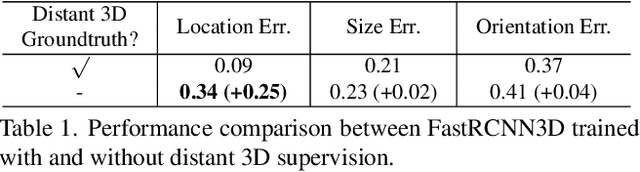
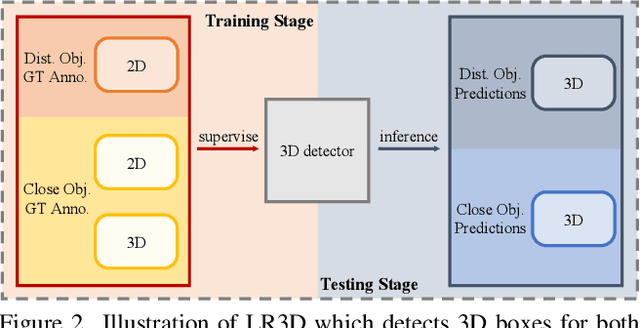
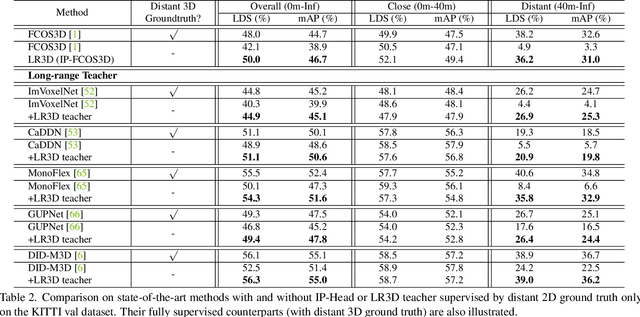
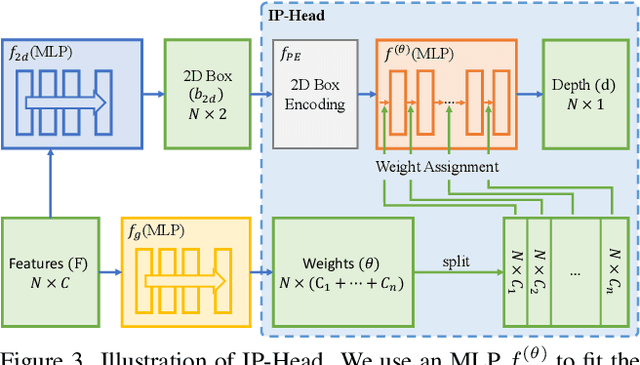
Improving the detection of distant 3d objects is an important yet challenging task. For camera-based 3D perception, the annotation of 3d bounding relies heavily on LiDAR for accurate depth information. As such, the distance of annotation is often limited due to the sparsity of LiDAR points on distant objects, which hampers the capability of existing detectors for long-range scenarios. We address this challenge by considering only 2D box supervision for distant objects since they are easy to annotate. We propose LR3D, a framework that learns to recover the missing depth of distant objects. LR3D adopts an implicit projection head to learn the generation of mapping between 2D boxes and depth using the 3D supervision on close objects. This mapping allows the depth estimation of distant objects conditioned on their 2D boxes, making long-range 3D detection with 2D supervision feasible. Experiments show that without distant 3D annotations, LR3D allows camera-based methods to detect distant objects (over 200m) with comparable accuracy to full 3D supervision. Our framework is general, and could widely benefit 3D detection methods to a large extent.
