 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
$V_kD:$ Improving Knowledge Distillation using Orthogonal Projections
Mar 10, 2024
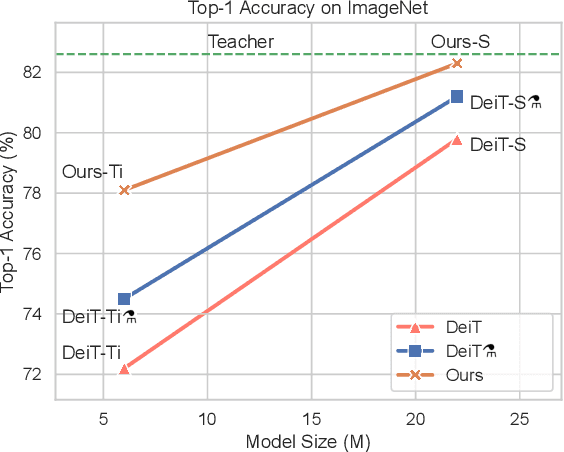
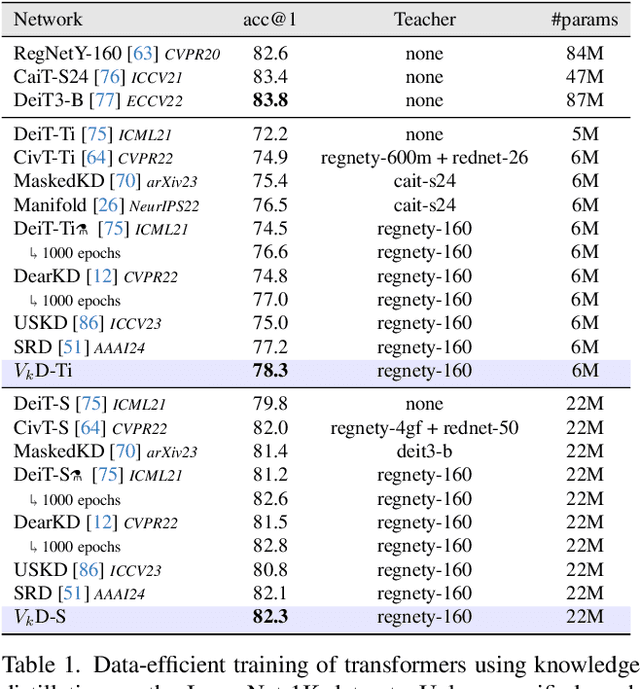
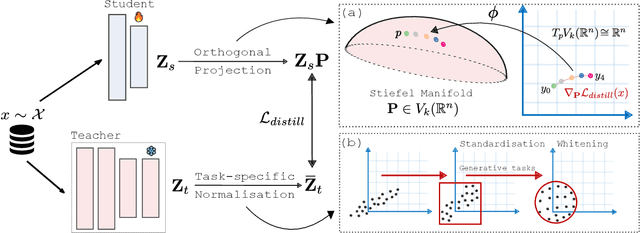
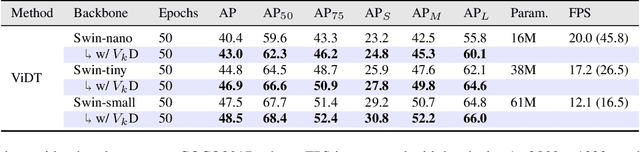
Knowledge distillation is an effective method for training small and efficient deep learning models. However, the efficacy of a single method can degenerate when transferring to other tasks, modalities, or even other architectures. To address this limitation, we propose a novel constrained feature distillation method. This method is derived from a small set of core principles, which results in two emerging components: an orthogonal projection and a task-specific normalisation. Equipped with both of these components, our transformer models can outperform all previous methods on ImageNet and reach up to a 4.4% relative improvement over the previous state-of-the-art methods. To further demonstrate the generality of our method, we apply it to object detection and image generation, whereby we obtain consistent and substantial performance improvements over state-of-the-art. Code and models are publicly available: https://github.com/roymiles/vkd
Knowledge Graph Driven UAV Cognitive Semantic Communication Systems for Efficient Object Detection
Jan 25, 2024Unmanned aerial vehicles (UAVs) are widely used for object detection. However, the existing UAV-based object detection systems are subject to the serious challenge, namely, the finite computation, energy and communication resources, which limits the achievable detection performance. In order to overcome this challenge, a UAV cognitive semantic communication system is proposed by exploiting knowledge graph. Moreover, a multi-scale compression network is designed for semantic compression to reduce data transmission volume while guaranteeing the detection performance. Furthermore, an object detection scheme is proposed by using the knowledge graph to overcome channel noise interference and compression distortion. Simulation results conducted on the practical aerial image dataset demonstrate that compared to the benchmark systems, our proposed system has superior detection accuracy, communication robustness and computation efficiency even under high compression rates and low signal-to-noise ratio (SNR) conditions.
