 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Poly Kernel Inception Network for Remote Sensing Detection
Mar 20, 2024
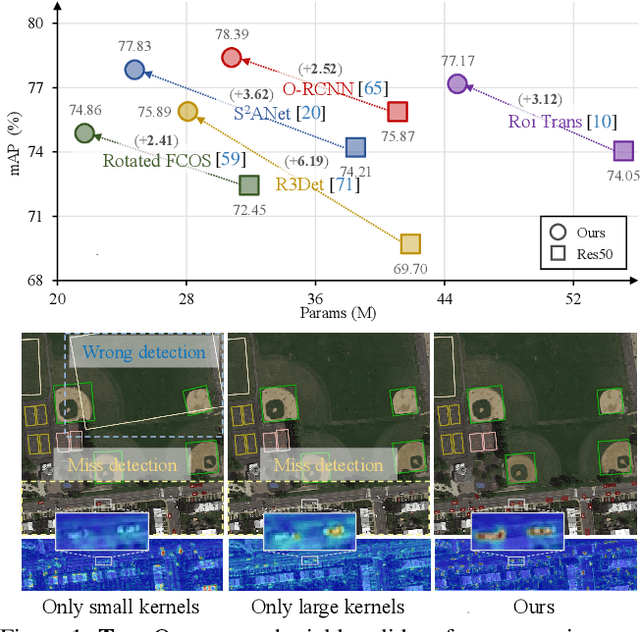
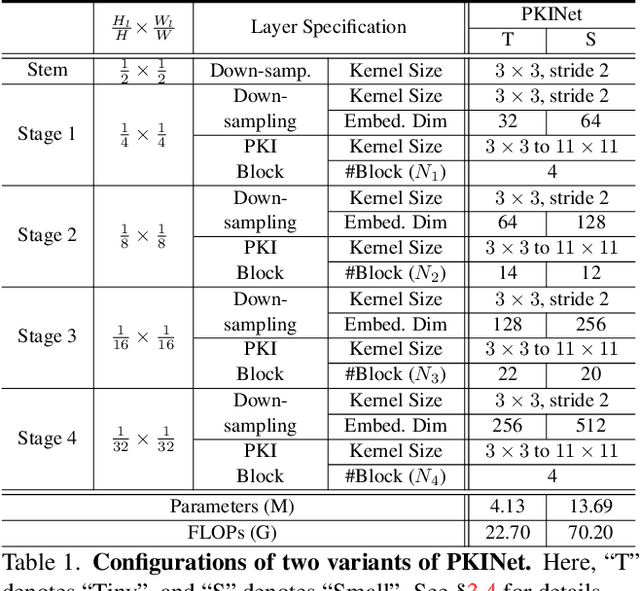
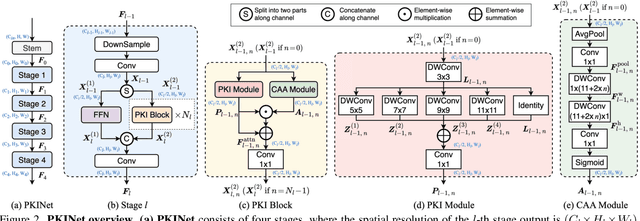
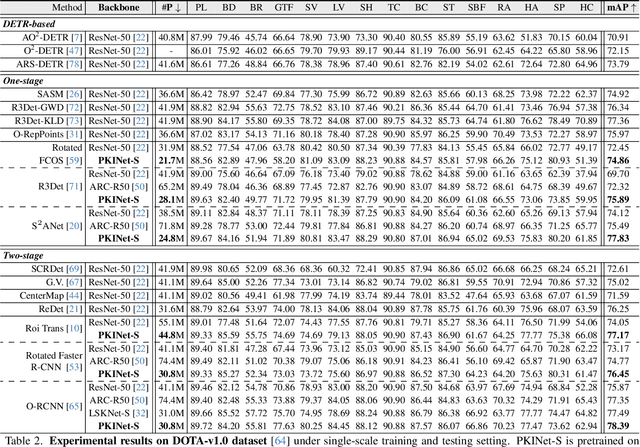
Object detection in remote sensing images (RSIs) often suffers from several increasing challenges, including the large variation in object scales and the diverse-ranging context. Prior methods tried to address these challenges by expanding the spatial receptive field of the backbone, either through large-kernel convolution or dilated convolution. However, the former typically introduces considerable background noise, while the latter risks generating overly sparse feature representations. In this paper, we introduce the Poly Kernel Inception Network (PKINet) to handle the above challenges. PKINet employs multi-scale convolution kernels without dilation to extract object features of varying scales and capture local context. In addition, a Context Anchor Attention (CAA) module is introduced in parallel to capture long-range contextual information. These two components work jointly to advance the performance of PKINet on four challenging remote sensing detection benchmarks, namely DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R.
