 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Exploring the Potential of Large Foundation Models for Open-Vocabulary HOI Detection
Apr 10, 2024
Open-vocabulary human-object interaction (HOI) detection, which is concerned with the problem of detecting novel HOIs guided by natural language, is crucial for understanding human-centric scenes. However, prior zero-shot HOI detectors often employ the same levels of feature maps to model HOIs with varying distances, leading to suboptimal performance in scenes containing human-object pairs with a wide range of distances. In addition, these detectors primarily rely on category names and overlook the rich contextual information that language can provide, which is essential for capturing open vocabulary concepts that are typically rare and not well-represented by category names alone. In this paper, we introduce a novel end-to-end open vocabulary HOI detection framework with conditional multi-level decoding and fine-grained semantic enhancement (CMD-SE), harnessing the potential of Visual-Language Models (VLMs). Specifically, we propose to model human-object pairs with different distances with different levels of feature maps by incorporating a soft constraint during the bipartite matching process. Furthermore, by leveraging large language models (LLMs) such as GPT models, we exploit their extensive world knowledge to generate descriptions of human body part states for various interactions. Then we integrate the generalizable and fine-grained semantics of human body parts to improve interaction recognition. Experimental results on two datasets, SWIG-HOI and HICO-DET, demonstrate that our proposed method achieves state-of-the-art results in open vocabulary HOI detection. The code and models are available at https://github.com/ltttpku/CMD-SE-release.
Explicit Motion Handling and Interactive Prompting for Video Camouflaged Object Detection
Mar 04, 2024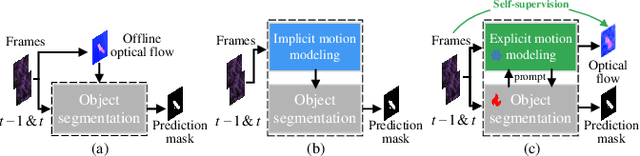
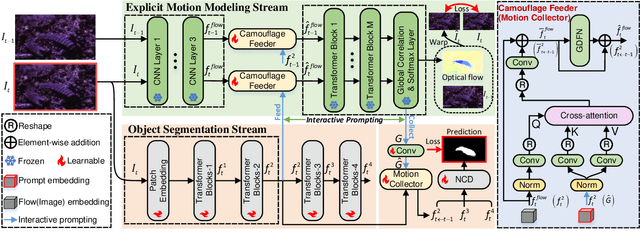

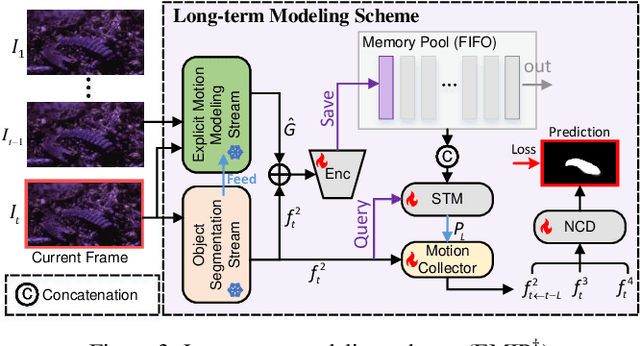
Camouflage poses challenges in distinguishing a static target, whereas any movement of the target can break this disguise. Existing video camouflaged object detection (VCOD) approaches take noisy motion estimation as input or model motion implicitly, restricting detection performance in complex dynamic scenes. In this paper, we propose a novel Explicit Motion handling and Interactive Prompting framework for VCOD, dubbed EMIP, which handles motion cues explicitly using a frozen pre-trained optical flow fundamental model. EMIP is characterized by a two-stream architecture for simultaneously conducting camouflaged segmentation and optical flow estimation. Interactions across the dual streams are realized in an interactive prompting way that is inspired by emerging visual prompt learning. Two learnable modules, i.e. the camouflaged feeder and motion collector, are designed to incorporate segmentation-to-motion and motion-to-segmentation prompts, respectively, and enhance outputs of the both streams. The prompt fed to the motion stream is learned by supervising optical flow in a self-supervised manner. Furthermore, we show that long-term historical information can also be incorporated as a prompt into EMIP and achieve more robust results with temporal consistency. Experimental results demonstrate that our EMIP achieves new state-of-the-art records on popular VCOD benchmarks. The code will be publicly available.