Self-supervised co-salient object detection via feature correspondence at multiple scales
Mar 17, 2024

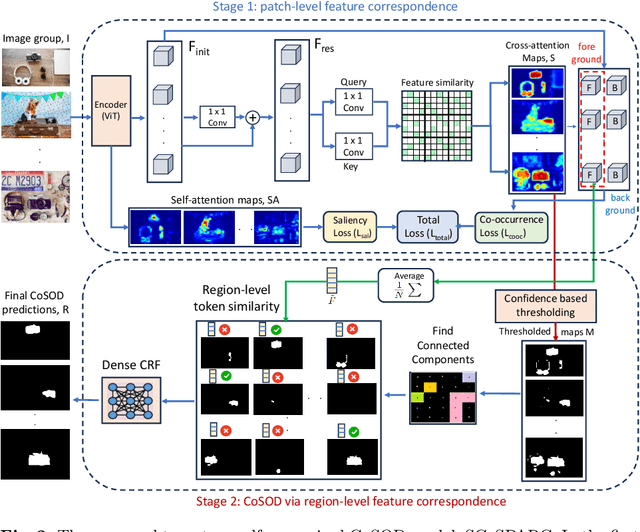
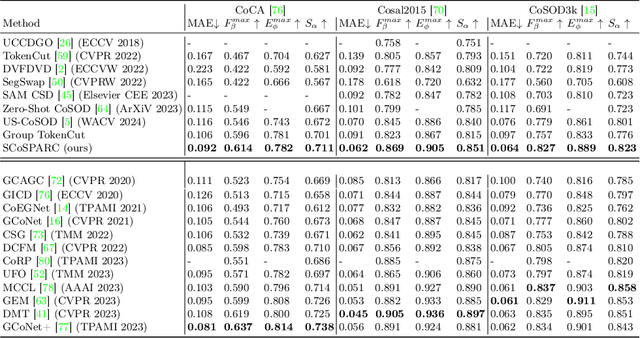
Our paper introduces a novel two-stage self-supervised approach for detecting co-occurring salient objects (CoSOD) in image groups without requiring segmentation annotations. Unlike existing unsupervised methods that rely solely on patch-level information (e.g. clustering patch descriptors) or on computation heavy off-the-shelf components for CoSOD, our lightweight model leverages feature correspondences at both patch and region levels, significantly improving prediction performance. In the first stage, we train a self-supervised network that detects co-salient regions by computing local patch-level feature correspondences across images. We obtain the segmentation predictions using confidence-based adaptive thresholding. In the next stage, we refine these intermediate segmentations by eliminating the detected regions (within each image) whose averaged feature representations are dissimilar to the foreground feature representation averaged across all the cross-attention maps (from the previous stage). Extensive experiments on three CoSOD benchmark datasets show that our self-supervised model outperforms the corresponding state-of-the-art models by a huge margin (e.g. on the CoCA dataset, our model has a 13.7% F-measure gain over the SOTA unsupervised CoSOD model). Notably, our self-supervised model also outperforms several recent fully supervised CoSOD models on the three test datasets (e.g., on the CoCA dataset, our model has a 4.6% F-measure gain over a recent supervised CoSOD model).
VRSO: Visual-Centric Reconstruction for Static Object Annotation
Mar 22, 2024As a part of the perception results of intelligent driving systems, static object detection (SOD) in 3D space provides crucial cues for driving environment understanding. With the rapid deployment of deep neural networks for SOD tasks, the demand for high-quality training samples soars. The traditional, also reliable, way is manual labeling over the dense LiDAR point clouds and reference images. Though most public driving datasets adopt this strategy to provide SOD ground truth (GT), it is still expensive (requires LiDAR scanners) and low-efficient (time-consuming and unscalable) in practice. This paper introduces VRSO, a visual-centric approach for static object annotation. VRSO is distinguished in low cost, high efficiency, and high quality: (1) It recovers static objects in 3D space with only camera images as input, and (2) manual labeling is barely involved since GT for SOD tasks is generated based on an automatic reconstruction and annotation pipeline. (3) Experiments on the Waymo Open Dataset show that the mean reprojection error from VRSO annotation is only 2.6 pixels, around four times lower than the Waymo labeling (10.6 pixels). Source code is available at: https://github.com/CaiYingFeng/VRSO.
