 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
InstaGen: Enhancing Object Detection by Training on Synthetic Dataset
Feb 20, 2024
In this paper, we introduce a novel paradigm to enhance the ability of object detector, e.g., expanding categories or improving detection performance, by training on synthetic dataset generated from diffusion models. Specifically, we integrate an instance-level grounding head into a pre-trained, generative diffusion model, to augment it with the ability of localising arbitrary instances in the generated images. The grounding head is trained to align the text embedding of category names with the regional visual feature of the diffusion model, using supervision from an off-the-shelf object detector, and a novel self-training scheme on (novel) categories not covered by the detector. This enhanced version of diffusion model, termed as InstaGen, can serve as a data synthesizer for object detection. We conduct thorough experiments to show that, object detector can be enhanced while training on the synthetic dataset from InstaGen, demonstrating superior performance over existing state-of-the-art methods in open-vocabulary (+4.5 AP) and data-sparse (+1.2 to 5.2 AP) scenarios.
MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection
Mar 29, 2024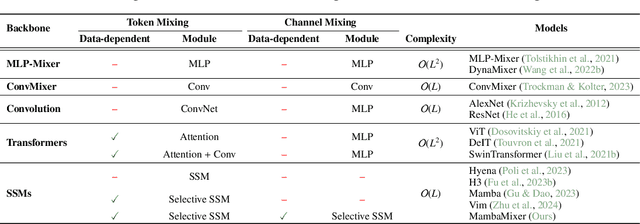
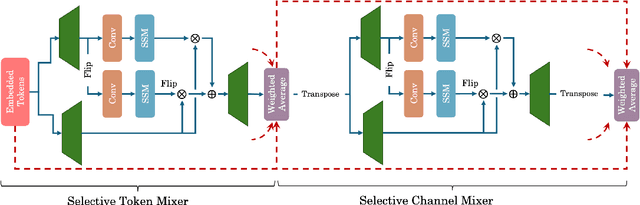
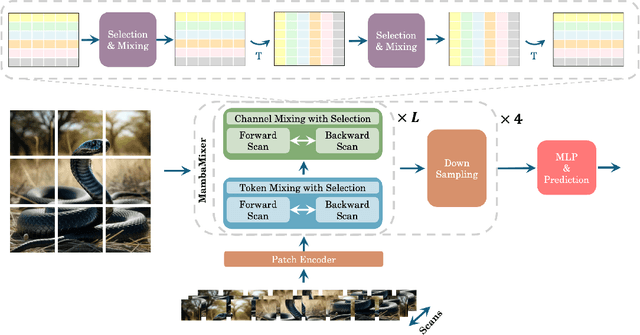
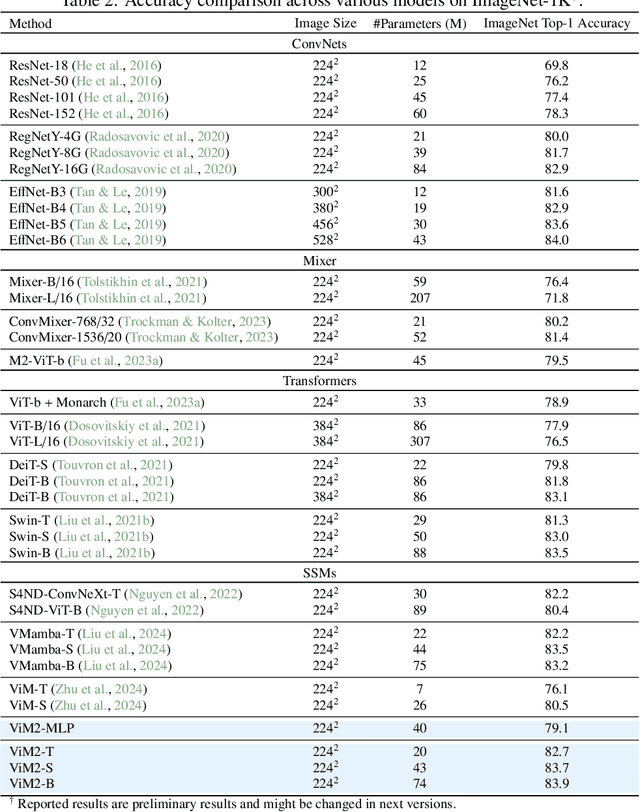
Recent advances in deep learning have mainly relied on Transformers due to their data dependency and ability to learn at scale. The attention module in these architectures, however, exhibits quadratic time and space in input size, limiting their scalability for long-sequence modeling. Despite recent attempts to design efficient and effective architecture backbone for multi-dimensional data, such as images and multivariate time series, existing models are either data independent, or fail to allow inter- and intra-dimension communication. Recently, State Space Models (SSMs), and more specifically Selective State Space Models, with efficient hardware-aware implementation, have shown promising potential for long sequence modeling. Motivated by the success of SSMs, we present MambaMixer, a new architecture with data-dependent weights that uses a dual selection mechanism across tokens and channels, called Selective Token and Channel Mixer. MambaMixer connects selective mixers using a weighted averaging mechanism, allowing layers to have direct access to early features. As a proof of concept, we design Vision MambaMixer (ViM2) and Time Series MambaMixer (TSM2) architectures based on the MambaMixer block and explore their performance in various vision and time series forecasting tasks. Our results underline the importance of selective mixing across both tokens and channels. In ImageNet classification, object detection, and semantic segmentation tasks, ViM2 achieves competitive performance with well-established vision models and outperforms SSM-based vision models. In time series forecasting, TSM2 achieves outstanding performance compared to state-of-the-art methods while demonstrating significantly improved computational cost. These results show that while Transformers, cross-channel attention, and MLPs are sufficient for good performance in time series forecasting, neither is necessary.
