 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
MixSup: Mixed-grained Supervision for Label-efficient LiDAR-based 3D Object Detection
Jan 29, 2024
Label-efficient LiDAR-based 3D object detection is currently dominated by weakly/semi-supervised methods. Instead of exclusively following one of them, we propose MixSup, a more practical paradigm simultaneously utilizing massive cheap coarse labels and a limited number of accurate labels for Mixed-grained Supervision. We start by observing that point clouds are usually textureless, making it hard to learn semantics. However, point clouds are geometrically rich and scale-invariant to the distances from sensors, making it relatively easy to learn the geometry of objects, such as poses and shapes. Thus, MixSup leverages massive coarse cluster-level labels to learn semantics and a few expensive box-level labels to learn accurate poses and shapes. We redesign the label assignment in mainstream detectors, which allows them seamlessly integrated into MixSup, enabling practicality and universality. We validate its effectiveness in nuScenes, Waymo Open Dataset, and KITTI, employing various detectors. MixSup achieves up to 97.31% of fully supervised performance, using cheap cluster annotations and only 10% box annotations. Furthermore, we propose PointSAM based on the Segment Anything Model for automated coarse labeling, further reducing the annotation burden. The code is available at https://github.com/BraveGroup/PointSAM-for-MixSup.
COMMIT: Certifying Robustness of Multi-Sensor Fusion Systems against Semantic Attacks
Mar 04, 2024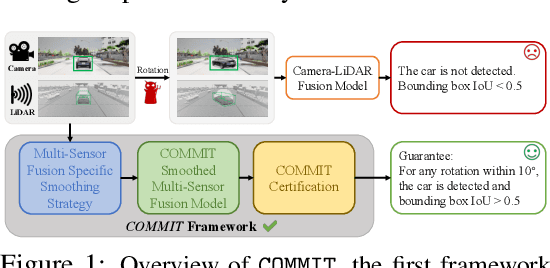
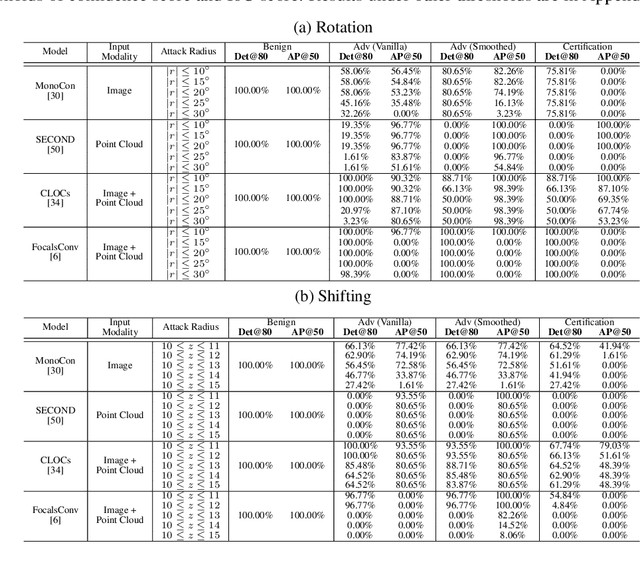

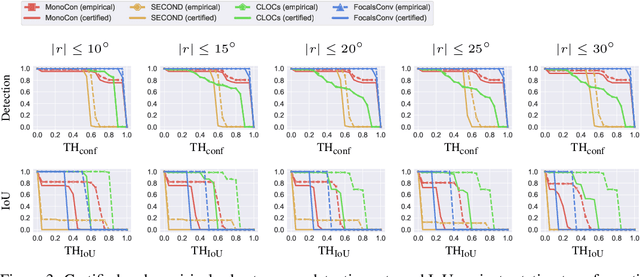
Multi-sensor fusion systems (MSFs) play a vital role as the perception module in modern autonomous vehicles (AVs). Therefore, ensuring their robustness against common and realistic adversarial semantic transformations, such as rotation and shifting in the physical world, is crucial for the safety of AVs. While empirical evidence suggests that MSFs exhibit improved robustness compared to single-modal models, they are still vulnerable to adversarial semantic transformations. Despite the proposal of empirical defenses, several works show that these defenses can be attacked again by new adaptive attacks. So far, there is no certified defense proposed for MSFs. In this work, we propose the first robustness certification framework COMMIT certify robustness of multi-sensor fusion systems against semantic attacks. In particular, we propose a practical anisotropic noise mechanism that leverages randomized smoothing with multi-modal data and performs a grid-based splitting method to characterize complex semantic transformations. We also propose efficient algorithms to compute the certification in terms of object detection accuracy and IoU for large-scale MSF models. Empirically, we evaluate the efficacy of COMMIT in different settings and provide a comprehensive benchmark of certified robustness for different MSF models using the CARLA simulation platform. We show that the certification for MSF models is at most 48.39% higher than that of single-modal models, which validates the advantages of MSF models. We believe our certification framework and benchmark will contribute an important step towards certifiably robust AVs in practice.