An In-Depth Analysis of Data Reduction Methods for Sustainable Deep Learning
Mar 22, 2024In recent years, Deep Learning has gained popularity for its ability to solve complex classification tasks, increasingly delivering better results thanks to the development of more accurate models, the availability of huge volumes of data and the improved computational capabilities of modern computers. However, these improvements in performance also bring efficiency problems, related to the storage of datasets and models, and to the waste of energy and time involved in both the training and inference processes. In this context, data reduction can help reduce energy consumption when training a deep learning model. In this paper, we present up to eight different methods to reduce the size of a tabular training dataset, and we develop a Python package to apply them. We also introduce a representativeness metric based on topology to measure how similar are the reduced datasets and the full training dataset. Additionally, we develop a methodology to apply these data reduction methods to image datasets for object detection tasks. Finally, we experimentally compare how these data reduction methods affect the representativeness of the reduced dataset, the energy consumption and the predictive performance of the model.
DetDiffusion: Synergizing Generative and Perceptive Models for Enhanced Data Generation and Perception
Mar 20, 2024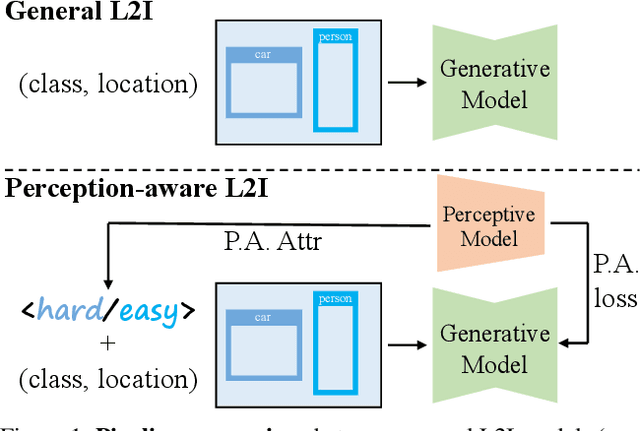
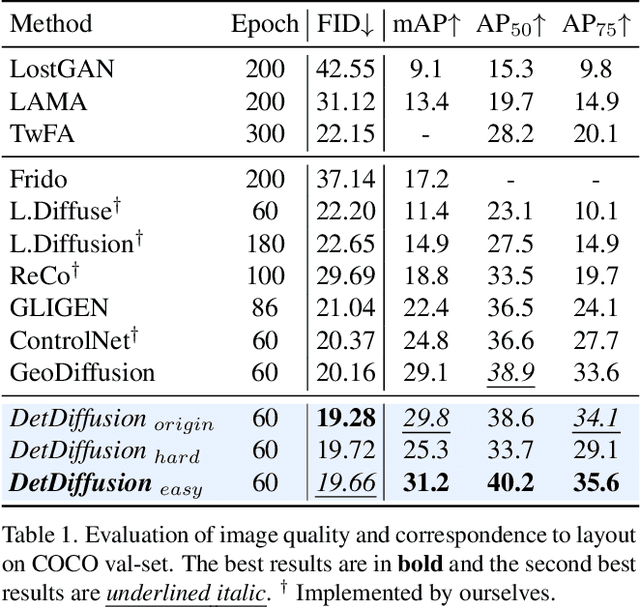
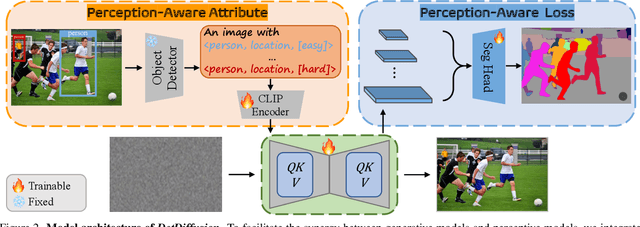
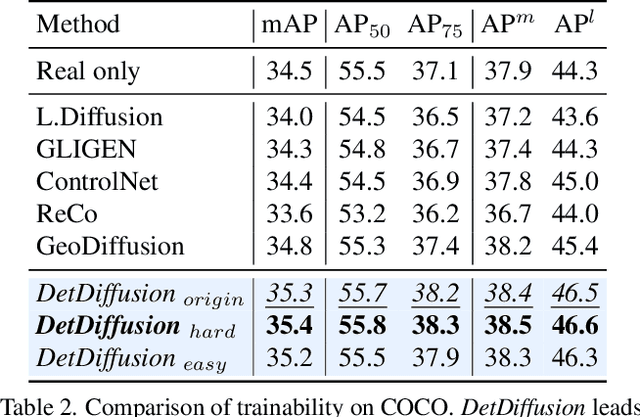