LSKNet: A Foundation Lightweight Backbone for Remote Sensing
Mar 22, 2024
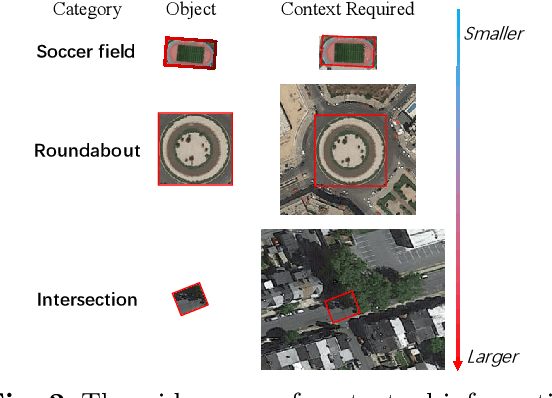
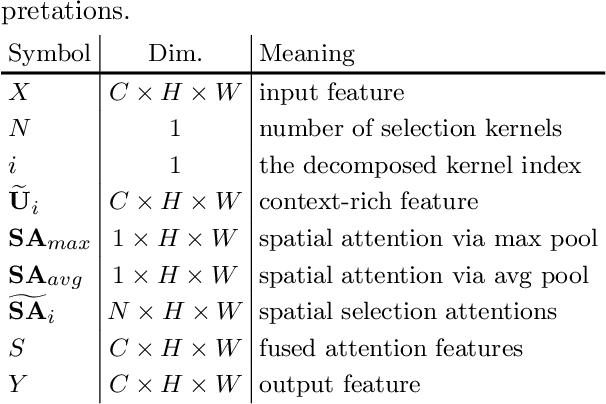
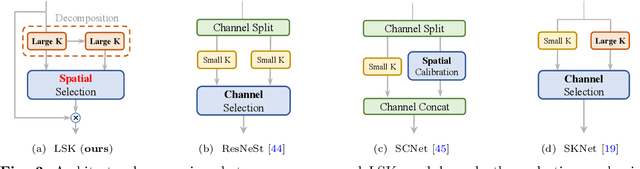
Remote sensing images pose distinct challenges for downstream tasks due to their inherent complexity. While a considerable amount of research has been dedicated to remote sensing classification, object detection and semantic segmentation, most of these studies have overlooked the valuable prior knowledge embedded within remote sensing scenarios. Such prior knowledge can be useful because remote sensing objects may be mistakenly recognized without referencing a sufficiently long-range context, which can vary for different objects. This paper considers these priors and proposes a lightweight Large Selective Kernel Network (LSKNet) backbone. LSKNet can dynamically adjust its large spatial receptive field to better model the ranging context of various objects in remote sensing scenarios. To our knowledge, large and selective kernel mechanisms have not been previously explored in remote sensing images. Without bells and whistles, our lightweight LSKNet sets new state-of-the-art scores on standard remote sensing classification, object detection and semantic segmentation benchmarks. Our comprehensive analysis further validated the significance of the identified priors and the effectiveness of LSKNet. The code is available at https://github.com/zcablii/LSKNet.
Are Dense Labels Always Necessary for 3D Object Detection from Point Cloud?
