 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Improving Robustness of LiDAR-Camera Fusion Model against Weather Corruption from Fusion Strategy Perspective
Feb 05, 2024
In recent years, LiDAR-camera fusion models have markedly advanced 3D object detection tasks in autonomous driving. However, their robustness against common weather corruption such as fog, rain, snow, and sunlight in the intricate physical world remains underexplored. In this paper, we evaluate the robustness of fusion models from the perspective of fusion strategies on the corrupted dataset. Based on the evaluation, we further propose a concise yet practical fusion strategy to enhance the robustness of the fusion models, namely flexibly weighted fusing features from LiDAR and camera sources to adapt to varying weather scenarios. Experiments conducted on four types of fusion models, each with two distinct lightweight implementations, confirm the broad applicability and effectiveness of the approach.
Weakly Supervised Monocular 3D Detection with a Single-View Image
Feb 29, 2024Monocular 3D detection (M3D) aims for precise 3D object localization from a single-view image which usually involves labor-intensive annotation of 3D detection boxes. Weakly supervised M3D has recently been studied to obviate the 3D annotation process by leveraging many existing 2D annotations, but it often requires extra training data such as LiDAR point clouds or multi-view images which greatly degrades its applicability and usability in various applications. We propose SKD-WM3D, a weakly supervised monocular 3D detection framework that exploits depth information to achieve M3D with a single-view image exclusively without any 3D annotations or other training data. One key design in SKD-WM3D is a self-knowledge distillation framework, which transforms image features into 3D-like representations by fusing depth information and effectively mitigates the inherent depth ambiguity in monocular scenarios with little computational overhead in inference. In addition, we design an uncertainty-aware distillation loss and a gradient-targeted transfer modulation strategy which facilitate knowledge acquisition and knowledge transfer, respectively. Extensive experiments show that SKD-WM3D surpasses the state-of-the-art clearly and is even on par with many fully supervised methods.
Domain Adaptable Fine-Tune Distillation Framework For Advancing Farm Surveillance
Feb 10, 2024In this study, we propose an automated framework for camel farm monitoring, introducing two key contributions: the Unified Auto-Annotation framework and the Fine-Tune Distillation framework. The Unified Auto-Annotation approach combines two models, GroundingDINO (GD), and Segment-Anything-Model (SAM), to automatically annotate raw datasets extracted from surveillance videos. Building upon this foundation, the Fine-Tune Distillation framework conducts fine-tuning of student models using the auto-annotated dataset. This process involves transferring knowledge from a large teacher model to a student model, resembling a variant of Knowledge Distillation. The Fine-Tune Distillation framework aims to be adaptable to specific use cases, enabling the transfer of knowledge from the large models to the small models, making it suitable for domain-specific applications. By leveraging our raw dataset collected from Al-Marmoom Camel Farm in Dubai, UAE, and a pre-trained teacher model, GroundingDINO, the Fine-Tune Distillation framework produces a lightweight deployable model, YOLOv8. This framework demonstrates high performance and computational efficiency, facilitating efficient real-time object detection. Our code is available at \href{https://github.com/Razaimam45/Fine-Tune-Distillation}{https://github.com/Razaimam45/Fine-Tune-Distillation}
Using YOLO v7 to Detect Kidney in Magnetic Resonance Imaging
Feb 12, 2024Introduction This study explores the use of the latest You Only Look Once (YOLO V7) object detection method to enhance kidney detection in medical imaging by training and testing a modified YOLO V7 on medical image formats. Methods Study includes 878 patients with various subtypes of renal cell carcinoma (RCC) and 206 patients with normal kidneys. A total of 5657 MRI scans for 1084 patients were retrieved. 326 patients with 1034 tumors recruited from a retrospective maintained database, and bounding boxes were drawn around their tumors. A primary model was trained on 80% of annotated cases, with 20% saved for testing (primary test set). The best primary model was then used to identify tumors in the remaining 861 patients and bounding box coordinates were generated on their scans using the model. Ten benchmark training sets were created with generated coordinates on not-segmented patients. The final model used to predict the kidney in the primary test set. We reported the positive predictive value (PPV), sensitivity, and mean average precision (mAP). Results The primary training set showed an average PPV of 0.94 +/- 0.01, sensitivity of 0.87 +/- 0.04, and mAP of 0.91 +/- 0.02. The best primary model yielded a PPV of 0.97, sensitivity of 0.92, and mAP of 0.95. The final model demonstrated an average PPV of 0.95 +/- 0.03, sensitivity of 0.98 +/- 0.004, and mAP of 0.95 +/- 0.01. Conclusion Using a semi-supervised approach with a medical image library, we developed a high-performing model for kidney detection. Further external validation is required to assess the model's generalizability.
