 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Ship in Sight: Diffusion Models for Ship-Image Super Resolution
Mar 27, 2024
In recent years, remarkable advancements have been achieved in the field of image generation, primarily driven by the escalating demand for high-quality outcomes across various image generation subtasks, such as inpainting, denoising, and super resolution. A major effort is devoted to exploring the application of super-resolution techniques to enhance the quality of low-resolution images. In this context, our method explores in depth the problem of ship image super resolution, which is crucial for coastal and port surveillance. We investigate the opportunity given by the growing interest in text-to-image diffusion models, taking advantage of the prior knowledge that such foundation models have already learned. In particular, we present a diffusion-model-based architecture that leverages text conditioning during training while being class-aware, to best preserve the crucial details of the ships during the generation of the super-resoluted image. Since the specificity of this task and the scarcity availability of off-the-shelf data, we also introduce a large labeled ship dataset scraped from online ship images, mostly from ShipSpotting\footnote{\url{www.shipspotting.com}} website. Our method achieves more robust results than other deep learning models previously employed for super resolution, as proven by the multiple experiments performed. Moreover, we investigate how this model can benefit downstream tasks, such as classification and object detection, thus emphasizing practical implementation in a real-world scenario. Experimental results show flexibility, reliability, and impressive performance of the proposed framework over state-of-the-art methods for different tasks. The code is available at: https://github.com/LuigiSigillo/ShipinSight .
Real-time Traffic Object Detection for Autonomous Driving
Jan 31, 2024With recent advances in computer vision, it appears that autonomous driving will be part of modern society sooner rather than later. However, there are still a significant number of concerns to address. Although modern computer vision techniques demonstrate superior performance, they tend to prioritize accuracy over efficiency, which is a crucial aspect of real-time applications. Large object detection models typically require higher computational power, which is achieved by using more sophisticated onboard hardware. For autonomous driving, these requirements translate to increased fuel costs and, ultimately, a reduction in mileage. Further, despite their computational demands, the existing object detectors are far from being real-time. In this research, we assess the robustness of our previously proposed, highly efficient pedestrian detector LSFM on well-established autonomous driving benchmarks, including diverse weather conditions and nighttime scenes. Moreover, we extend our LSFM model for general object detection to achieve real-time object detection in traffic scenes. We evaluate its performance, low latency, and generalizability on traffic object detection datasets. Furthermore, we discuss the inadequacy of the current key performance indicator employed by object detection systems in the context of autonomous driving and propose a more suitable alternative that incorporates real-time requirements.
DEYO: DETR with YOLO for End-to-End Object Detection
Feb 26, 2024The training paradigm of DETRs is heavily contingent upon pre-training their backbone on the ImageNet dataset. However, the limited supervisory signals provided by the image classification task and one-to-one matching strategy result in an inadequately pre-trained neck for DETRs. Additionally, the instability of matching in the early stages of training engenders inconsistencies in the optimization objectives of DETRs. To address these issues, we have devised an innovative training methodology termed step-by-step training. Specifically, in the first stage of training, we employ a classic detector, pre-trained with a one-to-many matching strategy, to initialize the backbone and neck of the end-to-end detector. In the second stage of training, we froze the backbone and neck of the end-to-end detector, necessitating the training of the decoder from scratch. Through the application of step-by-step training, we have introduced the first real-time end-to-end object detection model that utilizes a purely convolutional structure encoder, DETR with YOLO (DEYO). Without reliance on any supplementary training data, DEYO surpasses all existing real-time object detectors in both speed and accuracy. Moreover, the comprehensive DEYO series can complete its second-phase training on the COCO dataset using a single 8GB RTX 4060 GPU, significantly reducing the training expenditure. Source code and pre-trained models are available at https://github.com/ouyanghaodong/DEYO.
