 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Spiking CenterNet: A Distillation-boosted Spiking Neural Network for Object Detection
Feb 02, 2024
In the era of AI at the edge, self-driving cars, and climate change, the need for energy-efficient, small, embedded AI is growing. Spiking Neural Networks (SNNs) are a promising approach to address this challenge, with their event-driven information flow and sparse activations. We propose Spiking CenterNet for object detection on event data. It combines an SNN CenterNet adaptation with an efficient M2U-Net-based decoder. Our model significantly outperforms comparable previous work on Prophesee's challenging GEN1 Automotive Detection Dataset while using less than half the energy. Distilling the knowledge of a non-spiking teacher into our SNN further increases performance. To the best of our knowledge, our work is the first approach that takes advantage of knowledge distillation in the field of spiking object detection.
EfficientMFD: Towards More Efficient Multimodal Synchronous Fusion Detection
Mar 14, 2024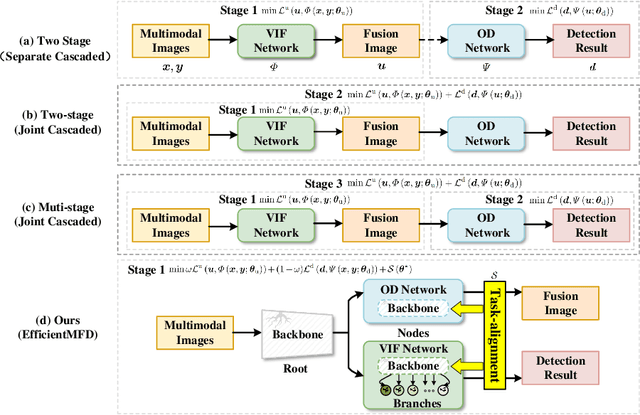
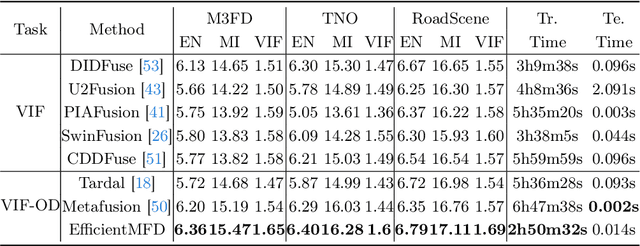
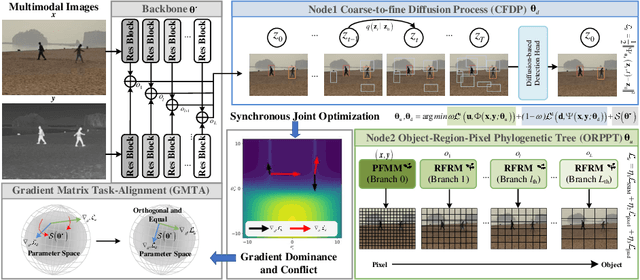

Multimodal image fusion and object detection play a vital role in autonomous driving. Current joint learning methods have made significant progress in the multimodal fusion detection task combining the texture detail and objective semantic information. However, the tedious training steps have limited its applications to wider real-world industrial deployment. To address this limitation, we propose a novel end-to-end multimodal fusion detection algorithm, named EfficientMFD, to simplify models that exhibit decent performance with only one training step. Synchronous joint optimization is utilized in an end-to-end manner between two components, thus not being affected by the local optimal solution of the individual task. Besides, a comprehensive optimization is established in the gradient matrix between the shared parameters for both tasks. It can converge to an optimal point with fusion detection weights. We extensively test it on several public datasets, demonstrating superior performance on not only visually appealing fusion but also favorable detection performance (e.g., 6.6% mAP50:95) over other state-of-the-art approaches.