EC-IoU: Orienting Safety for Object Detectors via Ego-Centric Intersection-over-Union
Mar 20, 2024This paper presents safety-oriented object detection via a novel Ego-Centric Intersection-over-Union (EC-IoU) measure, addressing practical concerns when applying state-of-the-art learning-based perception models in safety-critical domains such as autonomous driving. Concretely, we propose a weighting mechanism to refine the widely used IoU measure, allowing it to assign a higher score to a prediction that covers closer points of a ground-truth object from the ego agent's perspective. The proposed EC-IoU measure can be used in typical evaluation processes to select object detectors with higher safety-related performance for downstream tasks. It can also be integrated into common loss functions for model fine-tuning. While geared towards safety, our experiment with the KITTI dataset demonstrates the performance of a model trained on EC-IoU can be better than that of a variant trained on IoU in terms of mean Average Precision as well.
Entity6K: A Large Open-Domain Evaluation Dataset for Real-World Entity Recognition
Mar 19, 2024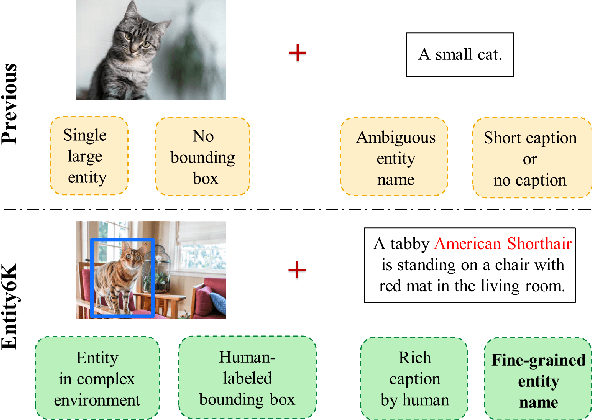

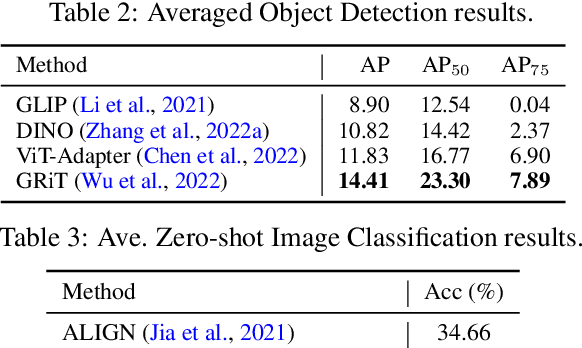
Open-domain real-world entity recognition is essential yet challenging, involving identifying various entities in diverse environments. The lack of a suitable evaluation dataset has been a major obstacle in this field due to the vast number of entities and the extensive human effort required for data curation. We introduce Entity6K, a comprehensive dataset for real-world entity recognition, featuring 5,700 entities across 26 categories, each supported by 5 human-verified images with annotations. Entity6K offers a diverse range of entity names and categorizations, addressing a gap in existing datasets. We conducted benchmarks with existing models on tasks like image captioning, object detection, zero-shot classification, and dense captioning to demonstrate Entity6K's effectiveness in evaluating models' entity recognition capabilities. We believe Entity6K will be a valuable resource for advancing accurate entity recognition in open-domain settings.
