 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
FLAME Diffuser: Grounded Wildfire Image Synthesis using Mask Guided Diffusion
Mar 06, 2024
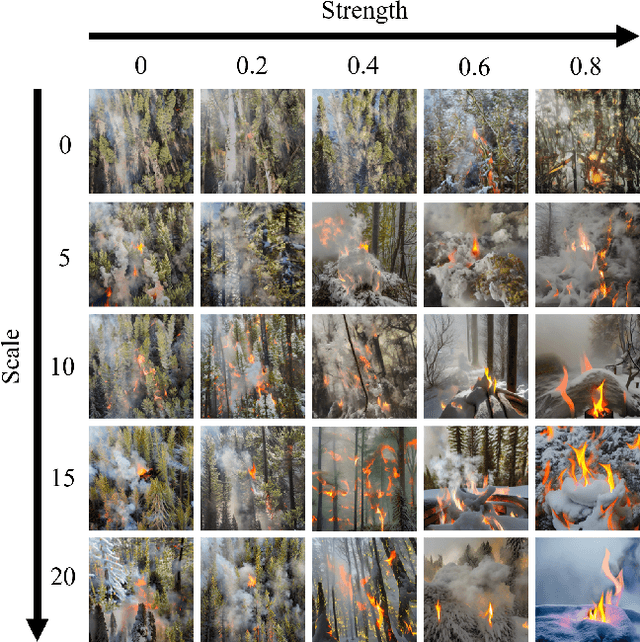



The rise of machine learning in recent years has brought benefits to various research fields such as wide fire detection. Nevertheless, small object detection and rare object detection remain a challenge. To address this problem, we present a dataset automata that can generate ground truth paired datasets using diffusion models. Specifically, we introduce a mask-guided diffusion framework that can fusion the wildfire into the existing images while the flame position and size can be precisely controlled. In advance, to fill the gap that the dataset of wildfire images in specific scenarios is missing, we vary the background of synthesized images by controlling both the text prompt and input image. Furthermore, to solve the color tint problem or the well-known domain shift issue, we apply the CLIP model to filter the generated massive dataset to preserve quality. Thus, our proposed framework can generate a massive dataset of that images are high-quality and ground truth-paired, which well addresses the needs of the annotated datasets in specific tasks.
CSDNet: Detect Salient Object in Depth-Thermal via A Lightweight Cross Shallow and Deep Perception Network
Mar 15, 2024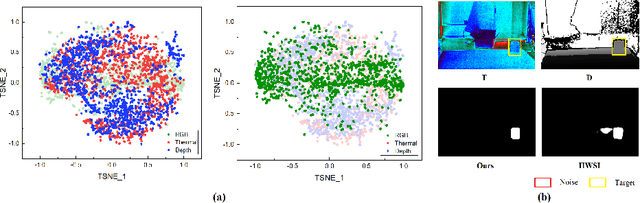
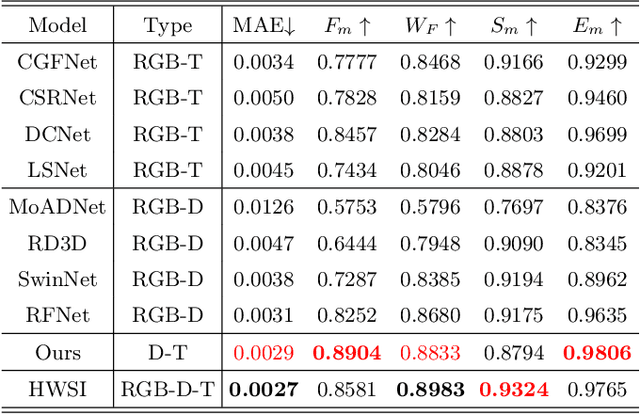
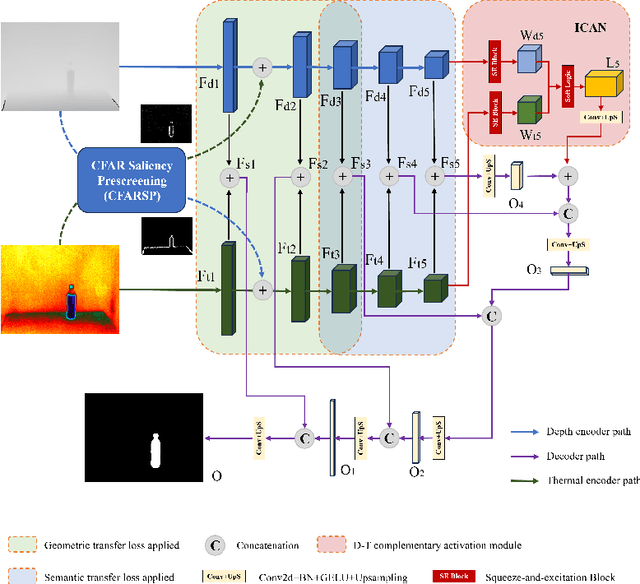
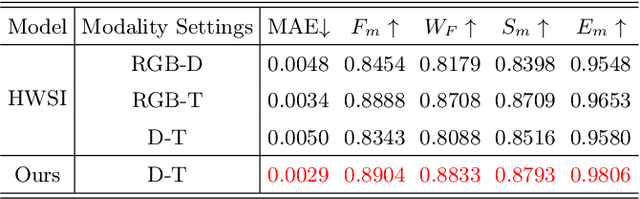
While we enjoy the richness and informativeness of multimodal data, it also introduces interference and redundancy of information. To achieve optimal domain interpretation with limited resources, we propose CSDNet, a lightweight \textbf{C}ross \textbf{S}hallow and \textbf{D}eep Perception \textbf{Net}work designed to integrate two modalities with less coherence, thereby discarding redundant information or even modality. We implement our CSDNet for Salient Object Detection (SOD) task in robotic perception. The proposed method capitalises on spatial information prescreening and implicit coherence navigation across shallow and deep layers of the depth-thermal (D-T) modality, prioritising integration over fusion to maximise the scene interpretation. To further