PeLK: Parameter-efficient Large Kernel ConvNets with Peripheral Convolution
Mar 16, 2024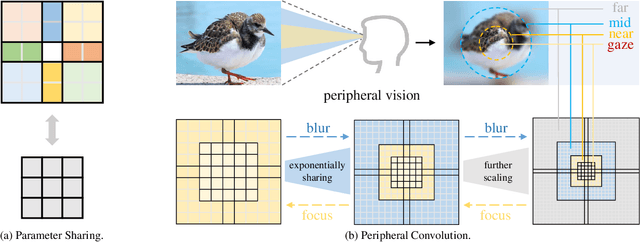

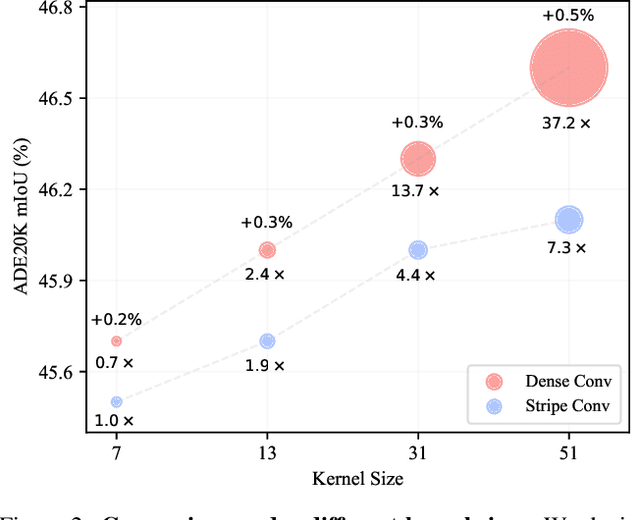
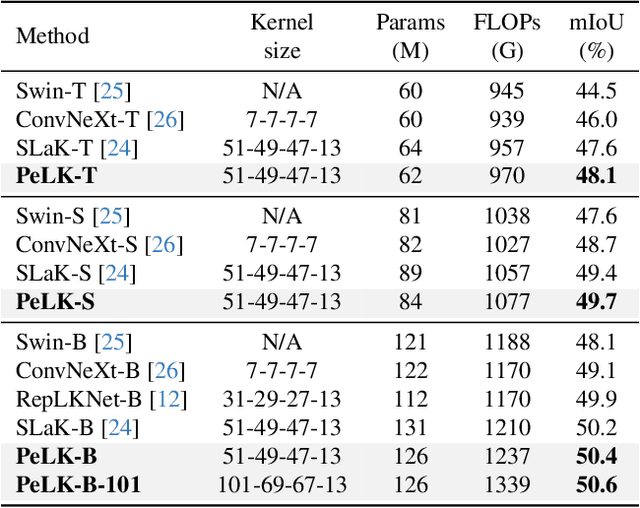
Recently, some large kernel convnets strike back with appealing performance and efficiency. However, given the square complexity of convolution, scaling up kernels can bring about an enormous amount of parameters and the proliferated parameters can induce severe optimization problem. Due to these issues, current CNNs compromise to scale up to 51x51 in the form of stripe convolution (i.e., 51x5 + 5x51) and start to saturate as the kernel size continues growing. In this paper, we delve into addressing these vital issues and explore whether we can continue scaling up kernels for more performance gains. Inspired by human vision, we propose a human-like peripheral convolution that efficiently reduces over 90% parameter count of dense grid convolution through parameter sharing, and manage to scale up kernel size to extremely large. Our peripheral convolution behaves highly similar to human, reducing the complexity of convolution from O(K^2) to O(logK) without backfiring performance. Built on this, we propose Parameter-efficient Large Kernel Network (PeLK). Our PeLK outperforms modern vision Transformers and ConvNet architectures like Swin, ConvNeXt, RepLKNet and SLaK on various vision tasks including ImageNet classification, semantic segmentation on ADE20K and object detection on MS COCO. For the first time, we successfully scale up the kernel size of CNNs to an unprecedented 101x101 and demonstrate consistent improvements.
Detection of Micromobility Vehicles in Urban Traffic Videos
Feb 28, 2024Urban traffic environments present unique challenges for object detection, particularly with the increasing presence of micromobility vehicles like e-scooters and bikes. To address this object detection problem, this work introduces an adapted detection model that combines the accuracy and speed of single-frame object detection with the richer features offered by video object detection frameworks. This is done by applying aggregated feature maps from consecutive frames processed through motion flow to the YOLOX architecture. This fusion brings a temporal perspective to YOLOX detection abilities, allowing for a better understanding of urban mobility patterns and substantially improving detection reliability. Tested on a custom dataset curated for urban micromobility scenarios, our model showcases substantial improvement over existing state-of-the-art methods, demonstrating the need to consider spatio-temporal information for detecting such small and thin objects. Our approach enhances detection in challenging conditions, including occlusions, ensuring temporal consistency, and effectively mitigating motion blur.
