 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
LangXAI: Integrating Large Vision Models for Generating Textual Explanations to Enhance Explainability in Visual Perception Tasks
Feb 19, 2024
LangXAI is a framework that integrates Explainable Artificial Intelligence (XAI) with advanced vision models to generate textual explanations for visual recognition tasks. Despite XAI advancements, an understanding gap persists for end-users with limited domain knowledge in artificial intelligence and computer vision. LangXAI addresses this by furnishing text-based explanations for classification, object detection, and semantic segmentation model outputs to end-users. Preliminary results demonstrate LangXAI's enhanced plausibility, with high BERTScore across tasks, fostering a more transparent and reliable AI framework on vision tasks for end-users.
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Feb 29, 2024Today's deep learning methods focus on how to design the most appropriate objective functions so that the prediction results of the model can be closest to the ground truth. Meanwhile, an appropriate architecture that can facilitate acquisition of enough information for prediction has to be designed. Existing methods ignore a fact that when input data undergoes layer-by-layer feature extraction and spatial transformation, large amount of information will be lost. This paper will delve into the important issues of data loss when data is transmitted through deep networks, namely information bottleneck and reversible functions. We proposed the concept of programmable gradient information (PGI) to cope with the various changes required by deep networks to achieve multiple objectives. PGI can provide complete input information for the target task to calculate objective function, so that reliable gradient information can be obtained to update network weights. In addition, a new lightweight network architecture -- Generalized Efficient Layer Aggregation Network (GELAN), based on gradient path planning is designed. GELAN's architecture confirms that PGI has gained superior results on lightweight models. We verified the proposed GELAN and PGI on MS COCO dataset based object detection. The results show that GELAN only uses conventional convolution operators to achieve better parameter utilization than the state-of-the-art methods developed based on depth-wise convolution. PGI can be used for variety of models from lightweight to large. It can be used to obtain complete information, so that train-from-scratch models can achieve better results than state-of-the-art models pre-trained using large datasets, the comparison results are shown in Figure 1. The source codes are at: https://github.com/WongKinYiu/yolov9.
A Multispectral Automated Transfer Technique (MATT) for machine-driven image labeling utilizing the Segment Anything Model (SAM)
Feb 18, 2024Segment Anything Model (SAM) is drastically accelerating the speed and accuracy of automatically segmenting and labeling large Red-Green-Blue (RGB) imagery datasets. However, SAM is unable to segment and label images outside of the visible light spectrum, for example, for multispectral or hyperspectral imagery. Therefore, this paper outlines a method we call the Multispectral Automated Transfer Technique (MATT). By transposing SAM segmentation masks from RGB images we can automatically segment and label multispectral imagery with high precision and efficiency. For example, the results demonstrate that segmenting and labeling a 2,400-image dataset utilizing MATT achieves a time reduction of 87.8% in developing a trained model, reducing roughly 20 hours of manual labeling, to only 2.4 hours. This efficiency gain is associated with only a 6.7% decrease in overall mean average precision (mAP) when training multispectral models via MATT, compared to a manually labeled dataset. We consider this an acceptable level of precision loss when considering the time saved during training, especially for rapidly prototyping experimental modeling methods. This research greatly contributes to the study of multispectral object detection by providing a novel and open-source method to rapidly segment, label, and train multispectral object detection models with minimal human interaction. Future research needs to focus on applying these methods to (i) space-based multispectral, and (ii) drone-based hyperspectral imagery.
Genie: Smart ROS-based Caching for Connected Autonomous Robots
Feb 29, 2024Despite the promising future of autonomous robots, several key issues currently remain that can lead to compromised performance and safety. One such issue is latency, where we find that even the latest embedded platforms from NVIDIA fail to execute intelligence tasks (e.g., object detection) of autonomous vehicles in a real-time fashion. One remedy to this problem is the promising paradigm of edge computing. Through collaboration with our industry partner, we identify key prohibitive limitations of the current edge mindset: (1) servers are not distributed enough and thus, are not close enough to vehicles, (2) current proposed edge solutions do not provide substantially better performance and extra information specific to autonomous vehicles to warrant their cost to the user, and (3) the state-of-the-art solutions are not compatible with popular frameworks used in autonomous systems, particularly the Robot Operating System (ROS). To remedy these issues, we provide Genie, an encapsulation technique that can enable transparent caching in ROS in a non-intrusive way (i.e., without modifying the source code), can build the cache in a distributed manner (in contrast to traditional central caching methods), and can construct a collective three-dimensional object map to provide substantially better latency (even on low-power edge servers) and higher quality data to all vehicles in a certain locality. We fully implement our design on state-of-the-art industry-adopted embedded and edge platforms, using the prominent autonomous driving software Autoware, and find that Genie can enhance the latency of Autoware Vision Detector by 82% on average, enable object reusability 31% of the time on average and as much as 67% for the incoming requests, and boost the confidence in its object map considerably over time.