Impact of Video Compression Artifacts on Fisheye Camera Visual Perception Tasks
Mar 25, 2024Autonomous driving systems require extensive data collection schemes to cover the diverse scenarios needed for building a robust and safe system. The data volumes are in the order of Exabytes and have to be stored for a long period of time (i.e., more than 10 years of the vehicle's life cycle). Lossless compression doesn't provide sufficient compression ratios, hence, lossy video compression has been explored. It is essential to prove that lossy video compression artifacts do not impact the performance of the perception algorithms. However, there is limited work in this area to provide a solid conclusion. In particular, there is no such work for fisheye cameras, which have high radial distortion and where compression may have higher artifacts. Fisheye cameras are commonly used in automotive systems for 3D object detection task. In this work, we provide the first analysis of the impact of standard video compression codecs on wide FOV fisheye camera images. We demonstrate that the achievable compression with negligible impact depends on the dataset and temporal prediction of the video codec. We propose a radial distortion-aware zonal metric to evaluate the performance of artifacts in fisheye images. In addition, we present a novel method for estimating affine mode parameters of the latest VVC codec, and suggest some areas for improvement in video codecs for the application to fisheye imagery.
UAV-Assisted Maritime Search and Rescue: A Holistic Approach
Mar 21, 2024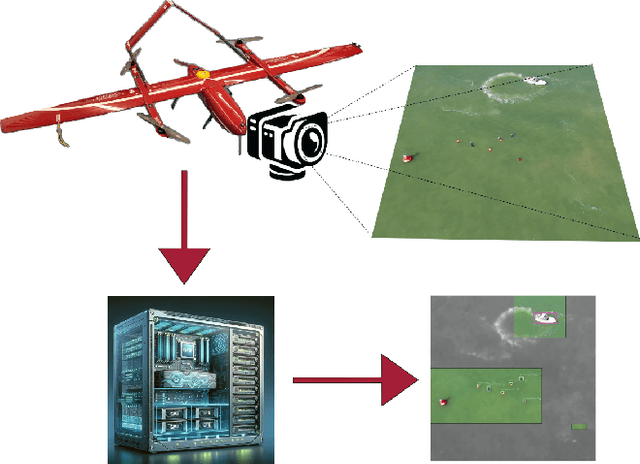



In this paper, we explore the application of Unmanned Aerial Vehicles (UAVs) in maritime search and rescue (mSAR) missions, focusing on medium-sized fixed-wing drones and quadcopters. We address the challenges and limitations inherent in operating some of the different classes of UAVs, particularly in search operations. Our research includes the development of a comprehensive software framework designed to enhance the efficiency and efficacy of SAR operations. This framework combines preliminary detection onboard UAVs with advanced object detection at ground stations, aiming to reduce visual strain and improve decision-making for operators. It will be made publicly available upon publication. We conduct experiments to evaluate various Region of Interest (RoI) proposal methods, especially by imposing simulated limited bandwidth on them, an important consideration when flying remote or offshore operations. This forces the algorithm to prioritize some predictions over others.
SparseFusion: Efficient Sparse Multi-Modal Fusion Framework for Long-Range 3D Perception
Mar 15, 2024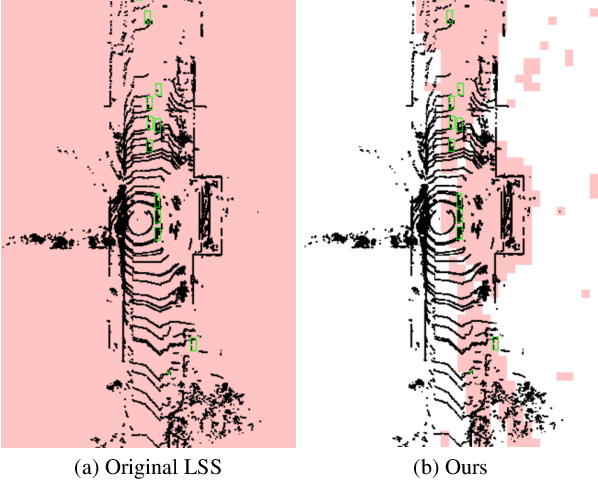

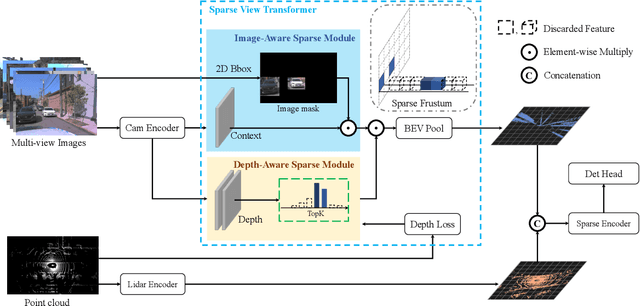
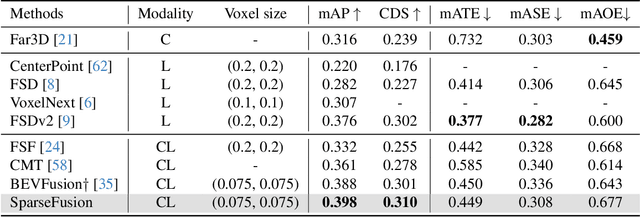
Multi-modal 3D object detection has exhibited significant progress in recent years. However, most existing methods can hardly scale to long-range scenarios due to their reliance on dense 3D features, which substantially escalate computational demands and memory usage. In this paper, we introduce SparseFusion, a novel multi-modal fusion framework fully built upon sparse 3D features to facilitate efficient long-range perception. The core of our method is the Sparse View Transformer module, which selectively lifts regions of interest in 2D image space into the unified 3D space. The proposed module introduces sparsity from both