CR3DT: Camera-RADAR Fusion for 3D Detection and Tracking
Mar 22, 2024Accurate detection and tracking of surrounding objects is essential to enable self-driving vehicles. While Light Detection and Ranging (LiDAR) sensors have set the benchmark for high performance, the appeal of camera-only solutions lies in their cost-effectiveness. Notably, despite the prevalent use of Radio Detection and Ranging (RADAR) sensors in automotive systems, their potential in 3D detection and tracking has been largely disregarded due to data sparsity and measurement noise. As a recent development, the combination of RADARs and cameras is emerging as a promising solution. This paper presents Camera-RADAR 3D Detection and Tracking (CR3DT), a camera-RADAR fusion model for 3D object detection, and Multi-Object Tracking (MOT). Building upon the foundations of the State-of-the-Art (SotA) camera-only BEVDet architecture, CR3DT demonstrates substantial improvements in both detection and tracking capabilities, by incorporating the spatial and velocity information of the RADAR sensor. Experimental results demonstrate an absolute improvement in detection performance of 5.3% in mean Average Precision (mAP) and a 14.9% increase in Average Multi-Object Tracking Accuracy (AMOTA) on the nuScenes dataset when leveraging both modalities. CR3DT bridges the gap between high-performance and cost-effective perception systems in autonomous driving, by capitalizing on the ubiquitous presence of RADAR in automotive applications.
Wildfire danger prediction optimization with transfer learning
Mar 19, 2024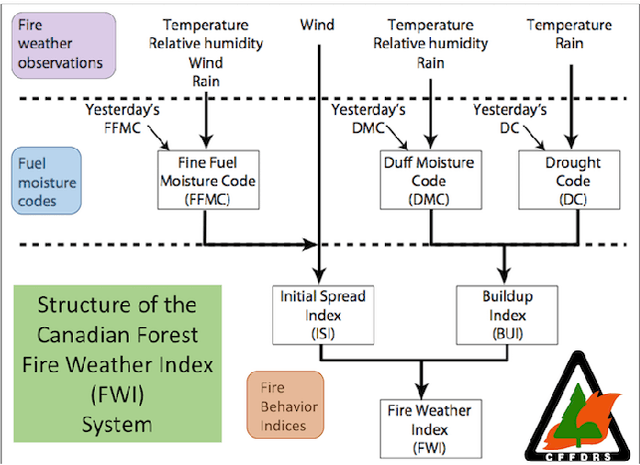
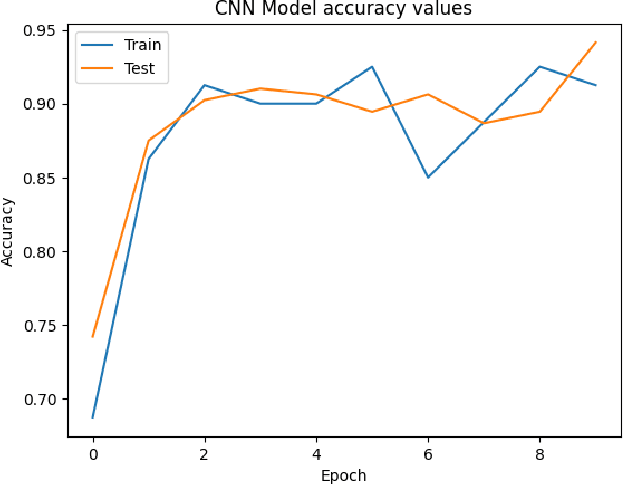
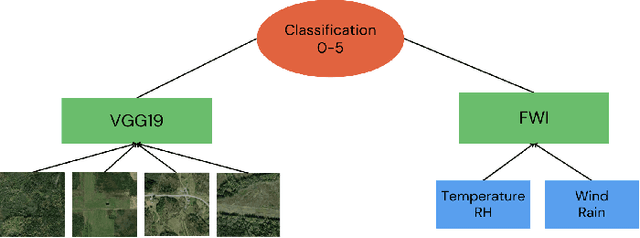

Convolutional Neural Networks (CNNs) have proven instrumental across various computer science domains, enabling advancements in object detection, classification, and anomaly detection. This paper explores the application of CNNs to analyze geospatial data specifically for identifying wildfire-affected areas. Leveraging transfer learning techniques, we fine-tuned CNN hyperparameters and integrated the Canadian Fire Weather Index (FWI) to assess moisture conditions. The study establishes a methodology for computing wildfire risk levels on a scale of 0 to 5, dynamically linked to weather patterns. Notably, through the integration of transfer learning, the CNN model achieved an impressive accuracy of 95\% in identifying burnt areas. This research sheds light on the inner workings of CNNs and their practical, real-time utility in predicting and mitigating wildfires. By combining transfer learning and CNNs, this study contributes a robust approach to assess burnt areas, facilitating timely interventions and preventative measures against conflagrations.
