 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Investigation of the Impact of Synthetic Training Data in the Industrial Application of Terminal Strip Object Detection
Mar 06, 2024

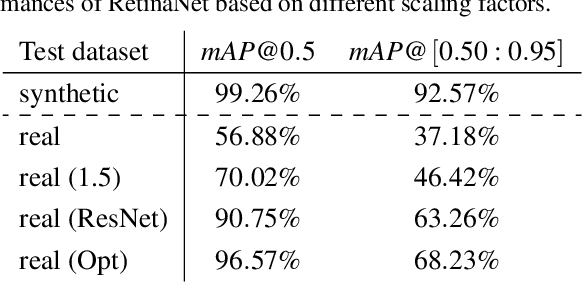

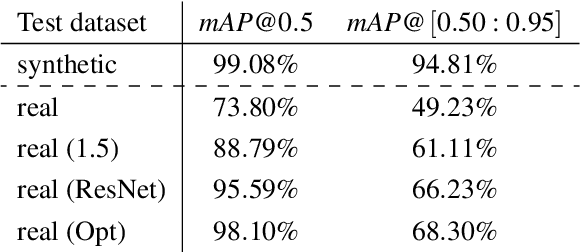
In industrial manufacturing, numerous tasks of visually inspecting or detecting specific objects exist that are currently performed manually or by classical image processing methods. Therefore, introducing recent deep learning models to industrial environments holds the potential to increase productivity and enable new applications. However, gathering and labeling sufficient data is often intractable, complicating the implementation of such projects. Hence, image synthesis methods are commonly used to generate synthetic training data from 3D models and annotate them automatically, although it results in a sim-to-real domain gap. In this paper, we investigate the sim-to-real generalization performance of standard object detectors on the complex industrial application of terminal strip object detection. Combining domain randomization and domain knowledge, we created an image synthesis pipeline for automatically generating the training data. Moreover, we manually annotated 300 real images of terminal strips for the evaluation. The results show the cruciality of the objects of interest to have the same scale in either domain. Nevertheless, under optimized scaling conditions, the sim-to-real performance difference in mean average precision amounts to 2.69 % for RetinaNet and 0.98 % for Faster R-CNN, qualifying this approach for industrial requirements.
Event-to-Video Conversion for Overhead Object Detection
Feb 09, 2024Collecting overhead imagery using an event camera is desirable due to the energy efficiency of the image sensor compared to standard cameras. However, event cameras complicate downstream image processing, especially for complex tasks such as object detection. In this paper, we investigate the viability of event streams for overhead object detection. We demonstrate that across a number of standard modeling approaches, there is a significant gap in performance between dense event representations and corresponding RGB frames. We establish that this gap is, in part, due to a lack of overlap between the event representations and the pre-training data used to initialize the weights of the object detectors. Then, we apply event-to-video conversion models that convert event streams into gray-scale video to close this gap. We demonstrate that this approach results in a large performance increase, outperforming even event-specific object detection techniques on our overhead target task. These results suggest that better alignment between event representations and existing large pre-trained models may result in greater short-term performance gains compared to end-to-end event-specific architectural improvements.
CRPlace: Camera-Radar Fusion with BEV Representation for Place Recognition
Mar 22, 2024The integration of complementary characteristics from camera and radar data has emerged as an effective approach in 3D object detection. However, such fusion-based methods remain unexplored for place recognition, an equally important task for autonomous systems. Given that place recognition relies on the similarity between a query scene and the corresponding candidate scene, the stationary background of a scene is expected to play a crucial role in the task. As such, current well-designed camera-radar fusion methods for 3D object detection can hardly take effect in place recognition because they mainly focus on dynamic foreground objects. In this paper, a background-attentive camera-radar fusion-based method, named CRPlace, is proposed to generate background-attentive global descriptors from multi-view images and radar point clouds for accurate place recognition. To extract stationary background features effectively, we design an adaptive module that generates the background-attentive mask by utilizing the camera BEV feature and radar dynamic points. With the guidance of a background mask, we devise a bidirectional cross-attention-based spatial fusion strategy to facilitate comprehensive spatial interaction between the background information of the camera BEV feature and the radar BEV feature. As the first camera-radar fusion-based place recognition network, CRPlace has been evaluated thoroughly on the nuScenes dataset. The results show that our algorithm outperforms a variety of baseline methods across a comprehensive set of metrics (recall@1 reaches 91.2%).