Current perceptive models heavily depend on resource-intensive datasets, prompting the need for innovative solutions. Leveraging recent advances in diffusion models, synthetic data, by constructing image inputs from various annotations, proves beneficial for downstream tasks. While prior methods have separately addressed generative and perceptive models, DetDiffusion, for the first time, harmonizes both, tackling the challenges in generating effective data for perceptive models. To enhance image generation with perceptive models, we introduce perception-aware loss (P.A. loss) through segmentation, improving both quality and controllability. To boost the performance of specific perceptive models, our method customizes data augmentation by extracting and utilizing perception-aware attribute (P.A. Attr) during generation. Experimental results from the object detection task highlight DetDiffusion's superior performance, establishing a new state-of-the-art in layout-guided generation. Furthermore, image syntheses from DetDiffusion can effectively augment training data, significantly enhancing downstream detection performance.
Poly Kernel Inception Network for Remote Sensing Detection
Mar 20, 2024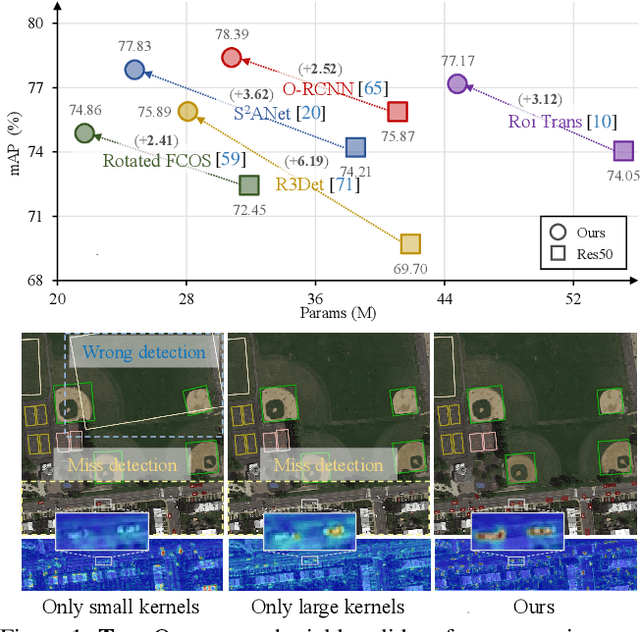
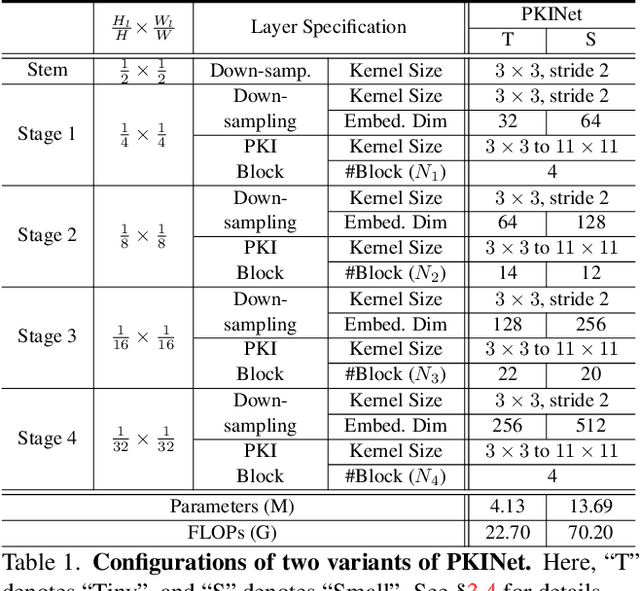
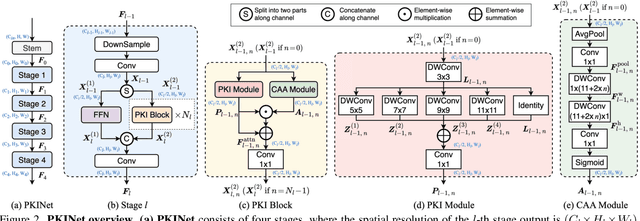
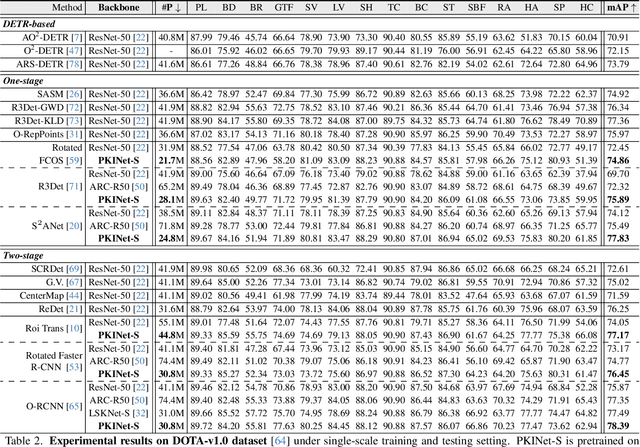
Object detection in remote sensing images (RSIs) often suffers from several increasing challenges, including the large variation in object scales and the diverse-ranging context. Prior methods tried to address these challenges by expanding the spatial receptive field of the backbone, either through large-kernel