Mar 05, 2024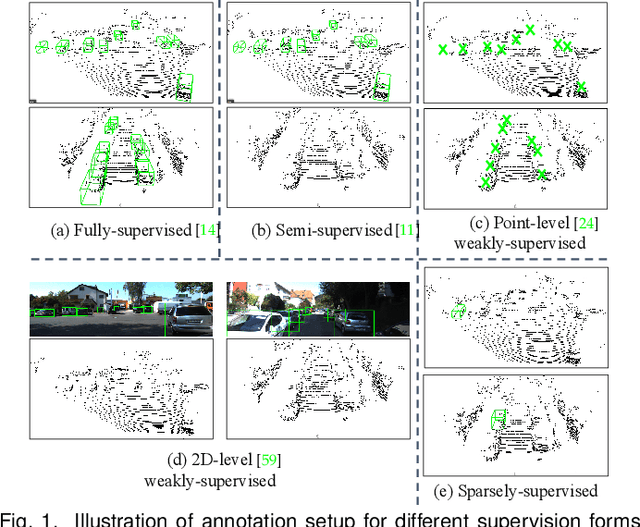
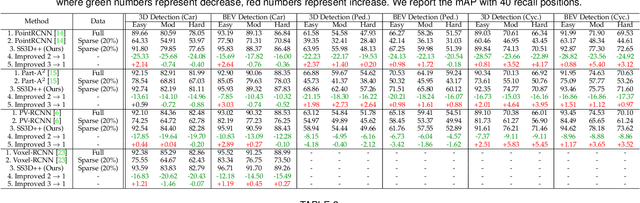
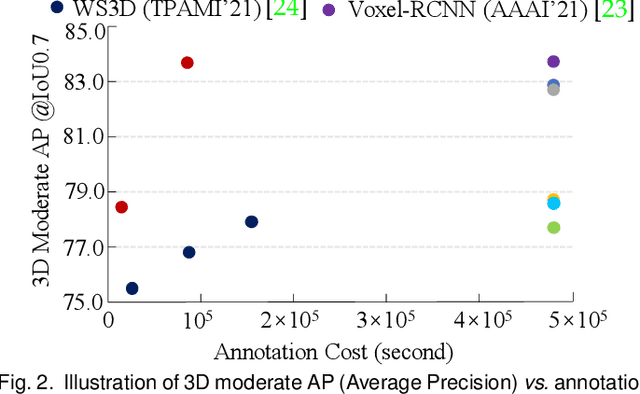

Current state-of-the-art (SOTA) 3D object detection methods often require a large amount of 3D bounding box annotations for training. However, collecting such large-scale densely-supervised datasets is notoriously costly. To reduce the cumbersome data annotation process, we propose a novel sparsely-annotated framework, in which we just annotate one 3D object per scene. Such a sparse annotation strategy could significantly reduce the heavy annotation burden, while inexact and incomplete sparse supervision may severely deteriorate the detection performance. To address this issue, we develop the SS3D++ method that alternatively improves 3D detector training and confident fully-annotated scene generation in a unified learning scheme. Using sparse annotations as seeds, we progressively generate confident fully-annotated scenes based on designing a missing-annotated instance mining module and reliable background mining module. Our proposed method produces competitive results when compared with SOTA weakly-supervised methods using the same or even more annotation costs. Besides, compared with SOTA fully-supervised methods, we achieve on-par or even better performance on the KITTI dataset with about 5x less annotation cost, and 90% of their performance on the Waymo dataset with about 15x less annotation cost. The additional unlabeled training scenes could further boost the performance. The code will be available at https://github.com/gaocq/SS3D2.
Dual DETRs for Multi-Label Temporal Action Detection
Mar 31, 2024Temporal Action Detection (TAD) aims to identify the action boundaries and the corresponding category within untrimmed videos. Inspired by the success of DETR in object detection, several methods have adapted the query-based framework to the TAD task. However, these approaches primarily followed DETR to predict actions at the instance level (i.e., identify each action by its center point), leading to sub-optimal boundary localization. To address this issue, we propose a new Dual-level query-based TAD framework, namely DualDETR, to detect actions from both instance-level and boundary-level. Decoding at different levels requires semantics of different granularity, therefore we introduce a two-branch decoding structure. This structure builds distinctive decoding processes for different levels, facilitating explicit capture of temporal cues and semantics at each level. On top of the two-branch design, we present a joint query initialization strategy to align queries from both levels. Specifically, we leverage encoder proposals to match queries from each level in a one-to-one manner. Then, the matched queries are initialized using position and content prior from the matched action proposal. The aligned dual-level queries can refine the matched proposal with complementary cues during subsequent decoding. We evaluate DualDETR on three challenging multi-label TAD benchmarks. The experimental results demonstrate the superior performance of DualDETR to the existing state-of-the-art methods, achieving a substantial improvement under det-mAP and delivering impressive results under seg-mAP.
Embodied Active Defense: Leveraging Recurrent Feedback to Counter Adversarial Patches
Mar 31, 2024The vulnerability of deep neural networks to adversarial patches has motivated numerous defense strategies for boosting model robustness. However, the prevailing defenses depend on single observation or pre-established adversary information to counter adversarial patches, often failing to be confronted with unseen or adaptive adversarial attacks and easily exhibiting unsatisfying performance in dynamic 3D environments. Inspired by active human perception and recurrent feedback mechanisms, we develop Embodied Active Defense (EAD), a proactive defensive strategy that actively contextualizes environmental information to address misaligned adversarial patches in 3D real-world settings. To achieve this, EAD develops two central recurrent sub-modules, i.e., a perception module and a policy module, to implement two critical functions of active vision. These models recurrently process a series of beliefs and observations, facilitating progressive refinement of their comprehension of the target object and enabling the development of strategic actions to counter adversarial patches in 3D environments. To optimize learning efficiency, we incorporate a differentiable approximation of environmental dynamics and deploy patches that are agnostic to the adversary strategies. Extensive experiments demonstrate that EAD substantially enhances robustness against a variety of patches within just a few steps through its action policy in safety-critical tasks (e.g., face recognition and object detection), without compromising standard accuracy. Furthermore, due to the attack-agnostic characteristic, EAD facilitates excellent generalization to unseen attacks, diminishing the averaged attack success rate by 95 percent across a range of unseen adversarial attacks.