Deployment Prior Injection for Run-time Calibratable Object Detection
Feb 27, 2024With a strong alignment between the training and test distributions, object relation as a context prior facilitates object detection. Yet, it turns into a harmful but inevitable training set bias upon test distributions that shift differently across space and time. Nevertheless, the existing detectors cannot incorporate deployment context prior during the test phase without parameter update. Such kind of capability requires the model to explicitly learn disentangled representations with respect to context prior. To achieve this, we introduce an additional graph input to the detector, where the graph represents the deployment context prior, and its edge values represent object relations. Then, the detector behavior is trained to bound to the graph with a modified training objective. As a result, during the test phase, any suitable deployment context prior can be injected into the detector via graph edits, hence calibrating, or "re-biasing" the detector towards the given prior at run-time without parameter update. Even if the deployment prior is unknown, the detector can self-calibrate using deployment prior approximated using its own predictions. Comprehensive experimental results on the COCO dataset, as well as cross-dataset testing on the Objects365 dataset, demonstrate the effectiveness of the run-time calibratable detector.
Point-DETR3D: Leveraging Imagery Data with Spatial Point Prior for Weakly Semi-supervised 3D Object Detection
Mar 25, 2024Training high-accuracy 3D detectors necessitates massive labeled 3D annotations with 7 degree-of-freedom, which is laborious and time-consuming. Therefore, the form of point annotations is proposed to offer significant prospects for practical applications in 3D detection, which is not only more accessible and less expensive but also provides strong spatial information for object localization. In this paper, we empirically discover that it is non-trivial to merely adapt Point-DETR to its 3D form, encountering two main bottlenecks: 1) it fails to encode strong 3D prior into the model, and 2) it generates low-quality pseudo labels in distant regions due to the extreme sparsity of LiDAR points. To overcome these challenges, we introduce Point-DETR3D, a teacher-student framework for weakly semi-supervised 3D detection, designed to fully capitalize on point-wise supervision within a constrained instance-wise annotation budget.Different from Point-DETR which encodes 3D positional information solely through a point encoder, we propose an explicit positional query initialization strategy to enhance the positional prior. Considering the low quality of pseudo labels at distant regions produced by the teacher model, we enhance the detector's perception by incorporating dense imagery data through a novel Cross-Modal Deformable RoI Fusion (D-RoI).Moreover, an innovative point-guided self-supervised learning technique is proposed to allow for fully exploiting point priors, even in student models.Extensive experiments on representative nuScenes dataset demonstrate our Point-DETR3D obtains significant improvements compared to previous works. Notably, with only 5% of labeled data, Point-DETR3D achieves over 90% performance of its fully supervised counterpart.