Transfer learning with generative models for object detection on limited datasets
Feb 09, 2024The availability of data is limited in some fields, especially for object detection tasks, where it is necessary to have correctly labeled bounding boxes around each object. A notable example of such data scarcity is found in the domain of marine biology, where it is useful to develop methods to automatically detect submarine species for environmental monitoring. To address this data limitation, the state-of-the-art machine learning strategies employ two main approaches. The first involves pretraining models on existing datasets before generalizing to the specific domain of interest. The second strategy is to create synthetic datasets specifically tailored to the target domain using methods like copy-paste techniques or ad-hoc simulators. The first strategy often faces a significant domain shift, while the second demands custom solutions crafted for the specific task. In response to these challenges, here we propose a transfer learning framework that is valid for a generic scenario. In this framework, generated images help to improve the performances of an object detector in a few-real data regime. This is achieved through a diffusion-based generative model that was pretrained on large generic datasets, and is not trained on the task-specific domain. We validate our approach on object detection tasks, specifically focusing on fishes in an underwater environment, and on the more common domain of cars in an urban setting. Our method achieves detection performance comparable to models trained on thousands of images, using only a few hundreds of input data. Our results pave the way for new generative AI-based protocols for machine learning applications in various domains, for instance ranging from geophysics to biology and medicine.
A Survey of Vision Transformers in Autonomous Driving: Current Trends and Future Directions
Mar 12, 2024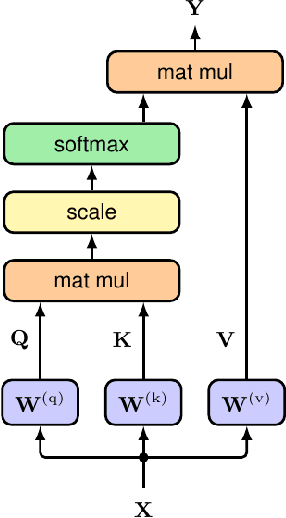
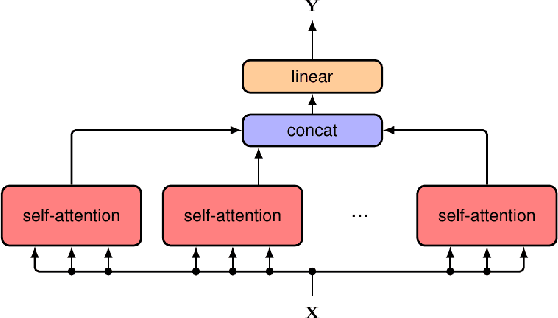
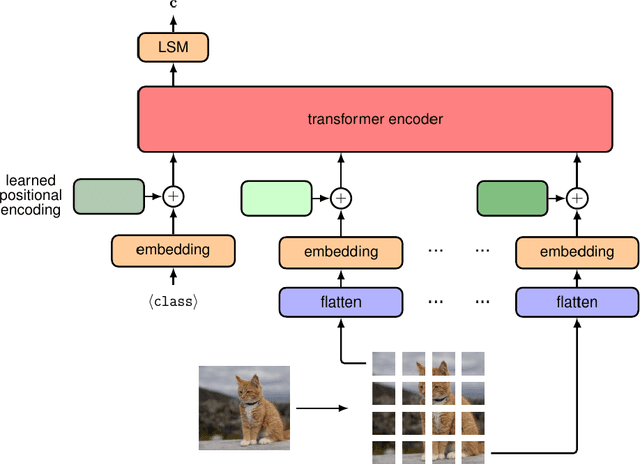
This survey explores the adaptation of visual transformer models in Autonomous Driving, a transition inspired by their success in Natural Language Processing. Surpassing traditional Recurrent Neural Networks in tasks like sequential image processing and outperforming Convolutional Neural Networks in global context capture, as evidenced in complex scene recognition, Transformers are gaining traction in computer vision. These capabilities are crucial in Autonomous Driving for real-time, dynamic visual scene processing. Our survey provides a comprehensive overview of Vision Transformer applications in Autonomous Driving, focusing on foundational concepts such as self-attention, multi-head attention, and encoder-decoder architecture. We cover applications in object detection, segmentation, pedestrian detection, lane detection, and more, comparing their architectural merits and limitations. The survey concludes with future research directions, highlighting the growing role of Vision Transformers in Autonomous Driving.