Simple Image-level Classification Improves Open-vocabulary Object Detection
Dec 19, 2023Open-Vocabulary Object Detection (OVOD) aims to detect novel objects beyond a given set of base categories on which the detection model is trained. Recent OVOD methods focus on adapting the image-level pre-trained vision-language models (VLMs), such as CLIP, to a region-level object detection task via, eg., region-level knowledge distillation, regional prompt learning, or region-text pre-training, to expand the detection vocabulary. These methods have demonstrated remarkable performance in recognizing regional visual concepts, but they are weak in exploiting the VLMs' powerful global scene understanding ability learned from the billion-scale image-level text descriptions. This limits their capability in detecting hard objects of small, blurred, or occluded appearance from novel/base categories, whose detection heavily relies on contextual information. To address this, we propose a novel approach, namely Simple Image-level Classification for Context-Aware Detection Scoring (SIC-CADS), to leverage the superior global knowledge yielded from CLIP for complementing the current OVOD models from a global perspective. The core of SIC-CADS is a multi-modal multi-label recognition (MLR) module that learns the object co-occurrence-based contextual information from CLIP to recognize all possible object categories in the scene. These image-level MLR scores can then be utilized to refine the instance-level detection scores of the current OVOD models in detecting those hard objects. This is verified by extensive empirical results on two popular benchmarks, OV-LVIS and OV-COCO, which show that SIC-CADS achieves significant and consistent improvement when combined with different types of OVOD models. Further, SIC-CADS also improves the cross-dataset generalization ability on Objects365 and OpenImages. The code is available at https://github.com/mala-lab/SIC-CADS.
Enhancing Novel Object Detection via Cooperative Foundational Models
Nov 22, 2023
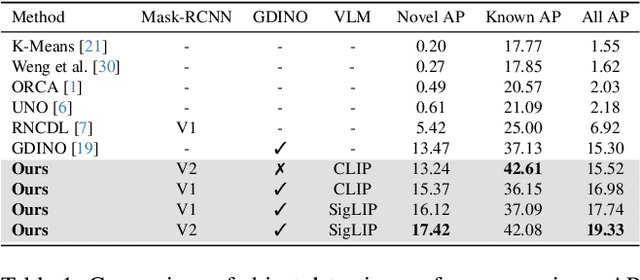
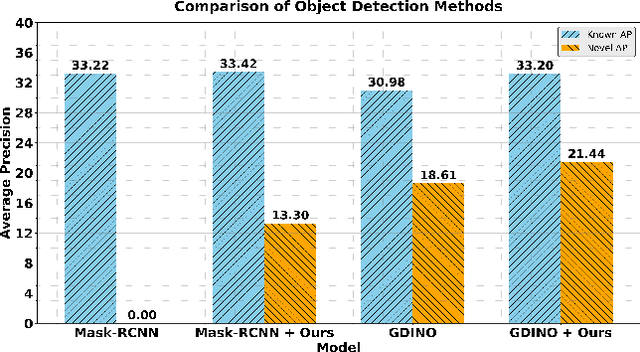
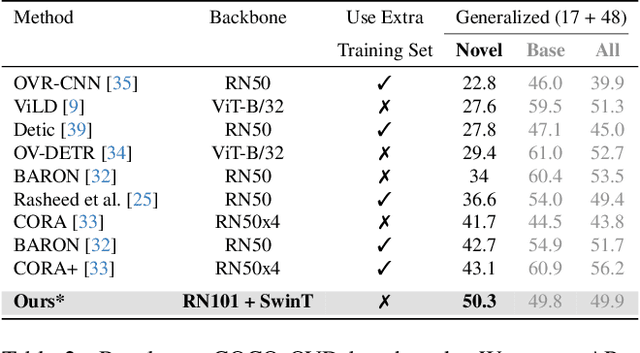
In this work, we address the challenging and emergent problem of novel object detection (NOD), focusing on the accurate detection of both known and novel object categories during inference. Traditional object detection algorithms are inherently closed-set, limiting their capability to handle NOD. We present a novel approach to transform existing closed-set detectors into open-set detectors. This transformation is achieved by leveraging the complementary strengths of pre-trained foundational models, specifically CLIP and SAM, through our cooperative mechanism. Furthermore, by integrating this mechanism with state-of-the-art open-set detectors such as GDINO, we establish new benchmarks in object detection performance. Our method achieves 17.42 mAP in novel object detection and 42.08 mAP for known objects on the challenging LVIS dataset. Adapting our approach to the COCO OVD split, we surpass the current state-of-the-art by a margin of 7.2 $ \text{AP}_{50} $ for novel classes. Our code is available at https://github.com/rohit901/cooperative-foundational-models .
