 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Object Detectors in the Open Environment: Challenges, Solutions, and Outlook
Apr 09, 2024
With the emergence of foundation models, deep learning-based object detectors have shown practical usability in closed set scenarios. However, for real-world tasks, object detectors often operate in open environments, where crucial factors (e.g., data distribution, objective) that influence model learning are often changing. The dynamic and intricate nature of the open environment poses novel and formidable challenges to object detectors. Unfortunately, current research on object detectors in open environments lacks a comprehensive analysis of their distinctive characteristics, challenges, and corresponding solutions, which hinders their secure deployment in critical real-world scenarios. This paper aims to bridge this gap by conducting a comprehensive review and analysis of object detectors in open environments. We initially identified limitations of key structural components within the existing detection pipeline and propose the open environment object detector challenge framework that includes four quadrants (i.e., out-of-domain, out-of-category, robust learning, and incremental learning) based on the dimensions of the data / target changes. For each quadrant of challenges in the proposed framework, we present a detailed description and systematic analysis of the overarching goals and core difficulties, systematically review the corresponding solutions, and benchmark their performance over multiple widely adopted datasets. In addition, we engage in a discussion of open problems and potential avenues for future research. This paper aims to provide a fresh, comprehensive, and systematic understanding of the challenges and solutions associated with open-environment object detectors, thus catalyzing the development of more solid applications in real-world scenarios. A project related to this survey can be found at https://github.com/LiangSiyuan21/OEOD_Survey.
Semantic Is Enough: Only Semantic Information For NeRF Reconstruction
Mar 24, 2024Recent research that combines implicit 3D representation with semantic information, like Semantic-NeRF, has proven that NeRF model could perform excellently in rendering 3D structures with semantic labels. This research aims to extend the Semantic Neural Radiance Fields (Semantic-NeRF) model by focusing solely on semantic output and removing the RGB output component. We reformulate the model and its training procedure to leverage only the cross-entropy loss between the model semantic output and the ground truth semantic images, removing the colour data traditionally used in the original Semantic-NeRF approach. We then conduct a series of identical experiments using the original and the modified Semantic-NeRF model. Our primary objective is to obverse the impact of this modification on the model performance by Semantic-NeRF, focusing on tasks such as scene understanding, object detection, and segmentation. The results offer valuable insights into the new way of rendering the scenes and provide an avenue for further research and development in semantic-focused 3D scene understanding.
MOTPose: Multi-object 6D Pose Estimation for Dynamic Video Sequences using Attention-based Temporal Fusion
