 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
MCA: Moment Channel Attention Networks
Mar 04, 2024
Channel attention mechanisms endeavor to recalibrate channel weights to enhance representation abilities of networks. However, mainstream methods often rely solely on global average pooling as the feature squeezer, which significantly limits the overall potential of models. In this paper, we investigate the statistical moments of feature maps within a neural network. Our findings highlight the critical role of high-order moments in enhancing model capacity. Consequently, we introduce a flexible and comprehensive mechanism termed Extensive Moment Aggregation (EMA) to capture the global spatial context. Building upon this mechanism, we propose the Moment Channel Attention (MCA) framework, which efficiently incorporates multiple levels of moment-based information while minimizing additional computation costs through our Cross Moment Convolution (CMC) module. The CMC module via channel-wise convolution layer to capture multiple order moment information as well as cross channel features. The MCA block is designed to be lightweight and easily integrated into a variety of neural network architectures. Experimental results on classical image classification, object detection, and instance segmentation tasks demonstrate that our proposed method achieves state-of-the-art results, outperforming existing channel attention methods.
The Why, When, and How to Use Active Learning in Large-Data-Driven 3D Object Detection for Safe Autonomous Driving: An Empirical Exploration
Jan 30, 2024Active learning strategies for 3D object detection in autonomous driving datasets may help to address challenges of data imbalance, redundancy, and high-dimensional data. We demonstrate the effectiveness of entropy querying to select informative samples, aiming to reduce annotation costs and improve model performance. We experiment using the BEVFusion model for 3D object detection on the nuScenes dataset, comparing active learning to random sampling and demonstrating that entropy querying outperforms in most cases. The method is particularly effective in reducing the performance gap between majority and minority classes. Class-specific analysis reveals efficient allocation of annotated resources for limited data budgets, emphasizing the importance of selecting diverse and informative data for model training. Our findings suggest that entropy querying is a promising strategy for selecting data that enhances model learning in resource-constrained environments.
Self-Supervised Representation Learning with Meta Comprehensive Regularization
Mar 03, 2024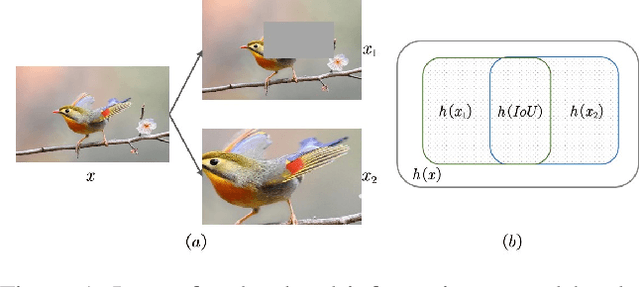
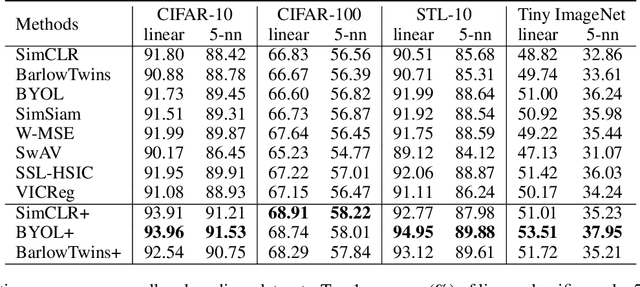