refine the descriptive capabilities of the encoder for the less-known D-T modalities, we also propose SAMAEP to guide an effective feature mapping to the generalised feature space. Our approach is tested on the VDT-2048 dataset, leveraging the D-T modality outperforms those of SOTA methods using RGB-T or RGB-D modalities for the first time, achieves comparable performance with the RGB-D-T triple-modality benchmark method with 5.97 times faster at runtime and demanding 0.0036 times fewer FLOPs. Demonstrates the proposed CSDNet effectively integrates the information from the D-T modality. The code will be released upon acceptance.
CLIP-EBC: CLIP Can Count Accurately through Enhanced Blockwise Classification
Mar 14, 2024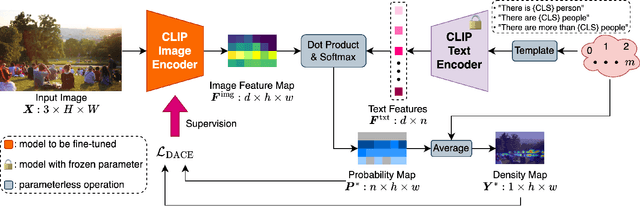
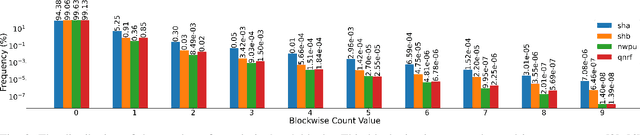
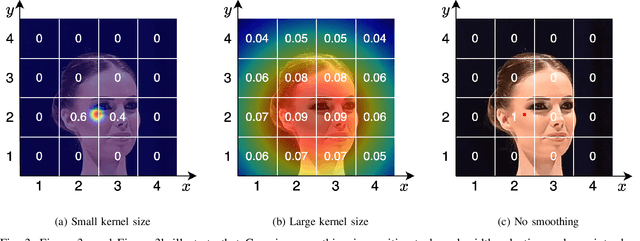
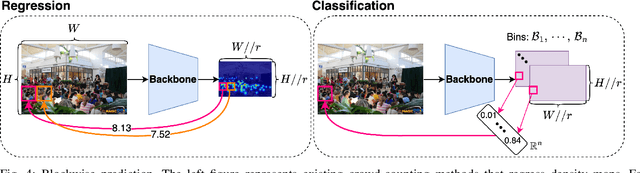
The CLIP (Contrastive Language-Image Pretraining) model has exhibited outstanding performance in recognition problems, such as zero-shot image classification and object detection. However, its ability to count remains understudied due to the inherent challenges of transforming counting--a regression task--into a recognition task. In this paper, we investigate CLIP's potential in counting, focusing specifically on estimating crowd sizes. Existing classification-based crowd-counting methods have encountered issues, including inappropriate discretization strategies, which impede the application of CLIP and result in suboptimal performance. To address these challenges, we propose the Enhanced Blockwise Classification (EBC) framework. In contrast to previous methods, EBC relies on integer-valued bins that facilitate the learning of robust decision boundaries. Within our model-agnostic EBC framework, we introduce CLIP-EBC, the first fully CLIP-based crowd-counting model capable of generating density maps. Comprehensive evaluations across diverse crowd-counting datasets demonstrate the state-of-the-art performance of our methods. Particularly, EBC can improve existing models by up to 76.9%. Moreover, our CLIP-EBC model surpasses current crowd-counting methods, achieving mean absolute errors of 55.0 and 6.3 on ShanghaiTech part A and part B datasets, respectively. The code will be made publicly available.