Mar 14, 2024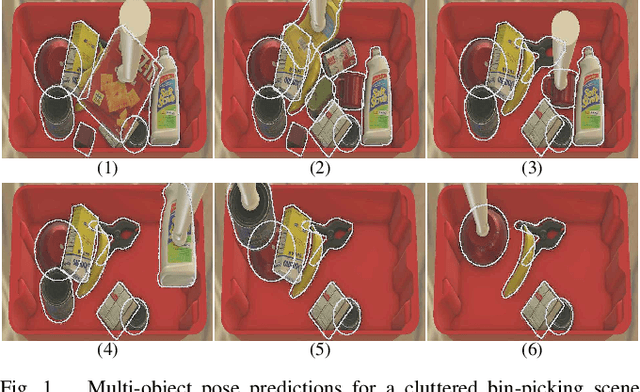
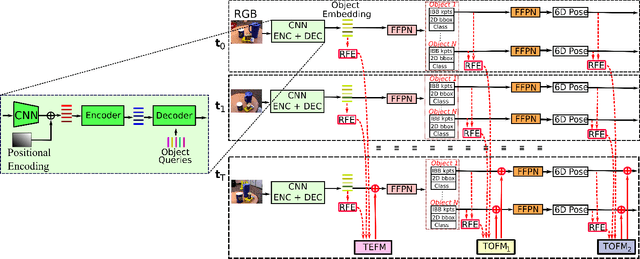
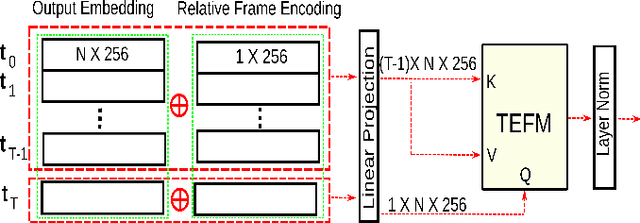

Cluttered bin-picking environments are challenging for pose estimation models. Despite the impressive progress enabled by deep learning, single-view RGB pose estimation models perform poorly in cluttered dynamic environments. Imbuing the rich temporal information contained in the video of scenes has the potential to enhance models ability to deal with the adverse effects of occlusion and the dynamic nature of the environments. Moreover, joint object detection and pose estimation models are better suited to leverage the co-dependent nature of the tasks for improving the accuracy of both tasks. To this end, we propose attention-based temporal fusion for multi-object 6D pose estimation that accumulates information across multiple frames of a video sequence. Our MOTPose method takes a sequence of images as input and performs joint object detection and pose estimation for all objects in one forward pass. It learns to aggregate both object embeddings and object parameters over multiple time steps using cross-attention-based fusion modules. We evaluate our method on the physically-realistic cluttered bin-picking dataset SynPick and the YCB-Video dataset and demonstrate improved pose estimation accuracy as well as better object detection accuracy
FogGuard: guarding YOLO against fog using perceptual loss
Mar 13, 2024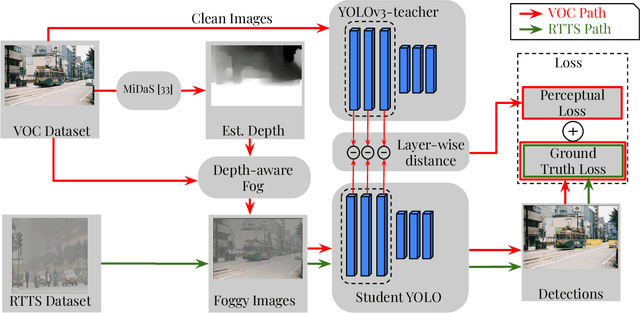
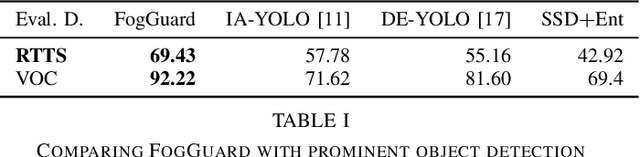

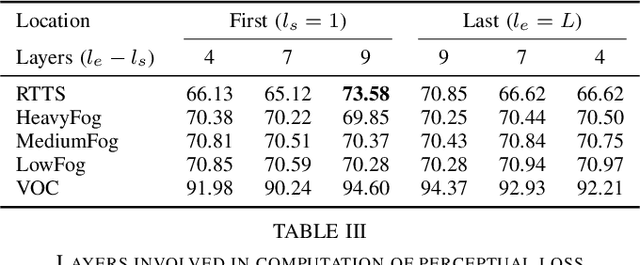
In this paper, we present a novel fog-aware object detection network called FogGuard, designed to address the challenges posed by foggy weather conditions. Autonomous driving systems heavily rely on accurate object detection algorithms, but adverse weather conditions can significantly impact the reliability of deep neural networks (DNNs). Existing approaches fall into two main categories, 1) image enhancement such as IA-YOLO 2) domain adaptation based approaches. Image enhancement based techniques attempt to generate fog-free image. However, retrieving a fogless image from a foggy image is a much harder problem than detecting objects in a foggy image. Domain-adaptation based approaches, on the other hand, do not make use of labelled datasets in the target domain. Both categories of approaches are attempting to solve a harder version of the problem. Our approach builds over fine-tuning on the Our framework is specifically designed to compensate for foggy conditions present in the scene, ensuring robust performance even. We adopt YOLOv3 as the baseline object detection algorithm and introduce a novel Teacher-Student Perceptual loss, to high accuracy object detection in foggy images. Through extensive evaluations on common datasets such as PASCAL VOC and RTTS, we demonstrate the improvement in performance achieved by our network. We demonstrate that FogGuard achieves 69.43\% mAP, as compared to 57.78\% for YOLOv3 on the RTTS dataset. Furthermore, we show that while our training method increases time complexity, it does not introduce any additional overhead during inference compared to the regular YOLO network.