Poly Kernel Inception Network for Remote Sensing Detection
Mar 10, 2024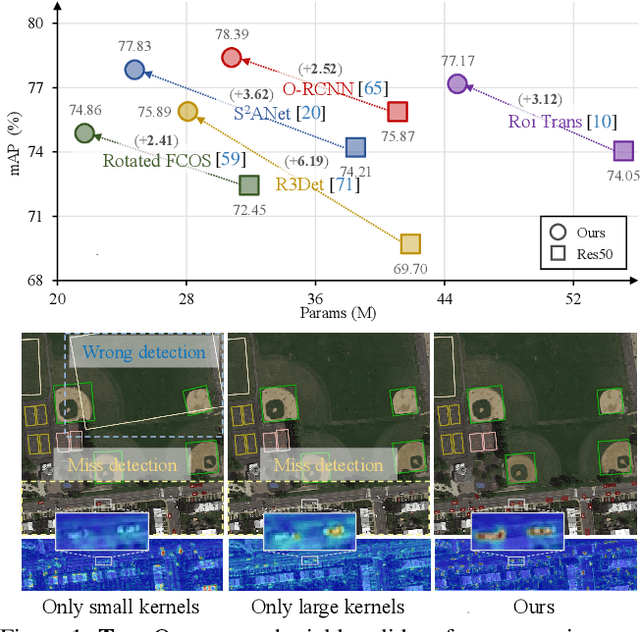
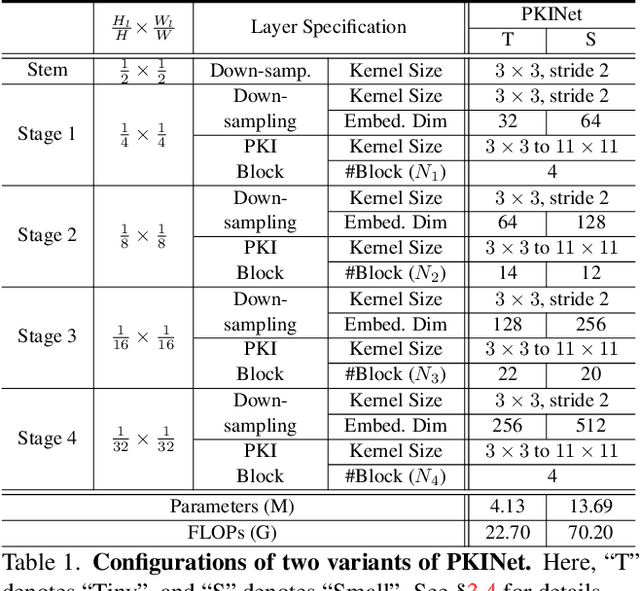
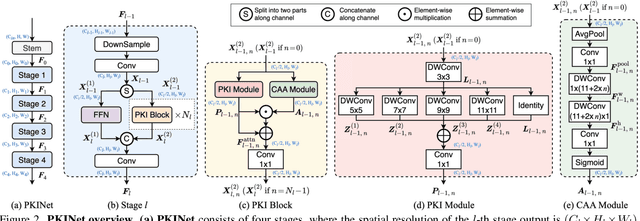
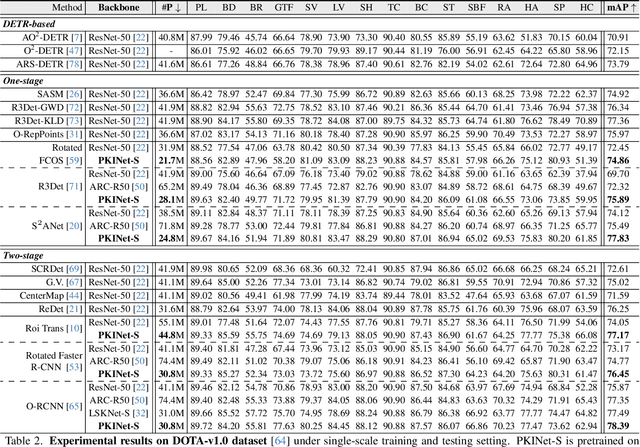
Object detection in remote sensing images (RSIs) often suffers from several increasing challenges, including the large variation in object scales and the diverse-ranging context. Prior methods tried to address these challenges by expanding the spatial receptive field of the backbone, either through large-kernel convolution or dilated convolution. However, the former typically introduces considerable background noise, while the latter risks generating overly sparse feature representations. In this paper, we introduce the Poly Kernel Inception Network (PKINet) to handle the above challenges. PKINet employs multi-scale convolution kernels without dilation to extract object features of varying scales and capture local context. In addition, a Context Anchor Attention (CAA) module is introduced in parallel to capture long-range contextual information. These two components work jointly to advance the performance of PKINet on four challenging remote sensing detection benchmarks, namely DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R.
FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything
Feb 29, 2024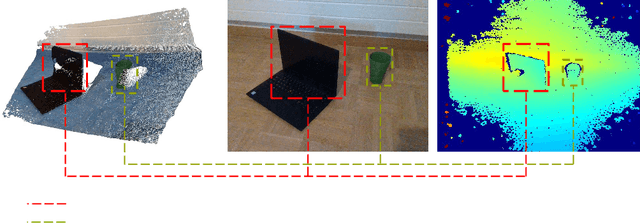



In the realm of computer vision, the integration of advanced techniques into the processing of RGB-D camera inputs poses a significant challenge, given the inherent complexities arising from diverse environmental conditions and varying object appearances. Therefore, this paper introduces FusionVision, an exhaustive pipeline adapted for the robust 3D segmentation of objects in RGB-D imagery. Traditional computer vision systems face limitations in simultaneously capturing precise object boundaries and achieving high-precision object detection on depth map as they are mainly proposed for RGB cameras. To address this challenge, FusionVision adopts an integrated approach by merging state-of-the-art object detection techniques, with advanced instance segmentation methods. The integration of these components enables a holistic (unified analysis of information obtained from both color \textit{RGB} and depth \textit{D} channels) interpretation of RGB-D data, facilitating the extraction of comprehensive and accurate object information. The proposed FusionVision pipeline employs YOLO for identifying objects within the RGB image domain. Subsequently, FastSAM, an innovative semantic segmentation model, is applied to delineate object boundaries, yielding refined segmentation masks. The synergy between these components and their integration into 3D scene understanding ensures a cohesive fusion of object detection and segmentation, enhancing overall precision in 3D object segmentation. The code and pre-trained models are publicly available at https://github.com/safouaneelg/FusionVision/.