convolution or dilated convolution. However, the former typically introduces considerable background noise, while the latter risks generating overly sparse feature representations. In this paper, we introduce the Poly Kernel Inception Network (PKINet) to handle the above challenges. PKINet employs multi-scale convolution kernels without dilation to extract object features of varying scales and capture local context. In addition, a Context Anchor Attention (CAA) module is introduced in parallel to capture long-range contextual information. These two components work jointly to advance the performance of PKINet on four challenging remote sensing detection benchmarks, namely DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R.
Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head
Mar 11, 2024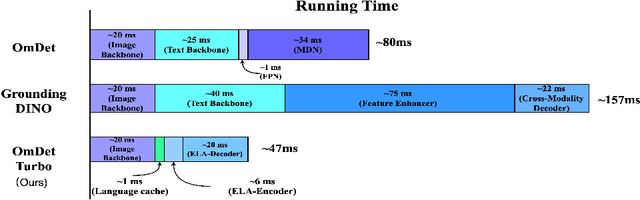
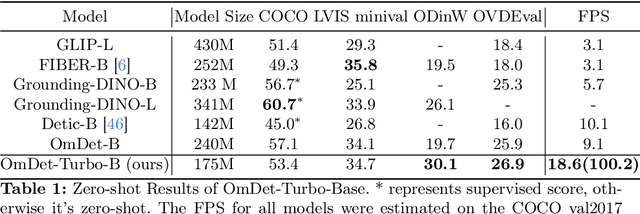
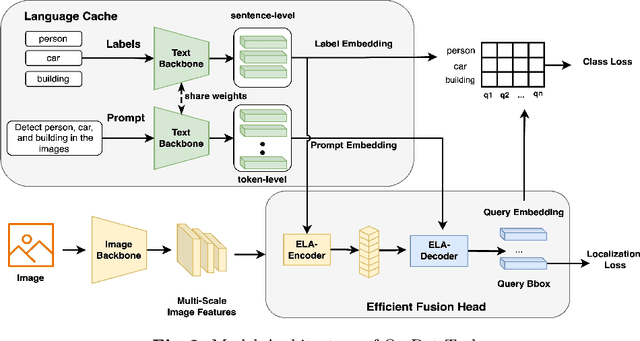

End-to-end transformer-based detectors (DETRs) have shown exceptional performance in both closed-set and open-vocabulary object detection (OVD) tasks through the integration of language modalities. However, their demanding computational requirements have hindered their practical application in real-time object detection (OD) scenarios. In this paper, we scrutinize the limitations of two leading models in the OVDEval benchmark, OmDet and Grounding-DINO, and introduce OmDet-Turbo. This novel transformer-based real-time OVD model features an innovative Efficient Fusion Head (EFH) module designed to alleviate the bottlenecks observed in OmDet and Grounding-DINO. Notably, OmDet-Turbo-Base achieves a 100.2 frames