PlainMamba: Improving Non-Hierarchical Mamba in Visual Recognition
Mar 26, 2024We present PlainMamba: a simple non-hierarchical state space model (SSM) designed for general visual recognition. The recent Mamba model has shown how SSMs can be highly competitive with other architectures on sequential data and initial attempts have been made to apply it to images. In this paper, we further adapt the selective scanning process of Mamba to the visual domain, enhancing its ability to learn features from two-dimensional images by (i) a continuous 2D scanning process that improves spatial continuity by ensuring adjacency of tokens in the scanning sequence, and (ii) direction-aware updating which enables the model to discern the spatial relations of tokens by encoding directional information. Our architecture is designed to be easy to use and easy to scale, formed by stacking identical PlainMamba blocks, resulting in a model with constant width throughout all layers. The architecture is further simplified by removing the need for special tokens. We evaluate PlainMamba on a variety of visual recognition tasks including image classification, semantic segmentation, object detection, and instance segmentation. Our method achieves performance gains over previous non-hierarchical models and is competitive with hierarchical alternatives. For tasks requiring high-resolution inputs, in particular, PlainMamba requires much less computing while maintaining high performance. Code and models are available at https://github.com/ChenhongyiYang/PlainMamba
LiRaFusion: Deep Adaptive LiDAR-Radar Fusion for 3D Object Detection
Feb 18, 2024We propose LiRaFusion to tackle LiDAR-radar fusion for 3D object detection to fill the performance gap of existing LiDAR-radar detectors. To improve the feature extraction capabilities from these two modalities, we design an early fusion module for joint voxel feature encoding, and a middle fusion module to adaptively fuse feature maps via a gated network. We perform extensive evaluation on nuScenes to demonstrate that LiRaFusion leverages the complementary information of LiDAR and radar effectively and achieves notable improvement over existing methods.
SDDGR: Stable Diffusion-based Deep Generative Replay for Class Incremental Object Detection
Feb 27, 2024In the field of class incremental learning (CIL), genera- tive replay has become increasingly prominent as a method to mitigate the catastrophic forgetting, alongside the con- tinuous improvements in generative models. However, its application in class incremental object detection (CIOD) has been significantly limited, primarily due to the com- plexities of scenes involving multiple labels. In this paper, we propose a novel approach called stable diffusion deep generative replay (SDDGR) for CIOD. Our method utilizes a diffusion-based generative model with pre-trained text- to-diffusion networks to generate realistic and diverse syn- thetic images. SDDGR incorporates an iterative refinement strategy to produce high-quality images encompassing old classes. Additionally, we adopt an L2 knowledge distilla- tion technique to improve the retention of prior knowledge in synthetic images. Furthermore, our approach includes pseudo-labeling for old objects within new task images, pre- venting misclassification as background elements. Exten- sive experiments on the COCO 2017 dataset demonstrate that SDDGR significantly outperforms existing algorithms, achieving a new state-of-the-art in various CIOD scenarios. The source code will be made available to the public.
Optimizing LiDAR Placements for Robust Driving Perception in Adverse Conditions
Mar 25, 2024The robustness of driving perception systems under unprecedented conditions is crucial for safety-critical usages. Latest advancements have prompted increasing interests towards multi-LiDAR perception. However, prevailing driving datasets predominantly utilize single-LiDAR systems and collect data devoid of adverse conditions, failing to capture the complexities of real-world environments accurately. Addressing these gaps, we proposed Place3D, a full-cycle pipeline that encompasses LiDAR placement optimization, data generation, and downstream evaluations. Our framework makes three appealing contributions. 1) To identify the most effective configurations for multi-LiDAR systems, we introduce a Surrogate Metric of the Semantic Occupancy Grids (M-SOG) to evaluate LiDAR placement quality. 2) Leveraging the M-SOG metric, we propose a novel optimization strategy to refine multi-LiDAR placements. 3) Centered around the theme of multi-condition multi-LiDAR perception, we collect a 364,000-frame dataset from both clean and adverse conditions. Extensive experiments demonstrate that LiDAR placements optimized using our approach outperform various baselines. We showcase exceptional robustness in both 3D object detection and LiDAR semantic segmentation tasks, under diverse adverse weather and sensor failure conditions. Code and benchmark toolkit are publicly available.