HASSOD: Hierarchical Adaptive Self-Supervised Object Detection
Feb 05, 2024The human visual perception system demonstrates exceptional capabilities in learning without explicit supervision and understanding the part-to-whole composition of objects. Drawing inspiration from these two abilities, we propose Hierarchical Adaptive Self-Supervised Object Detection (HASSOD), a novel approach that learns to detect objects and understand their compositions without human supervision. HASSOD employs a hierarchical adaptive clustering strategy to group regions into object masks based on self-supervised visual representations, adaptively determining the number of objects per image. Furthermore, HASSOD identifies the hierarchical levels of objects in terms of composition, by analyzing coverage relations between masks and constructing tree structures. This additional self-supervised learning task leads to improved detection performance and enhanced interpretability. Lastly, we abandon the inefficient multi-round self-training process utilized in prior methods and instead adapt the Mean Teacher framework from semi-supervised learning, which leads to a smoother and more efficient training process. Through extensive experiments on prevalent image datasets, we demonstrate the superiority of HASSOD over existing methods, thereby advancing the state of the art in self-supervised object detection. Notably, we improve Mask AR from 20.2 to 22.5 on LVIS, and from 17.0 to 26.0 on SA-1B. Project page: https://HASSOD-NeurIPS23.github.io.
Improving Object Detection Quality in Football Through Super-Resolution Techniques
Jan 31, 2024This study explores the potential of super-resolution techniques in enhancing object detection accuracy in football. Given the sport's fast-paced nature and the critical importance of precise object (e.g. ball, player) tracking for both analysis and broadcasting, super-resolution could offer significant improvements. We investigate how advanced image processing through super-resolution impacts the accuracy and reliability of object detection algorithms in processing football match footage. Our methodology involved applying state-of-the-art super-resolution techniques to a diverse set of football match videos from SoccerNet, followed by object detection using Faster R-CNN. The performance of these algorithms, both with and without super-resolution enhancement, was rigorously evaluated in terms of detection accuracy. The results indicate a marked improvement in object detection accuracy when super-resolution preprocessing is applied. The improvement of object detection through the integration of super-resolution techniques yields significant benefits, especially for low-resolution scenarios, with a notable 12\% increase in mean Average Precision (mAP) at an IoU (Intersection over Union) range of 0.50:0.95 for 320x240 size images when increasing the resolution fourfold using RLFN. As the dimensions increase, the magnitude of improvement becomes more subdued; however, a discernible improvement in the quality of detection is consistently evident. Additionally, we discuss the implications of these findings for real-time sports analytics, player tracking, and the overall viewing experience. The study contributes to the growing field of sports technology by demonstrating the practical benefits and limitations of integrating super-resolution techniques in football analytics and broadcasting.
EMIFF: Enhanced Multi-scale Image Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Feb 23, 2024In autonomous driving, cooperative perception makes use of multi-view cameras from both vehicles and infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Currently, two major challenges persist in vehicle-infrastructure cooperative 3D (VIC3D) object detection: $1)$ inherent pose errors when fusing multi-view images, caused by time asynchrony across cameras; $2)$ information loss in transmission process resulted from limited communication bandwidth. To address these issues, we propose a novel camera-based 3D detection framework for VIC3D task, Enhanced Multi-scale Image Feature Fusion (EMIFF). To fully exploit holistic perspectives from both vehicles and infrastructure, we propose Multi-scale Cross Attention (MCA) and Camera-aware Channel Masking (CCM) modules to enhance infrastructure and vehicle features at scale, spatial, and channel levels to correct the pose error introduced by camera asynchrony. We also introduce a Feature Compression (FC) module with channel and spatial compression blocks for transmission efficiency. Experiments show that EMIFF achieves SOTA on DAIR-V2X-C datasets, significantly outperforming previous early-fusion and late-fusion methods with comparable transmission costs.
As Firm As Their Foundations: Can open-sourced foundation models be used to create adversarial examples for downstream tasks?