per second (FPS) with TensorRT and language cache techniques applied. Notably, in zero-shot scenarios on COCO and LVIS datasets, OmDet-Turbo achieves performance levels nearly on par with current state-of-the-art supervised models. Furthermore, it establishes new state-of-the-art benchmarks on ODinW and OVDEval, boasting an AP of 30.1 and an NMS-AP of 26.86, respectively. The practicality of OmDet-Turbo in industrial applications is underscored by its exceptional performance on benchmark datasets and superior inference speed, positioning it as a compelling choice for real-time object detection tasks. Code: \url{https://github.com/om-ai-lab/OmDet}
Towards Zero-shot Human-Object Interaction Detection via Vision-Language Integration
Mar 12, 2024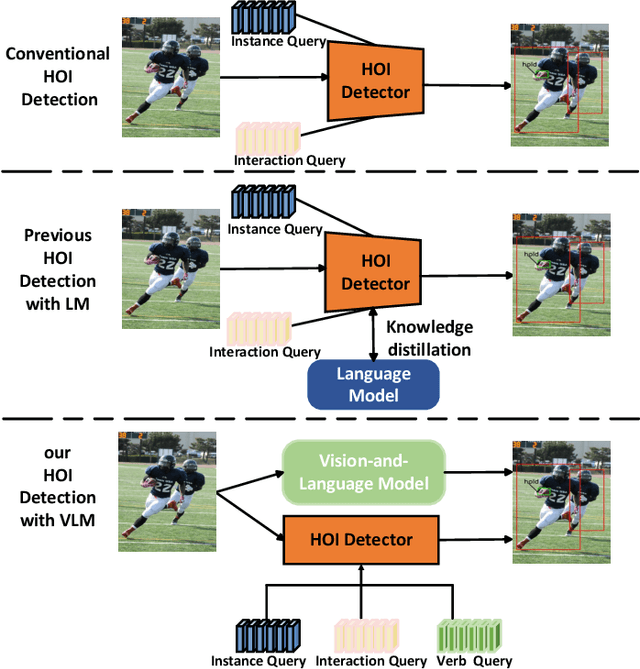
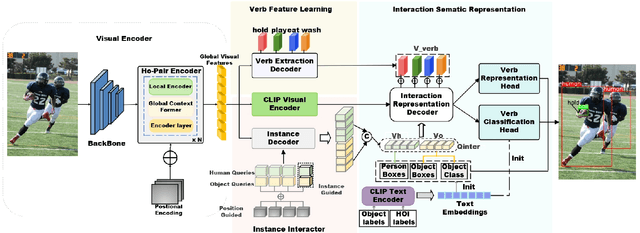
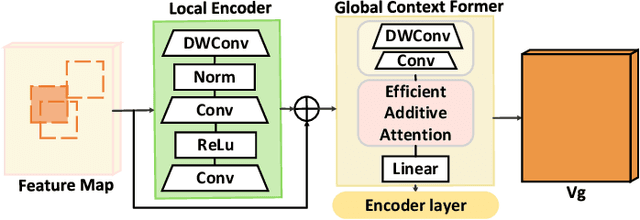
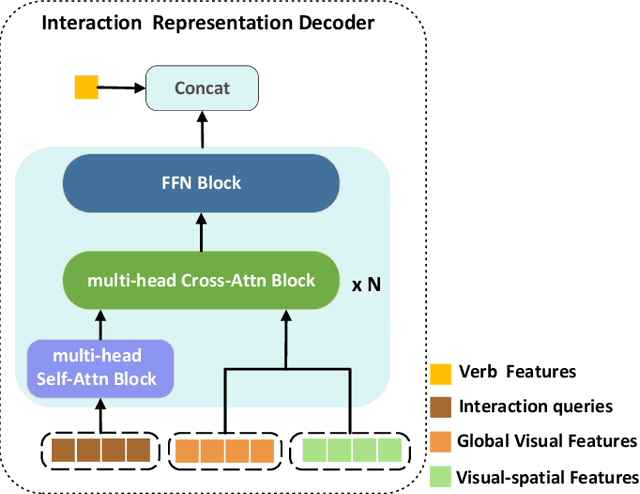
Human-object interaction (HOI) detection aims to locate human-object pairs and identify their interaction categories in images. Most existing methods primarily focus on supervised learning, which relies on extensive manual HOI annotations. In this paper, we propose a novel framework, termed Knowledge Integration to HOI (KI2HOI), that effectively integrates the knowledge of visual-language model to improve zero-shot HOI detection. Specifically, the verb feature learning module is designed based on visual semantics, by employing the verb extraction decoder to convert corresponding verb queries into interaction-specific category representations. We develop an effective additive self-attention mechanism to generate more