ADOD: Adaptive Domain-Aware Object Detection with Residual Attention for Underwater Environments
Dec 11, 2023This research presents ADOD, a novel approach to address domain generalization in underwater object detection. Our method enhances the model's ability to generalize across diverse and unseen domains, ensuring robustness in various underwater environments. The first key contribution is Residual Attention YOLOv3, a novel variant of the YOLOv3 framework empowered by residual attention modules. These modules enable the model to focus on informative features while suppressing background noise, leading to improved detection accuracy and adaptability to different domains. The second contribution is the attention-based domain classification module, vital during training. This module helps the model identify domain-specific information, facilitating the learning of domain-invariant features. Consequently, ADOD can generalize effectively to underwater environments with distinct visual characteristics. Extensive experiments on diverse underwater datasets demonstrate ADOD's superior performance compared to state-of-the-art domain generalization methods, particularly in challenging scenarios. The proposed model achieves exceptional detection performance in both seen and unseen domains, showcasing its effectiveness in handling domain shifts in underwater object detection tasks. ADOD represents a significant advancement in adaptive object detection, providing a promising solution for real-world applications in underwater environments. With the prevalence of domain shifts in such settings, the model's strong generalization ability becomes a valuable asset for practical underwater surveillance and marine research endeavors.
Online Informative Sampling using Semantic Features in Underwater Environments
Feb 06, 2024The underwater world remains largely unexplored, with Autonomous Underwater Vehicles (AUVs) playing a crucial role in sub-sea explorations. However, continuous monitoring of underwater environments using AUVs can generate a significant amount of data. In addition, sending live data feed from an underwater environment requires dedicated on-board data storage options for AUVs which can hinder requirements of other higher priority tasks. Informative sampling techniques offer a solution by condensing observations. In this paper, we present a semantically-aware online informative sampling (ON-IS) approach which samples an AUV's visual experience in real-time. Specifically, we obtain visual features from a fine-tuned object detection model to align the sampling outcomes with the desired semantic information. Our contributions are (a) a novel Semantic Online Informative Sampling (SON-IS) algorithm, (b) a user study to validate the proposed approach and (c) a novel evaluation metric to score our proposed algorithm with respect to the suggested samples by human subjects
LiDAR-PTQ: Post-Training Quantization for Point Cloud 3D Object Detection
Jan 29, 2024Due to highly constrained computing power and memory, deploying 3D lidar-based detectors on edge devices equipped in autonomous vehicles and robots poses a crucial challenge. Being a convenient and straightforward model compression approach, Post-Training Quantization (PTQ) has been widely adopted in 2D vision tasks. However, applying it directly to 3D lidar-based tasks inevitably leads to performance degradation. As a remedy, we propose an effective PTQ method called LiDAR-PTQ, which is particularly curated for 3D lidar detection (both SPConv-based and SPConv-free). Our LiDAR-PTQ features three main components, \textbf{(1)} a sparsity-based calibration method to determine the initialization of quantization parameters, \textbf{(2)} a Task-guided Global Positive Loss (TGPL) to reduce the disparity between the final predictions before and after quantization, \textbf{(3)} an adaptive rounding-to-nearest operation to minimize the layerwise reconstruction error. Extensive experiments demonstrate that our LiDAR-PTQ can achieve state-of-the-art quantization performance when applied to CenterPoint (both Pillar-based and Voxel-based). To our knowledge, for the very first time in lidar-based 3D detection tasks, the PTQ INT8 model's accuracy is almost the same as the FP32 model while enjoying $3\times$ inference speedup. Moreover, our LiDAR-PTQ is cost-effective being $30\times$ faster than the quantization-aware training method. Code will be released at \url{https://github.com/StiphyJay/LiDAR-PTQ}.
SimMining-3D: Altitude-Aware 3D Object Detection in Complex Mining Environments: A Novel Dataset and ROS-Based Automatic Annotation Pipeline
Dec 11, 2023Accurate and efficient object detection is crucial for safe and efficient operation of earth-moving equipment in mining. Traditional 2D image-based methods face limitations in dynamic and complex mine environments. To overcome these challenges, 3D object detection using point cloud data has emerged as a comprehensive approach. However, training models for mining scenarios is challenging due to sensor height variations, viewpoint changes, and the need for diverse annotated datasets. This paper presents novel contributions to address these challenges. We introduce a synthetic dataset SimMining 3D [1] specifically designed for 3D object detection in mining environments. The dataset captures objects and sensors positioned at various heights within mine benches, accurately reflecting authentic mining scenarios. An automatic annotation pipeline through ROS interface reduces manual labor and accelerates dataset creation. We propose evaluation metrics accounting for sensor-to-object height variations and point cloud density, enabling accurate model assessment in mining scenarios. Real data tests validate our models effectiveness in object prediction. Our ablation study emphasizes the importance of altitude and height variation augmentations in improving accuracy and reliability. The publicly accessible synthetic dataset [1] serves as a benchmark for supervised learning and advances object detection techniques in mining with complimentary pointwise annotations for each scene. In conclusion, our work bridges the gap between synthetic and real data, addressing the domain shift challenge in 3D object detection for mining. We envision robust object detection systems enhancing safety and efficiency in mining and related domains.