MTMMC: A Large-Scale Real-World Multi-Modal Camera Tracking Benchmark
Mar 29, 2024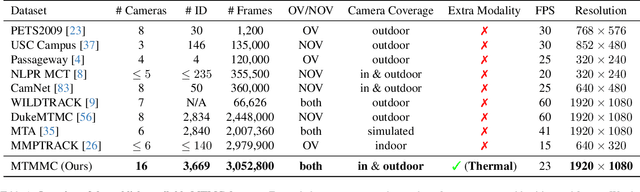
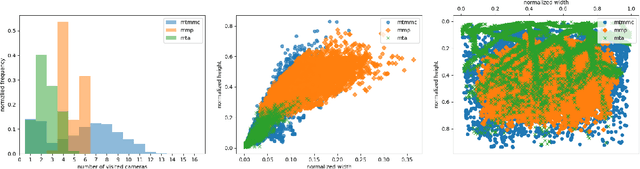

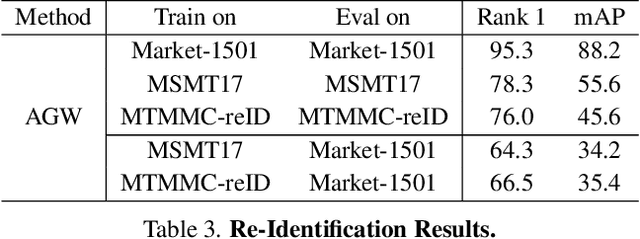
Multi-target multi-camera tracking is a crucial task that involves identifying and tracking individuals over time using video streams from multiple cameras. This task has practical applications in various fields, such as visual surveillance, crowd behavior analysis, and anomaly detection. However, due to the difficulty and cost of collecting and labeling data, existing datasets for this task are either synthetically generated or artificially constructed within a controlled camera network setting, which limits their ability to model real-world dynamics and generalize to diverse camera configurations. To address this issue, we present MTMMC, a real-world, large-scale dataset that includes long video sequences captured by 16 multi-modal cameras in two different environments - campus and factory - across various time, weather, and season conditions. This dataset provides a challenging test-bed for studying multi-camera tracking under diverse real-world complexities and includes an additional input modality of spatially aligned and temporally synchronized RGB and thermal cameras, which enhances the accuracy of multi-camera tracking. MTMMC is a super-set of existing datasets, benefiting independent fields such as person detection, re-identification, and multiple object tracking. We provide baselines and new learning setups on this dataset and set the reference scores for future studies. The datasets, models, and test server will be made publicly available.
Leveraging Self-Supervised Instance Contrastive Learning for Radar Object Detection
Feb 13, 2024In recent years, driven by the need for safer and more autonomous transport systems, the automotive industry has shifted toward integrating a growing number of Advanced Driver Assistance Systems (ADAS). Among the array of sensors employed for object recognition tasks, radar sensors have emerged as a formidable contender due to their abilities in adverse weather conditions or low-light scenarios and their robustness in maintaining consistent performance across diverse environments. However, the small size of radar datasets and the complexity of the labelling of those data limit the performance of radar object detectors. Driven by the promising results of self-supervised learning in computer vision, this paper presents RiCL, an instance contrastive learning framework to pre-train radar object detectors. We propose to exploit the detection from the radar and the temporal information to pre-train the radar object detection model in a self-supervised way using contrastive learning. We aim to pre-train an object detector's backbone, head and neck to learn with fewer data. Experiments on the CARRADA and the RADDet datasets show the effectiveness of our approach in learning generic representations of objects in range-Doppler maps. Notably, our pre-training strategy allows us to use only 20% of the labelled data to reach a similar mAP@0.5 than a supervised approach using the whole training set.