LSKNet: A Foundation Lightweight Backbone for Remote Sensing
Mar 18, 2024
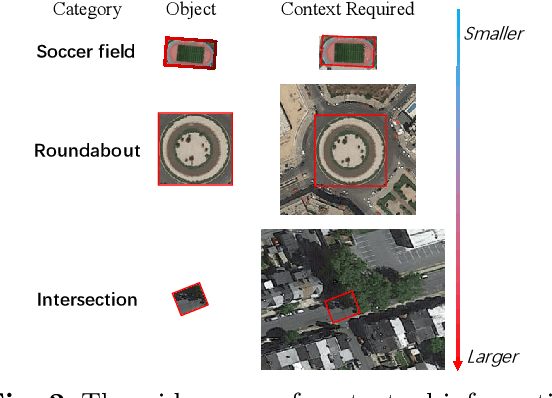
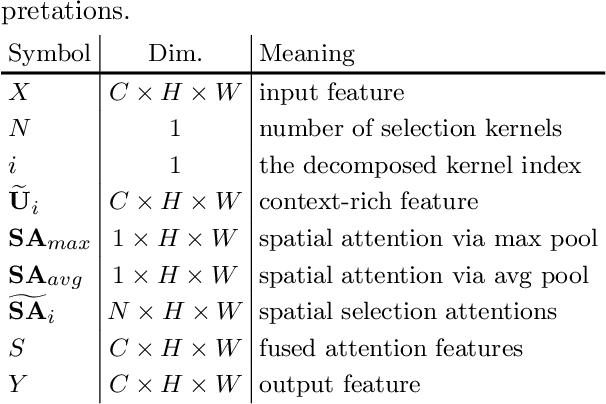
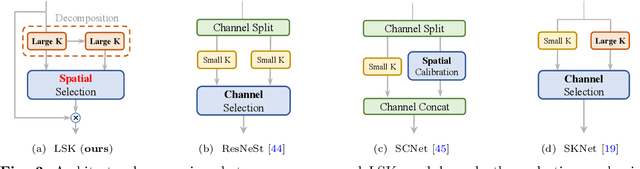
Remote sensing images pose distinct challenges for downstream tasks due to their inherent complexity. While a considerable amount of research has been dedicated to remote sensing classification, object detection and semantic segmentation, most of these studies have overlooked the valuable prior knowledge embedded within remote sensing scenarios. Such prior knowledge can be useful because remote sensing objects may be mistakenly recognized without referencing a sufficiently long-range context, which can vary for different objects. This paper considers these priors and proposes a lightweight Large Selective Kernel Network (LSKNet) backbone. LSKNet can dynamically adjust its large spatial receptive field to better model the ranging context of various objects in remote sensing scenarios. To our knowledge, large and selective kernel mechanisms have not been previously explored in remote sensing images. Without bells and whistles, our lightweight LSKNet sets new state-of-the-art scores on standard remote sensing classification, object detection and semantic segmentation benchmarks. Our comprehensive analysis further validated the significance of the identified priors and the effectiveness of LSKNet. The code is available at https://github.com/zcablii/LSKNet.
The Solution for the CVPR 2023 1st foundation model challenge-Track2
Mar 26, 2024In this paper, we propose a solution for cross-modal transportation retrieval. Due to the cross-domain problem of traffic images, we divide the problem into two sub-tasks of pedestrian retrieval and vehicle retrieval through a simple strategy. In pedestrian retrieval tasks, we use IRRA as the base model and specifically design an Attribute Classification to mine the knowledge implied by attribute labels. More importantly, We use the strategy of Inclusion Relation Matching to make the image-text pairs with inclusion relation have similar representation in the feature space. For the vehicle retrieval task, we use BLIP as the base model. Since aligning the color attributes of vehicles is challenging, we introduce attribute-based object detection techniques to add color patch blocks to vehicle images for color data augmentation. This serves as strong prior information, helping the model perform the image-text alignment. At the same time, we incorporate labeled attributes into the image-text alignment loss to learn fine-grained alignment and prevent similar images and texts from being incorrectly separated. Our approach ranked first in the final B-board test with a score of 70.9.