semantic and geometric aspects which only fill grids that foreground objects potentially reside in. Comprehensive experiments have verified the efficiency and effectiveness of our framework in long-range 3D perception. Remarkably, on the long-range Argoverse2 dataset, SparseFusion reduces memory footprint and accelerates the inference by about two times compared to dense detectors. It also achieves state-of-the-art performance with mAP of 41.2% and CDS of 32.1%. The versatility of SparseFusion is also validated in the temporal object detection task and 3D lane detection task. Codes will be released upon acceptance.
Isolated Diffusion: Optimizing Multi-Concept Text-to-Image Generation Training-Freely with Isolated Diffusion Guidance
Mar 25, 2024Large-scale text-to-image diffusion models have achieved great success in synthesizing high-quality and diverse images given target text prompts. Despite the revolutionary image generation ability, current state-of-the-art models still struggle to deal with multi-concept generation accurately in many cases. This phenomenon is known as ``concept bleeding" and displays as the unexpected overlapping or merging of various concepts. This paper presents a general approach for text-to-image diffusion models to address the mutual interference between different subjects and their attachments in complex scenes, pursuing better text-image consistency. The core idea is to isolate the synthesizing processes of different concepts. We propose to bind each attachment to corresponding subjects separately with split text prompts. Besides, we introduce a revision method to fix the concept bleeding problem in multi-subject synthesis. We first depend on pre-trained object detection and segmentation models to obtain the layouts of subjects. Then we isolate and resynthesize each subject individually with corresponding text prompts to avoid mutual interference. Overall, we achieve a training-free strategy, named Isolated Diffusion, to optimize multi-concept text-to-image synthesis. It is compatible with the latest Stable Diffusion XL (SDXL) and prior Stable Diffusion (SD) models. We compare our approach with alternative methods using a variety of multi-concept text prompts and demonstrate its effectiveness with clear advantages in text-image consistency and user study.
Deep Active Learning: A Reality Check
Mar 21, 2024We conduct a comprehensive evaluation of state-of-the-art deep active learning methods. Surprisingly, under general settings, no single-model method decisively outperforms entropy-based active learning, and some even fall short of random sampling. We delve into overlooked aspects like starting budget, budget step, and pretraining's impact, revealing their significance in achieving superior results. Additionally, we extend our evaluation to other tasks, exploring the active learning effectiveness in combination with semi-supervised learning, and object detection. Our experiments provide valuable insights and concrete recommendations for future active learning studies. By uncovering the limitations of current methods and understanding the impact of different experimental settings, we aim to inspire more efficient training of deep learning models in real-world scenarios with limited annotation budgets. This work contributes to advancing active learning's efficacy in deep learning and empowers researchers to make informed decisions when applying active learning to their tasks.