Frequency-Adaptive Dilated Convolution for Semantic Segmentation
Mar 12, 2024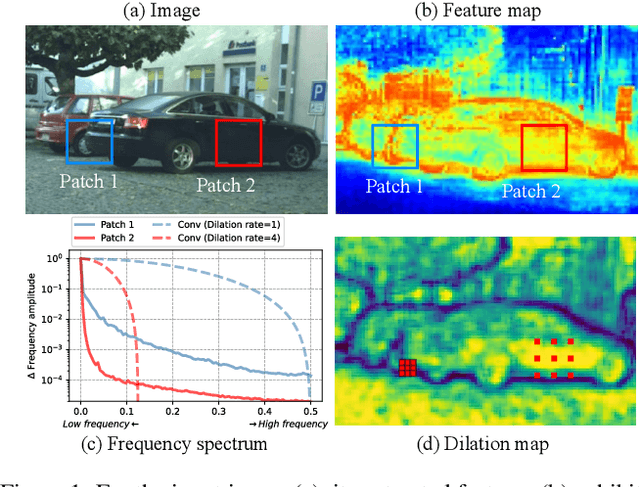
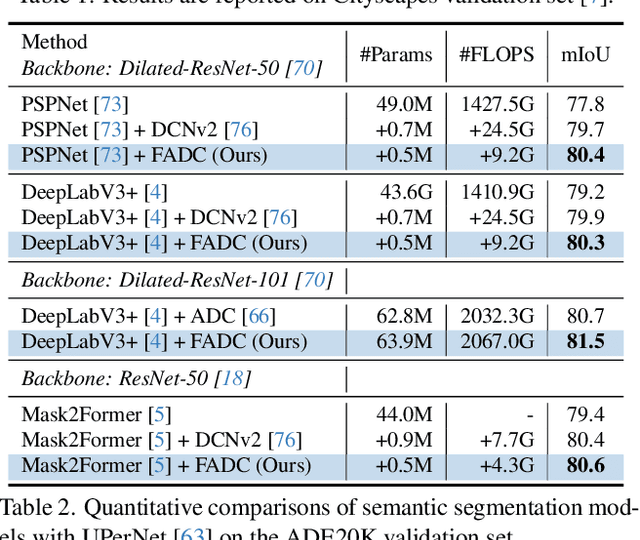
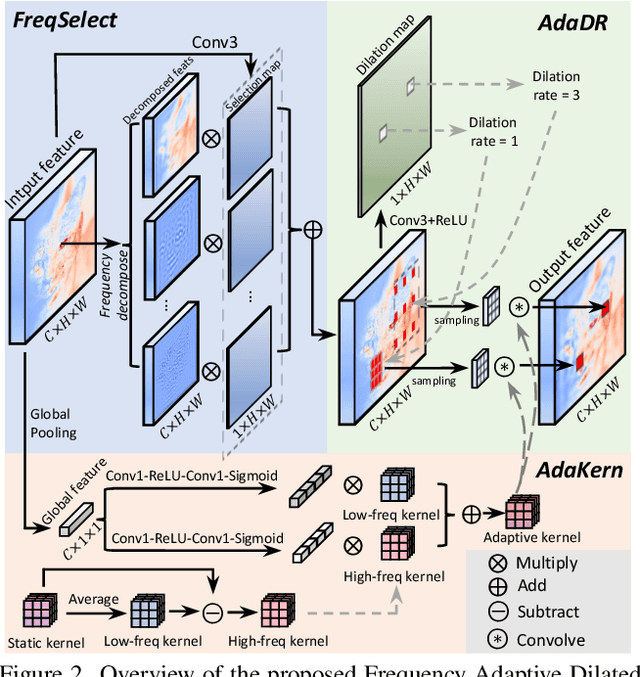
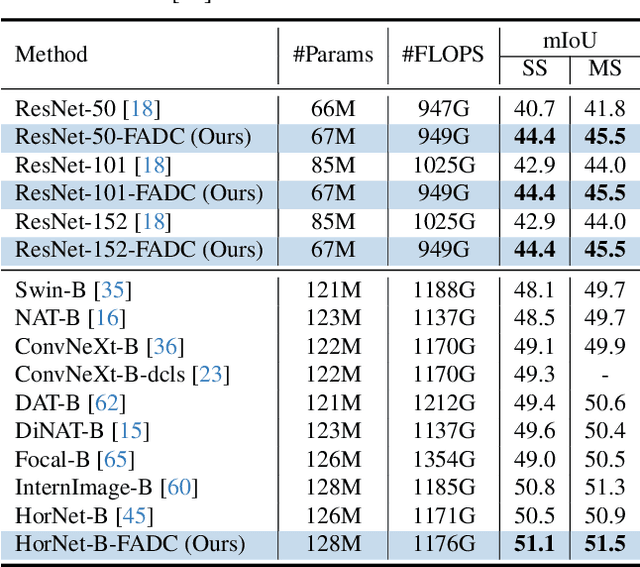
Dilated convolution, which expands the receptive field by inserting gaps between its consecutive elements, is widely employed in computer vision. In this study, we propose three strategies to improve individual phases of dilated convolution from the view of spectrum analysis. Departing from the conventional practice of fixing a global dilation rate as a hyperparameter, we introduce Frequency-Adaptive Dilated Convolution (FADC), which dynamically adjusts dilation rates spatially based on local frequency components. Subsequently, we design two plug-in modules to directly enhance effective bandwidth and receptive field size. The Adaptive Kernel (AdaKern) module decomposes convolution weights into low-frequency and high-frequency components, dynamically adjusting the ratio between these components on a per-channel basis. By increasing the high-frequency part of convolution weights, AdaKern captures more high-frequency components, thereby improving effective bandwidth. The Frequency Selection (FreqSelect) module optimally balances high- and low-frequency components in feature representations through spatially variant reweighting. It suppresses high frequencies in the background to encourage FADC to learn a larger