comprehensive visual representations. Moreover, the innovative interaction representation decoder effectively extracts informative regions by integrating spatial and visual feature information through a cross-attention mechanism. To deal with zero-shot learning in low-data, we leverage a priori knowledge from the CLIP text encoder to initialize the linear classifier for enhanced interaction understanding. Extensive experiments conducted on the mainstream HICO-DET and V-COCO datasets demonstrate that our model outperforms the previous methods in various zero-shot and full-supervised settings.
EC-IoU: Orienting Safety for Object Detectors via Ego-Centric Intersection-over-Union
Mar 20, 2024This paper presents safety-oriented object detection via a novel Ego-Centric Intersection-over-Union (EC-IoU) measure, addressing practical concerns when applying state-of-the-art learning-based perception models in safety-critical domains such as autonomous driving. Concretely, we propose a weighting mechanism to refine the widely used IoU measure, allowing it to assign a higher score to a prediction that covers closer points of a ground-truth object from the ego agent's perspective. The proposed EC-IoU measure can be used in typical evaluation processes to select object detectors with higher safety-related performance for downstream tasks. It can also be integrated into common loss functions for model fine-tuning. While geared towards safety, our experiment with the KITTI dataset demonstrates the performance of a model trained on EC-IoU can be better than that of a variant trained on IoU in terms of mean Average Precision as well.