Towards Scenario Generalization for Vision-based Roadside 3D Object Detection
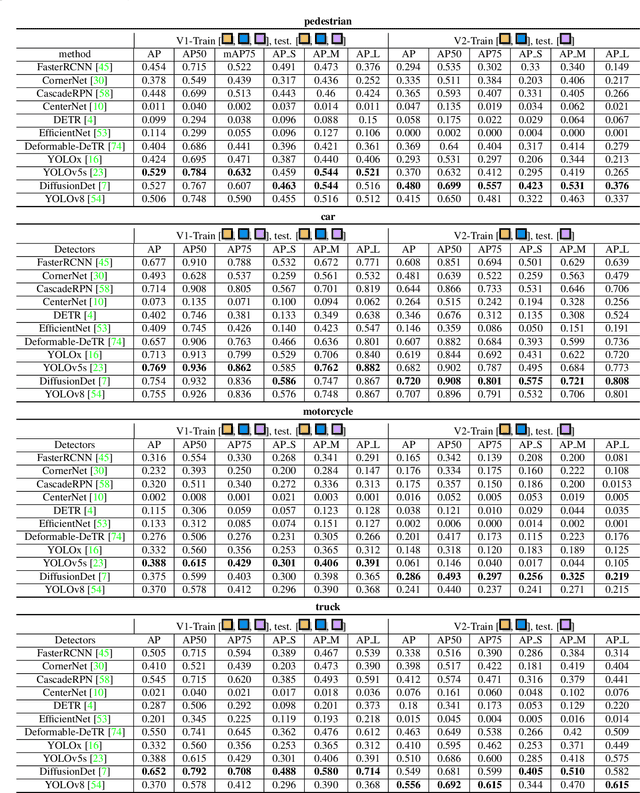
Jan 29, 2024Roadside perception can greatly increase the safety of autonomous vehicles by extending their perception ability beyond the visual range and addressing blind spots. However, current state-of-the-art vision-based roadside detection methods possess high accuracy on labeled scenes but have inferior performance on new scenes. This is because roadside cameras remain stationary after installation and can only collect data from a single scene, resulting in the algorithm overfitting these roadside backgrounds and camera poses. To address this issue, in this paper, we propose an innovative Scenario Generalization Framework for Vision-based Roadside 3D Object Detection, dubbed SGV3D. Specifically, we employ a Background-suppressed Module (BSM) to mitigate background overfitting in vision-centric pipelines by attenuating background features during the 2D to bird's-eye-view projection. Furthermore, by introducing the Semi-supervised Data Generation Pipeline (SSDG) using unlabeled images from new scenes, diverse instance foregrounds with varying camera poses are generated, addressing the risk of overfitting specific camera poses. We evaluate our method on two large-scale roadside benchmarks. Our method surpasses all previous methods by a significant margin in new scenes, including +42.57% for vehicle, +5.87% for pedestrian, and +14.89% for cyclist compared to BEVHeight on the DAIR-V2X-I heterologous benchmark. On the larger-scale Rope3D heterologous benchmark, we achieve notable gains of 14.48% for car and 12.41% for large vehicle. We aspire to contribute insights on the exploration of roadside perception techniques, emphasizing their capability for scenario generalization. The code will be available at {\url{ https://github.com/yanglei18/SGV3D}}
MMW-Carry: Enhancing Carry Object Detection through Millimeter-Wave Radar-Camera Fusion
Feb 24, 2024This paper introduces MMW-Carry, a system designed to predict the probability of individuals carrying various objects using millimeter-wave radar signals, complemented by camera input. The primary goal of MMW-Carry is to provide a rapid and cost-effective preliminary screening solution, specifically tailored for non-super-sensitive scenarios. Overall, MMW-Carry achieves significant advancements in two crucial aspects. Firstly, it addresses localization challenges in complex indoor environments caused by multi-path reflections, enhancing the system's overall robustness. This is accomplished by the integration of camera-based human detection, tracking, and the radar-camera plane transformation for obtaining subjects' spatial occupancy region, followed by a zooming-in operation on the radar images. Secondly, the system performance is elevated by leveraging long-term observation of a subject. This is realized through the intelligent fusion of neural network results from multiple different-view radar images of an in-track moving subject and their carried objects, facilitated by a proposed knowledge-transfer module. Our experiment results demonstrate that MMW-Carry detects objects with an average error rate of 25.22\% false positives and a 21.71\% missing rate for individuals moving randomly in a large indoor space, carrying the common-in-everyday-life objects, both in open carry or concealed ways. These findings affirm MMW-Carry's potential to extend its capabilities to detect a broader range of objects for diverse applications.