YOLO-TLA: An Efficient and Lightweight Small Object Detection Model based on YOLOv5
Feb 22, 2024Object detection, a crucial aspect of computer vision, has seen significant advancements in accuracy and robustness. Despite these advancements, practical applications still face notable challenges, primarily the inaccurate detection or missed detection of small objects. In this paper, we propose YOLO-TLA, an advanced object detection model building on YOLOv5. We first introduce an additional detection layer for small objects in the neck network pyramid architecture, thereby producing a feature map of a larger scale to discern finer features of small objects. Further, we integrate the C3CrossCovn module into the backbone network. This module uses sliding window feature extraction, which effectively minimizes both computational demand and the number of parameters, rendering the model more compact. Additionally, we have incorporated a global attention mechanism into the backbone network. This mechanism combines the channel information with global information to create a weighted feature map. This feature map is tailored to highlight the attributes of the object of interest, while effectively ignoring irrelevant details. In comparison to the baseline YOLOv5s model, our newly developed YOLO-TLA model has shown considerable improvements on the MS COCO validation dataset, with increases of 4.6% in mAP@0.5 and 4% in mAP@0.5:0.95, all while keeping the model size compact at 9.49M parameters. Further extending these improvements to the YOLOv5m model, the enhanced version exhibited a 1.7% and 1.9% increase in mAP@0.5 and mAP@0.5:0.95, respectively, with a total of 27.53M parameters. These results validate the YOLO-TLA model's efficient and effective performance in small object detection, achieving high accuracy with fewer parameters and computational demands.
ASDF: Assembly State Detection Utilizing Late Fusion by Integrating 6D Pose Estimation
Mar 25, 2024In medical and industrial domains, providing guidance for assembly processes is critical to ensure efficiency and safety. Errors in assembly can lead to significant consequences such as extended surgery times, and prolonged manufacturing or maintenance times in industry. Assembly scenarios can benefit from in-situ AR visualization to provide guidance, reduce assembly times and minimize errors. To enable in-situ visualization 6D pose estimation can be leveraged. Existing 6D pose estimation techniques primarily focus on individual objects and static captures. However, assembly scenarios have various dynamics including occlusion during assembly and dynamics in the assembly objects appearance. Existing work, combining object detection/6D pose estimation and assembly state detection focuses either on pure deep learning-based approaches, or limit the assembly state detection to building blocks. To address the challenges of 6D pose estimation in combination with assembly state detection, our approach ASDF builds upon the strengths of YOLOv8, a real-time capable object detection framework. We extend this framework, refine the object pose and fuse pose knowledge with network-detected pose information. Utilizing our late fusion in our Pose2State module results in refined 6D pose estimation and assembly state detection. By combining both pose and state information, our Pose2State module predicts the final assembly state with precision. Our evaluation on our ASDF dataset shows that our Pose2State module leads to an improved assembly state detection and that the improvement of the assembly state further leads to a more robust 6D pose estimation. Moreover, on the GBOT dataset, we outperform the pure deep learning-based network, and even outperform the hybrid and pure tracking-based approaches.