Fine-Grained Pillar Feature Encoding Via Spatio-Temporal Virtual Grid for 3D Object Detection
Mar 11, 2024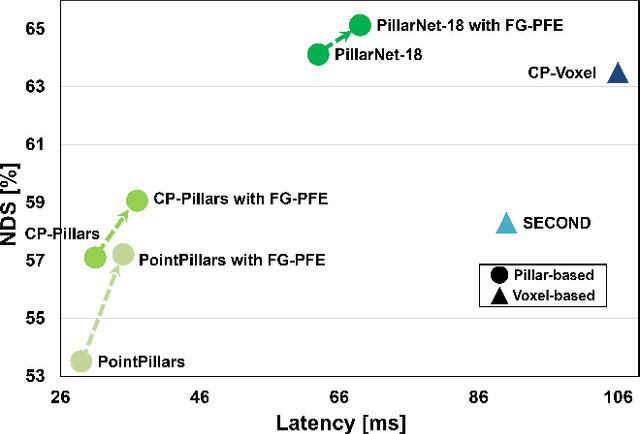
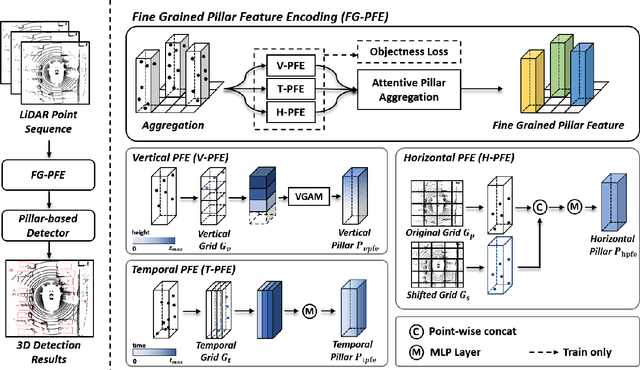
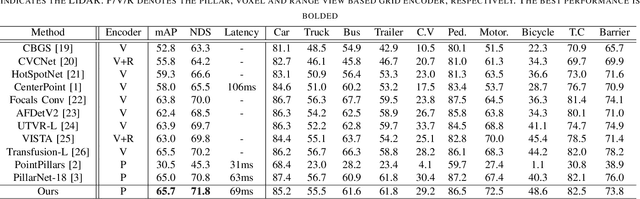
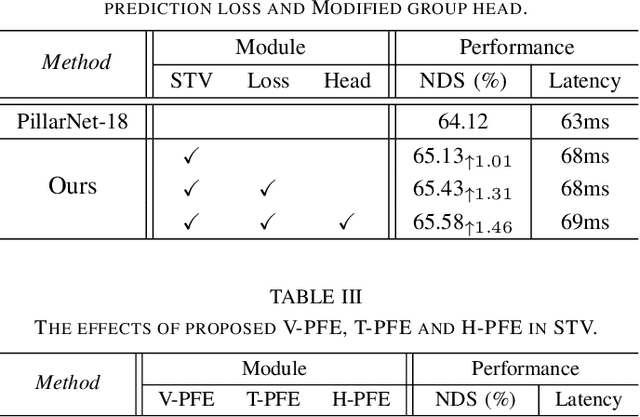
Developing high-performance, real-time architectures for LiDAR-based 3D object detectors is essential for the successful commercialization of autonomous vehicles. Pillar-based methods stand out as a practical choice for onboard deployment due to their computational efficiency. However, despite their efficiency, these methods can sometimes underperform compared to alternative point encoding techniques such as Voxel-encoding or PointNet++. We argue that current pillar-based methods have not sufficiently captured the fine-grained distributions of LiDAR points within each pillar structure. Consequently, there exists considerable room for improvement in pillar feature encoding. In this paper, we introduce a novel pillar encoding architecture referred to as Fine-Grained Pillar Feature Encoding (FG-PFE). FG-PFE utilizes Spatio-Temporal Virtual (STV) grids to capture the distribution of point clouds within each pillar across vertical, temporal, and horizontal dimensions. Through STV grids, points within each pillar are individually encoded using Vertical PFE (V-PFE), Temporal PFE (T-PFE), and Horizontal PFE (H-PFE). These encoded features are then aggregated through an Attentive Pillar Aggregation method. Our experiments conducted on the nuScenes dataset demonstrate that FG-PFE achieves significant performance improvements over baseline models such as PointPillar, CenterPoint-Pillar, and PillarNet, with only a minor increase in computational overhead.