BSDP: Brain-inspired Streaming Dual-level Perturbations for Online Open World Object Detection
Mar 05, 2024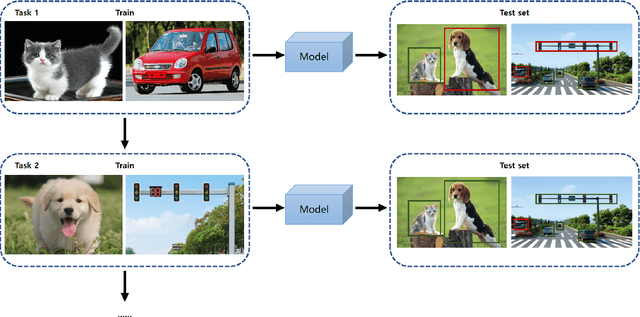

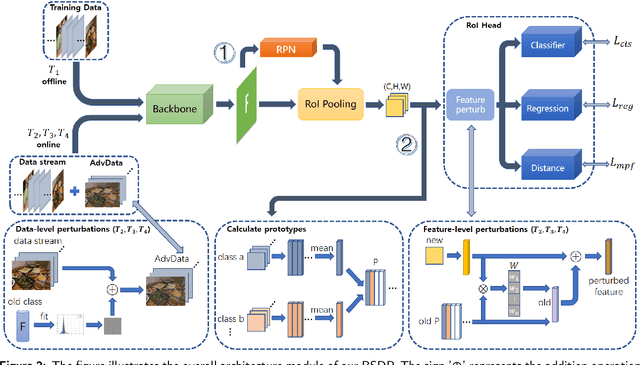
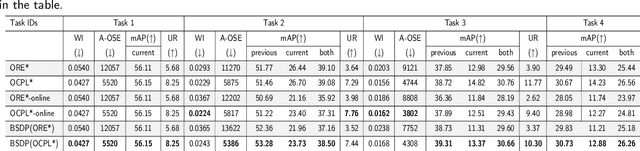
Humans can easily distinguish the known and unknown categories and can recognize the unknown object by learning it once instead of repeating it many times without forgetting the learned object. Hence, we aim to make deep learning models simulate the way people learn. We refer to such a learning manner as OnLine Open World Object Detection(OLOWOD). Existing OWOD approaches pay more attention to the identification of unknown categories, while the incremental learning part is also very important. Besides, some neuroscience research shows that specific noises allow the brain to form new connections and neural pathways which may improve learning speed and efficiency. In this paper, we take the dual-level information of old samples as perturbations on new samples to make the model good at learning new knowledge without forgetting the old knowledge. Therefore, we propose a simple plug-and-play method, called Brain-inspired Streaming Dual-level Perturbations(BSDP), to solve the OLOWOD problem. Specifically, (1) we first calculate the prototypes of previous categories and use the distance between samples and the prototypes as the sample selecting strategy to choose old samples for replay; (2) then take the prototypes as the streaming feature-level perturbations of new samples, so as to improve the plasticity of the model through revisiting the old knowledge; (3) and also use the distribution of the features of the old category samples to generate adversarial data in the form of streams as the data-level perturbations to enhance the robustness of the model to new categories. We empirically evaluate BSDP on PASCAL VOC and MS-COCO, and the excellent results demonstrate the promising performance of our proposed method and learning manner.
Sunshine to Rainstorm: Cross-Weather Knowledge Distillation for Robust 3D Object Detection
Feb 28, 2024LiDAR-based 3D object detection models have traditionally struggled under rainy conditions due to the degraded and noisy scanning signals. Previous research has attempted to address this by simulating the noise from rain to improve the robustness of detection models. However, significant disparities exist between simulated and actual rain-impacted data points. In this work, we propose a novel rain simulation method, termed DRET, that unifies Dynamics and Rainy Environment Theory to provide a cost-effective means of expanding the available realistic rain data for 3D detection training. Furthermore, we present a Sunny-to-Rainy Knowledge Distillation (SRKD) approach to enhance 3D detection under rainy conditions. Extensive experiments on the WaymoOpenDataset large-scale dataset show that, when combined with the state-of-the-art DSVT model and other classical 3D detectors, our proposed framework demonstrates significant detection accuracy improvements, without losing efficiency. Remarkably, our framework also improves detection capabilities under sunny conditions, therefore offering a robust solution for 3D detection regardless of whether the weather is rainy or sunny
Multi-Agent VQA: Exploring Multi-Agent Foundation Models in Zero-Shot Visual Question Answering
Mar 21, 2024This work explores the zero-shot capabilities of foundation models in Visual Question Answering (VQA) tasks. We propose an adaptive multi-agent system, named Multi-Agent VQA, to overcome the limitations of foundation models in object detection and counting by using specialized agents as tools. Unlike existing approaches, our study focuses on the system's performance without fine-tuning it on specific VQA datasets, making it more practical and robust in the open world. We present preliminary experimental results under zero-shot scenarios and highlight some failure cases, offering new directions for future research.