Ship in Sight: Diffusion Models for Ship-Image Super Resolution
Mar 27, 2024In recent years, remarkable advancements have been achieved in the field of image generation, primarily driven by the escalating demand for high-quality outcomes across various image generation subtasks, such as inpainting, denoising, and super resolution. A major effort is devoted to exploring the application of super-resolution techniques to enhance the quality of low-resolution images. In this context, our method explores in depth the problem of ship image super resolution, which is crucial for coastal and port surveillance. We investigate the opportunity given by the growing interest in text-to-image diffusion models, taking advantage of the prior knowledge that such foundation models have already learned. In particular, we present a diffusion-model-based architecture that leverages text conditioning during training while being class-aware, to best preserve the crucial details of the ships during the generation of the super-resoluted image. Since the specificity of this task and the scarcity availability of off-the-shelf data, we also introduce a large labeled ship dataset scraped from online ship images, mostly from ShipSpotting\footnote{\url{www.shipspotting.com}} website. Our method achieves more robust results than other deep learning models previously employed for super resolution, as proven by the multiple experiments performed. Moreover, we investigate how this model can benefit downstream tasks, such as classification and object detection, thus emphasizing practical implementation in a real-world scenario. Experimental results show flexibility, reliability, and impressive performance of the proposed framework over state-of-the-art methods for different tasks. The code is available at: https://github.com/LuigiSigillo/ShipinSight .
EffiPerception: an Efficient Framework for Various Perception Tasks
Mar 18, 2024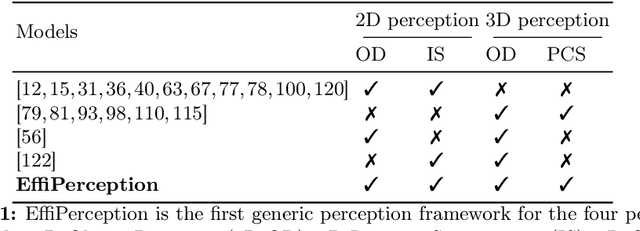
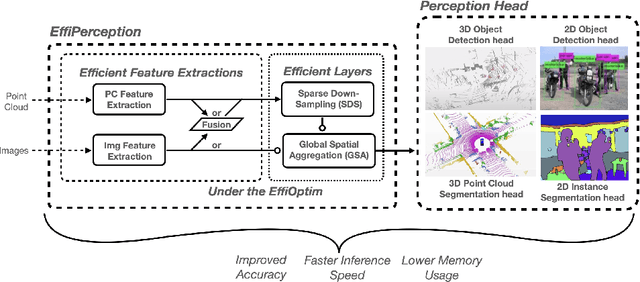
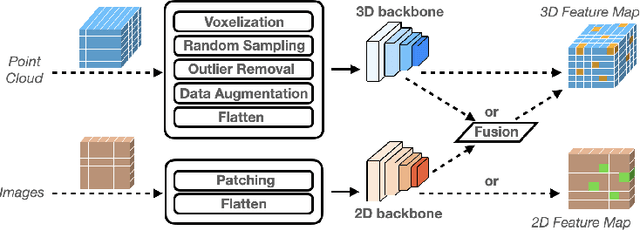
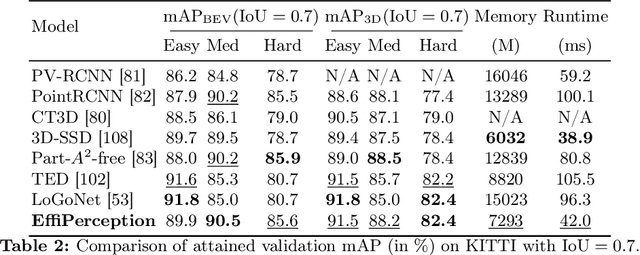
The accuracy-speed-memory trade-off is always the priority to consider for several computer vision perception tasks. Previous methods mainly focus on a single or small couple of these tasks, such as creating effective data augmentation, feature extractor, learning strategies, etc. These approaches, however, could be inherently task-specific: their proposed model's performance may depend on a specific perception task or a dataset. Targeting to explore common learning patterns and increasing the module robustness, we propose the EffiPerception framework. It could achieve great accuracy-speed performance with relatively low memory cost under several perception tasks: 2D Object Detection, 3D Object Detection, 2D Instance Segmentation, and 3D Point Cloud Segmentation. Overall, the framework consists of three parts: (1) Efficient Feature Extractors, which extract the input features for each modality. (2) Efficient Layers, plug-in plug-out layers that further process the feature representation, aggregating core learned information while pruning noisy proposals. (3) The EffiOptim, an 8-bit optimizer to further cut down the computational cost and facilitate performance stability. Extensive experiments on the KITTI, semantic-KITTI, and COCO datasets revealed that EffiPerception could show great accuracy-speed-memory overall performance increase within the four detection and segmentation tasks, in comparison to earlier, well-respected methods.