Probing Multimodal Large Language Models for Global and Local Semantic Representation
Feb 27, 2024The success of large language models has inspired researchers to transfer their exceptional representing ability to other modalities. Several recent works leverage image-caption alignment datasets to train multimodal large language models (MLLMs), which achieve state-of-the-art performance on image-to-text tasks. However, there are very few studies exploring whether MLLMs truly understand the complete image information, i.e., global information, or if they can only capture some local object information. In this study, we find that the intermediate layers of models can encode more global semantic information, whose representation vectors perform better on visual-language entailment tasks, rather than the topmost layers. We further probe models for local semantic representation through object detection tasks. And we draw a conclusion that the topmost layers may excessively focus on local information, leading to a diminished ability to encode global information.
Fast Quantum Convolutional Neural Networks for Low-Complexity Object Detection in Autonomous Driving Applications
Dec 28, 2023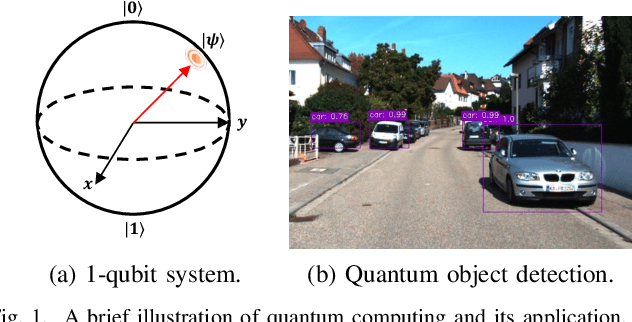
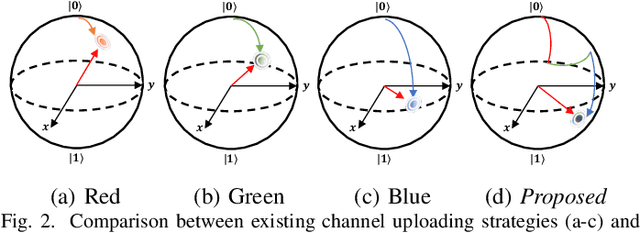
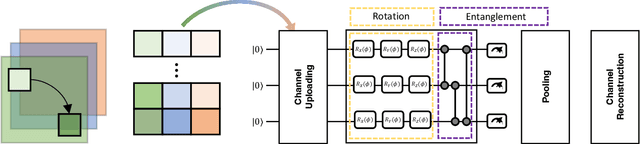
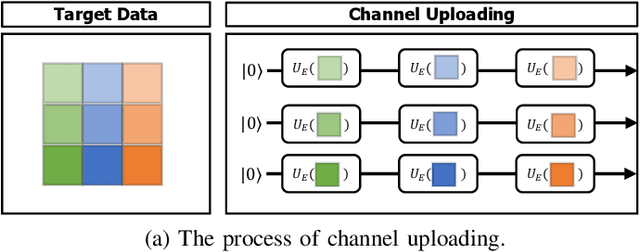
Spurred by consistent advances and innovation in deep learning, object detection applications have become prevalent, particularly in autonomous driving that leverages various visual data. As convolutional neural networks (CNNs) are being optimized, the performances and computation speeds of object detection in autonomous driving have been significantly improved. However, due to the exponentially rapid growth in the complexity and scale of data used in object detection, there are limitations in terms of computation speeds while conducting object detection solely with classical computing. Motivated by this, quantum convolution-based object detection (QCOD) is proposed to adopt quantum computing to perform object detection at high speed. The QCOD utilizes our proposed fast quantum convolution that uploads input channel information and re-constructs output channels for achieving reduced computational complexity and thus improving performances. Lastly, the extensive experiments with KITTI autonomous driving object detection dataset verify that the proposed fast quantum convolution and QCOD are successfully operated in real object detection applications.