dilation, thereby increasing the receptive field for an expanded scope. Extensive experiments on segmentation and object detection consistently validate the efficacy of our approach. The code is publicly available at \url{https://github.com/Linwei-Chen/FADC}.
PeLK: Parameter-efficient Large Kernel ConvNets with Peripheral Convolution
Mar 12, 2024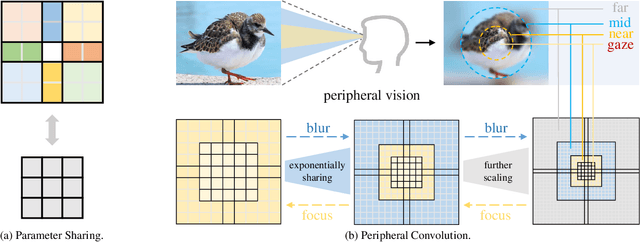

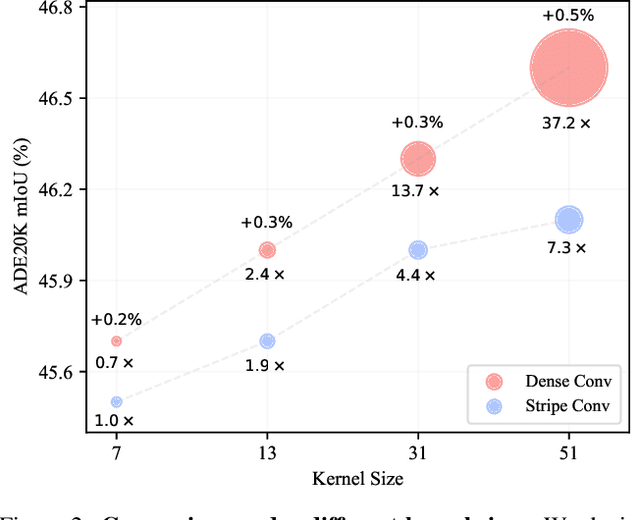
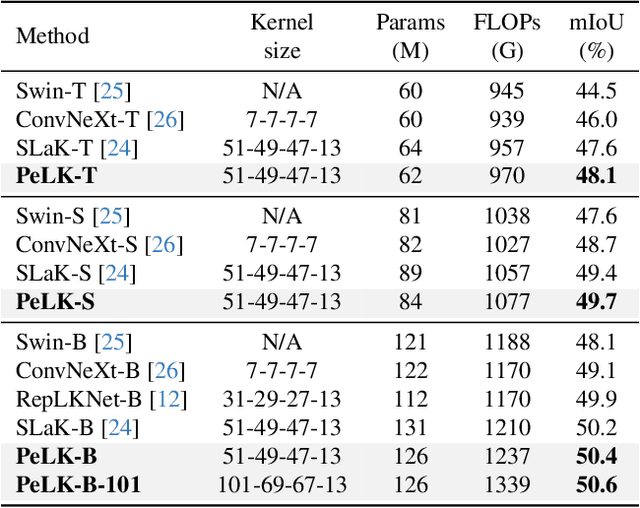
Recently, some large kernel convnets strike back with appealing performance and efficiency. However, given the square complexity of convolution, scaling up kernels can bring about an enormous amount of parameters and the proliferated parameters can induce severe optimization problem. Due to these issues, current CNNs compromise to scale up to 51x51 in the form of stripe convolution (i.e., 51x5 + 5x51) and start to saturate as the kernel size continues growing. In this paper, we delve into addressing these vital issues and explore whether we can continue scaling up kernels for more performance gains. Inspired by human vision, we propose a human-like peripheral convolution that efficiently reduces over 90% parameter count of dense grid convolution through parameter sharing, and manage to scale up kernel size to extremely large. Our peripheral convolution behaves highly similar to human, reducing the complexity of convolution from O(K^2) to O(logK) without backfiring performance. Built