Advanced Knowledge Extraction of Physical Design Drawings, Translation and conversion to CAD formats using Deep Learning
Mar 17, 2024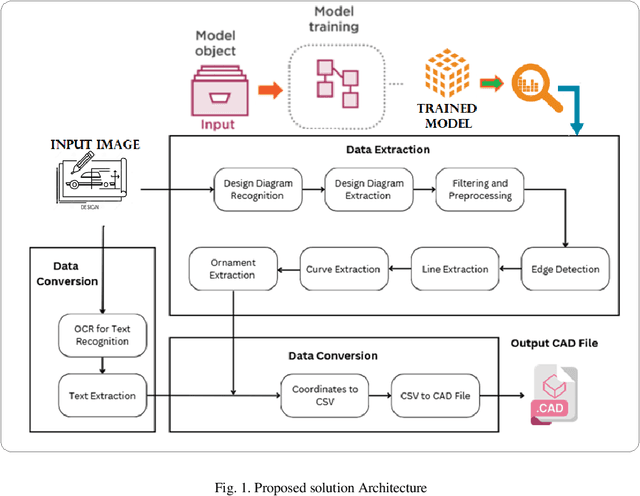
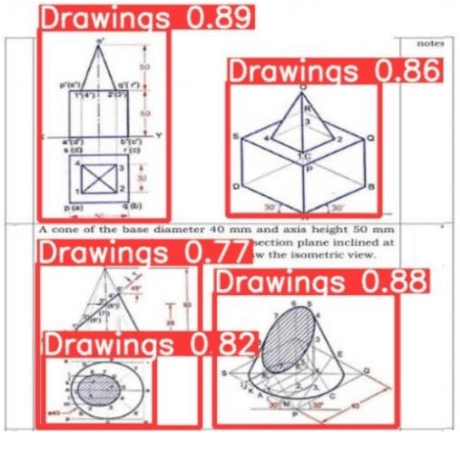
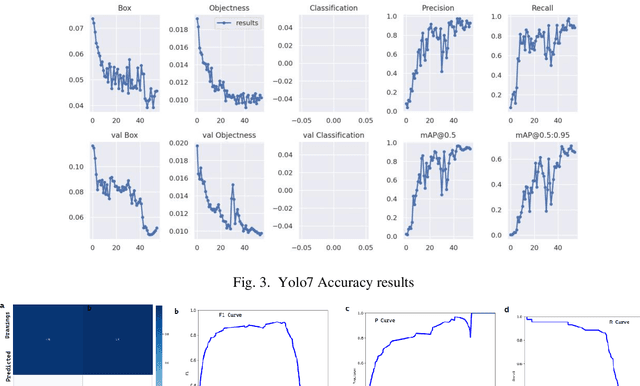
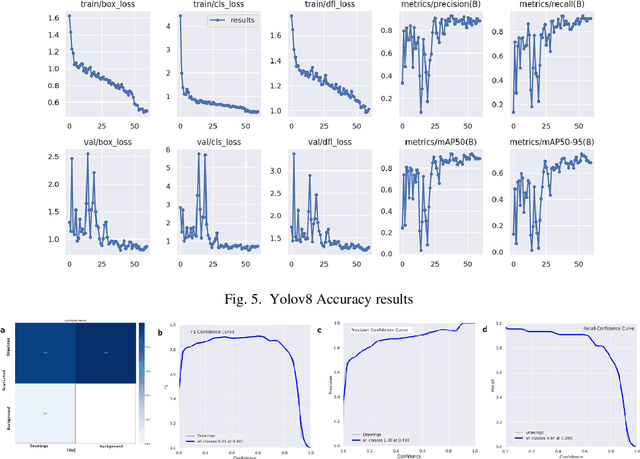
The maintenance, archiving and usage of the design drawings is cumbersome in physical form in different industries for longer period. It is hard to extract information by simple scanning of drawing sheets. Converting them to their digital formats such as Computer-Aided Design (CAD), with needed knowledge extraction can solve this problem. The conversion of these machine drawings to its digital form is a crucial challenge which requires advanced techniques. This research proposes an innovative methodology utilizing Deep Learning methods. The approach employs object detection model, such as Yolov7, Faster R-CNN, to detect physical drawing objects present in the images followed by, edge detection algorithms such as canny filter to extract and refine the identified lines from the drawing region and curve detection techniques to detect circle. Also ornaments (complex shapes) within the drawings are extracted. To ensure comprehensive conversion, an Optical Character Recognition (OCR) tool is integrated to identify and extract the text elements from the drawings. The extracted data which includes the lines, shapes and text is consolidated and stored in a structured comma separated values(.csv) file format. The accuracy and the efficiency of conversion is evaluated. Through this, conversion can be automated to help organizations enhance their productivity, facilitate seamless collaborations and preserve valuable design information in a digital format easily accessible. Overall, this study contributes to the advancement of CAD conversions, providing accurate results from the translating process. Future research can focus on handling diverse drawing types, enhanced accuracy in shape and line detection and extraction.