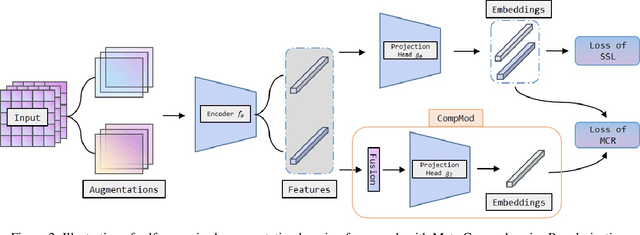
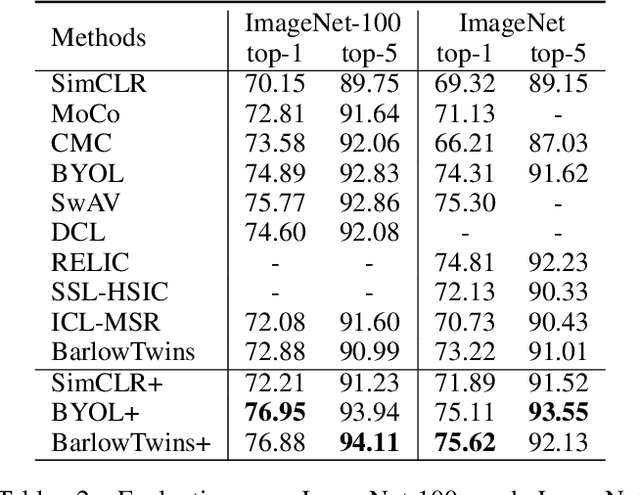
Self-Supervised Learning (SSL) methods harness the concept of semantic invariance by utilizing data augmentation strategies to produce similar representations for different deformations of the same input. Essentially, the model captures the shared information among multiple augmented views of samples, while disregarding the non-shared information that may be beneficial for downstream tasks. To address this issue, we introduce a module called CompMod with Meta Comprehensive Regularization (MCR), embedded into existing self-supervised frameworks, to make the learned representations more comprehensive. Specifically, we update our proposed model through a bi-level optimization mechanism, enabling it to capture comprehensive features. Additionally, guided by the constrained extraction of features using maximum entropy coding, the self-supervised learning model learns more comprehensive features on top of learning consistent features. In addition, we provide theoretical support for our proposed method from information theory and causal counterfactual perspective. Experimental results show that our method achieves significant improvement in classification, object detection and instance segmentation tasks on multiple benchmark datasets.
Preventing Catastrophic Forgetting through Memory Networks in Continuous Detection
Mar 21, 2024Modern pre-trained architectures struggle to retain previous information while undergoing continuous fine-tuning on new tasks. Despite notable progress in continual classification, systems designed for complex vision tasks such as detection or segmentation still struggle to attain satisfactory performance. In this work, we introduce a memory-based detection transformer architecture to adapt a pre-trained DETR-style detector to new tasks while preserving knowledge from previous tasks. We propose a novel localized query function for efficient information retrieval from memory units, aiming to minimize forgetting. Furthermore, we identify a fundamental challenge in continual detection referred to as background relegation. This arises when object categories from earlier tasks reappear in future tasks, potentially without labels, leading them to be implicitly treated as background. This is an inevitable issue in continual detection or segmentation. The introduced continual optimization technique effectively tackles this challenge. Finally, we assess the performance of our proposed system on continual detection benchmarks and demonstrate that our approach surpasses the performance of existing state-of-the-art resulting in 5-7% improvements on MS-COCO and PASCAL-VOC on the task of continual detection.