FriendNet: Detection-Friendly Dehazing Network
Mar 07, 2024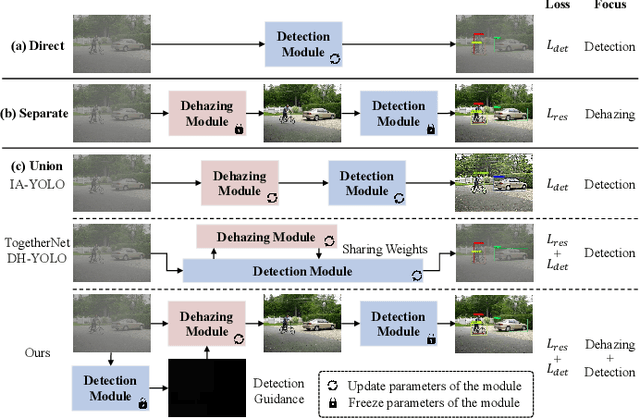
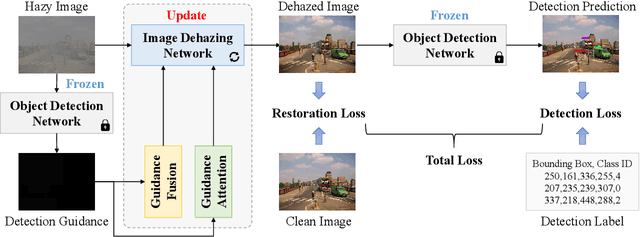
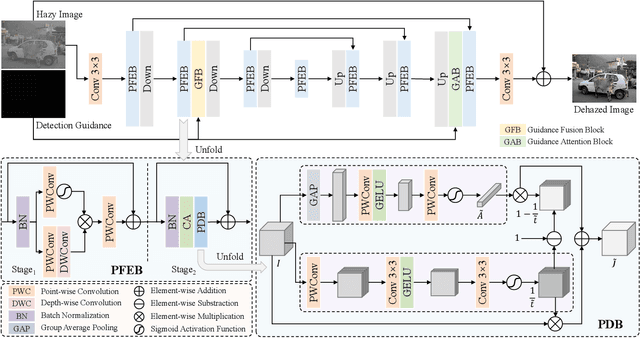
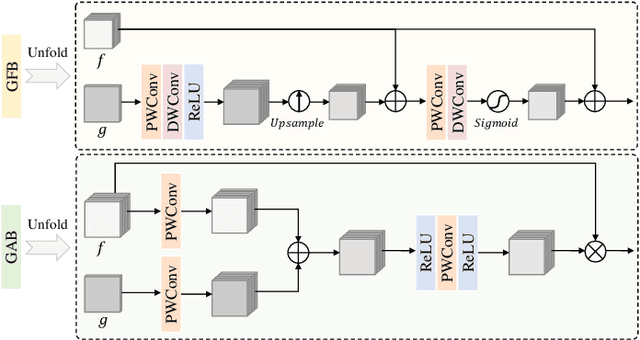
Adverse weather conditions often impair the quality of captured images, inevitably inducing cutting-edge object detection models for advanced driver assistance systems (ADAS) and autonomous driving. In this paper, we raise an intriguing question: can the combination of image restoration and object detection enhance detection performance in adverse weather conditions? To answer it, we propose an effective architecture that bridges image dehazing and object detection together via guidance information and task-driven learning to achieve detection-friendly dehazing, termed FriendNet. FriendNet aims to deliver both high-quality perception and high detection capacity. Different from existing efforts that intuitively treat image dehazing as pre-processing, FriendNet establishes a positive correlation between these two tasks. Clean features generated by the dehazing network potentially contribute to improvements in object detection performance. Conversely, object detection crucially guides the learning process of the image dehazing network under the task-driven learning scheme. We shed light on how downstream tasks can guide upstream dehazing processes, considering both network architecture and learning objectives. We design Guidance Fusion Block (GFB) and Guidance Attention Block (GAB) to facilitate the integration of detection information into the network. Furthermore, the incorporation of the detection task loss aids in refining the optimization process. Additionally, we introduce a new Physics-aware Feature Enhancement Block (PFEB), which integrates physics-based priors to enhance the feature extraction and representation capabilities. Extensive experiments on synthetic and real-world datasets demonstrate the superiority of our method over state-of-the-art methods on both image quality and detection precision. Our source code is available at https://github.com/fanyihua0309/FriendNet.