Credible Teacher for Semi-Supervised Object Detection in Open Scene
Jan 03, 2024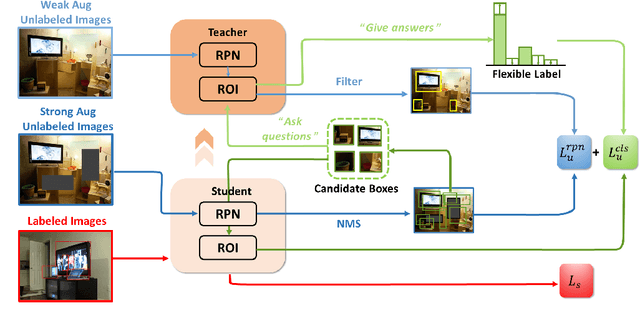
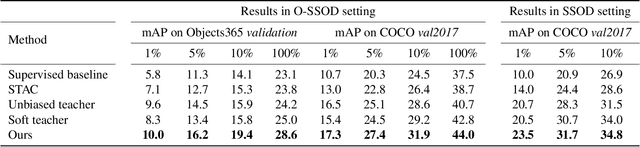
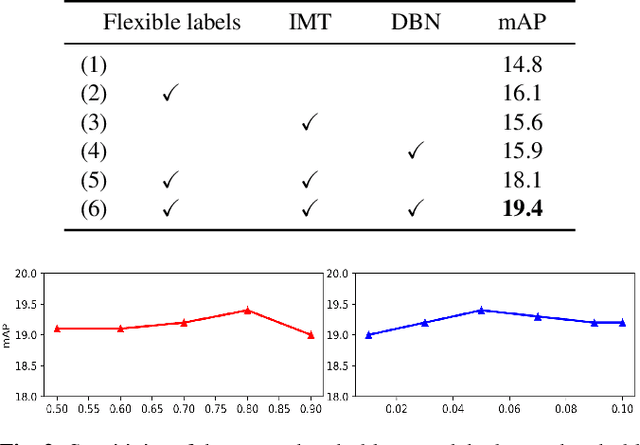
Semi-Supervised Object Detection (SSOD) has achieved resounding success by leveraging unlabeled data to improve detection performance. However, in Open Scene Semi-Supervised Object Detection (O-SSOD), unlabeled data may contains unknown objects not observed in the labeled data, which will increase uncertainty in the model's predictions for known objects. It is detrimental to the current methods that mainly rely on self-training, as more uncertainty leads to the lower localization and classification precision of pseudo labels. To this end, we propose Credible Teacher, an end-to-end framework. Credible Teacher adopts an interactive teaching mechanism using flexible labels to prevent uncertain pseudo labels from misleading the model and gradually reduces its uncertainty through the guidance of other credible pseudo labels. Empirical results have demonstrated our method effectively restrains the adverse effect caused by O-SSOD and significantly outperforms existing counterparts.
Combining unsupervised and supervised learning in microscopy enables defect analysis of a full 4H-SiC wafer
Feb 20, 2024Detecting and analyzing various defect types in semiconductor materials is an important prerequisite for understanding the underlying mechanisms as well as tailoring the production processes. Analysis of microscopy images that reveal defects typically requires image analysis tasks such as segmentation and object detection. With the permanently increasing amount of data that is produced by experiments, handling these tasks manually becomes more and more impossible. In this work, we combine various image analysis and data mining techniques for creating a robust and accurate, automated image analysis pipeline. This allows for extracting the type and position of all defects in a microscopy image of a KOH-etched 4H-SiC wafer that was stitched together from approximately 40,000 individual images.
Dual-Perspective Knowledge Enrichment for Semi-Supervised 3D Object Detection
Jan 10, 2024Semi-supervised 3D object detection is a promising yet under-explored direction to reduce data annotation costs, especially for cluttered indoor scenes. A few prior works, such as SESS and 3DIoUMatch, attempt to solve this task by utilizing a teacher model to generate pseudo-labels for unlabeled samples. However, the availability of unlabeled samples in the 3D domain is relatively limited compared to its 2D counterpart due to the greater effort required to collect 3D data. Moreover, the loose consistency regularization in SESS and restricted pseudo-label selection strategy in 3DIoUMatch lead to either low-quality supervision or a limited amount of pseudo labels. To address these issues, we present a novel Dual-Perspective Knowledge Enrichment approach named DPKE for semi-supervised 3D object detection. Our DPKE enriches the knowledge of limited training data, particularly unlabeled data, from two perspectives: data-perspective and feature-perspective. Specifically, from the data-perspective, we propose a class-probabilistic data augmentation method that augments the input data with additional instances based on the varying distribution of class probabilities. Our DPKE achieves feature-perspective knowledge enrichment by designing a geometry-aware feature matching method that regularizes feature-level similarity between object proposals from the student and teacher models. Extensive experiments on the two benchmark datasets demonstrate that our DPKE achieves superior performance over existing state-of-the-art approaches under various label ratio conditions. The source code will be made available to the public.