on this, we propose Parameter-efficient Large Kernel Network (PeLK). Our PeLK outperforms modern vision Transformers and ConvNet architectures like Swin, ConvNeXt, RepLKNet and SLaK on various vision tasks including ImageNet classification, semantic segmentation on ADE20K and object detection on MS COCO. For the first time, we successfully scale up the kernel size of CNNs to an unprecedented 101x101 and demonstrate consistent improvements.
Cross-domain and Cross-dimension Learning for Image-to-Graph Transformers
Mar 11, 2024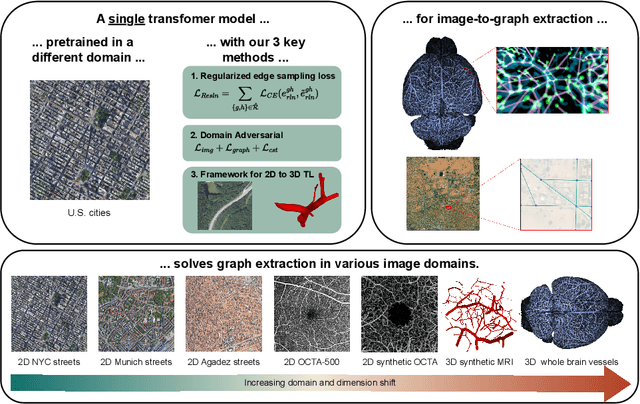
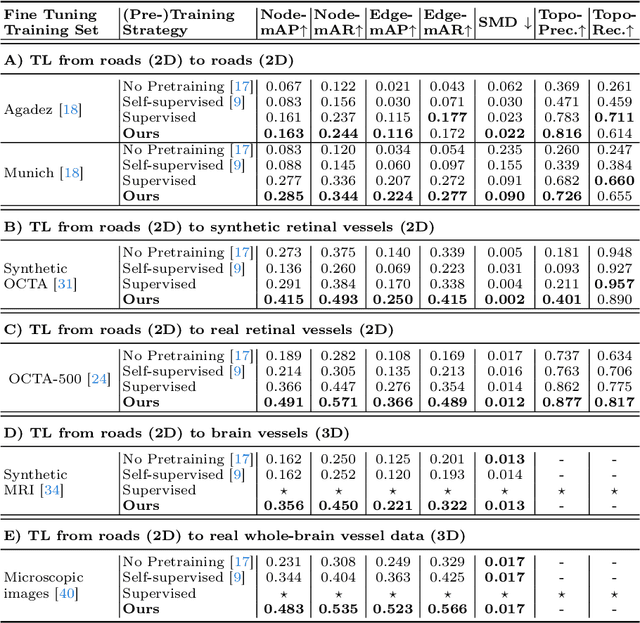

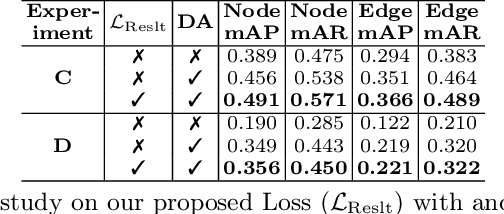
Direct image-to-graph transformation is a challenging task that solves object detection and relationship prediction in a single model. Due to the complexity of this task, large training datasets are rare in many domains, which makes the training of large networks challenging. This data sparsity necessitates the establishment of pre-training strategies akin to the state-of-the-art in computer vision. In this work, we introduce a set of methods enabling cross-domain and cross-dimension transfer learning for image-to-graph transformers. We propose (1) a regularized edge sampling loss for sampling the optimal number of object relationships (edges) across domains, (2) a domain adaptation framework for image-to-graph transformers that aligns features from different domains, and (3) a simple projection