Mar 19, 2024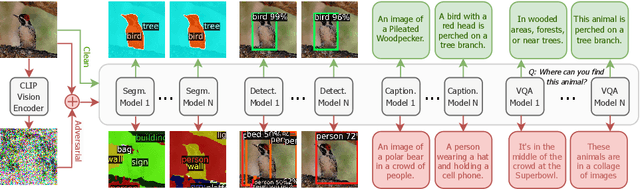
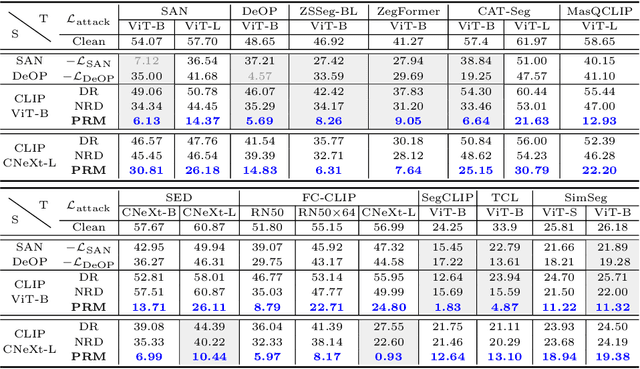
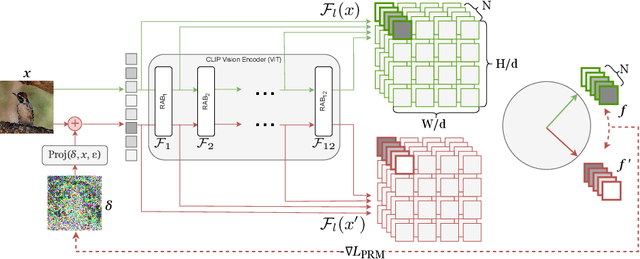
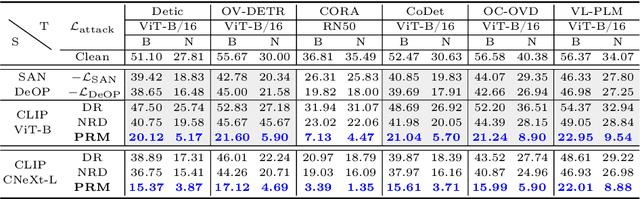
Foundation models pre-trained on web-scale vision-language data, such as CLIP, are widely used as cornerstones of powerful machine learning systems. While pre-training offers clear advantages for downstream learning, it also endows downstream models with shared adversarial vulnerabilities that can be easily identified through the open-sourced foundation model. In this work, we expose such vulnerabilities in CLIP's downstream models and show that foundation models can serve as a basis for attacking their downstream systems. In particular, we propose a simple yet effective adversarial attack strategy termed Patch Representation Misalignment (PRM). Solely based on open-sourced CLIP vision encoders, this method produces adversaries that simultaneously fool more than 20 downstream models spanning 4 common vision-language tasks (semantic segmentation, object detection, image captioning and visual question-answering). Our findings highlight the concerning safety risks introduced by the extensive usage of public foundational models in the development of downstream systems, calling for extra caution in these scenarios.
SceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
Mar 19, 2024

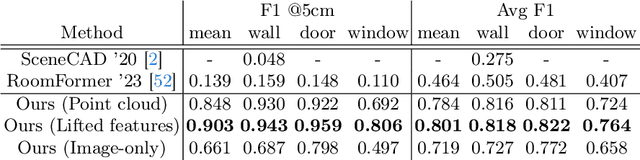
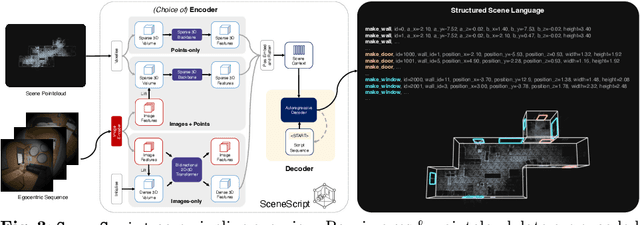
We introduce SceneScript, a method that directly produces full scene models as a sequence of structured language commands using an autoregressive, token-based approach. Our proposed scene representation is inspired by recent successes in transformers & LLMs, and departs from more traditional methods which commonly describe scenes as meshes, voxel grids, point clouds or radiance fields. Our method infers the set of structured language commands directly from encoded visual data using a scene language encoder-decoder architecture. To train SceneScript, we generate and release a large-scale synthetic dataset called Aria Synthetic Environments consisting of 100k high-quality in-door scenes, with photorealistic and ground-truth annotated renders of egocentric scene walkthroughs. Our method gives state-of-the art results in architectural layout estimation, and competitive results in 3D object detection. Lastly, we explore an advantage for SceneScript, which is the ability to readily adapt to new commands via simple additions to the structured language, which we illustrate for tasks such as coarse 3D object part reconstruction.