Abductive Ego-View Accident Video Understanding for Safe Driving Perception
Mar 01, 2024
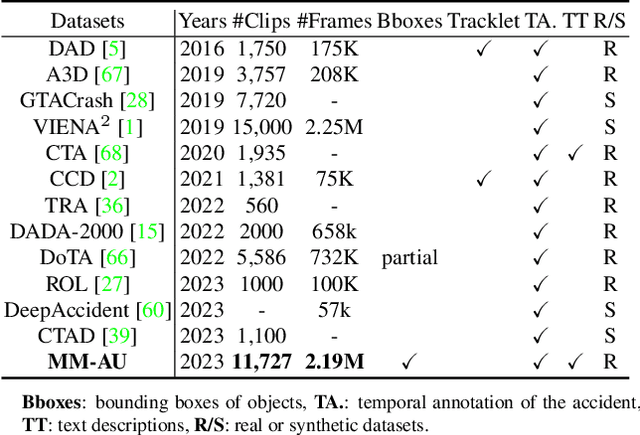
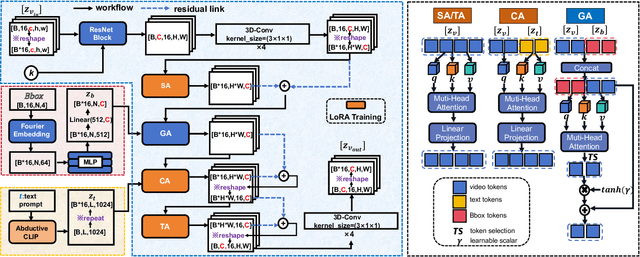
We present MM-AU, a novel dataset for Multi-Modal Accident video Understanding. MM-AU contains 11,727 in-the-wild ego-view accident videos, each with temporally aligned text descriptions. We annotate over 2.23 million object boxes and 58,650 pairs of video-based accident reasons, covering 58 accident categories. MM-AU supports various accident understanding tasks, particularly multimodal video diffusion to understand accident cause-effect chains for safe driving. With MM-AU, we present an Abductive accident Video understanding framework for Safe Driving perception (AdVersa-SD). AdVersa-SD performs video diffusion via an Object-Centric Video Diffusion (OAVD) method which is driven by an abductive CLIP model. This model involves a contrastive interaction loss to learn the pair co-occurrence of normal, near-accident, accident frames with the corresponding text descriptions, such as accident reasons, prevention advice, and accident categories. OAVD enforces the causal region learning while fixing the content of the original frame background in video generation, to find the dominant cause-effect chain for certain accidents. Extensive experiments verify the abductive ability of AdVersa-SD and the superiority of OAVD against the state-of-the-art diffusion models. Additionally, we provide careful benchmark evaluations for object detection and accident reason answering since AdVersa-SD relies on precise object and accident reason information.