function that allows us to pretrain 3D transformers on 2D input data. We demonstrate our method's utility in cross-domain and cross-dimension experiments, where we pretrain our models on 2D satellite images before applying them to vastly different target domains in 2D and 3D. Our method consistently outperforms a series of baselines on challenging benchmarks, such as retinal or whole-brain vessel graph extraction.
Improving the Successful Robotic Grasp Detection Using Convolutional Neural Networks
Mar 08, 2024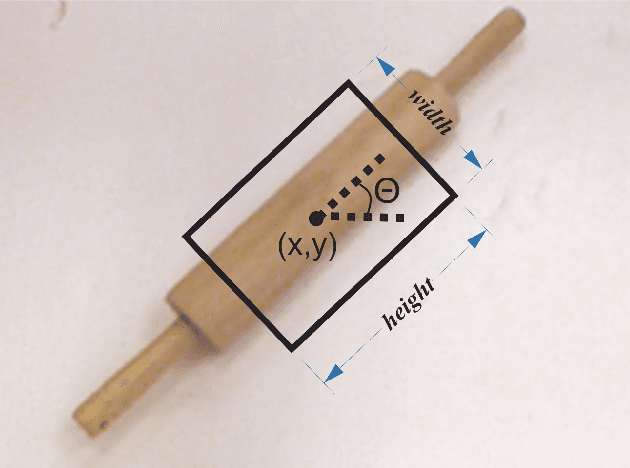

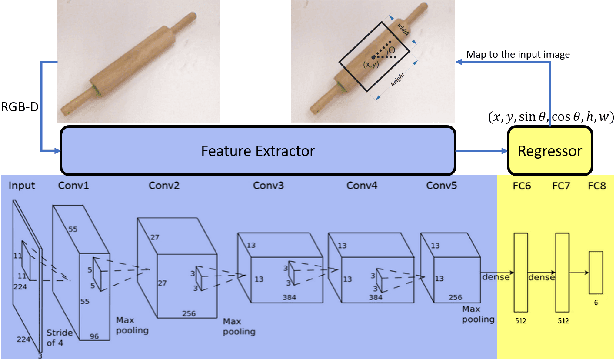
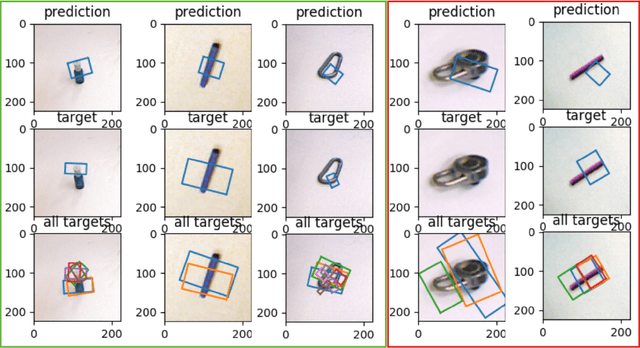
Robotic grasp should be carried out in a real-time manner by proper accuracy. Perception is the first and significant step in this procedure. This paper proposes an improved pipeline model trying to detect grasp as a rectangle representation for different seen or unseen objects. It helps the robot to start control procedures from nearer to the proper part of the object. The main idea consists in pre-processing, output normalization, and data augmentation to improve accuracy by 4.3 percent without making the system slow. Also, a comparison has been conducted over different pre-trained models like AlexNet, ResNet, Vgg19, which are the most famous feature extractors for image processing in object detection. Although AlexNet has less complexity than other ones, it outperformed them, which helps the real-time property.