EcoSense: Energy-Efficient Intelligent Sensing for In-Shore Ship Detection through Edge-Cloud Collaboration
Mar 20, 2024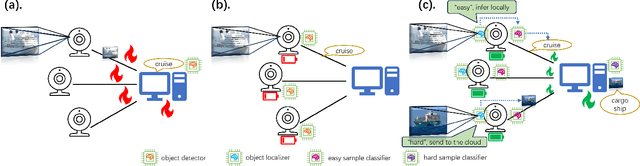

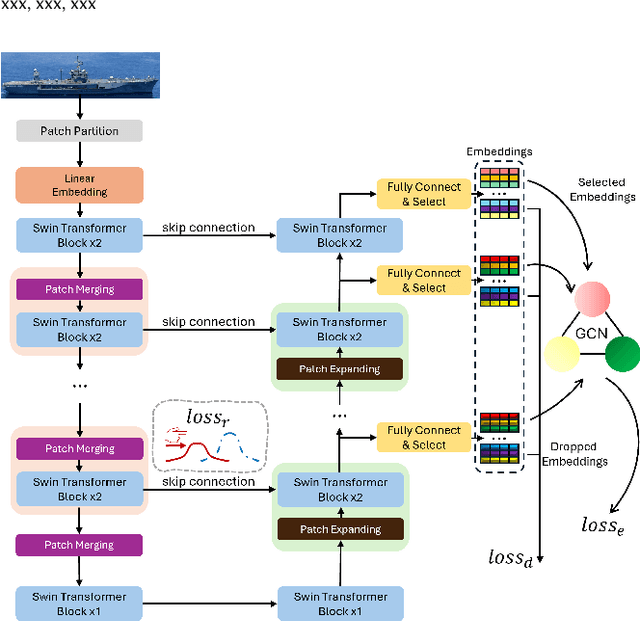
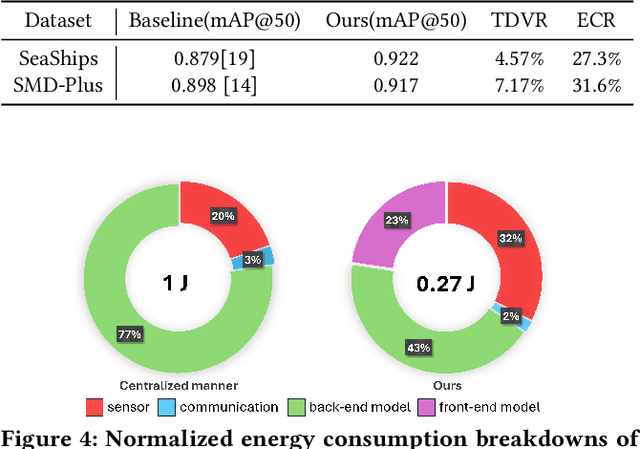
Detecting marine objects inshore presents challenges owing to algorithmic intricacies and complexities in system deployment. We propose a difficulty-aware edge-cloud collaborative sensing system that splits the task into object localization and fine-grained classification. Objects are classified either at the edge or within the cloud, based on their estimated difficulty. The framework comprises a low-power device-tailored front-end model for object localization, classification, and difficulty estimation, along with a transformer-graph convolutional network-based back-end model for fine-grained classification. Our system demonstrates superior performance (mAP@0.5 +4.3%}) on widely used marine object detection datasets, significantly reducing both data transmission volume (by 95.43%) and energy consumption (by 72.7%}) at the system level. We validate the proposed system across various embedded system platforms and in real-world scenarios involving drone deployment.
Improving Detection in Aerial Images by Capturing Inter-Object Relationships
Apr 05, 2024In many image domains, the spatial distribution of objects in a scene exhibits meaningful patterns governed by their semantic relationships. In most modern detection pipelines, however, the detection proposals are processed independently, overlooking the underlying relationships between objects. In this work, we introduce a transformer-based approach to capture these inter-object relationships to refine classification and regression outcomes for detected objects. Building on two-stage detectors, we tokenize the region of interest (RoI) proposals to be processed by a transformer encoder. Specific spatial and geometric relations are incorporated into the attention weights and adaptively modulated and regularized. Experimental results demonstrate that the proposed method achieves consistent performance improvement on three benchmarks including DOTA-v1.0, DOTA-v1.5, and HRSC 2016, especially ranking first on both DOTA-v1.5 and HRSC 2016. Specifically, our new method has an increase of 1.59 mAP on DOTA-v1.0, 4.88 mAP on DOTA-v1.5, and 2.1 mAP on HRSC 2016, respectively, compared to the baselines.