Robust Tiny Object Detection in Aerial Images amidst Label Noise
Jan 16, 2024Precise detection of tiny objects in remote sensing imagery remains a significant challenge due to their limited visual information and frequent occurrence within scenes. This challenge is further exacerbated by the practical burden and inherent errors associated with manual annotation: annotating tiny objects is laborious and prone to errors (i.e., label noise). Training detectors for such objects using noisy labels often leads to suboptimal performance, with networks tending to overfit on noisy labels. In this study, we address the intricate issue of tiny object detection under noisy label supervision. We systematically investigate the impact of various types of noise on network training, revealing the vulnerability of object detectors to class shifts and inaccurate bounding boxes for tiny objects. To mitigate these challenges, we propose a DeNoising Tiny Object Detector (DN-TOD), which incorporates a Class-aware Label Correction (CLC) scheme to address class shifts and a Trend-guided Learning Strategy (TLS) to handle bounding box noise. CLC mitigates inaccurate class supervision by identifying and filtering out class-shifted positive samples, while TLS reduces noisy box-induced erroneous supervision through sample reweighting and bounding box regeneration. Additionally, Our method can be seamlessly integrated into both one-stage and two-stage object detection pipelines. Comprehensive experiments conducted on synthetic (i.e., noisy AI-TOD-v2.0 and DOTA-v2.0) and real-world (i.e., AI-TOD) noisy datasets demonstrate the robustness of DN-TOD under various types of label noise. Notably, when applied to the strong baseline RFLA, DN-TOD exhibits a noteworthy performance improvement of 4.9 points under 40% mixed noise. Datasets, codes, and models will be made publicly available.
Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
Mar 15, 2024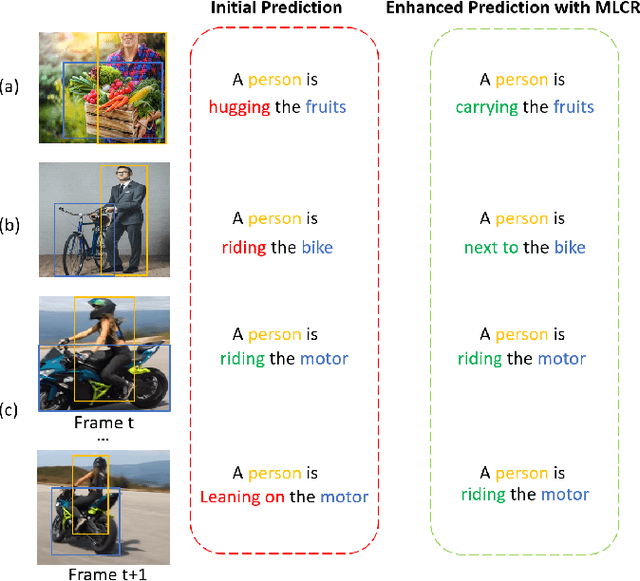
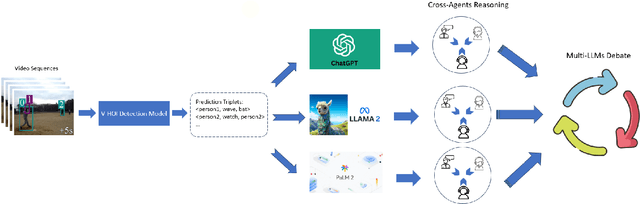
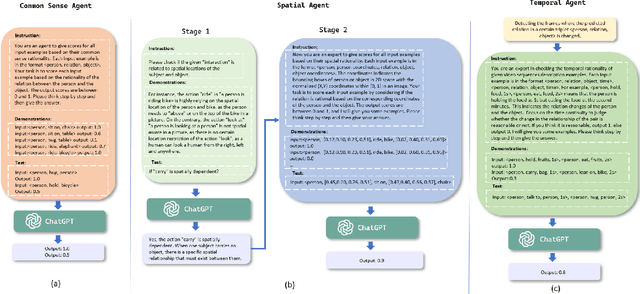
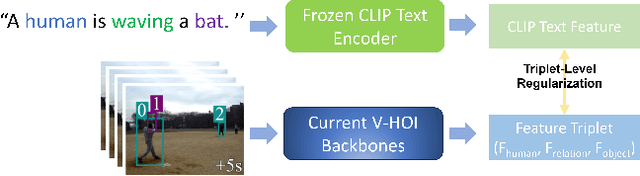
Human-centered dynamic scene understanding plays a pivotal role in enhancing the capability of robotic and autonomous systems, in which Video-based Human-Object Interaction (V-HOI) detection is a crucial task in semantic scene understanding, aimed at comprehensively understanding HOI relationships within a video to benefit the behavioral decisions of mobile robots and autonomous driving systems. Although previous V-HOI detection models have made significant strides in accurate detection on specific datasets, they still lack the general reasoning ability like human beings to effectively induce HOI relationships. In this study, we propose V-HOI Multi-LLMs Collaborated Reasoning (V-HOI MLCR), a novel framework consisting of a series of plug-and-play modules that could facilitate the performance of current V-HOI detection models by leveraging the strong reasoning ability of different off-the-shelf pre-trained large language models (LLMs). We design a two-stage collaboration system of different LLMs for the V-HOI task. Specifically, in the first stage, we design a Cross-Agents Reasoning scheme to leverage the LLM conduct reasoning from different aspects. In the second stage, we perform Multi-LLMs Debate to get the final reasoning answer based on the different knowledge in different LLMs. Additionally, we devise an auxiliary training strategy that utilizes CLIP, a large vision-language model to enhance the base V-HOI models' discriminative ability to better cooperate with LLMs. We validate the superiority of our design by demonstrating its effectiveness in improving the prediction accuracy of the base V-HOI model via reasoning from multiple perspectives.