Detecting Concrete Visual Tokens for Multimodal Machine Translation
Mar 05, 2024
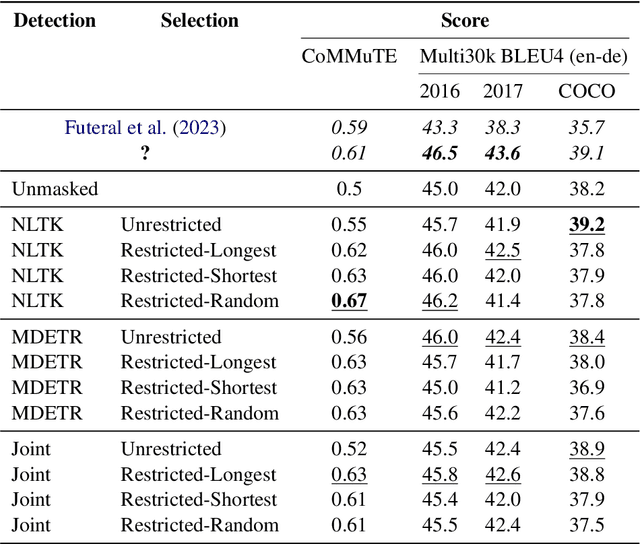

The challenge of visual grounding and masking in multimodal machine translation (MMT) systems has encouraged varying approaches to the detection and selection of visually-grounded text tokens for masking. We introduce new methods for detection of visually and contextually relevant (concrete) tokens from source sentences, including detection with natural language processing (NLP), detection with object detection, and a joint detection-verification technique. We also introduce new methods for selection of detected tokens, including shortest $n$ tokens, longest $n$ tokens, and all detected concrete tokens. We utilize the GRAM MMT architecture to train models against synthetically collated multimodal datasets of source images with masked sentences, showing performance improvements and improved usage of visual context during translation tasks over the baseline model.
YOLO-World: Real-Time Open-Vocabulary Object Detection
Feb 02, 2024The You Only Look Once (YOLO) series of detectors have established themselves as efficient and practical tools. However, their reliance on predefined and trained object categories limits their applicability in open scenarios. Addressing this limitation, we introduce YOLO-World, an innovative approach that enhances YOLO with open-vocabulary detection capabilities through vision-language modeling and pre-training on large-scale datasets. Specifically, we propose a new Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) and region-text contrastive loss to facilitate the interaction between visual and linguistic information. Our method excels in detecting a wide range of objects in a zero-shot manner with high efficiency. On the challenging LVIS dataset, YOLO-World achieves 35.4 AP with 52.0 FPS on V100, which outperforms many state-of-the-art methods in terms of both accuracy and speed. Furthermore, the fine-tuned YOLO-World achieves remarkable performance on several downstream tasks, including object detection and open-vocabulary instance segmentation.