Multi-task Learning for Real-time Autonomous Driving Leveraging Task-adaptive Attention Generator
Mar 06, 2024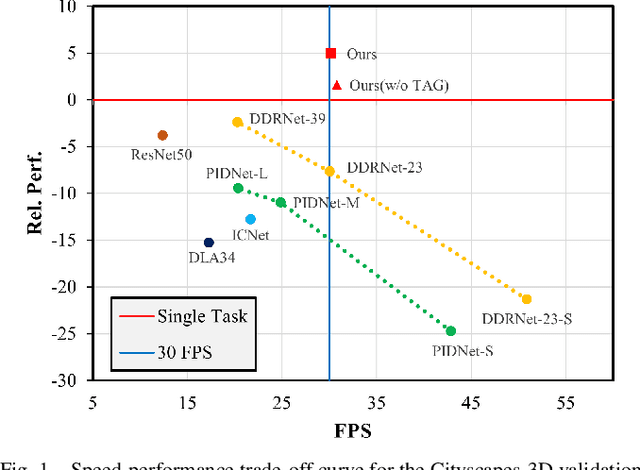
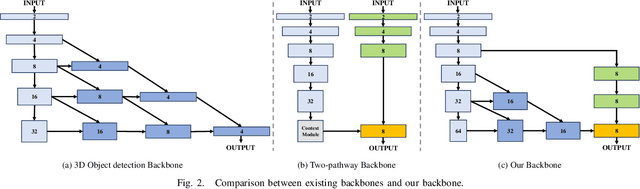
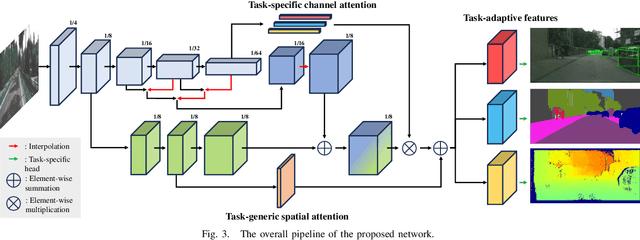
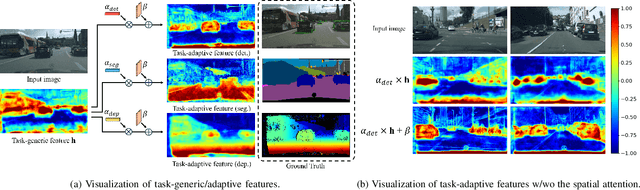
Real-time processing is crucial in autonomous driving systems due to the imperative of instantaneous decision-making and rapid response. In real-world scenarios, autonomous vehicles are continuously tasked with interpreting their surroundings, analyzing intricate sensor data, and making decisions within split seconds to ensure safety through numerous computer vision tasks. In this paper, we present a new real-time multi-task network adept at three vital autonomous driving tasks: monocular 3D object detection, semantic segmentation, and dense depth estimation. To counter the challenge of negative transfer, which is the prevalent issue in multi-task learning, we introduce a task-adaptive attention generator. This generator is designed to automatically discern interrelations across the three tasks and arrange the task-sharing pattern, all while leveraging the efficiency of the hard-parameter sharing approach. To the best of our knowledge, the proposed model is pioneering in its capability to concurrently handle multiple tasks, notably 3D object detection, while maintaining real-time processing speeds. Our rigorously optimized network, when tested on the Cityscapes-3D datasets, consistently outperforms various baseline models. Moreover, an in-depth ablation study substantiates the efficacy of the methodologies integrated into our framework.