ELA: Efficient Local Attention for Deep Convolutional Neural Networks
Mar 02, 2024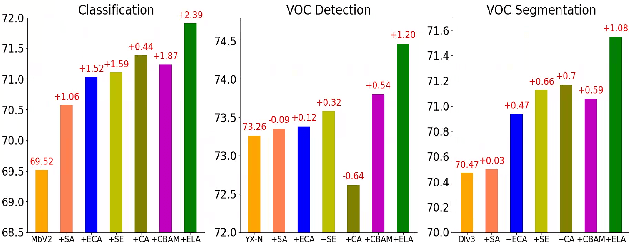

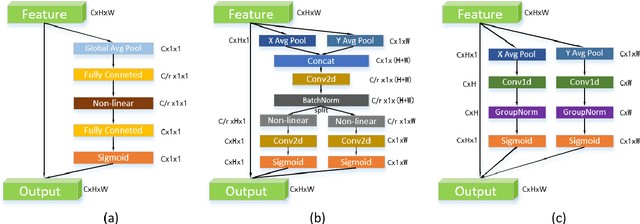
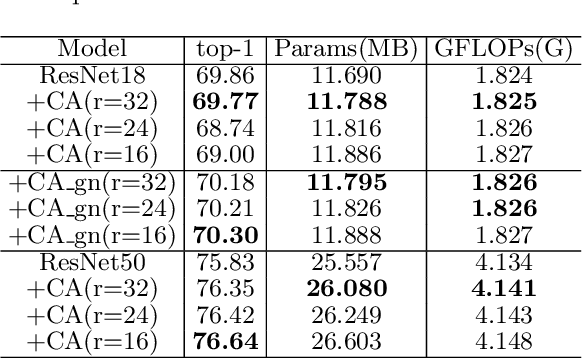
The attention mechanism has gained significant recognition in the field of computer vision due to its ability to effectively enhance the performance of deep neural networks. However, existing methods often struggle to effectively utilize spatial information or, if they do, they come at the cost of reducing channel dimensions or increasing the complexity of neural networks. In order to address these limitations, this paper introduces an Efficient Local Attention (ELA) method that achieves substantial performance improvements with a simple structure. By analyzing the limitations of the Coordinate Attention method, we identify the lack of generalization ability in Batch Normalization, the adverse effects of dimension reduction on channel attention, and the complexity of attention generation process. To overcome these challenges, we propose the incorporation of 1D convolution and Group Normalization feature enhancement techniques. This approach enables accurate localization of regions of interest by efficiently encoding two 1D positional feature maps without the need for dimension reduction, while allowing for a lightweight implementation. We carefully design three hyperparameters in ELA, resulting in four different versions: ELA-T, ELA-B, ELA-S, and ELA-L, to cater to the specific requirements of different visual tasks such as image classification, object detection and sementic segmentation. ELA can be seamlessly integrated into deep CNN networks such as ResNet, MobileNet, and DeepLab. Extensive evaluations on the ImageNet, MSCOCO, and Pascal VOC datasets demonstrate the superiority of the proposed ELA module over current state-of-the-art methods in all three aforementioned visual tasks.