DetToolChain: A New Prompting Paradigm to Unleash Detection Ability of MLLM
Mar 19, 2024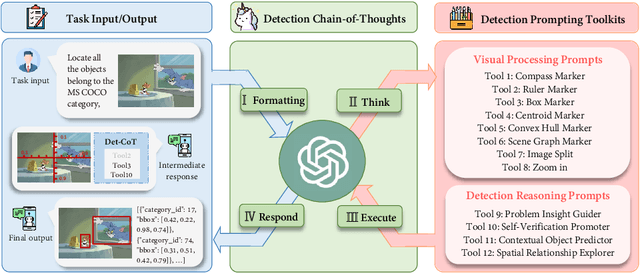

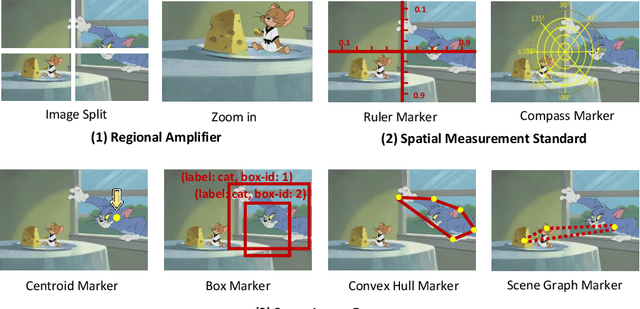
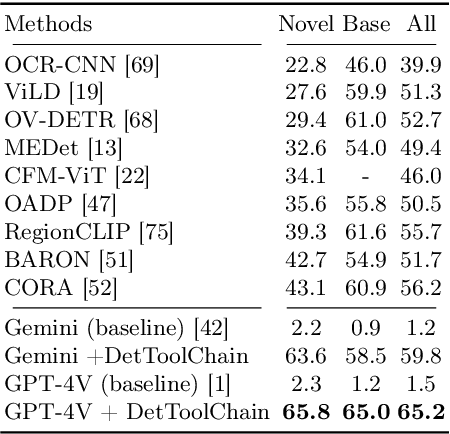
We present DetToolChain, a novel prompting paradigm, to unleash the zero-shot object detection ability of multimodal large language models (MLLMs), such as GPT-4V and Gemini. Our approach consists of a detection prompting toolkit inspired by high-precision detection priors and a new Chain-of-Thought to implement these prompts. Specifically, the prompts in the toolkit are designed to guide the MLLM to focus on regional information (e.g., zooming in), read coordinates according to measure standards (e.g., overlaying rulers and compasses), and infer from the contextual information (e.g., overlaying scene graphs). Building upon these tools, the new detection chain-of-thought can automatically decompose the task into simple subtasks, diagnose the predictions, and plan for progressive box refinements. The effectiveness of our framework is demonstrated across a spectrum of detection tasks, especially hard cases. Compared to existing state-of-the-art methods, GPT-4V with our DetToolChain improves state-of-the-art object detectors by +21.5% AP50 on MS COCO Novel class set for open-vocabulary detection, +24.23% Acc on RefCOCO val set for zero-shot referring expression comprehension, +14.5% AP on D-cube describe object detection FULL setting.
InstaGen: Enhancing Object Detection by Training on Synthetic Dataset
Feb 20, 2024In this paper, we introduce a novel paradigm to enhance the ability of object detector, e.g., expanding categories or improving detection performance, by training on synthetic dataset generated from diffusion models. Specifically, we integrate an instance-level grounding head into a pre-trained, generative diffusion model, to augment it with the ability of localising arbitrary instances in the generated images. The grounding head is trained to align the text embedding of category names with the regional visual feature of the diffusion model, using supervision from an off-the-shelf object detector, and a novel self-training scheme on (novel) categories not covered by the detector. This enhanced version of diffusion model, termed as InstaGen, can serve as a data synthesizer for object detection. We conduct thorough experiments to show that, object detector can be enhanced while training on the synthetic dataset from InstaGen, demonstrating superior performance over existing state-of-the-art methods in open-vocabulary (+4.5 AP) and data-sparse (+1.2 to 5.2 AP) scenarios.