Context Enhanced Transformer for Single Image Object Detection
Dec 26, 2023With the increasing importance of video data in real-world applications, there is a rising need for efficient object detection methods that utilize temporal information. While existing video object detection (VOD) techniques employ various strategies to address this challenge, they typically depend on locally adjacent frames or randomly sampled images within a clip. Although recent Transformer-based VOD methods have shown promising results, their reliance on multiple inputs and additional network complexity to incorporate temporal information limits their practical applicability. In this paper, we propose a novel approach to single image object detection, called Context Enhanced TRansformer (CETR), by incorporating temporal context into DETR using a newly designed memory module. To efficiently store temporal information, we construct a class-wise memory that collects contextual information across data. Additionally, we present a classification-based sampling technique to selectively utilize the relevant memory for the current image. In the testing, We introduce a test-time memory adaptation method that updates individual memory functions by considering the test distribution. Experiments with CityCam and ImageNet VID datasets exhibit the efficiency of the framework on various video systems. The project page and code will be made available at: https://ku-cvlab.github.io/CETR.
Selective nonlinearities removal from digital signals
Mar 13, 2024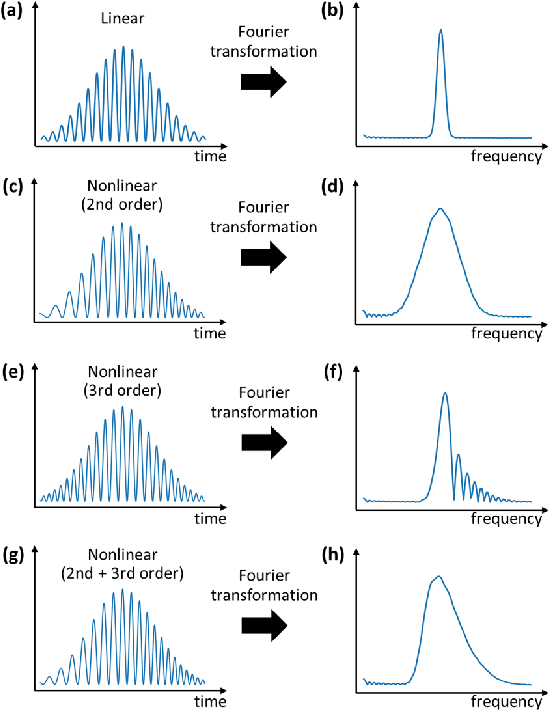
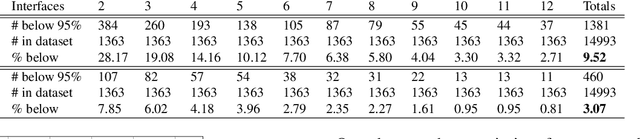
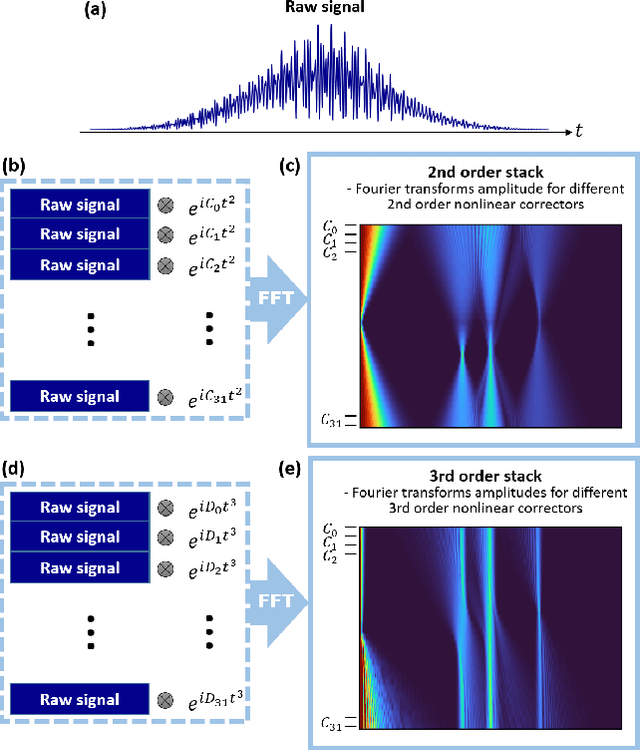
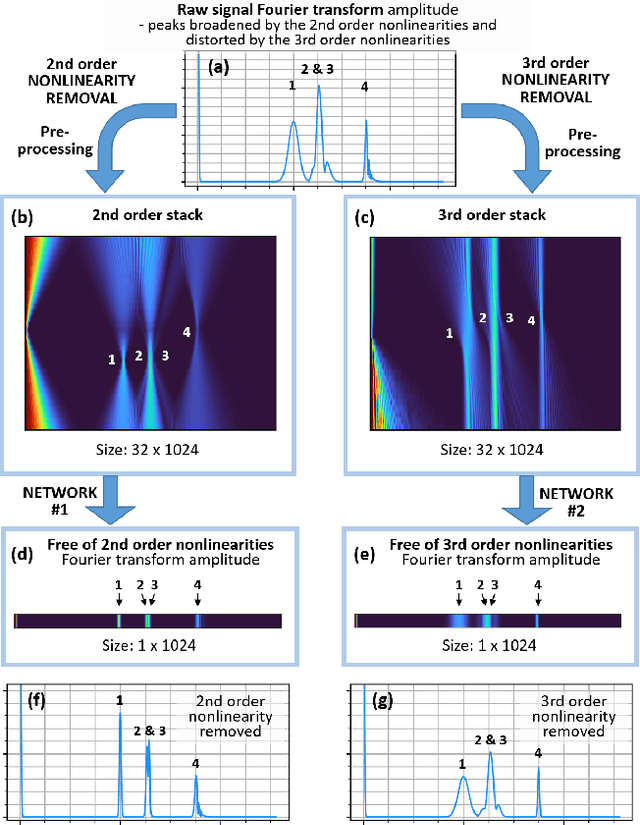
Many instruments performing optical and non-optical imaging and sensing, such as Optical Coherence Tomography (OCT), Magnetic Resonance Imaging or Fourier-transform spectrometry, produce digital signals containing modulations, sine-like components, which only after Fourier transformation give information about the structure or characteristics of the investigated object. Due to the fundamental physics-related limitations of such methods, the distribution of these signal components is often nonlinear and, when not properly compensated, leads to the resolution, precision or quality drop in the final image. Here, we propose an innovative approach that has the potential to allow cleaning of the signal from the nonlinearities but most of all, it now allows to switch the given order off, leaving all others