Staircase Localization for Autonomous Exploration in Urban Environments
Mar 26, 2024A staircase localization method is proposed for robots to explore urban environments autonomously. The proposed method employs a modular design in the form of a cascade pipeline consisting of three modules of stair detection, line segment detection, and stair localization modules. The stair detection module utilizes an object detection algorithm based on deep learning to generate a region of interest (ROI). From the ROI, line segment features are extracted using a deep line segment detection algorithm. The extracted line segments are used to localize a staircase in terms of position, orientation, and stair direction. The stair detection and localization are performed only with a single RGB-D camera. Each component of the proposed pipeline does not need to be designed particularly for staircases, which makes it easy to maintain the whole pipeline and replace each component with state-of-the-art deep learning detection techniques. The results of real-world experiments show that the proposed method can perform accurate stair detection and localization during autonomous exploration for various structured and unstructured upstairs and downstairs with shadows, dirt, and occlusions by artificial and natural objects.
CosalPure: Learning Concept from Group Images for Robust Co-Saliency Detection
Mar 27, 2024Co-salient object detection (CoSOD) aims to identify the common and salient (usually in the foreground) regions across a given group of images. Although achieving significant progress, state-of-the-art CoSODs could be easily affected by some adversarial perturbations, leading to substantial accuracy reduction. The adversarial perturbations can mislead CoSODs but do not change the high-level semantic information (e.g., concept) of the co-salient objects. In this paper, we propose a novel robustness enhancement framework by first learning the concept of the co-salient objects based on the input group images and then leveraging this concept to purify adversarial perturbations, which are subsequently fed to CoSODs for robustness enhancement. Specifically, we propose CosalPure containing two modules, i.e., group-image concept learning and concept-guided diffusion purification. For the first module, we adopt a pre-trained text-to-image diffusion model to learn the concept of co-salient objects within group images where the learned concept is robust to adversarial examples. For the second module, we map the adversarial image to the latent space and then perform diffusion generation by embedding the learned concept into the noise prediction function as an extra condition. Our method can effectively alleviate the influence of the SOTA adversarial attack containing different adversarial patterns, including exposure and noise. The extensive results demonstrate that our method could enhance the robustness of CoSODs significantly.
PhysicsAssistant: An LLM-Powered Interactive Learning Robot for Physics Lab Investigations
Mar 27, 2024Robot systems in education can leverage Large language models' (LLMs) natural language understanding capabilities to provide assistance and facilitate learning. This paper proposes a multimodal interactive robot (PhysicsAssistant) built on YOLOv8 object detection, cameras, speech recognition, and chatbot using LLM to provide assistance to students' physics labs. We conduct a user study on ten 8th-grade students to empirically evaluate the performance of PhysicsAssistant with a human expert. The Expert rates the assistants' responses to student queries on a 0-4 scale based on Bloom's taxonomy to provide educational support. We have compared the performance of PhysicsAssistant (YOLOv8+GPT-3.5-turbo) with GPT-4 and found that the human expert rating of both systems for factual understanding is the same. However, the rating of GPT-4 for conceptual and procedural knowledge (3 and 3.2 vs 2.2 and 2.6, respectively) is significantly higher than PhysicsAssistant (p < 0.05). However, the response time of GPT-4 is significantly higher than PhysicsAssistant (3.54 vs 1.64 sec, p < 0.05). Hence, despite the relatively lower response quality of PhysicsAssistant than GPT-4, it has shown potential for being used as a real-time lab assistant to provide timely responses and can offload teachers' labor to assist with repetitive tasks. To the best of our knowledge, this is the first attempt to build such an interactive multimodal robotic assistant for K-12 science (physics) education.
LiRaFusion: Deep Adaptive LiDAR-Radar Fusion for 3D Object Detection
Feb 18, 2024We propose LiRaFusion to tackle LiDAR-radar fusion for 3D object detection to fill the performance gap of existing LiDAR-radar detectors. To improve the feature extraction capabilities from these two modalities, we design an early fusion module for joint voxel feature encoding, and a middle fusion module to adaptively fuse feature maps via a gated network. We perform extensive evaluation on nuScenes to demonstrate that LiRaFusion leverages the complementary information of LiDAR and radar effectively and achieves notable improvement over existing methods.