Beyond Night Visibility: Adaptive Multi-Scale Fusion of Infrared and Visible Images
Mar 02, 2024
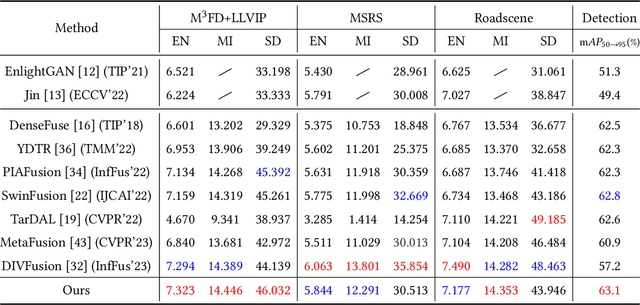
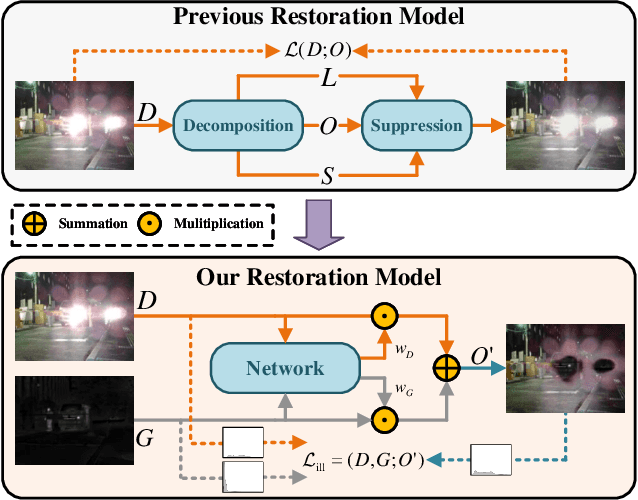
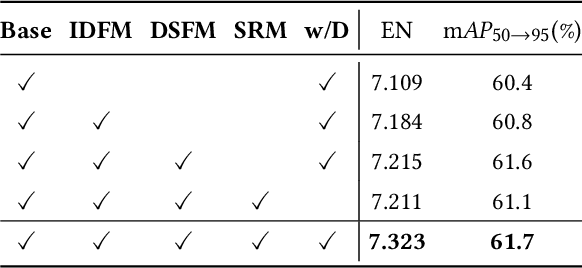
In addition to low light, night images suffer degradation from light effects (e.g., glare, floodlight, etc). However, existing nighttime visibility enhancement methods generally focus on low-light regions, which neglects, or even amplifies the light effects. To address this issue, we propose an Adaptive Multi-scale Fusion network (AMFusion) with infrared and visible images, which designs fusion rules according to different illumination regions. First, we separately fuse spatial and semantic features from infrared and visible images, where the former are used for the adjustment of light distribution and the latter are used for the improvement of detection accuracy. Thereby, we obtain an image free of low light and light effects, which improves the performance of nighttime object detection. Second, we utilize detection features extracted by a pre-trained backbone that guide the fusion of semantic features. Hereby, we design a Detection-guided Semantic Fusion Module (DSFM) to bridge the domain gap between detection and semantic features. Third, we propose a new illumination loss to constrain fusion image with normal light intensity. Experimental results demonstrate the superiority of AMFusion with better visual quality and detection accuracy. The source code will be released after the peer review process.
Measuring the Impact of Scene Level Objects on Object Detection: Towards Quantitative Explanations of Detection Decisions
Jan 19, 2024Although accuracy and other common metrics can provide a useful window into the performance of an object detection model, they lack a deeper view of the model's decision process. Regardless of the quality of the training data and process, the features that an object detection model learns cannot be guaranteed. A model may learn a relationship between certain background context, i.e., scene level objects, and the presence of the labeled classes. Furthermore, standard performance verification and metrics would not identify this phenomenon. This paper presents a new black box explainability method for additional verification of object detection models by finding the impact of scene level objects on the identification of the objects within the image. By comparing the accuracies of a model on test data with and without certain scene level objects, the contributions of these objects to the model's performance becomes clearer. The experiment presented here will assess the impact of buildings and people in image context on the detection of emergency road vehicles by a fine-tuned YOLOv8 model. A large increase in accuracy in the presence of a scene level object will indicate the model's reliance on that object to make its detections. The results of this research lead to providing a quantitative explanation of the object detection model's decision process, enabling a deeper understanding of the model's performance.