NeRF-MAE : Masked AutoEncoders for Self Supervised 3D representation Learning for Neural Radiance Fields
Apr 01, 2024Neural fields excel in computer vision and robotics due to their ability to understand the 3D visual world such as inferring semantics, geometry, and dynamics. Given the capabilities of neural fields in densely representing a 3D scene from 2D images, we ask the question: Can we scale their self-supervised pretraining, specifically using masked autoencoders, to generate effective 3D representations from posed RGB images. Owing to the astounding success of extending transformers to novel data modalities, we employ standard 3D Vision Transformers to suit the unique formulation of NeRFs. We leverage NeRF's volumetric grid as a dense input to the transformer, contrasting it with other 3D representations such as pointclouds where the information density can be uneven, and the representation is irregular. Due to the difficulty of applying masked autoencoders to an implicit representation, such as NeRF, we opt for extracting an explicit representation that canonicalizes scenes across domains by employing the camera trajectory for sampling. Our goal is made possible by masking random patches from NeRF's radiance and density grid and employing a standard 3D Swin Transformer to reconstruct the masked patches. In doing so, the model can learn the semantic and spatial structure of complete scenes. We pretrain this representation at scale on our proposed curated posed-RGB data, totaling over 1.6 million images. Once pretrained, the encoder is used for effective 3D transfer learning. Our novel self-supervised pretraining for NeRFs, NeRF-MAE, scales remarkably well and improves performance on various challenging 3D tasks. Utilizing unlabeled posed 2D data for pretraining, NeRF-MAE significantly outperforms self-supervised 3D pretraining and NeRF scene understanding baselines on Front3D and ScanNet datasets with an absolute performance improvement of over 20% AP50 and 8% AP25 for 3D object detection.
Scalable Vision-Based 3D Object Detection and Monocular Depth Estimation for Autonomous Driving
Mar 04, 2024
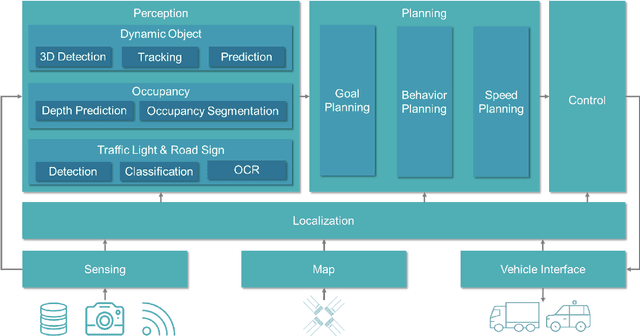
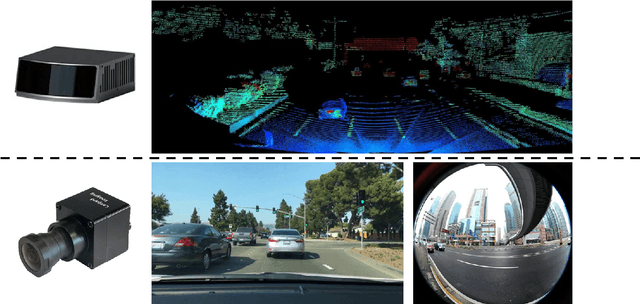
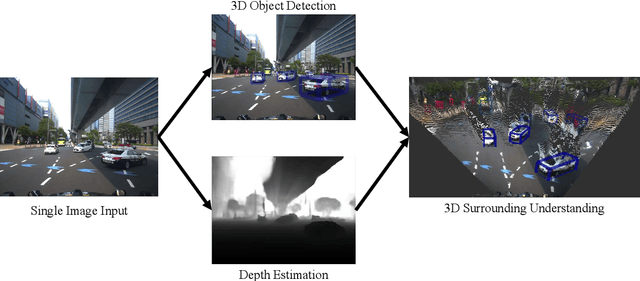
This dissertation is a multifaceted contribution to the advancement of vision-based 3D perception technologies. In the first segment, the thesis introduces structural enhancements to both monocular and stereo 3D object detection algorithms. By integrating ground-referenced geometric priors into monocular detection models, this research achieves unparalleled accuracy in benchmark evaluations for monocular 3D detection. Concurrently, the work refines stereo 3D detection paradigms by incorporating insights and inferential structures gleaned from monocular networks, thereby augmenting the operational efficiency of stereo detection systems. The second segment is devoted to data-driven strategies and their real-world applications in 3D vision detection. A novel training regimen is introduced that amalgamates datasets annotated with either 2D or 3D labels. This approach not only augments the detection models through the utilization of a substantially expanded dataset but also facilitates economical model deployment in real-world scenarios where only 2D annotations are readily available. Lastly, the dissertation presents an innovative pipeline tailored for unsupervised depth estimation in autonomous driving contexts. Extensive empirical analyses affirm the robustness and efficacy of this newly proposed pipeline. Collectively, these contributions lay a robust foundation for the widespread adoption of vision-based 3D perception technologies in autonomous driving applications.