GRA: Detecting Oriented Objects through Group-wise Rotating and Attention
Mar 19, 2024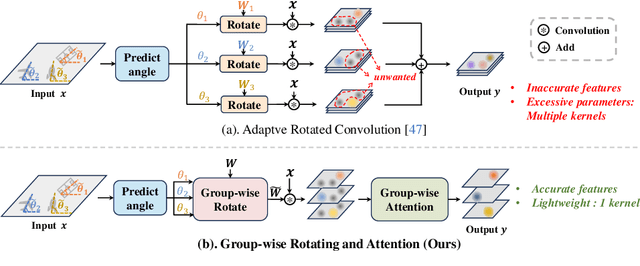
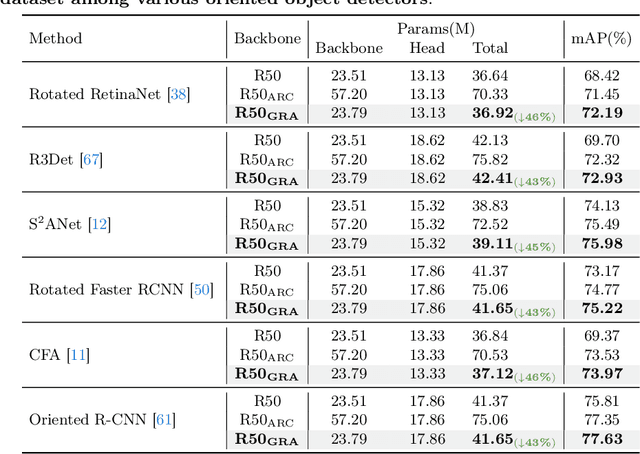
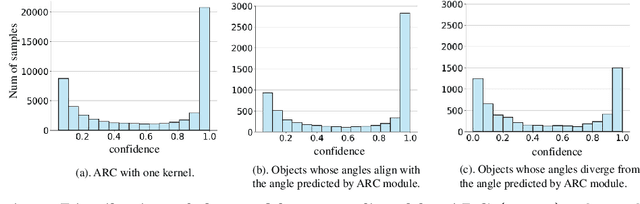
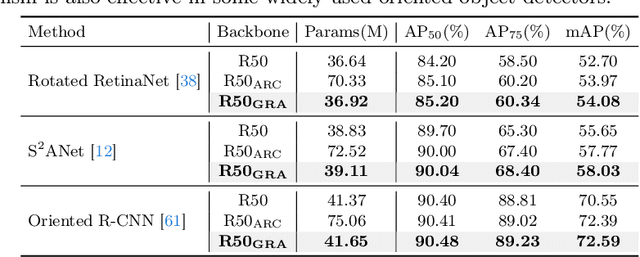
Oriented object detection, an emerging task in recent years, aims to identify and locate objects across varied orientations. This requires the detector to accurately capture the orientation information, which varies significantly within and across images. Despite the existing substantial efforts, simultaneously ensuring model effectiveness and parameter efficiency remains challenging in this scenario. In this paper, we propose a lightweight yet effective Group-wise Rotating and Attention (GRA) module to replace the convolution operations in backbone networks for oriented object detection. GRA can adaptively capture fine-grained features of objects with diverse orientations, comprising two key components: Group-wise Rotating and Group-wise Attention. Group-wise Rotating first divides the convolution kernel into groups, where each group extracts different object features by rotating at a specific angle according to the object orientation. Subsequently, Group-wise Attention is employed to adaptively enhance the object-related regions in the feature. The collaborative effort of these components enables GRA to effectively capture the various orientation information while maintaining parameter efficiency. Extensive experimental results demonstrate the superiority of our method. For example, GRA achieves a new state-of-the-art (SOTA) on the DOTA-v2.0 benchmark, while saving the parameters by nearly 50% compared to the previous SOTA method. Code will be released.
Multiple Object Tracking as ID Prediction
Mar 25, 2024In Multiple Object Tracking (MOT), tracking-by-detection methods have stood the test for a long time, which split the process into two parts according to the definition: object detection and association. They leverage robust single-frame detectors and treat object association as a post-processing step through hand-crafted heuristic algorithms and surrogate tasks. However, the nature of heuristic techniques prevents end-to-end exploitation of training data, leading to increasingly cumbersome and challenging manual modification while facing complicated or novel scenarios. In this paper, we regard this object association task as an End-to-End in-context ID prediction problem and propose a streamlined baseline called MOTIP. Specifically, we form the target embeddings into historical trajectory information while considering the corresponding IDs as in-context prompts, then directly predict the ID labels for the objects in the current frame. Thanks to this end-to-end process, MOTIP can learn tracking capabilities straight from training data, freeing itself from burdensome hand-crafted algorithms. Without bells and whistles, our method achieves impressive state-of-the-art performance in complex scenarios like DanceTrack and SportsMOT, and it performs competitively with other transformer-based methods on MOT17. We believe that MOTIP demonstrates remarkable potential and can serve as a starting point for future research. The code is available at https://github.com/MCG-NJU/MOTIP.