Robustness-Aware 3D Object Detection in Autonomous Driving: A Review and Outlook
Jan 12, 2024In the realm of modern autonomous driving, the perception system is indispensable for accurately assessing the state of the surrounding environment, thereby enabling informed prediction and planning. Key to this system is 3D object detection methods, that utilize vehicle-mounted sensors such as LiDAR and cameras to identify the size, category, and location of nearby objects. Despite the surge in 3D object detection methods aimed at enhancing detection precision and efficiency, there is a gap in the literature that systematically examines their resilience against environmental variations, noise, and weather changes. This study emphasizes the importance of robustness, alongside accuracy and latency, in evaluating perception systems under practical scenarios. Our work presents an extensive survey of camera-based, LiDAR-based, and multimodal 3D object detection algorithms, thoroughly evaluating their trade-off between accuracy, latency, and robustness, particularly on datasets like KITTI-C and nuScenes-C to ensure fair comparisons. Among these,multimodal 3D detection approaches exhibit superior robustness and a novel taxonomy is introduced to reorganize its literature for enhanced clarity. This survey aims to offer a more practical perspective on the current capabilities and constraints of 3D object detection algorithms in real-world applications, thus steering future research towards robustness-centric advancements
BlenDA: Domain Adaptive Object Detection through diffusion-based blending
Jan 18, 2024Unsupervised domain adaptation (UDA) aims to transfer a model learned using labeled data from the source domain to unlabeled data in the target domain. To address the large domain gap issue between the source and target domains, we propose a novel regularization method for domain adaptive object detection, BlenDA, by generating the pseudo samples of the intermediate domains and their corresponding soft domain labels for adaptation training. The intermediate samples are generated by dynamically blending the source images with their corresponding translated images using an off-the-shelf pre-trained text-to-image diffusion model which takes the text label of the target domain as input and has demonstrated superior image-to-image translation quality. Based on experimental results from two adaptation benchmarks, our proposed approach can significantly enhance the performance of the state-of-the-art domain adaptive object detector, Adversarial Query Transformer (AQT). Particularly, in the Cityscapes to Foggy Cityscapes adaptation, we achieve an impressive 53.4% mAP on the Foggy Cityscapes dataset, surpassing the previous state-of-the-art by 1.5%. It is worth noting that our proposed method is also applicable to various paradigms of domain adaptive object detection. The code is available at:https://github.com/aiiu-lab/BlenDA
WeakSAM: Segment Anything Meets Weakly-supervised Instance-level Recognition
Feb 22, 2024Weakly supervised visual recognition using inexact supervision is a critical yet challenging learning problem. It significantly reduces human labeling costs and traditionally relies on multi-instance learning and pseudo-labeling. This paper introduces WeakSAM and solves the weakly-supervised object detection (WSOD) and segmentation by utilizing the pre-learned world knowledge contained in a vision foundation model, i.e., the Segment Anything Model (SAM). WeakSAM addresses two critical limitations in traditional WSOD retraining, i.e., pseudo ground truth (PGT) incompleteness and noisy PGT instances, through adaptive PGT generation and Region of Interest (RoI) drop regularization. It also addresses the SAM's problems of requiring prompts and category unawareness for automatic object detection and segmentation. Our results indicate that WeakSAM significantly surpasses previous state-of-the-art methods in WSOD and WSIS benchmarks with large margins, i.e. average improvements of 7.4% and 8.5%, respectively. The code is available at \url{https://github.com/hustvl/WeakSAM}.
MAMBA: Multi-level Aggregation via Memory Bank for Video Object Detection
Feb 01, 2024State-of-the-art video object detection methods maintain a memory structure, either a sliding window or a memory queue, to enhance the current frame using attention mechanisms. However, we argue that these memory structures are not efficient or sufficient because of two implied operations: (1) concatenating all features in memory for enhancement, leading to a heavy computational cost; (2) frame-wise memory updating, preventing the memory from capturing more temporal information. In this paper, we propose a multi-level aggregation architecture via memory bank called MAMBA. Specifically, our memory bank employs two novel operations to eliminate the disadvantages of existing methods: (1) light-weight key-set construction which can significantly reduce the computational cost; (2) fine-grained feature-wise updating strategy which enables our method to utilize knowledge from the whole video. To better enhance features from complementary levels, i.e., feature maps and proposals, we further propose a generalized enhancement operation (GEO) to aggregate multi-level features in a unified manner. We conduct extensive evaluations on the challenging ImageNetVID dataset. Compared with existing state-of-the-art methods, our method achieves superior performance in terms of both speed and accuracy. More remarkably, MAMBA achieves mAP of 83.7/84.6% at 12.6/9.1 FPS with ResNet-101. Code is available at https://github.com/guanxiongsun/vfe.pytorch.
* update code url https://github.com/guanxiongsun/vfe.pytorch