Rectify the Regression Bias in Long-Tailed Object Detection
Jan 31, 2024Long-tailed object detection faces great challenges because of its extremely imbalanced class distribution. Recent methods mainly focus on the classification bias and its loss function design, while ignoring the subtle influence of the regression branch. This paper shows that the regression bias exists and does adversely and seriously impact the detection accuracy. While existing methods fail to handle the regression bias, the class-specific regression head for rare classes is hypothesized to be the main cause of it in this paper. As a result, three kinds of viable solutions to cater for the rare categories are proposed, including adding a class-agnostic branch, clustering heads and merging heads. The proposed methods brings in consistent and significant improvements over existing long-tailed detection methods, especially in rare and common classes. The proposed method achieves state-of-the-art performance in the large vocabulary LVIS dataset with different backbones and architectures. It generalizes well to more difficult evaluation metrics, relatively balanced datasets, and the mask branch. This is the first attempt to reveal and explore rectifying of the regression bias in long-tailed object detection.
Adaptive Bounding Box Uncertainties via Two-Step Conformal Prediction
Mar 12, 2024
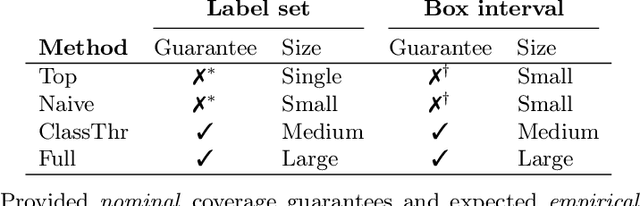
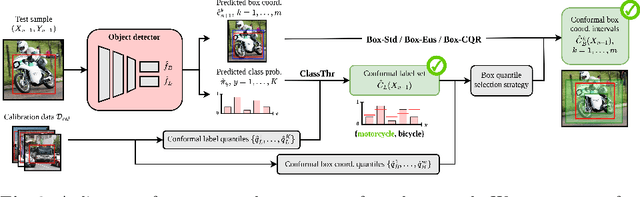
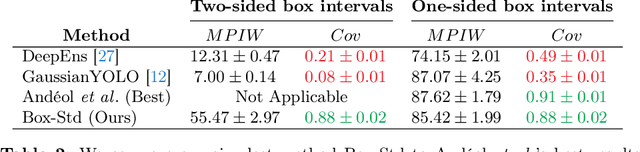
Quantifying a model's predictive uncertainty is essential for safety-critical applications such as autonomous driving. We consider quantifying such uncertainty for multi-object detection. In particular, we leverage conformal prediction to obtain uncertainty intervals with guaranteed coverage for object bounding boxes. One challenge in doing so is that bounding box predictions are conditioned on the object's class label. Thus, we develop a novel two-step conformal approach that propagates uncertainty in predicted class labels into the uncertainty intervals for the bounding boxes. This broadens the validity of our conformal coverage guarantees to include incorrectly classified objects, ensuring their usefulness when maximal safety assurances are required. Moreover, we investigate novel ensemble and quantile regression formulations to ensure the bounding box intervals are adaptive to object size, leading to a more balanced coverage across sizes. Validating our two-step approach on real-world datasets for 2D bounding box localization, we find that desired coverage levels are satisfied with actionably tight predictive uncertainty intervals.