intact. The latter provides a tool for more in-depth analysis of the nonlinearity-inducing properties of the investigated object, which can lead to applications in early disease detection or more sensitive sensing of chemical compounds. We consider OCT signals and nonlinearities up to the third order. In our approach, we propose two neural networks: one to remove solely the second-order nonlinearity and the other for removing solely the third-order nonlinearity. The input of the networks is a novel two-dimensional data structure with all the information needed for the network to infer a nonlinearity-free signal. We describe the developed networks and present the results for second-order and third-order nonlinearity removal in OCT data representing the images of various objects: a mirror, glass, and fruits.
SDGE: Stereo Guided Depth Estimation for 360$^\circ$ Camera Sets
Feb 26, 2024Depth estimation is a critical technology in autonomous driving, and multi-camera systems are often used to achieve a 360$^\circ$ perception. These 360$^\circ$ camera sets often have limited or low-quality overlap regions, making multi-view stereo methods infeasible for the entire image. Alternatively, monocular methods may not produce consistent cross-view predictions. To address these issues, we propose the Stereo Guided Depth Estimation (SGDE) method, which enhances depth estimation of the full image by explicitly utilizing multi-view stereo results on the overlap. We suggest building virtual pinhole cameras to resolve the distortion problem of fisheye cameras and unify the processing for the two types of 360$^\circ$ cameras. For handling the varying noise on camera poses caused by unstable movement, the approach employs a self-calibration method to obtain highly accurate relative poses of the adjacent cameras with minor overlap. These enable the use of robust stereo methods to obtain high-quality depth prior in the overlap region. This prior serves not only as an additional input but also as pseudo-labels that enhance the accuracy of depth estimation methods and improve cross-view prediction consistency. The effectiveness of SGDE is evaluated on one fisheye camera dataset, Synthetic Urban, and two pinhole camera datasets, DDAD and nuScenes. Our experiments demonstrate that SGDE is effective for both supervised and self-supervised depth estimation, and highlight the potential of our method for advancing downstream autonomous driving technologies, such as 3D object detection and occupancy prediction.