G-NAS: Generalizable Neural Architecture Search for Single Domain Generalization Object Detection
Feb 07, 2024In this paper, we focus on a realistic yet challenging task, Single Domain Generalization Object Detection (S-DGOD), where only one source domain's data can be used for training object detectors, but have to generalize multiple distinct target domains. In S-DGOD, both high-capacity fitting and generalization abilities are needed due to the task's complexity. Differentiable Neural Architecture Search (NAS) is known for its high capacity for complex data fitting and we propose to leverage Differentiable NAS to solve S-DGOD. However, it may confront severe over-fitting issues due to the feature imbalance phenomenon, where parameters optimized by gradient descent are biased to learn from the easy-to-learn features, which are usually non-causal and spuriously correlated to ground truth labels, such as the features of background in object detection data. Consequently, this leads to serious performance degradation, especially in generalizing to unseen target domains with huge domain gaps between the source domain and target domains. To address this issue, we propose the Generalizable loss (G-loss), which is an OoD-aware objective, preventing NAS from over-fitting by using gradient descent to optimize parameters not only on a subset of easy-to-learn features but also the remaining predictive features for generalization, and the overall framework is named G-NAS. Experimental results on the S-DGOD urban-scene datasets demonstrate that the proposed G-NAS achieves SOTA performance compared to baseline methods. Codes are available at https://github.com/wufan-cse/G-NAS.
Context-aware Multi-Model Object Detection for Diversely Heterogeneous Compute Systems
Feb 12, 2024In recent years, deep neural networks (DNNs) have gained widespread adoption for continuous mobile object detection (OD) tasks, particularly in autonomous systems. However, a prevalent issue in their deployment is the one-size-fits-all approach, where a single DNN is used, resulting in inefficient utilization of computational resources. This inefficiency is particularly detrimental in energy-constrained systems, as it degrades overall system efficiency. We identify that, the contextual information embedded in the input data stream (e.g. the frames in the camera feed that the OD models are run on) could be exploited to allow a more efficient multi-model-based OD process. In this paper, we propose SHIFT which continuously selects from a variety of DNN-based OD models depending on the dynamically changing contextual information and computational constraints. During this selection, SHIFT uniquely considers multi-accelerator execution to better optimize the energy-efficiency while satisfying the latency constraints. Our proposed methodology results in improvements of up to 7.5x in energy usage and 2.8x in latency compared to state-of-the-art GPU-based single model OD approaches.
AYDIV: Adaptable Yielding 3D Object Detection via Integrated Contextual Vision Transformer
Feb 12, 2024Combining LiDAR and camera data has shown potential in enhancing short-distance object detection in autonomous driving systems. Yet, the fusion encounters difficulties with extended distance detection due to the contrast between LiDAR's sparse data and the dense resolution of cameras. Besides, discrepancies in the two data representations further complicate fusion methods. We introduce AYDIV, a novel framework integrating a tri-phase alignment process specifically designed to enhance long-distance detection even amidst data discrepancies. AYDIV consists of the Global Contextual Fusion Alignment Transformer (GCFAT), which improves the extraction of camera features and provides a deeper understanding of large-scale patterns; the Sparse Fused Feature Attention (SFFA), which fine-tunes the fusion of LiDAR and camera details; and the Volumetric Grid Attention (VGA) for a comprehensive spatial data fusion. AYDIV's performance on the Waymo Open Dataset (WOD) with an improvement of 1.24% in mAPH value(L2 difficulty) and the Argoverse2 Dataset with a performance improvement of 7.40% in AP value demonstrates its efficacy in comparison to other existing fusion-based methods. Our code is publicly available at https://github.com/sanjay-810/AYDIV2
MultiCorrupt: A Multi-Modal Robustness Dataset and Benchmark of LiDAR-Camera Fusion for 3D Object Detection
Feb 18, 2024Multi-modal 3D object detection models for automated driving have demonstrated exceptional performance on computer vision benchmarks like nuScenes. However, their reliance on densely sampled LiDAR point clouds and meticulously calibrated sensor arrays poses challenges for real-world applications. Issues such as sensor misalignment, miscalibration, and disparate sampling frequencies lead to spatial and temporal misalignment in data from LiDAR and cameras. Additionally, the integrity of LiDAR and camera data is often compromised by adverse environmental conditions such as inclement weather, leading to occlusions and noise interference. To address this challenge, we introduce MultiCorrupt, a comprehensive benchmark designed to evaluate the robustness of multi-modal 3D object detectors against ten distinct types of corruptions. We evaluate five state-of-the-art multi-modal detectors on MultiCorrupt and analyze their performance in terms of their resistance ability. Our results show that existing methods exhibit varying degrees of robustness depending on the type of corruption and their fusion strategy. We provide insights into which multi-modal design choices make such models robust against certain perturbations. The dataset generation code and benchmark are open-sourced at https://github.com/ika-rwth-aachen/MultiCorrupt.